1. Introduction
- Intruducing a method for detecting LLM-generated text using zero-shot setting (No training sample from LLM source)
- outperforms all models with ChatGPT detection
- As it is zero-shot nature, it can spot multiple different LLMs with high accuracy
- Prior research (Turnitin) fixated strongly on ChatGPT
- More sophisticated actors use a wide range of LLMs beyond just ChatGPT
- Binoculars works by viewing text through two lenses
- compute the log perplexity of the text in question using an "observer LLM"
- compute all the next-token predictions that a "performer LLM" would make and compute their perplexity according to the observer
- If the string is written by a machine, the perplexities would be similar.
2. The LLM Detection Landscape
-
Spam and Fake news analyzing all benefit from signals that quantify whether text is human or machine-generated
-
Due to the rise of the Transformer models, primitive mechanisms became useless to record or watermark all generated text
-
Post-hoc detection approaches without cooperation from model owners
- Fine-Tuned pretrained backbone for the binary classification task (adversarial training, absentation)
- Linear classifier on top of frozen learned features allowing for the inclusion of commercial API outputs
-
Using statistical signatures that are characteristic of machine-generated text
- requires none or little training data
- easily adapted to newer model families
- based on perplexity, perplexity curvature, log rank, intrinsic dimensionality of generated text, n-gram
-
Detection has limitation
- Fully general-purpose models of language would be, by definition, impossible to detect
- Given sufficient examples, the text by model close to the optimum is technically detectable
- In practice, the relative success of detection provides evidence that current language models are imperfect representations of human writing (Detectable!)
-
How do we appropriately and thoroughly evaluate detectors?
- accuracy on test sets, AUC of classifiers are not well-suited for the highstakes question of detection
- Only detectors with low false positive truely reduce harm
- detectors are often only evaluated on relatively easy datasets that are reflexive of their training data
3. Binoculars: How it works
- perplexity and cross-perplexity (the next token predictions of one model are to another model)
3.1 Background and Notation
- string
- a list of token indices
- tokenizer
- -th token ID
- vocab
- language model
- number of tokens in ,
- Define logPPL as the average negative log-likelihood of all tokens in the given sequence
- This logPPL intuitively measures how surprising a string is to a language model
- As it is used as a loss function, the models are likely to score their own outputs as unsurprising
- Define Cross-Perplexity as a average per-token cross-entropy between the outputs of two models
3.2 What makes detection Hard? A primer on the Capybara problem
- LLM tends to generate text that is unsurprising to an LLM
- As humans are different from machine, human PPL is higher according to an LLM observer
- When it faces hand-crafted prompts, this intuition breaks
- prompt "1, 2, 3, " results in "4, 5, 6" which has very low PPL
- But the prompt like "Can you wirte a few sentences about a capybara that is an astrophysicist?" will yield a response that seems more strange High PPL ("capybara", "astrophysicist")
- in the absence of the prompt, LLM detection seems difficult and naive perplexity-based detection fails

3.3 Our Detection Score
- Binoculars solves the capybara problem by providing a mechanism for estimating the baseline PPL induced by the prompt
Motivation
- LM generates Low-PPL text relative to humans PPL Threshold classifier
- Capybara problem prompt matters Cross-PPL
- Cross-PPL measures the tokens are surprising relative to the baseline PPL of an LLM acting on the same string
- Expect the next-token choices of humans to be even higher PPL than those of the machine Normalize the observed PPL by the expected PPL of a machine acting on the same text
- The numerator is simple PPL (how surprising a string is to )
- The denominator measures how surprising the token predictions of are when observed by
- Expect human diverge from more than diverges from
- The Binoculars score is a general mechanism that captures a statistical signature of machine text
- It is also capable of detecting generic machine-text generated by a third model altogether
- Connection to other approaches
- Contrastive Decoding : generate high-quality text by maximizing the difference between a weak and a stron gmodel
- Speculative Decoding : Use weaker models to plan completions
- Both are working when pairing a strong model with a very seak model
- But Binoculars works well when pairing very close two models (use Falcon-7B as and Falcon-7b-instruct as )
4. Accurate Zero-Shot Detection
4.1 Datasets
- Ghostbuster : Writing Prompts, News, Student Essay datasets (Humans vs ChatGPT)
- Drew human samples from CCNews, PubMed, CNN and generated machine text by LLaMA-2-7B and Falcon-7B
- Peel up first 50 tokens of human sample and used it as a prompt to generate up to 512 tokens
- removed human prompt from the generation
- Orca dataset to check the reliability of the proposed method for instruction-tuned models
4.2 Metrics
- Binary classification metrics
- ROC Curve
- AUC
- In high-stakes detection settings, false positive is the most concerning harms (human text is labeled as machine's)
- TPR (True-Positive rates) at FPR (False-Positive rates)
- standard FPR threshold of 0.01%
- when the FPR is below 1%, AUC and TPR@FPR are often uncorrelated
4.3 Benchmark Performances
Ghostbuster (vs ChatGPT)
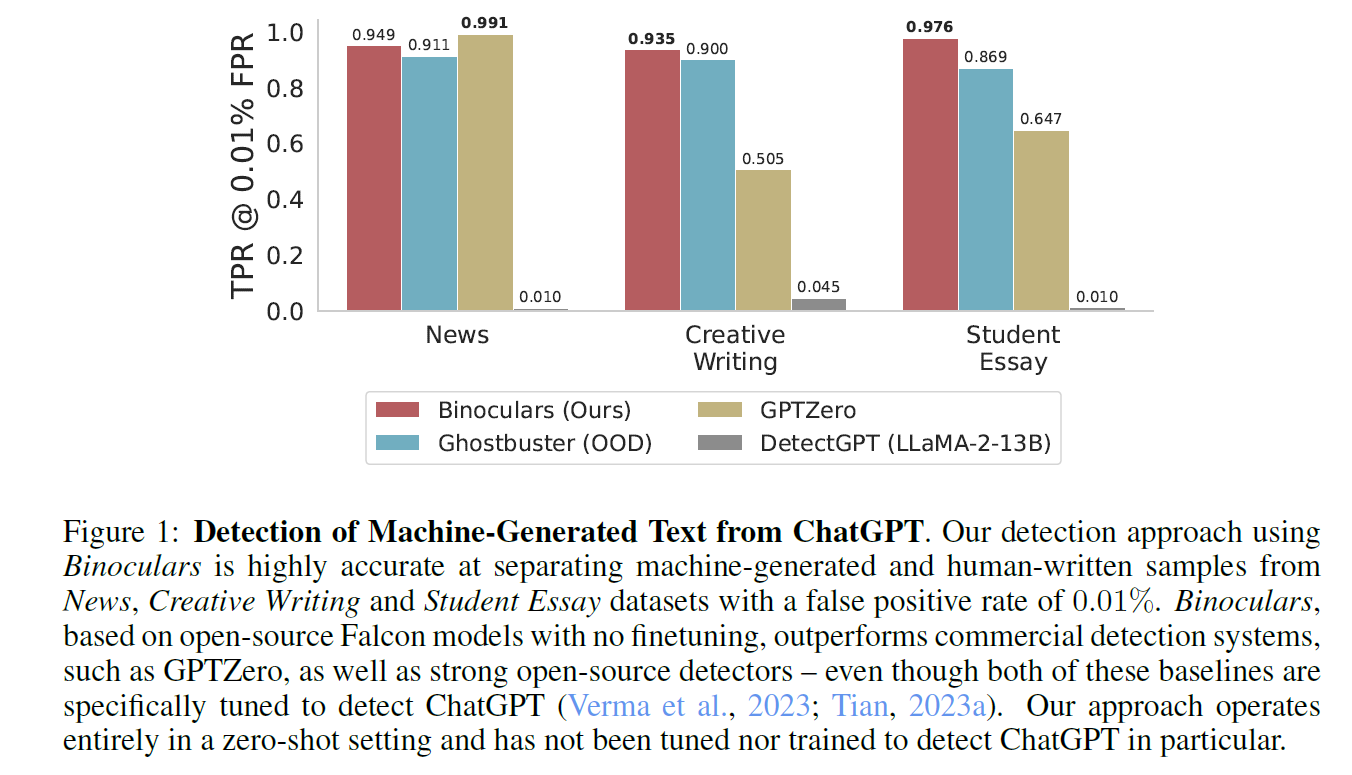
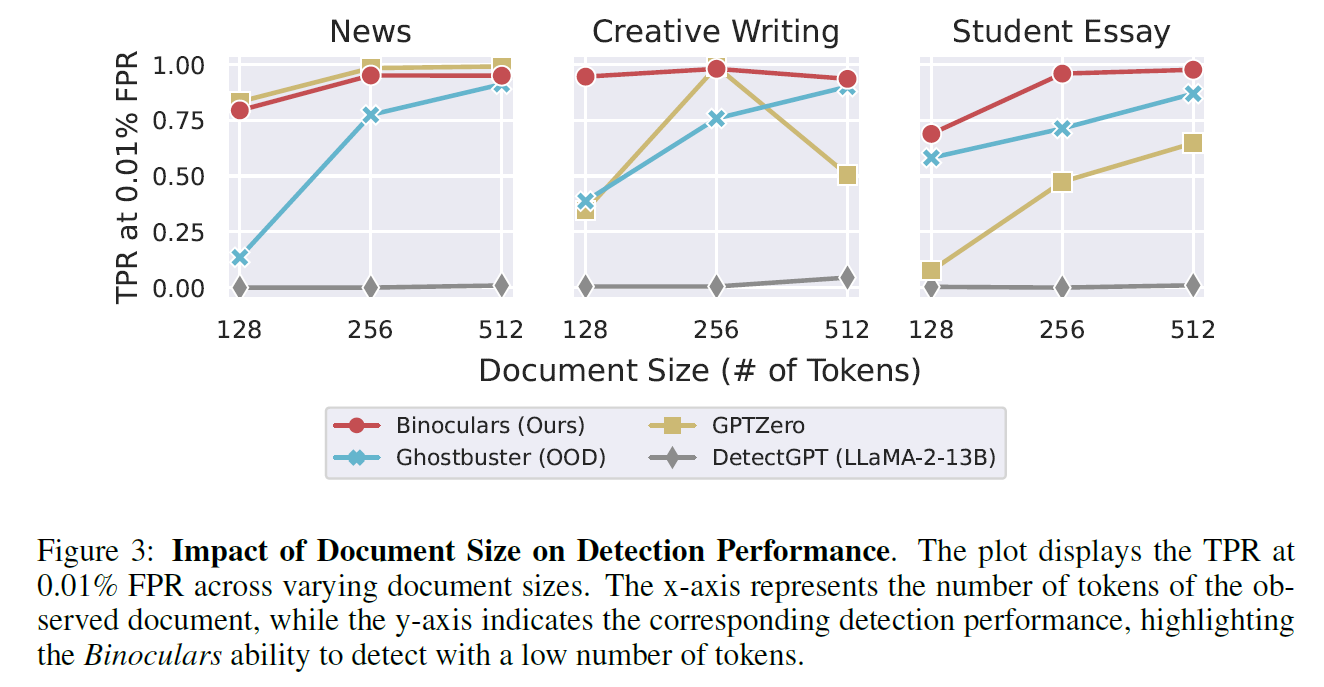
- outperforms Ghostbuster in "out-of-domain" settings
- Ghostbuster and Binoculars both have a property that they are getting stronger given more information
- Binoculars are clearer in the few-token regime
Open source LMs (vs LLaMA-2 and Falcon)
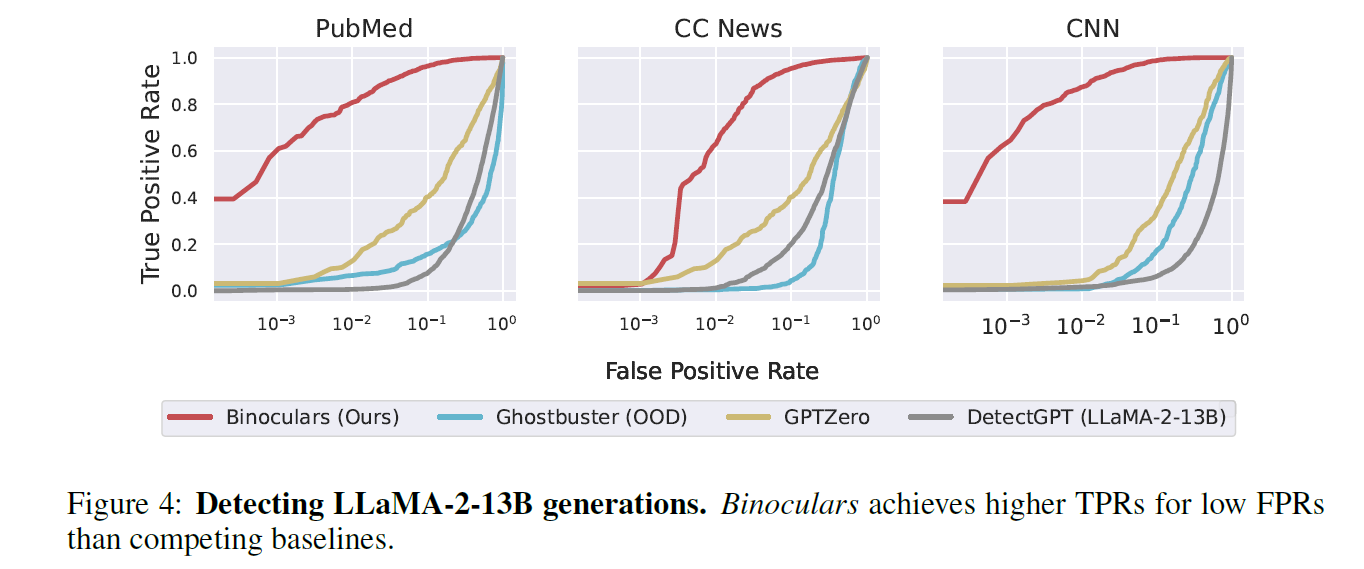
- Ghostbuster fails to detect other Open-source models generation
5. Reliability in the Wild
5.1 Varied Text Sources
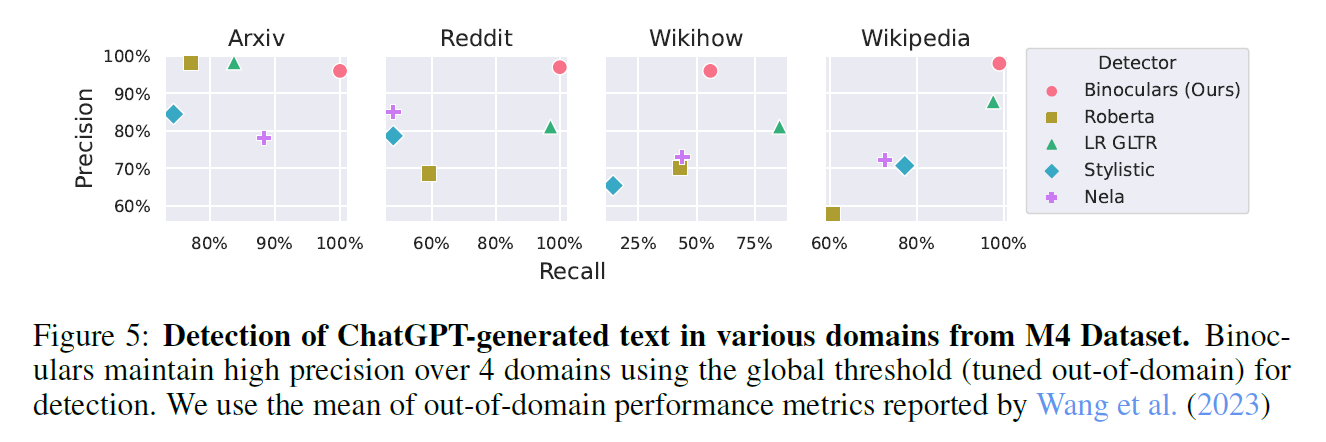
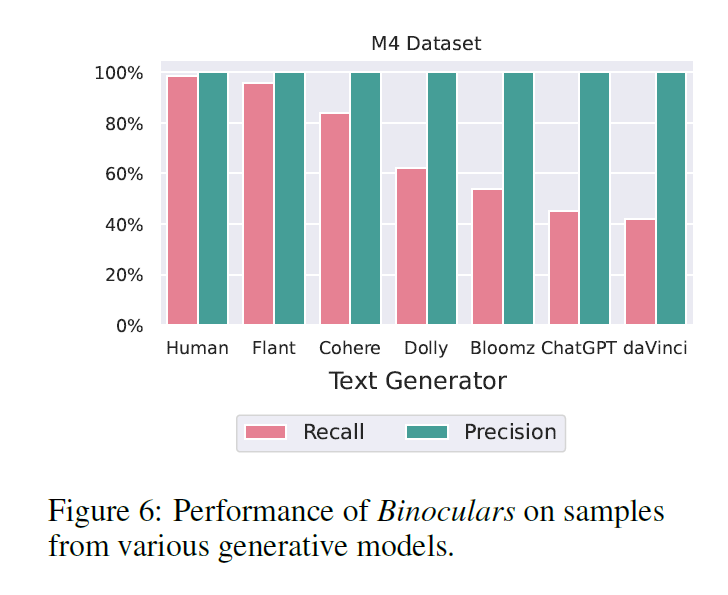
- used M4 detection dataset
- Binoculars generalizes across domains and languages
- LR GLTR : Logistic Regression over Giant Language Model Test Room
- NELA : News Landscape Classifiers
5.2 Other Languages

-
Evaluating on Binoculars on samples from languages that are not well represented in Common Crawn data
- FPR remains low but machine text is classified as human (poor recall)
- Binoculars is a machine-text detector to detect whtehre text may have been generated from a similar language model
- for Falcon, it has low capacity with low-resource languages. Then ChatGPT's text is unlikely to be machine-generated according to this score
-
Stronger multilingual pair of models would lead to make Binoculars more effietive to detect ChatGPT generated text in that language
FPR on text written by non-native speakers
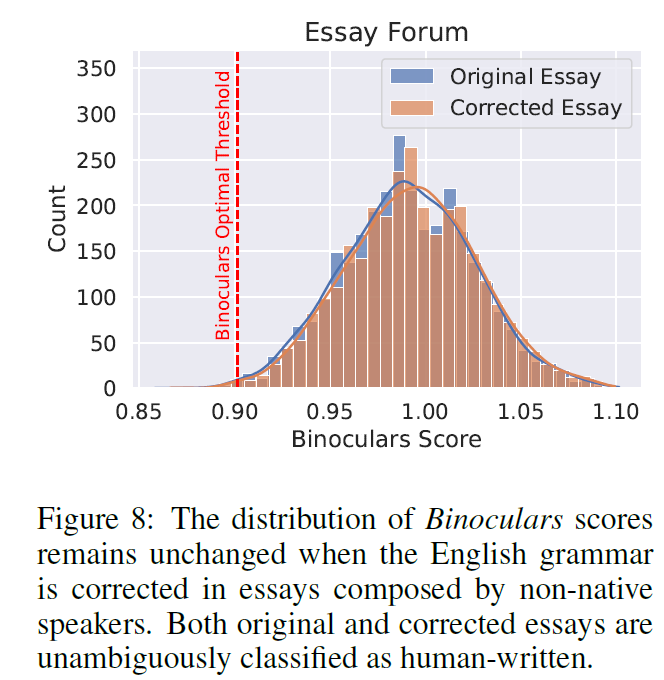
- LLM detectors are inadvertently biased against non-native English speakers classifying their writing as machine-generated
- Analyzed EssayForum (ESL student's academic writing) to make original essay and grammar-corrected version
- Binoculars is insensitive to this type of shift
5.3 Memorization
- Highly memrized examples are classified as machine-generated in PPL based detection (famous quotes)
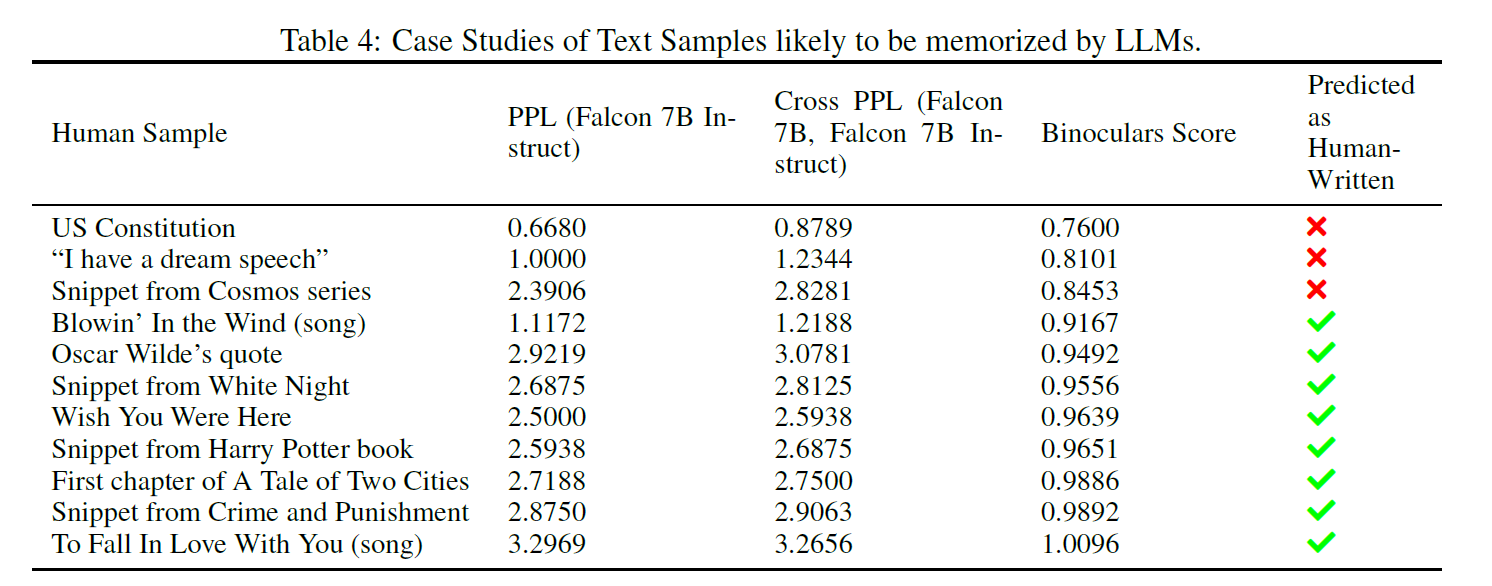
- Memorized text is both written by human and machine
- Both behavior is acceptable (plagiarism detection or removal of LLM-generated text from a training corpus)
5.4 Modified Prompting Strategies
-
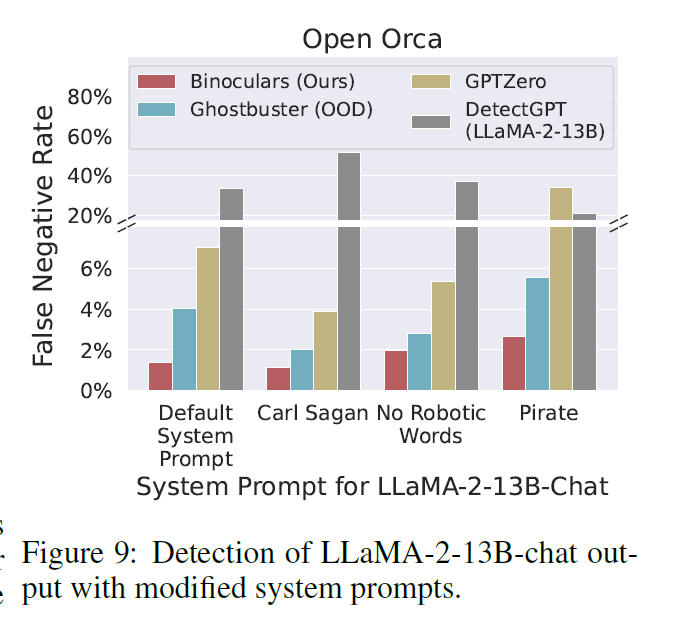
For OpenOrca set, Binoculars detects 92% of GPT-3 sampels and 89.57% of GPT-4 samples

-
Simple detection schemes are fooled by this changes of prompt
-
This is not affecting the performance of Binoculars score
5.5 Randomized Data
- Test arbitrary mistakes, hashcodes, or other kinds of random string
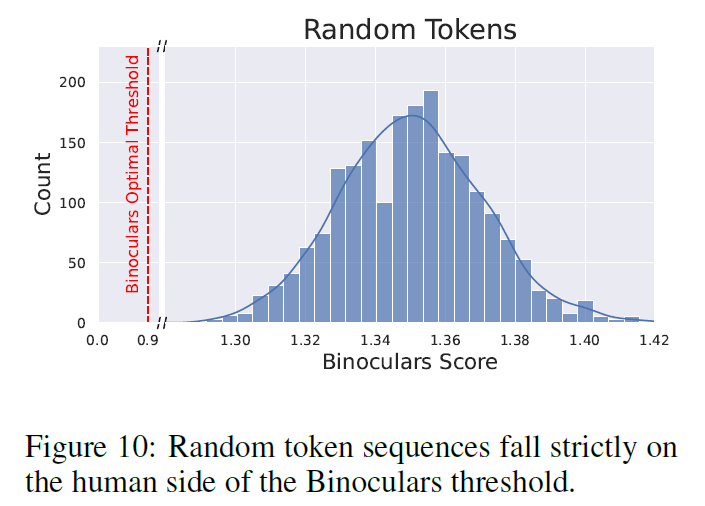
- Confidently scores them as human
- LLMs usually don't generate such things
6. Discussion and Limitations
- a method for detecting LLMs in Zero-Shot case
- Transferable detector words in zero-shot setting
- This transferability cames from the similarity between modern LLMs (Transformer!)
- Due to VRAM, they didn't check larger models (30B+)
- Didn't consider explicit efforts to bypass detection
- Non-conversational text domains are not included
7. Comment
단순 PPL이 아닌 Cross-PPL을 이용해 상대적으로 모델의 생성을 체크하는 방법. 그런데 모델 두 개를 올리려면 리소스 사용량이 꽤 많이 필요할듯.

Exploring the detection of machine-generated text with zero-shot techniques, as discussed in the linked blog, is a fascinating topic. It's crucial to differentiate between human and AI-written content, especially in academic contexts where authenticity is paramount. In my own experience, when I needed to ensure the originality and quality of my work, I found the reviews on https://99papers.com/reviews/ extremely helpful. This resource provided insights into various services, helping me choose the right tools for checking and improving my submissions. It’s a great starting point for anyone looking to enhance their understanding and management of textual content.