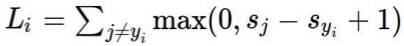Machine Learning
Bayesian Classification
Logistic Regression
Linear Classification
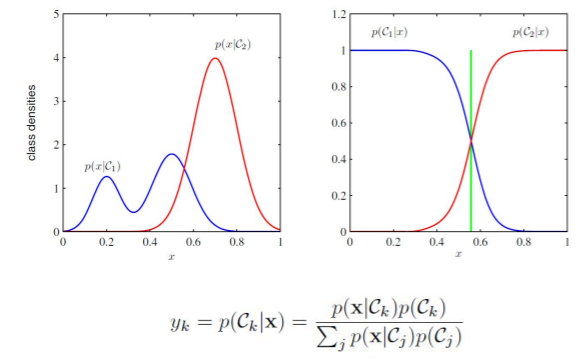
Bayesian Classification
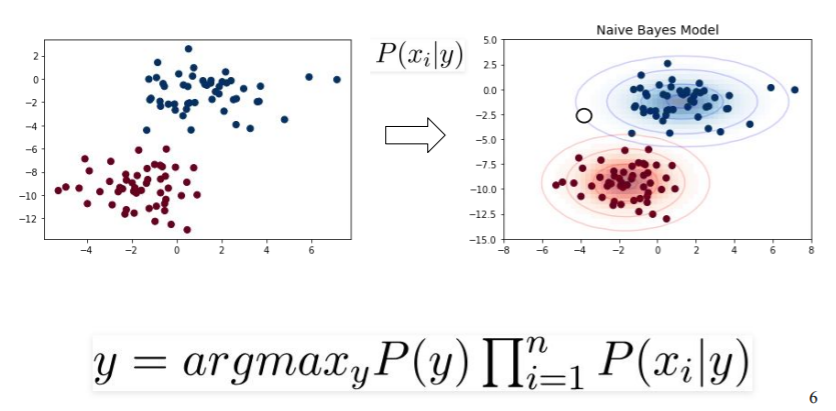
- 분류 작업에 기반한 확률 머신러닝 모델
- 베이즈 정리에 기반함
- Bayes Theorem:
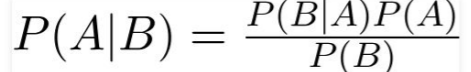
-베이즈 정리를 사용, predictor와 feature가 독립적이라는 가정 -> naive
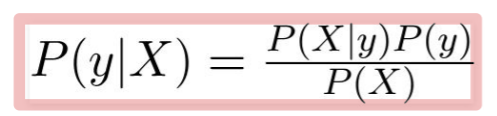
변수 y는 class variable이고, X는 parameter/feature를 대표함
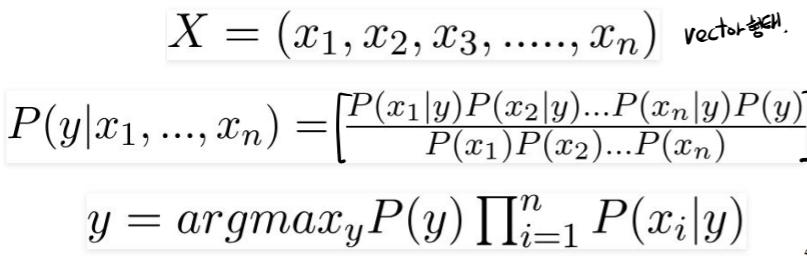
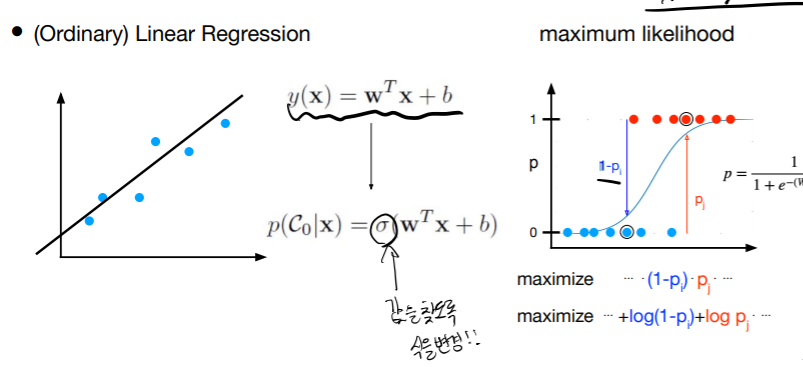
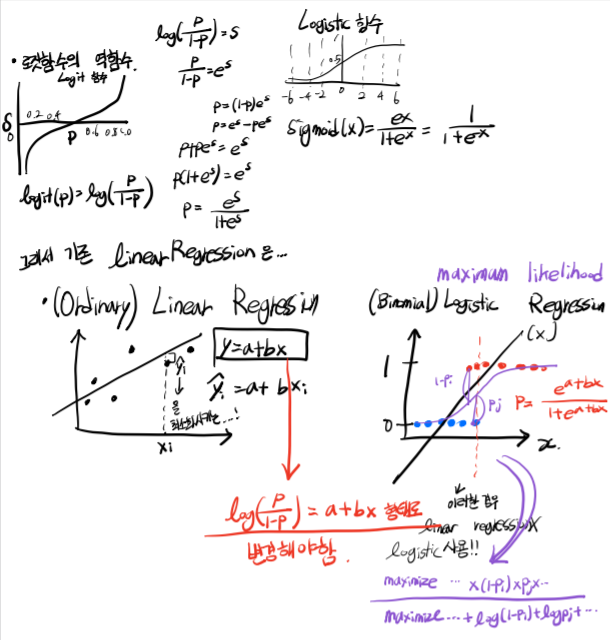
Logistic Regression

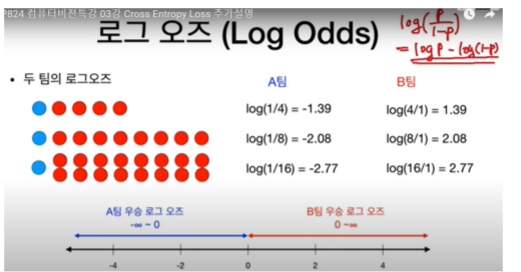
Odds(오즈)
어떤 사건 A가 일어난 횟수와 어떤 사건이 잃어나지 않은 횟수의 비율
(A팀이 경기에서 이긴 횟수와 이기지 못한 횟수의 비율)


Winning odds

log odds

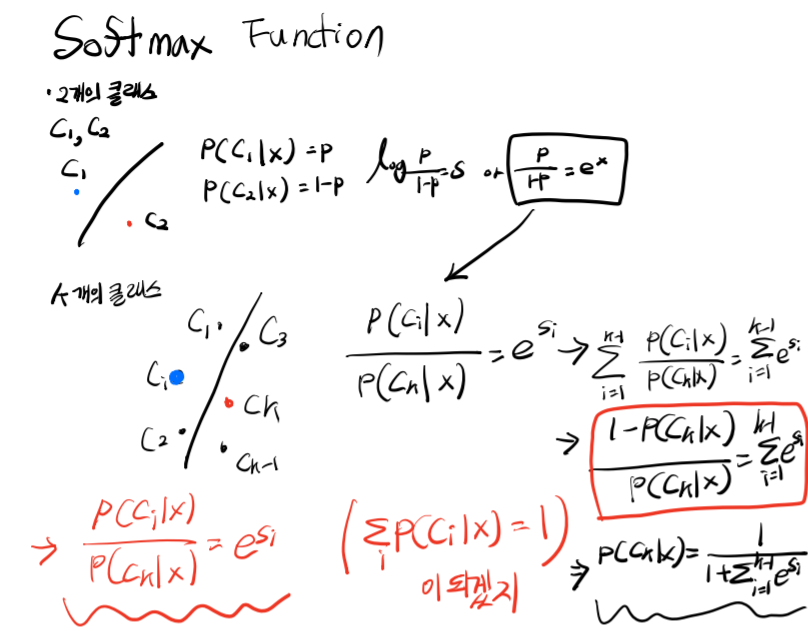
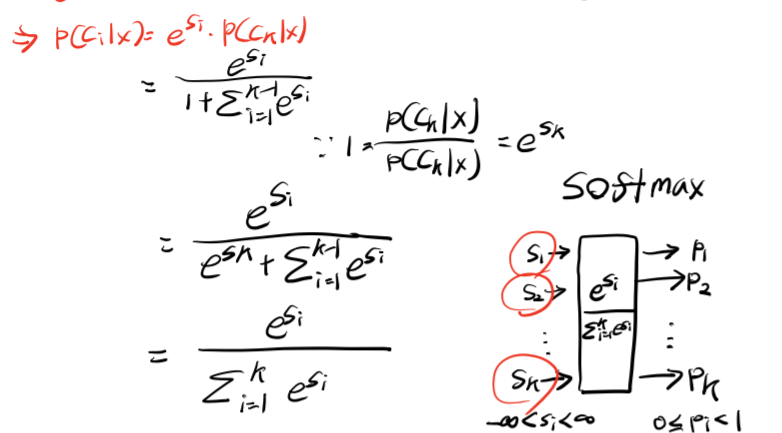
Soft max
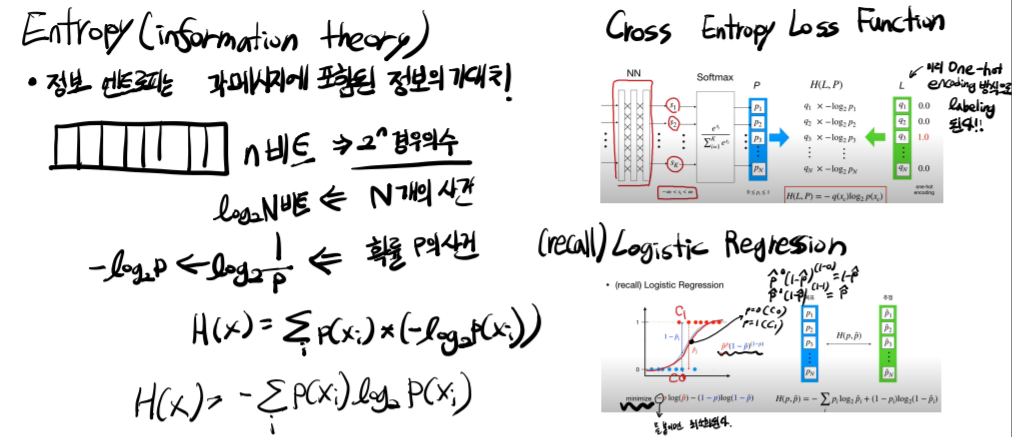
Entropy
Linear Classification
Parametric Approach
vs Non parametric approach
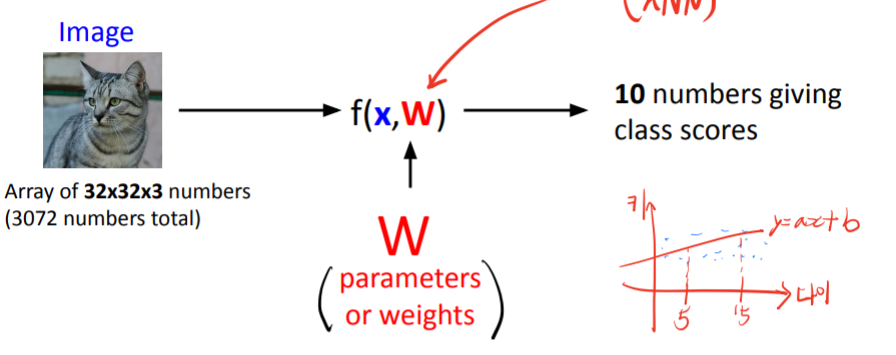
https://newsight.tistory.com/40
parametric model: 데이터가 특정한 모델을 따른다고 가정하고, 그것의 고정된 개수의 파라미터들을 학습해서 튜닝하는 것
ex) Linear regression, Gaussian Mixture Model
Non-parametric model: 데이터가 특정한 파라미터에 종속된다고 가정하지 않고, 학습에서 튜닝할 파라미터가 명시적으로 존재하지 않거나,정확히 셀 수 없는 경우
-> 파라미터를 추정하거나 교정하는 식으로 동작하지 않음 데이터의 분포를 표현하는 정도!
ex) KNN(학습을 해서 파라미터 튜닝하는게 아님, k는 학습대상이 아님)
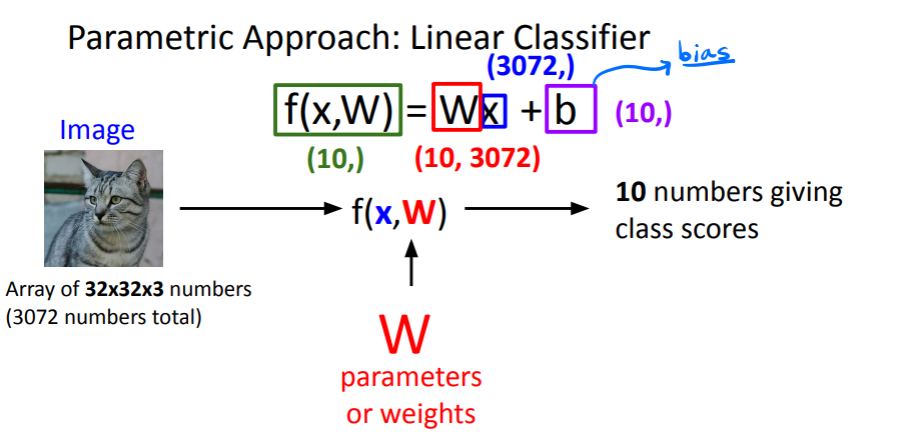
Example
w (class 개수, image pixel 수)
x (image pixel 수)
b (class 개수)
f(x,W) => class 개수
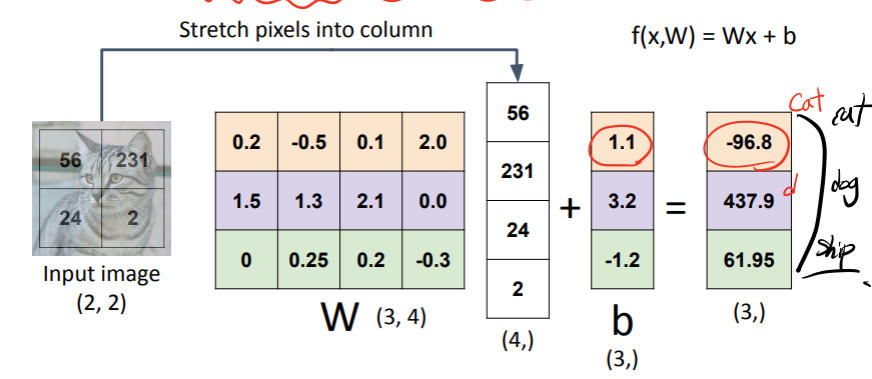

Algebraic Viewpoint로 해석하기
=> f(x,W) =Wx + b
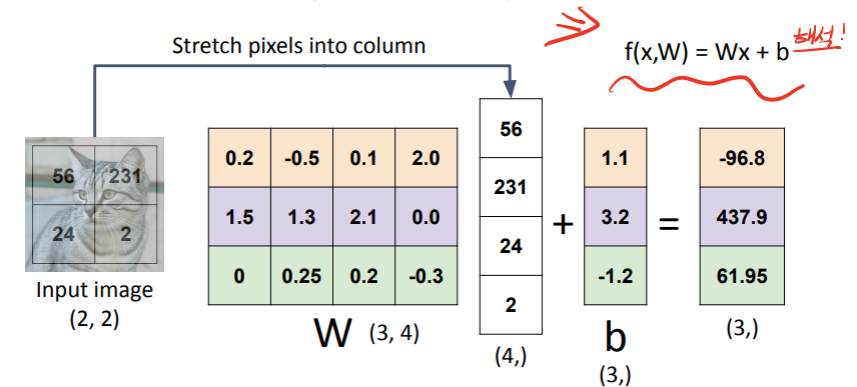
bias Trick
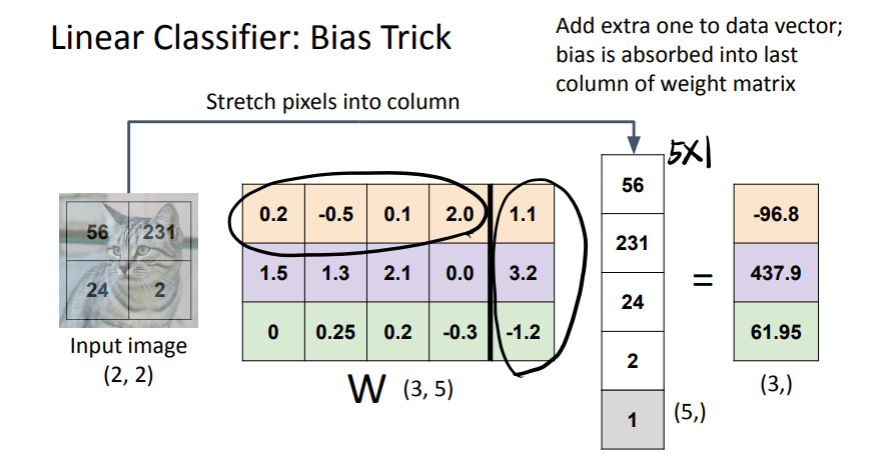
가중치에 bias 추가하고, x에 1하나 추가해서 출력 만들 수 있다!
prediction은 선형이다!

linear classifier 해석하기
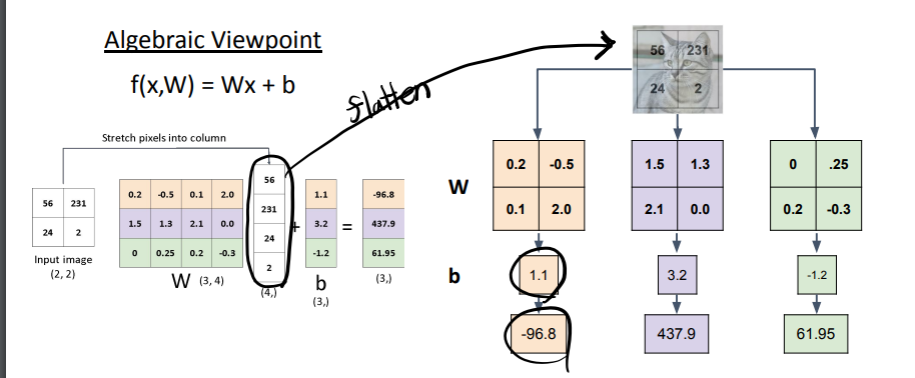
Visual Viewpoint로 해석하기
linear classifier는 category 당 한개이 템플릿을 가진다
한개의 템플릿은 data 여러개의 모드들을 포착할 수 없다
e.g. horse의 template이 2개의 머리를 가진다!
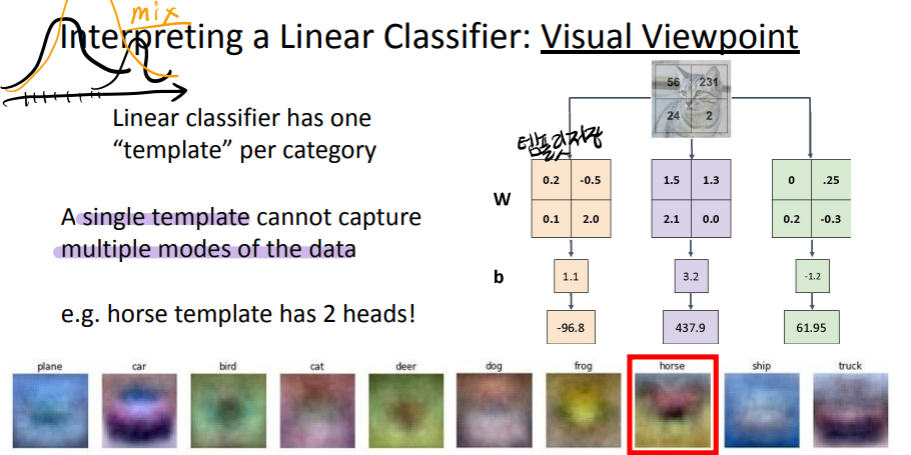
입력 영상에서 (작은 크기의) 템플릿 영상과 일치하는 부분을 찾는 기법
https://velog.io/@codren/%ED%85%9C%ED%94%8C%EB%A6%BF-%EB%A7%A4%EC%B9%AD

Geometric Viewpoint로 해석하기
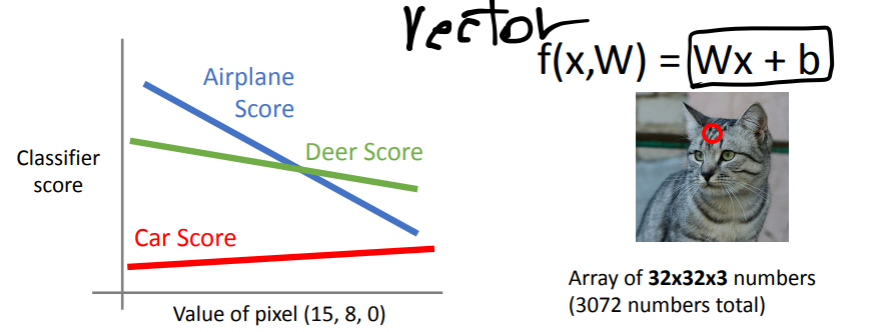
또한 linear classifier로 분류하기 어려운 케이스들이 있다
->XOR gate 같은 경우!
- image x에 대해, score function을 정의해야 한다
-> 그러나 어떻게 실제로 좋은 W 를 고를 수 있을까?
lost function이 최소화하는 방향으로 update!
- w값을 잘 정량화시키는 loss function 사용
- loss function을 최소화 시키는 W를 찾는다.(최적화)
Loss Function
loss function은 현재 분류기가 얼마나 좋은지 알려준다
Low loss = good classifier
High loss = bad classifier
(=objective funciton, cost function)
Negative loss function = reward function, profit function, utility function, fitness function
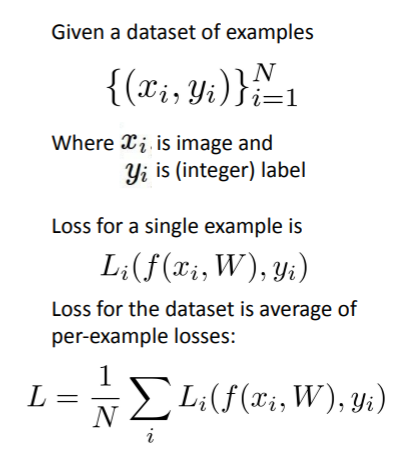
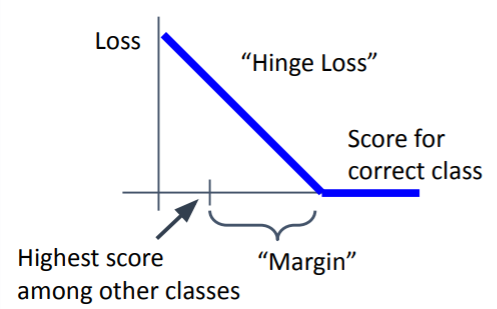
Multiclass SVM Loss
올바른 클래스의 score는 다른 것들보다 높아야함
(xi,yi)가 주어졌을때 (xi: image, yi: label)
s = f(xi,W)라고 정의
SVM loss: