이진 분류와 로지스틱 회귀
분류와 군집화:Classification vs Clustering
분류:지도 학습: 정답이 있는 데이터셋을 분류하는 것
EX) iris데이터 셋에서 품종의 분류, titanic 데이터셋에서 생존 여부를 예측
군집화 :비지도 학습:정답이 없는 데이터셋을 분류하는 것
iris 데이터셋에서 모양이 유사한 꽃들의 군집 찾기, titanic 데이터셋에서 서로 가까운 사람들의 군집 찾기
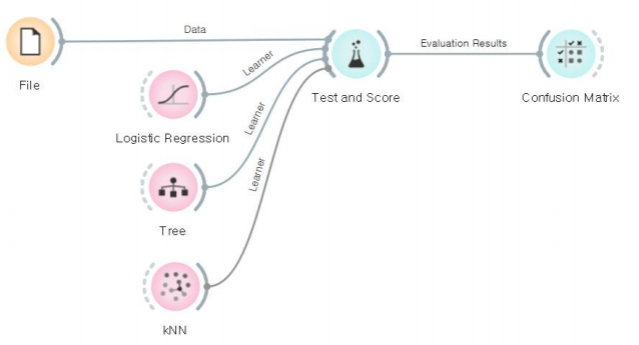
분류기의 종류
로지스틱 회귀분석:Logistic Regression
의사결정 트리:Decision Tree
랜덤 포리스트:Random Forest
k-최근접 이웃:kNN,k-Nearest-Neighbor
나이브 베이지안:Naive Bayesian
서포트 벡터머신:SVM,Support Vector Machine
이진 분류: Binary Classification
분류도 예측의 일종이지만, 종속변수가 범주형 변수이다.
-이진 분류: 종속변수 값의 범위가 두 개일때
titanic 데이터셋: survival 변수는 (생존,사망) 둘 중의 하나, 암 진단: 종속 변수가 암에 (걸렸거나, 걸리지 않았거나) 둘중의 하나
로지스틱 회귀: Logistic Regression
종속변수의 값이 바이너리 형태인 경우에 적용하기 좋은 회귀분석 모델
-직선으로는 이런 데이터를 잘 설명할 수 없으므로, 적절한 곡선을 찾아야 함.
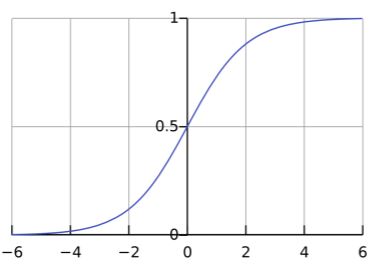
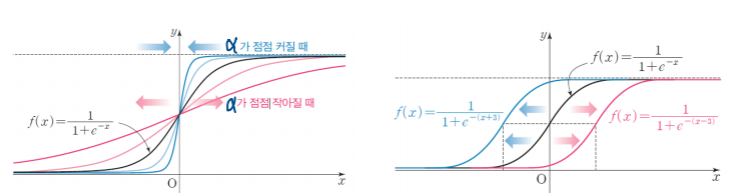
로지스틱 함수: Logistic Function
바이너리 값을 가지는 범주형 데이터를 잘 설명해 주는 지수 함수
y=1/(1+e^-x),e는 자연상수(오일러의 수, 네이피어의 수)
로지스틱 함수의 성질과 활용:
시그모이드 함수:Sigmoid Function
-bounded: 유한한 구간(a,b) 사이의 한정된 값을 갖는다.
-monotonic: 항상 양의 기울기를 가지는 단조증가 함수다.
로지스틱 함수를 분류의 기준을 충족할 확률로 해설
-y=αx+β,f(x)=1/(1+e^-(αx+β))
-f(x)>0.5: y=1이라고 분류
-f(x)<0.5: y=0이라고 분류
로지스틱 회귀식을 학습하기 위한 과정:
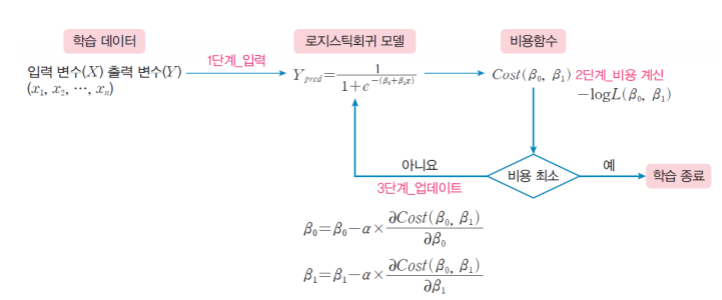
로지스틱 회귀식을 찾는 방법:
로지스틱 함수 f(x)에서 가장 적절한 α와 β 찾기
- 최대 우도 추정법:MLE, Maximum Likelihoode Estimation
우도 함수:Likelihood Function
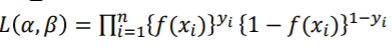
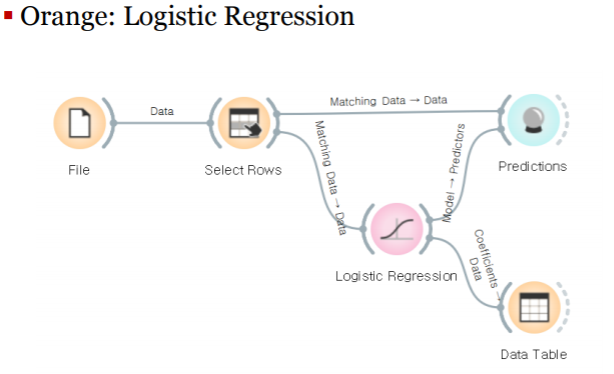
분류모델의 평가와 교차 검증
이진 분류의 결과 표현:
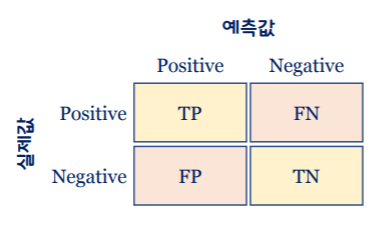
혼동 행렬: Confusion Matrix
-이진 분류기의 분류 결과를 2x2 행렬로 표시한 행렬
-이진 분류기가 분류(예측)할 때, 얼마나 많이 헷갈렸는가를 나타냄
분류 모델의 성능 평가 지표: Evaluation Metric
정확도:CA, Classfication Accuracy
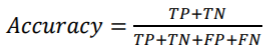
정밀도:Precision
-Precision= TP / TP+FP
재현율:Recall
-Recall= TP/TP+FN, 분류기가 양성으로 판정한 것의 비율은 얼마인가?
F1-SCORE
-F1=2precisionrecall/precision+recall, 정밀도와 재현율의 조화평균
분류 모델의 성능 평가 지표:
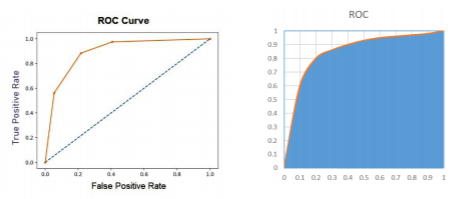
ROC 곡선: Receiver Operation Characteristic Curve
-이진 분류의 결과에서 FP 비율과 TP 비율의 관계를 그린 곡선
AUC:Area Under Curve//1에 가까울수록 좋은 성능이다.
-ROC 곡선의 하부 면적으로 표현하는 성능 평가 지표
교차 검증:Cross Validation
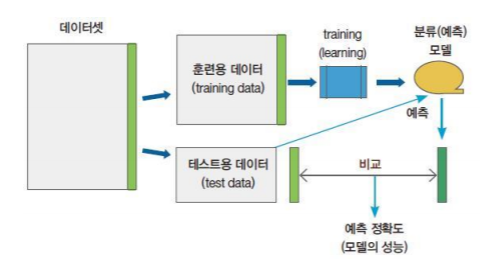
훈련용 데이터셋을 가지고 분류기의 정확성을 검증하는 방법은?
훈련용 데이터와 시험용 데이터로 나누어서 성능 평가
- 훈련용/시험용 데이터로 나누는 좋은 방법은?
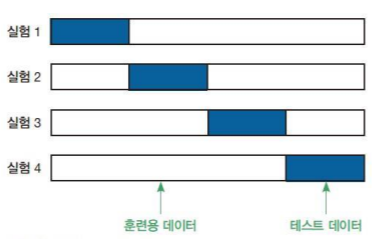
교차 검증 방법들:
k-폴드 교차 검증:k-Fold Cross Validation
-데이터셋을 k개의 폴드로 분리하여 하나만 시험용으로 사용
-Stratified:원본 데이터의 라벨 분포를 먼저 고려
랜덤 샘플링: Random Sampling
-임의로 학습용/시험용 데이터 셋을 추출하여 교차 검증
리브-원-아웃: Leave-One-Out Cross Validation(LOOCV)
-폴드 하나에 샘플 하나만 남겨두는 K-폴드 교차 검증
k-폴드 교차 검증:k-Fold Cross Validation
주어진 데이터셋을 k개로 나누어서 훈련용/검증용 데이터로 번갈아 사용
k개의 검증용 데이터셋으로 분류 모델의 성능을 테스트한 평균값을 지표로 사용
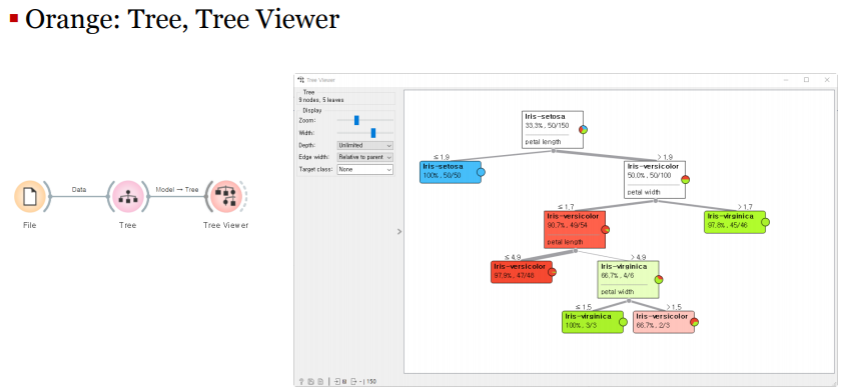
결정 트리와 k최근접 이웃
결정 트리:Decision Tree
데이터를 학습해서 트리 기반의 분류 규칙을 만드는 방법
일종의 스무고개 방식: 분할 정복(Divide-and-Conquer)
-루트 노드: 모든 데이터를 포함
-중간 노드: 특정 조건에 따른 데이터의 분할
-리프 노드: 분류 조건에 맞는 데이터의 집합
결정 트리를 학습하는 방법:
분할 조건이 되는 특징을 어떻게 식별할 것인가?
-순도(purity): 단일 분류 데이터를 포함하는 정도
-분류의 기준: 각 단계별로 순도가 높아지는 방향으로 분류
정보 이득:information gain
-데이터를 나누기 전과 데이터를 나눈 후의 정보량의 변화
정보 엔트로피:Information Entropy
정보량:어떤 데이터가 포함하고 있는 정보의 총 기대치
-어떤 사건이 발생할 확률이 p이면 그 사건의 정보량은 logb(1/p)
-어떤 사건의 정보량의 기대치 p*logb(1/p)=-plogb(p)
정보 엔트로피: 전체 사건의 기대치
-각 사건의 기대치의 합:
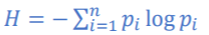
-사건의 확률이 1/2이라면: log의 밑은 2:
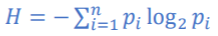
데이터의 순도가 높아지는 방향: 정보 엔트로피가 낮아지는 방향
k-최근접-이웃:k-Nearest-Neighbor
어떤 데이터와 가장 가까운 k개의 이웃을 보고, 가장 적절한 분류를 결정
협업 필터링:Collaboration Filtering
ex)유튜브/넷플릭스/페이스북의 추천 알고리즘
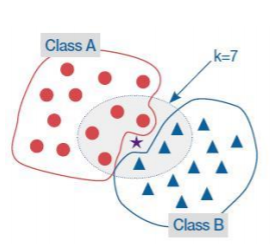
kNN의 적용:
K의 값을 어떻게 결정할 수 있는가?
- 데이터셋의 관측값의 개수가 100이라면? K는 10보다 작은 것이 좋다
- 보통은 1~10의 값을 차례로 실험해 보면서 예측의 정확도를 평가한다
이웃의 군집이 동수가 나오면? - 일반적으로는 둘 중 하나를 임의로 선택(random choice)
- k의 값을 줄이거나 늘려서 선택하는 방법도 있음
k개의 이웃을 찾는 것은 쉬운가? - 새로운 데이터 P가 도착했을 때 k개의 이웃을 찾으려면
- 기존의 모든 데이터들과 거리를 비교해야 함