1. Introduction

-
LLM is not guaranteed to be accurate for all queries
-
Understanding which queries they are reliable for is important
-
Selective Prediction : the deployment scenario for AI where humans are involved to maintain overall accuracy by reviewing AI-generated, low-confidence outputs
- Both human and AI performance are considered together to minimize human involvement cost
- AI should use Selective Prediction to assess the accuracy of their prediction and refrain from making wrong predictions
- Able to say "I don't know" when its prediction is not confident
-
Selective Prediction is hard as LLM is trained to predict not the "correct" next token but only the "next" token
-
It doesn't generate a confidence score also obtaining confidence score from output sequence is not straightforward
-
Distinguishing the correctness from likelihood scores is a challenging
- Using Prompt (Is the proposed answer True or False?) not generalized to other LLMs
- Semantic Entropy or Self-consistency should generate multiple output sequence
- Fine-tuning LLMs on target question can improve the likelihood of the ground-truth it is not same as minimizing wrong answers and it still has probability to generate wrong answers
-
ASPIRE : learns self-evaluate from target-task data
- training LLMs on a subset of the training data from the QA tasks
- define a selection score that combines the likelihood of the generated answer with the learned self-eval score to make selective predictions
- less computationally expensive than generating multiple output sequences
2. Related Work
Selective Predictions for LLMs
- Selective Prediction for classification (NLI) vs Selective Prediction for NLG
- NLG task has infinite size of the possible answer set
- Uncertainty Measure for LLMs
- Use selective prediction to solve QA task when question is ambiguous
- Use auxiliary model to distinguish correct predictions of QA model
Parameter Efficient Fine-Tuning (PEFT)
- LoRA
- Prefix Tuning
- Soft Prompt Tuning used!
- P-Tuning
3. Problem Setup
Notations
- pretrained LLM for arbitary generative modeling task like QA
- vocabulary
- the space of sequences of tokens
- logits of on given is
- the likelihood of the next token following being is(softmax!)
- likelihood of generating given iswhere and
- This likelihood can be very small when is very large normalize the likelihood
- use to generate the output sequence by solving
- Impossible to solve exactly as the output sequence is arbitrarily long use decoding strategy (greedy decoding, beam search) to solve it
Evaluate Correctness
-
set of reference outputs
-
evaluation metric
- evaluate the similarity of the generated output and the reference output
-
threshold
- if , then the generated output is correct
-
training dataset randomly sampled from a target task distribution
-
rejection operation
-
selective predictor
- should achieve strong selective prediction performance on test dataset
- composed of a predictor and a selection scoring function
- accuracy : the fraction of the accepted inputs where the predictions are correct
- coverage : the fraction of the inputs that are accepted
- Tune to achieve a certain coverage and manage accuracy-coverage trade-off
-
use AUACC (area under the accuracy-coverage curve) to measure selective prediction performance
-
use AUROC (area under the receiver operator characteristic curve) to measure the quality of the selection score estimation
- equivalent to the probability that a randomly chosen correct output sequence has a higher selection score than a randomly chosen incorrect output sequence
4. ASPIRE Framework
- LLM should have self-evaluation ability
- Previous work was only adaptable for specific LLMs
- Colelcting some training data to employ self-evaluation
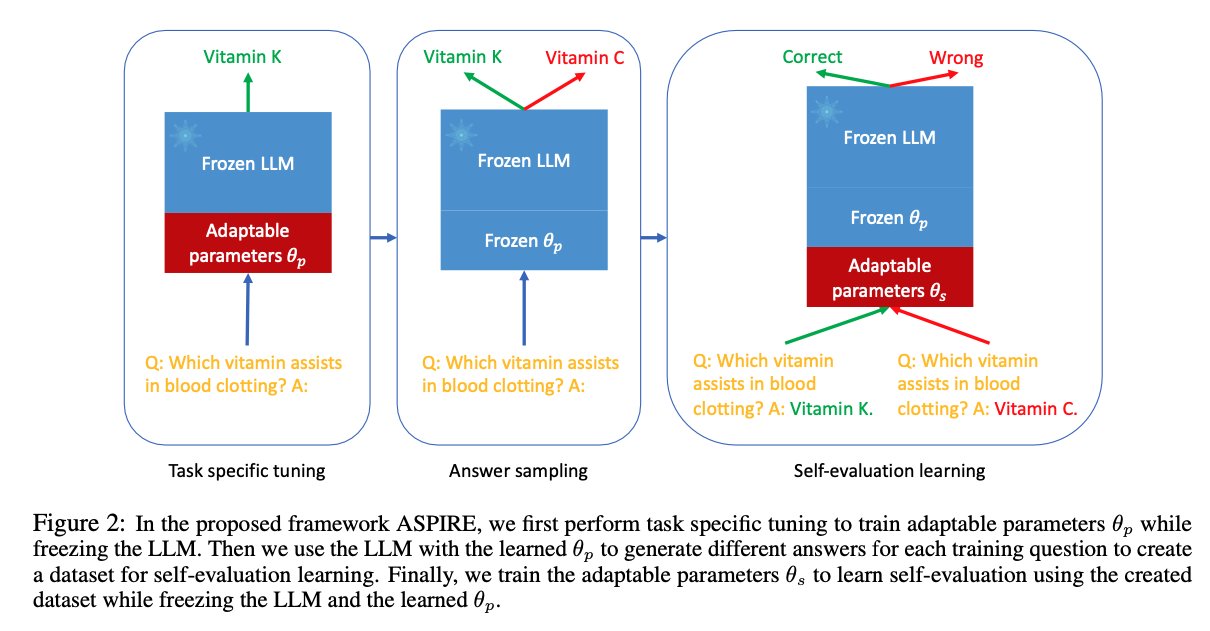
-
Start with LoRA
- model parameters is frozen
- adapter is added for fine-tuning and updated
- it improves prediction accuracy and likelihood of correct output sequences improves selective prediction performance!
-
Fine-tune LLM to learn self-evaluation
-
use to generate different answers for each example
-
supposing the decoding algorithm used to generate output sequences for is
where -
choose output sequences such that is maximal
-
use metric to determine is correct
i.e. if , it is correct -
use threshold different from for evaluation (choose sufficiently large so that the wrong outputs wouldn't be labeled as correct outputs)
-
after sampling high-likelihood outputs, tune only for learning self-evaluation ( and are frozen)
-
the training objective is
where is a set of 'correct' outputs containing the reference and correct outputs with highest likelihood from , same for (If doesn't have wrong output, add a default wrong output(e.g. empty string) to )
-
After training , obtain the prediction solving
-
Also, the self-eval score is defined as
-
Used Beam search decoding
-
Overall, the selection scoring function is
where is a hyperparameter
-
5. Implementation via Soft Prompt Tuning
- They could develop prompts that effectively stimulate self-evaluation
- it is possible to discover these prompts through soft prompt tuning with targeted training objectives
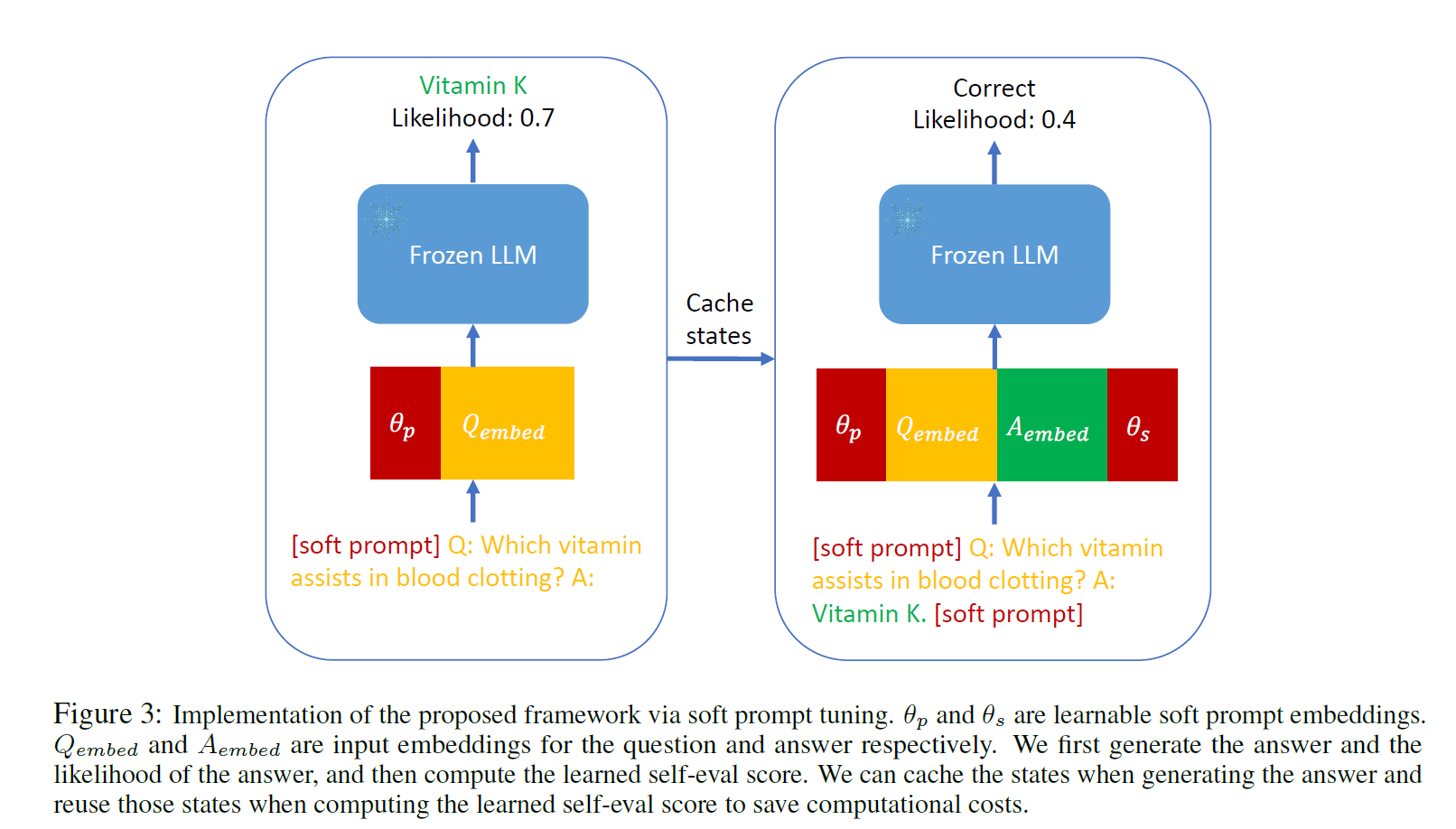
Soft Prompt Tuning
- given query
- get embedding of to form a matrix
- soft-prompts
- concatenate soft-prompts to query to form
Adapt to ASPIRE
- update with
- update with
- The Inference objective becomes
- The self-eval score becomes
Generation Pipeline
- obtain generated output and the likelihood for the output
- obtain self-eval score
- cache the states of first stage to reduce computational cost for second stage
Computational Complexity
- At test time :
- Predictive entropy and semantic entropy methods :
6. Experiments
- Use decoding algorithms that can sample different high-likelihood samples is important
- more training samples lead to enhanced performance
- 2k samples are enough to outperform the baselines without soft-prompt tuning
6.1 Setup
- free-form QA task : CoQA(zero-shot), SQuAD(zero-shot), TriviaQA (5-shot)
- used 50K examples subset
- OPT(350M, 1.3B, 2.7B, 30B), GPT-2(M, L, XL)
- pretrained LLM and trained model
- beam-search
- selection score with PPL, Predictive Entropy, Semantic Entropy, Self-eval, P(True)
- Rouge-L as the evaluation metric with relatively large (accepting wrong answer is more costly)
- Both stage of training and , 10 epochs with AdamW, batch 8, lr 0.01 and cosine lr scheduling
- for ASPIRE,
- beam search for
6.2 Results
Accuracy
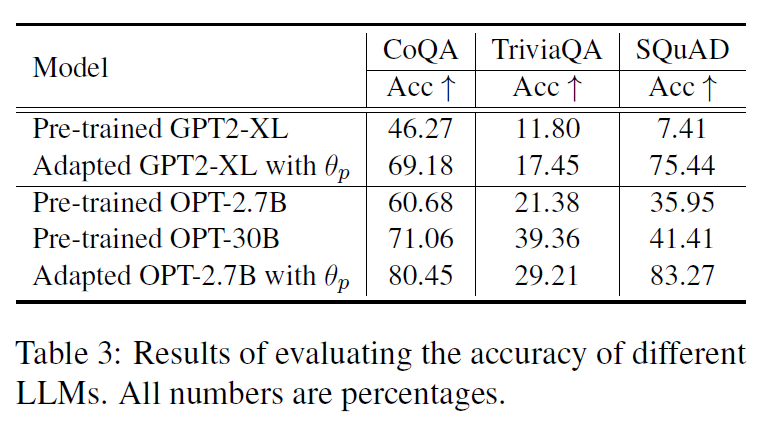
Methods to get selection score
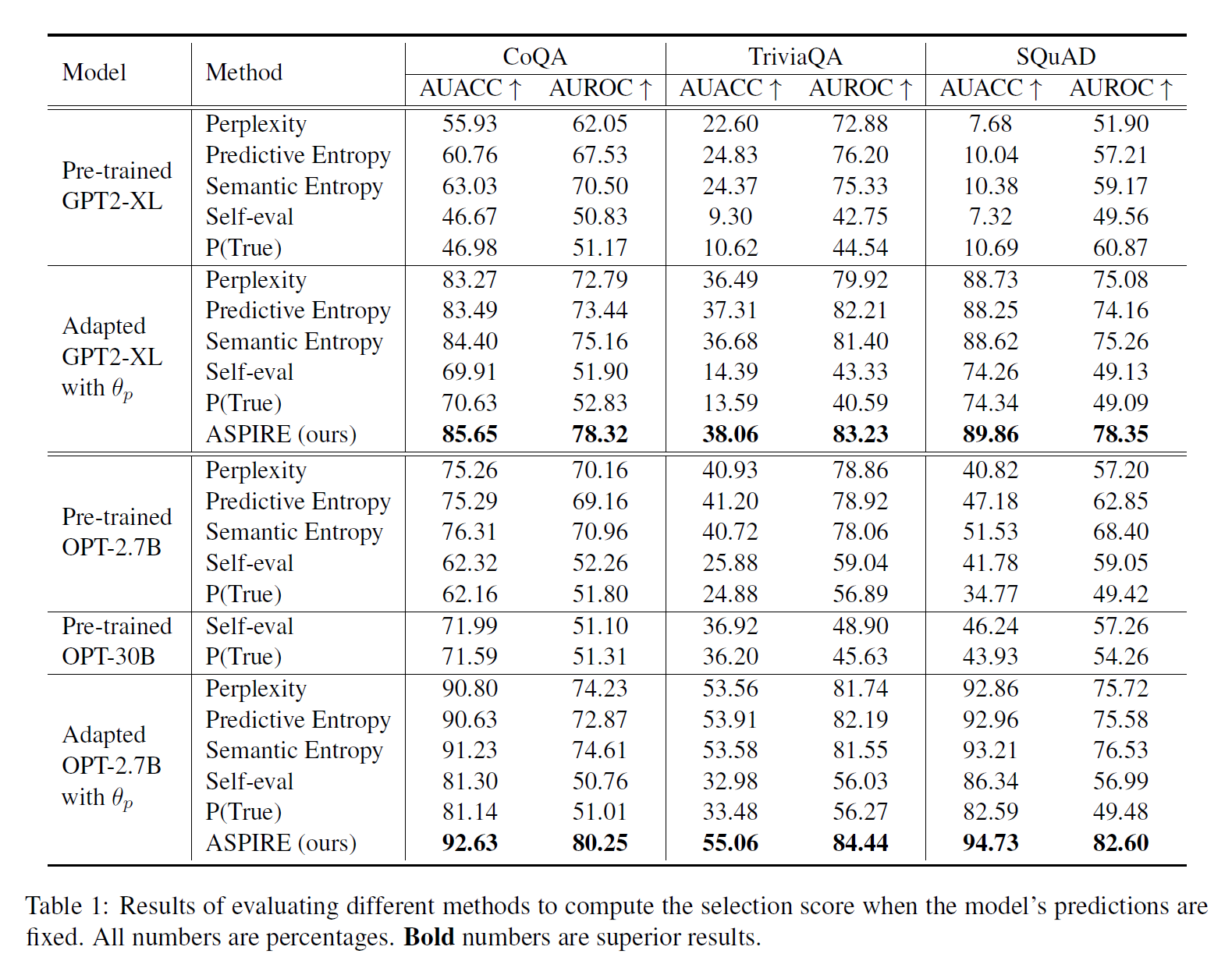
- After prompt tuning, other methods' AUACC is significantly improved as accuracy became better and PPL became more meaningful
- ASPIRE with OPT-2.7B significantly outperforms with Self-eval and P(True) with OPT-30B
- For Self-eval and P(True) method, the AUACC of OPT-30B is better than Adapted OPT-2.7B, it has much worse selective prediction performance
self-evaluation approach is not effective for high capacity LLMs
6.3 Empirical Analyses
The effect of
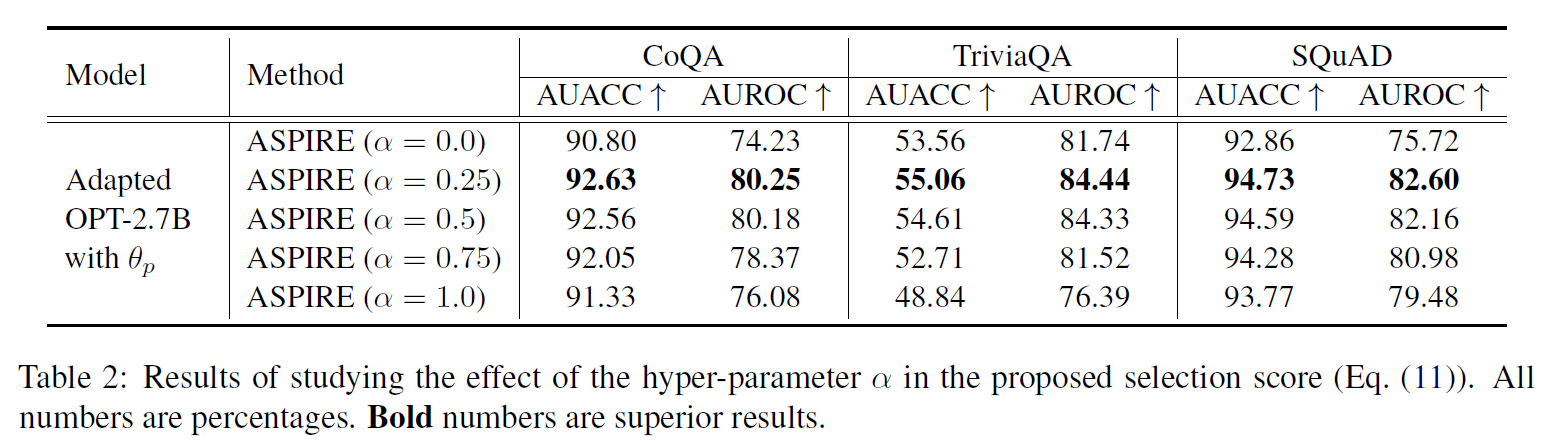
- is the best recipe for normalized likelihood and the learned self-eval score
- In practice, this value can be chosen based on the performance on the validation data
The choices of
- compared beam search and multinomial sampling
- used highest scoring beams as the answer list (beam search)
- tested temperature 0.1, 1.0, 2.0 for multinomial sampling

Training sample efficienty
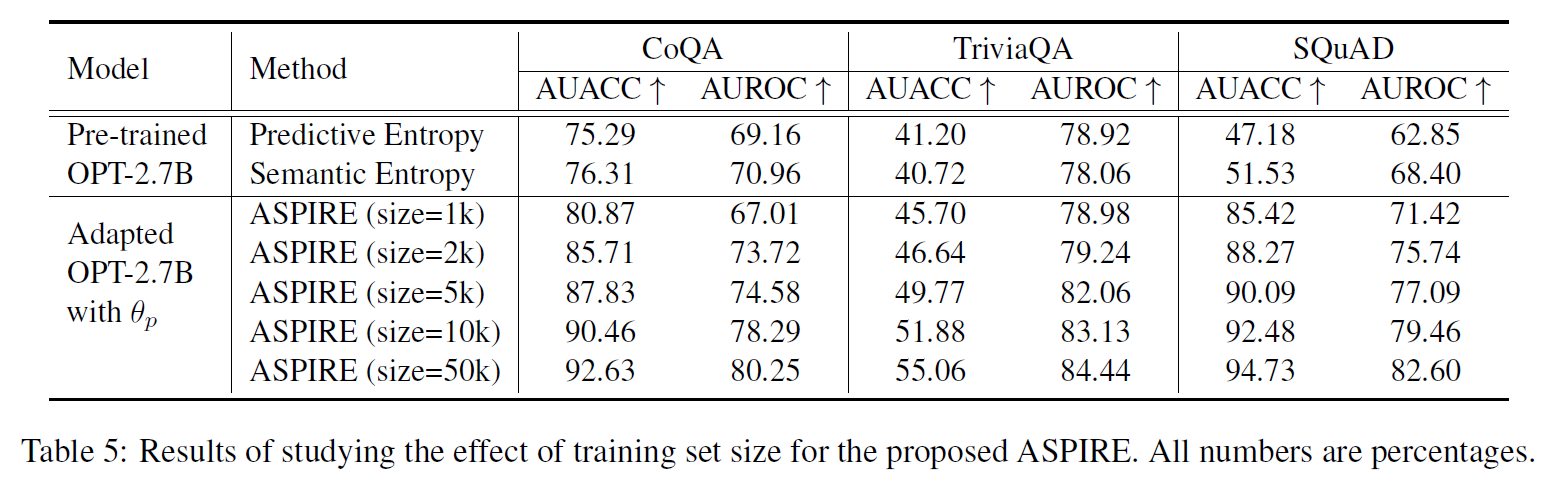
- Fixed the number of steps to be 50K
- ASPIRE can significantly improve selective prediction performance even with limited number of training samples
7. Conclusion
- Adaptation with self-evaluation to improve selective prediction in LLMs
- Soft prompt tuning
- Implement via other PEFT approaches and adapt to larger LLMs (Future work)
- Didn't tested with larger and stringest LLMs (computational constraints)
8. Comment
단순히 프롬프트로 신뢰도를 찍어내는 것이 아니라, 나름의 계산과 Learning 기반으로 신뢰도를 얻어낼 수 있는게 좋았음. 다만 테스트한 모델이 좀 오래되어서, 최근의 sLLM으로도 가능한지 의문

Hello, maybe you can try to reproduce this paper. I am very interested in this paper, but unfortunately there are some details that I don’t quite understand. By the way, your article is very well written and concise.