
..?
1. Introduction
-
Transformers require memory and compute to predict the next token of a sequence of length (using Flash Attention!)
-
Attempts to make similar architectures but with memory to predict each token S4 or Mamba / RNN / models that can trained in parallel like linear attention / parallel RNNs
- Say all models as GSSM (Generalized State Space Models)
-
Resent work says GSSM's performance but it is not clear what these models sacrifice for efficiency
- One particular capability that is sarificed is the ability to retrieve and repeat parts of the input context
-
Theoritical analysis of copying task
- Transformer can copy strings of length that is exponential in the number of heads of the transformer
- Transformer implements a 'storage' mechanism and retrieval of sequences of n-grams
- GSSMs cannot accurately copy strings with more bits than the size of the latent state
-
In practice, large GSSM may have enough capacity to represent the entire input in the latent state
- Transformers are both much more efficient at learning to copy and to generalize better to longer inputs
- Copy algorithms learned by Transformers are based on n-grams to perform where to copy from
2. Theory: Representational Capaciy
2.1 Setting
-
dictionary which contains alphabet tokens
-
seq2seq model
- input as the prompt
- as the generated 'answer'
-
sequence to token model
- it naturally defines by autoregressive inference
- for every input sequence , define recursively and let
GSSM
-
Finite set is a state space
-
the number of bits required to encode the states of as
-
GSSM is a sequence model defined by an update rule and some output function
- Let be some initial state
- Given sequence , the state of model at iteration is denoted by
- the output token is denoted by
- The recursive process is
-
Note that for any sequence model, there are two types of memory considerations
- Input-Independent Memory - parameters
- Input-Dependent Memory - activations
-
GSSM definition constraints the input-dependent memory
-
It doesn't restrict in any way the amount of input-independent memory or the runtime of state updates
-
Leaving all other considerations unconstrained shows the lower bownd on the state space memory
Transformers
-
input length
-
dimension
-
input tokens
-
an attention head is parametrized as
-
-
-
the output of the head at token is
-
with attention heads, the full dimension should be
-
embedding
-
MLP
-
embedding and MLP is applied on the token level
-
Attention-block is a set of heads applied in parallel
-
transformer-block is an attention-block floowed by an MLP on the concatenated output of heads
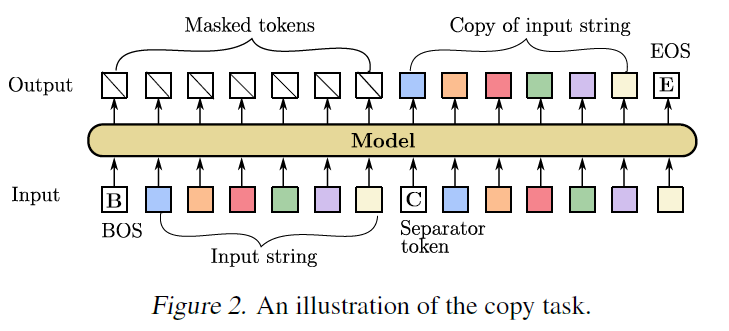
The Copy Task
- Add two special token <BOS> and <COPY> to
- A length- copy distribution over generates strings of the form "<BOS>, , <COPY>" where
- For some seq2seq model , denote the error of on a copy distribution
2.2 Transformers can copy inputs of exponential length
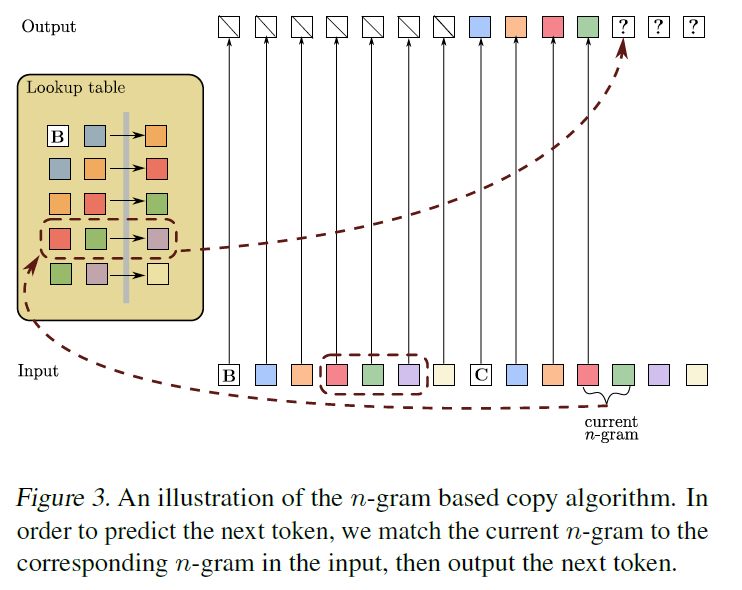
Construction : Hash-Based Copying
- Hash sequences of tokens
- At each iteration of the auto-regression attend to the previous occurrence of the most recent -gram and output the succeeding token

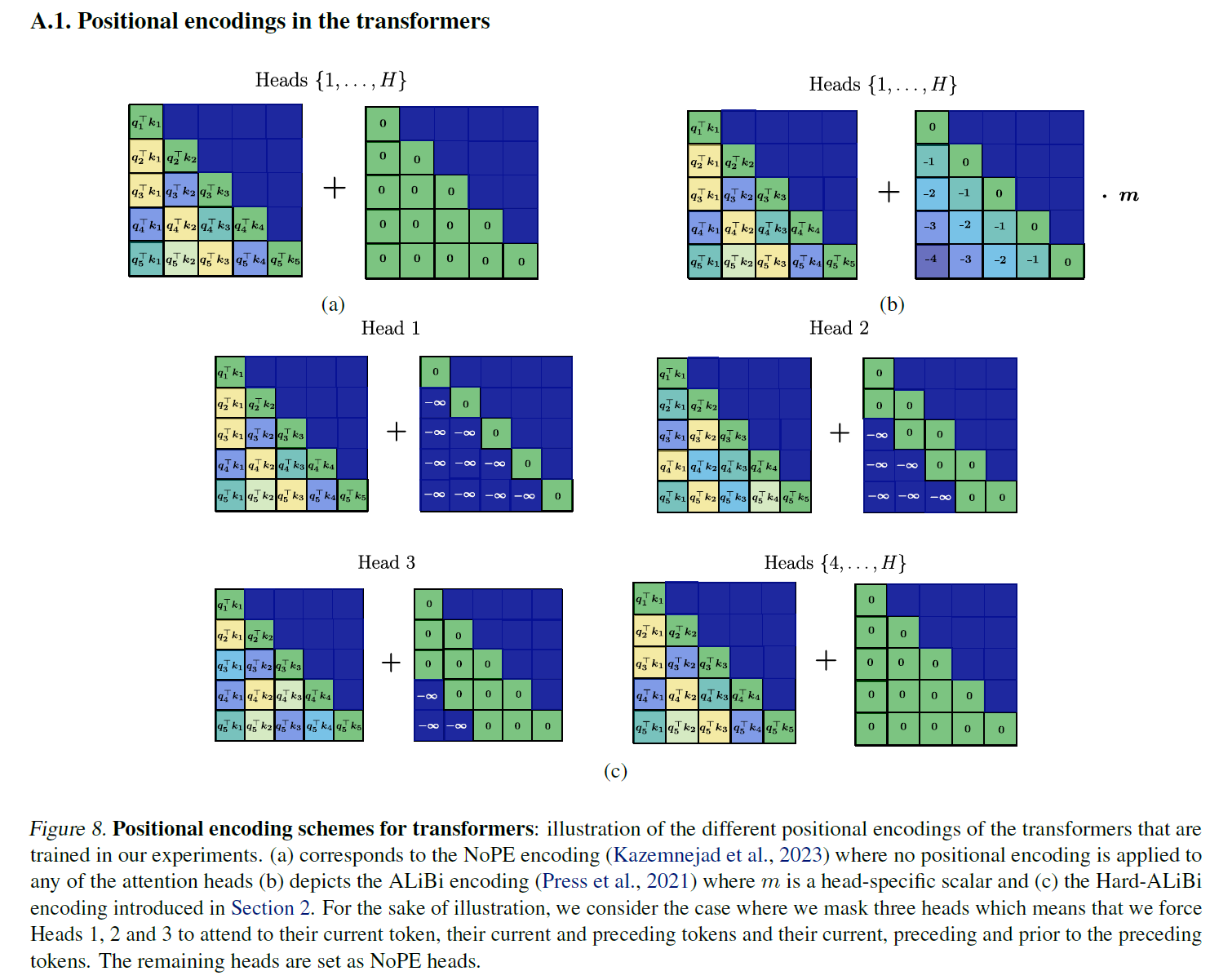
Positional Embedding: Hard-ALiBi
-
To perform the hashing described in the algorithm, it is necessary to leverage local positional information to define a hash and apply it globally on the entire input use Hard version of ALiBi
-
Alibi : biases the attention scores with a penalty that is proportional to their distance ( is a head-specific slope fixed before training)
-
add a bias to the -th attention head
- Allow different head with different and also allow (softmax attention with no PE)
Guarantees
- The copy algorithm can perfectly copy the input sequence, as long as there are no repeated -gram patterns in the input
- Then the error of the algorithm is
Theorem 2.3.
For all , there exists a depth-2 transformer of dimension s.t. for all and for any copy distribution ,
- The probability of repeated -grams quickly decays when increases
- For the uniform distribution over sequences, thie probability decays exponentially witn
Lemma 2.4.
Let be the copy distribution generated by sampling from the uniform distribution over the non-special (alphabet) tokens. Then
- By combining those, we get that Transformers can copy sequences of tokens drawn from the uniform distribution using a number of params that depends only logarithmically on the input sequence length
Corollary 2.5.
Fix some and some , there exists a depth-2 Transformer of dimension s.t. for the uniform copy distribution ,
- This doesn't limit the precision of the parameters of activations, but it holds for finite-precision transformers, using bits
2.3 State Space Models cannot copy inputs beyond memory size
- GSSMs cannot copy uniform input sequences unless the capacity of their state space grows linearly with the sequence length (To be able to copy, the model needs to store it in state space)
Theorem 2.7.
Fix some GSSM over state space . Then for all , for the uniform copy distribution , the model has error
Corollary 2.8.
Fix some then every GSSM with state space s.t. has error for uniform copy distribution
- The Input-dependent memory of Transformers grows linearly with the sequence length (less memory-efficient than GSSM)
- Transformers are almost optimal in terms of input-dependent memory (at least copying)
- Thm 2.3. says that there exists a transformer which can copy inputs of length using input-dependent memory and it is optimal by Corollary 2.8.
3. Learning to Copy
- Above results may not be observed in practice
- It's not clear that transformers can indeed learn to copy from examples
- In practice, GSSM may use a large latent state memory so that this bounds only hold for very long sequences of tokens (Also, it may not learn to do so)
3.1. Experimental Setup
- Transformer and Mamba 160M
- LSTM 40M
- 64 Batch
- 10 batches of 128 examples for test
- token space size is 30 and normally
- All strings are sampled uniformly
- sample the length of the sequence
- independently sample each position of the string from
- pack the context with i.i.d. sequences during training
- fill the context with multiple independent samples of task
- Positonal Information
- RoPE
- NoPE (No Positional Information)
- Hard-ALiBi
3.2. Data Efficiency on the Copy task
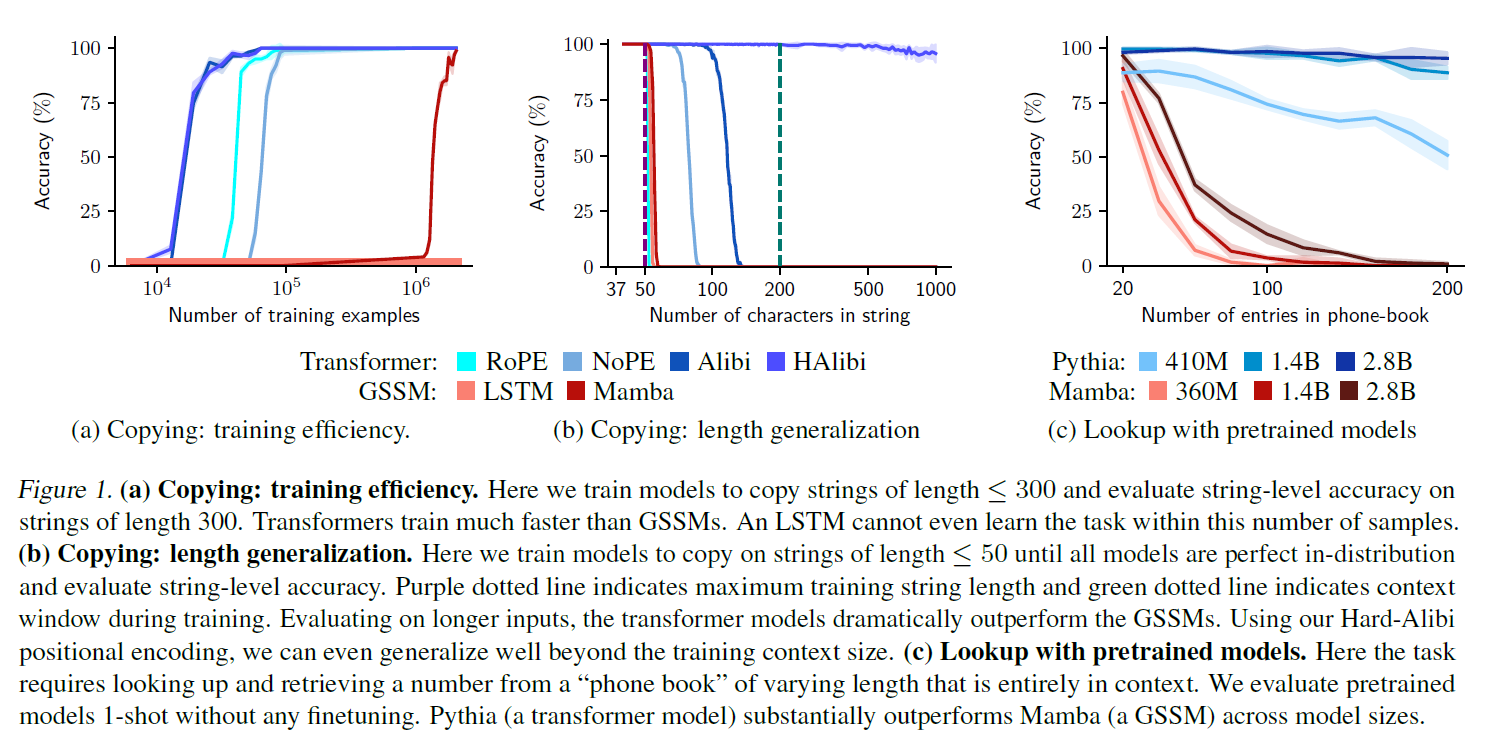
- Model gets an input of tokens followed by separator token
- record the string-level accuracy
- sharp change is due to the log-scaled x-axis and string-level accuracy as a y-axis
- String-level Accuracy
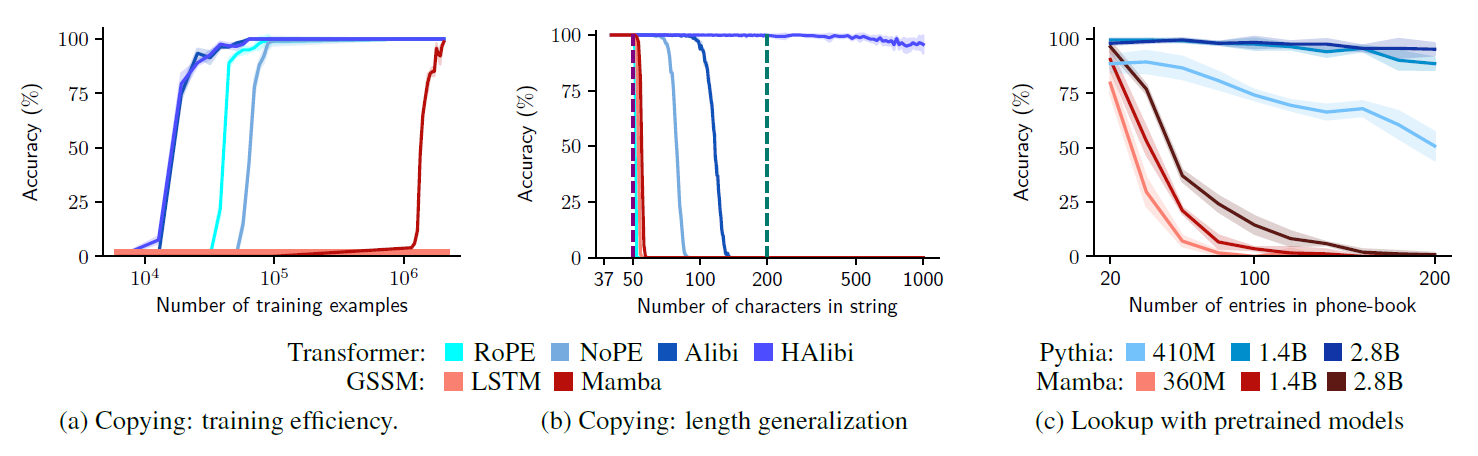
- Character-level Accuracy

3.3 Length Generalization on the Copy Task
-
Test to generalize out-of-distribution
-
Understand which function the model has learned
- model has truly learned the "correct" copy operation vs it just learned to copy sequences of the particular size it was trained on
-
Trained all models on sequences of tokens test them up to 100 tokens (string-level accuracy)
-
Transformers shows better generalization to longer input compared to GSSMs
- GSSMs' performance drops to near zero
- ALiBi and NoPE dramatically outperform the RoPE
- Sinusoidal embedding of RoPE creates a more dramatic change thatn the decay of ALiBi or NoPE
-
Using Hard-ALiBi in sequence length less than 50 shows almost perfect generalization up to 1000 tokens
3.4. Transformers learn to use n-gram hashing
-
To test whether the transformer uses the storage mechanism and retrieval of n-grams
-
Train Hard-ALiBi Transformer on the copy task with a dataset contains duplicate n-grams
-
Draw uniform sequences of tokens and randomly replace some n-gram with another n-gram that already appears in the sequence (each example always have two copies of n-gram)
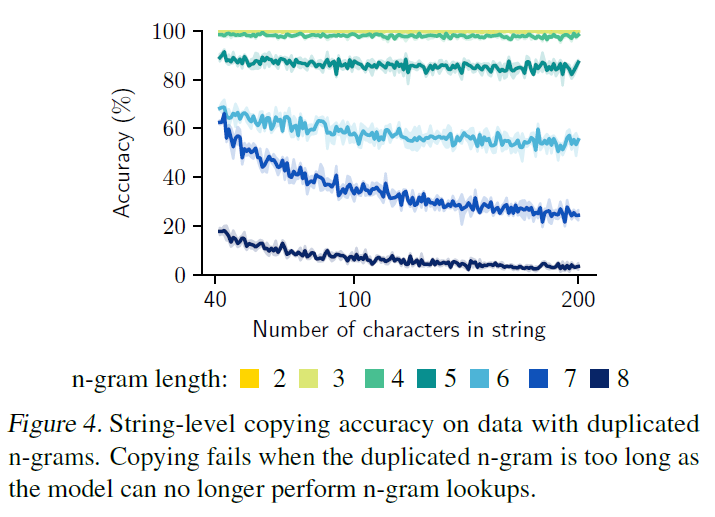
- It seems Transformer relies on something like 5-gram retrieval to do the copy task
3.5. GSSMs cannot arbitrarily retrieve from context
-
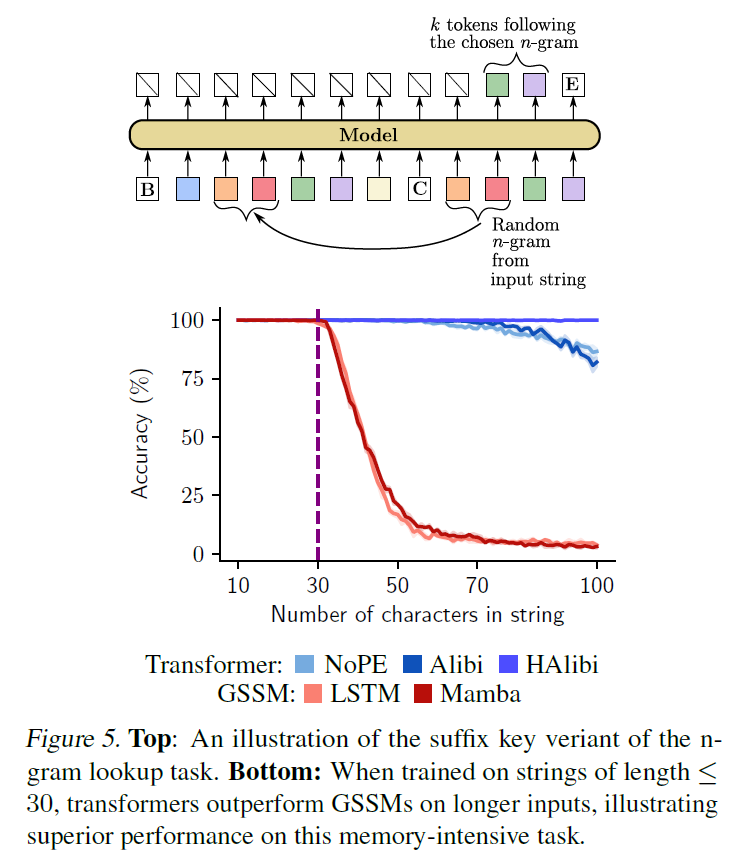
n-gram lookup task : the model should use given n-gram as a key to loop up k-token key that follows the query
- suffix key and prefix key
- assess length generalization
-
Suffix key version
- given sequence of input tokens, separator, n-gram from the input sequence
- need output sequence of tokens following the chosen n-gram
- it requires the model to be able to 'store' the context to find the correct key
- train all models on sequences of at most 30 tokens
- Transformers perform well
- Transformers learn to n-gram retrieval and storage
-
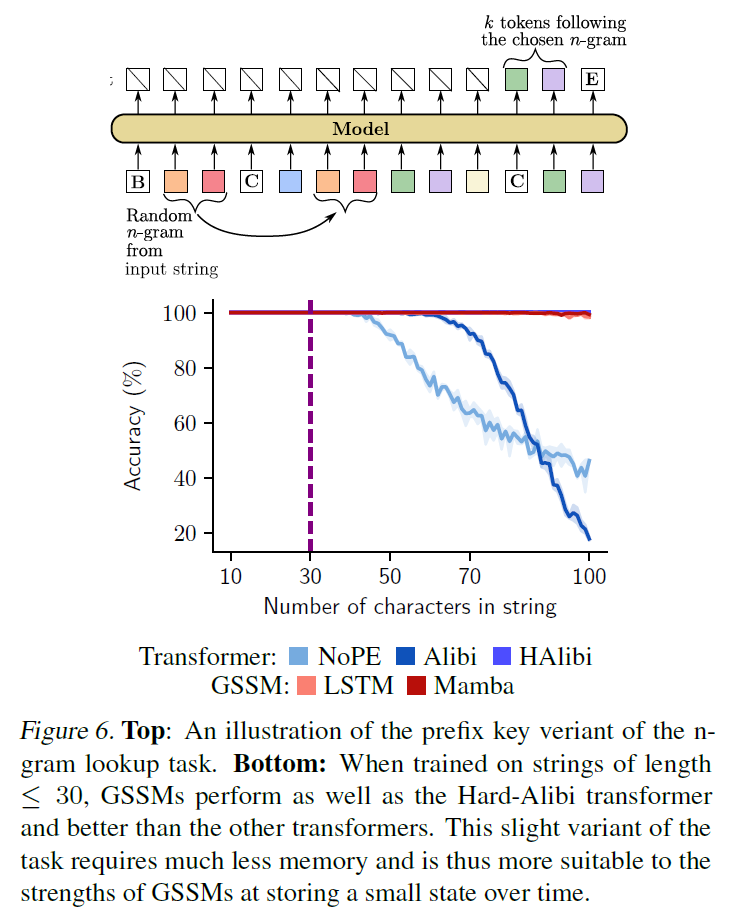
Prefix key version
- provide n-gram key at the beginning and then the full sequence
- model doesn't have to store the entire input as it can find the key on the fly
- good for the GSSMs since they can write the key in to the state and then ignore inputs that don't match
- GSSMs achieved almost perfect (outperformed NoPE and ALiBi but Hard-ALiBi)
- This may be an issue where positional embedding make it more diffecult to perform the hashing lookup over a long distance
- GSSM is memory limited but effective when the tasks only require a summary of the inputs
4. Pre-trained Models
- pretrained Transformer, GSSM
- copying long strings, retrieval and few-shot QA
- Transformer outperforms GSSM even GSSM shows lower PPL
4.1. Setup
-
Pythia transformer models 410M ~ 2.8B
-
Mamba with similar size
-
Pretrained on Pile, used same tokenizer
-
Copy based task / Information Retrieval (selective copy)
-
String-Level Accuracy
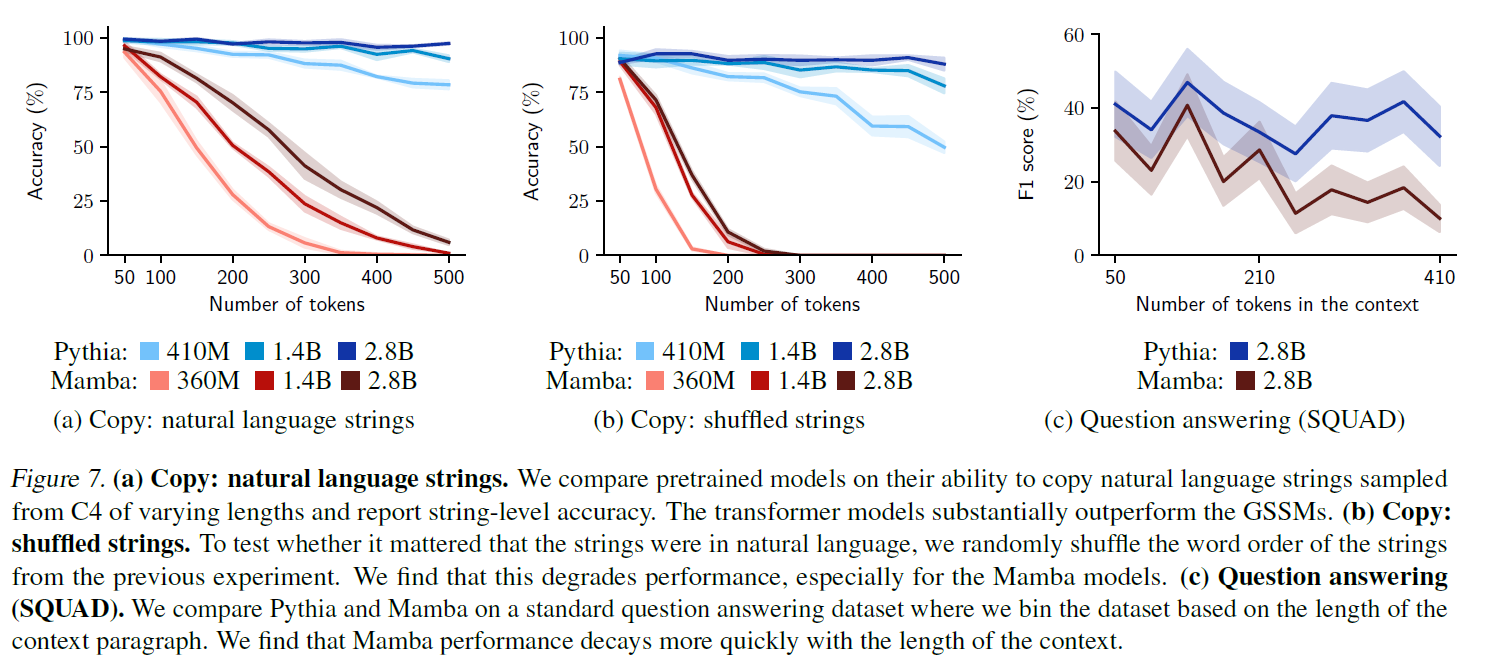
4.2. Copying the input text
- Transformers > GSSM
- Random sample from C4 dataset
- two copies of sampled string + first word of the string complete the third copy
- Unlike random string, natural text can often be compressed so that the model use lower memory to copy
- When the input is more difficult to compress, GSSM suffers due to its state size
4.3. Retrieval from the input context
-
Phone-book Lookup
- provide a synthetic phone-book to the model ans ask it to return the phone number
- randomly sampling names and phone number
- two-shot examples and question for phone-number
- Transformer (410M) > GSSM (2.8B) when
-
QA
- 2.8B Mamba and Transformer on SQuAD
- provided single demonstration of a QA pair with same text
- Mamba degrades more quickly with the paragraph length
5. Discussion
-
Transformer > GSSM at copying from their input text
-
SSM have many advantages over transformers
- The memory and computational complexity doesn't increase with the input length good for long context
- Better at tracking state variables across long sequences to make long consistent text
- Similar to Human brain
-
Future work is needed to make hybrid architectures of SSM and attention-like mechanism to enhance retrieving ability
- Humans have very limited memory but can translate entire novels if we allow look back at the text
6. Comment
제목이 자극적이었음. Retrieval 부분에서 Transformer의 성능을 증명했음. 다른 분야보다도 텍스트 관련해서는 이 점 때문에 SSM의 도입이 쉽지는 않을듯
