1. Introduction
- Deep Learning has focused on interpretable digital media files - text, images, audio
- Text played central role in conveying human intelligence and has led to the emergence of LMs
- LMs tokenize text and predict next token so that it can comprehend human language and intellegence
- Recent advancements extend tokenization beyond text
- These deep learning models overlooks the omnipresent native binary data in the digital world
- Next-Byte Prediction will allow the models to truly understand and simulate all activities in the digital world
- It has practical benefits in cybersecurity, computer diagnostics, data compression and even for reverse-engineering a software's source code from binary representation
- bGPT : model for binary data processing and digital world modelling by next byte prediction
-
directly interpreting and manipulating binary data
-
two-fold advantages
- Interpreting Digital System
- Unified Modelling
-
- Experiment in two areas
- well-studied tasks (generative modelling, classification)
- relatively underexplored tasks intrinsic to binary-native operations (data conversion, CPU state modelling)
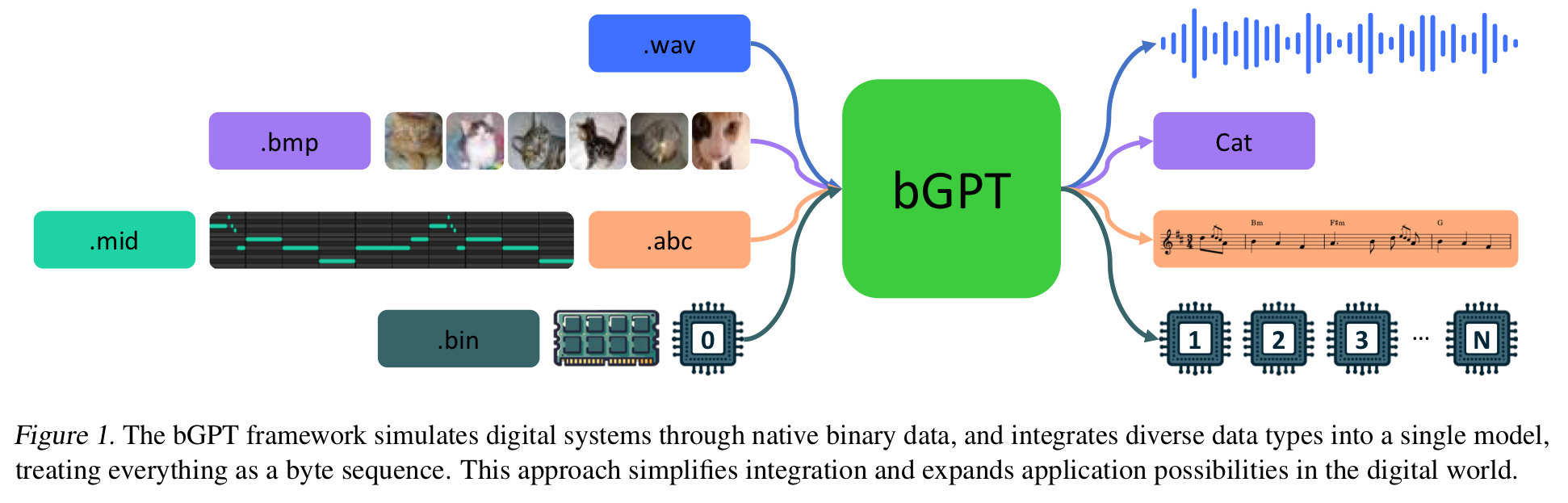
2. Background
2.1 Language Models
-
Text Models
- LSTM-based to Transformer-based
- Tokenization plays a fundamental role (breaking down into words or subwords)
- GPT models pretrained with self-supervised learning via next token prediction
- next token prediction enables the GPT to capture the structure and semantics behind languages
-
Audio Models
-
AudioPaLM : merged text and speech
- enables speech-to-speech translation and speech recognition
-
MusicGen : generate music by multiple parallel streams of acoustic tokens by EnCodec
-
-
Image Models
- iGPT : transformer to predict next pixel
- vision-language models : connect text and visual data
-
Biochemical sequence Models
- Tranception : transformers to predict protein fitness
- ProtGPT2 : generates protein sequences
- HyenaDNA : extends context lengths in genomic modelling
2.2 Byte Models
-
Binary data lacks the inherent structure and semantics of human-interpretable data
-
MalConv, DeepVSA : malware detection and program analysis
- MalConv uses CNN to analyze byte sequences
- DeepVSA : value seet analysis for post-mortem program analysis
-
Byte-level Byte Pair Encoding (BBPE) : used for multilingual pretraining, machine translation
-
ByT5 : transformers for byte sequences
- token-free encoding that improves noise robustness and spelling sensitivity in multilingual
-
ByteFormer : raw byte sequences from images and audio
-
MegaByte : modelling long byte sequences across various modalities
-
MambaByte : used Mamba to excel in byte-level language modelling and outperformed LMs based on subword tokenization
-
Current research often neglects native binary data, focusing on narrow tasks and overlooking broader potential in digital world simulation
3. Methodology
3.1 Model Architecture
-
the high granularity of bytes results in long sequences computational cost
-
quadratic self-attention scaling computational cost
-
hierarchical Transformer architecture
-
sequence of bytes of length
-
sequence of patches
-
each patch contains bytes
-
the number of patches
-
for
-
if , the last patch is padded with to size (eop, end-of-patch token)
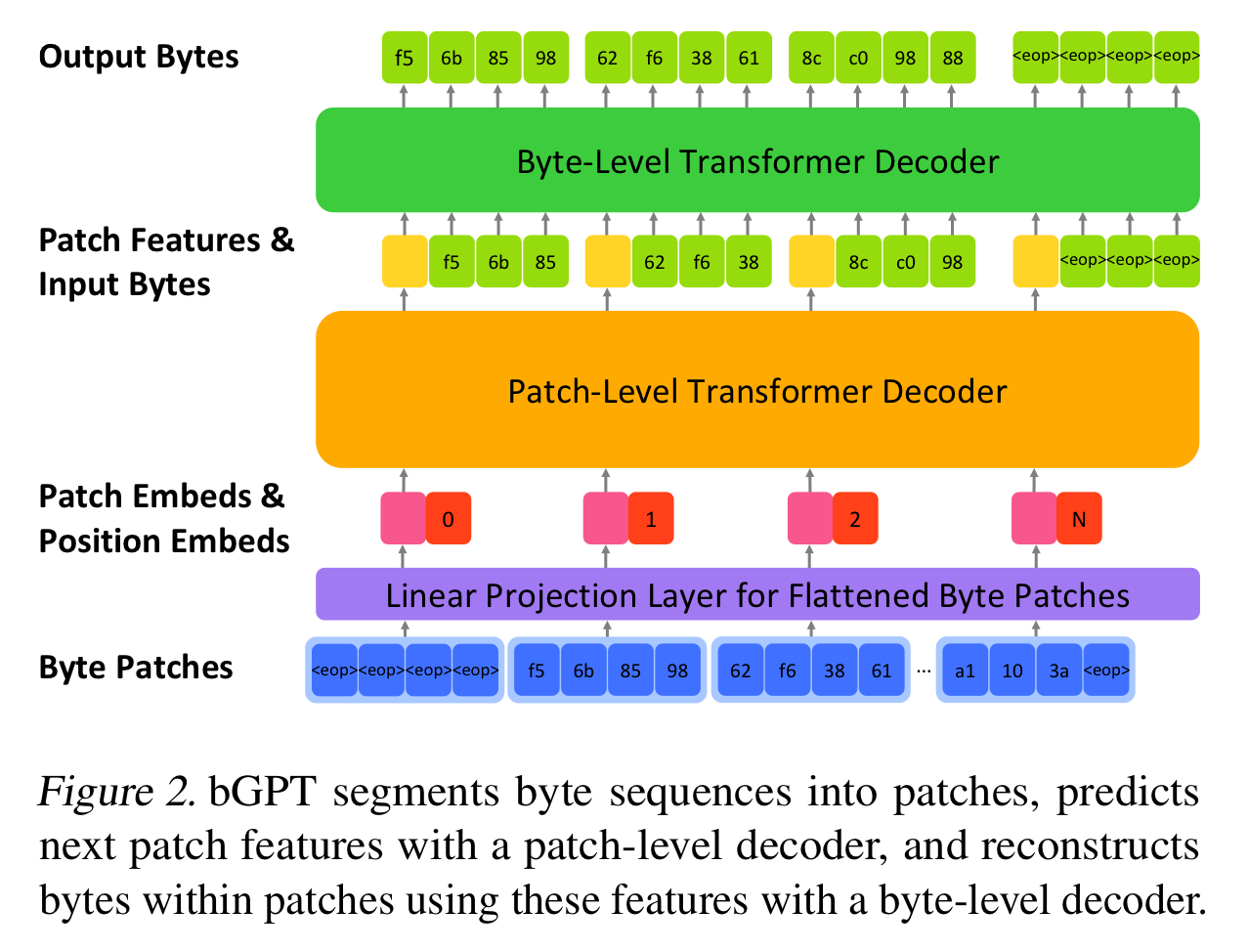
-
Linear Projection Layer
-
Each patch from is viewed as a matrix of size
- each byte is one-hot encoded (256 values + eop token)
-
Flatten those patches into one-dimensional vectors
- rows in the matrix are concatenated
-
the projection layer mats each flattened vector into a dense vector of a hidden size
-
has the shape of
-
Dense embedding enables more efficient processing of the byte sequence by reducing the dimension while preserving the essential information
Patch-Level Decoder
-
Takes the sequence of embedded patches and processes it to autoregressively predict the features of the subsequent patch, effectively learning the structure of data
-
-
for the sequence of patch embedding before the -th patch
-
for corresponding positional embeddings
-
for element-wise addition
Byte-Level Decoder
-
Takes the predicted feature of each patch and autoregressively reconstructs the sequence of bytes within that patch
-
independent for each patch and operates by conditioning on the feature representation of the current patch
-
3.2 Training Objectives
Generative Modelling
-
aims to predict the next byte based on preceding bytes without explicit guidance
-
the objective is minimizing the negative log-likelihood of the next byte prediction across the sequence
-
-
this loss encourages the model to understand the sequential dependencies in data at the byte level
Classification
-
After pretrained by next byte prediction, it is further trained on labelled datasets for classification
-
predicts categories from byte sequences
-
involves extracting a global feature from the byte sequence which is then processed by a classification head
-
-
is the boolean label for the -th category indicating whether the byte sequence is for that category
-
for total number of category
-
is the predicted probability of category given the byte sequence
4. Applications
4.1 Digital Media Processing
-
The field of deep learning is steadily advancing its proficiency in both generation and classification of text, audio, and images
-
These media is typically stored and transmitted as byte sequences bGPT can process them for generative modelling and classification
-
bGPT is trained in next token prediction, uses features from the patch-level decoder and employs average pooling to derive global features for classification
-
Data
- Audio : convert to WAV, including an 8000Hz sampling rate, mono channel, 8-bit depth, trimmed to 1 sec
- Image : convert to BMP, 32 * 32, RGB, 24-bit depth
4.2 Algorithm and Hardware Simulation
Data Conversion
-
converting data from one format to another with symbolic music formats (ABC notation) and MIDI files
-
employs the generative modelling approach on concatenated byte sequences of paired ABC and MIDI files separated by a special patch
-
bGPT learns to convert text-based ABC notation into binary MIDI performance signals and its reverse
-
ability to simulate and reverse-engineer the conversion algorithm
CPU State Modeling
-
give concatenated sequences of low-level machine instructions followed by a series of CPU register states
-
to accurately predict how the state updates with each instruction until the program halts
-
interpreting operational data and replicate digital activities within hardware
-
CPU States dataset (2.1M instances)
-
offering a simplified representation of CPU behavior
-
each instance contains a 1KB memory block with varying numbers of machine instructions followed by a sequence of 16-byte CPU register states
-
these states include various instructions (21 types with 43 variants - data movement, logical operations, arithmetic operations)
-
within each state
- 1 byte is for Program Counter and Accumulator
- 4 bytes for Instruction Register
- 10 bytes for general-purpose registers
-
instances are randomly generated 1 to 256 instructions and their captured results
-
5. Experiments
5.1 Settings
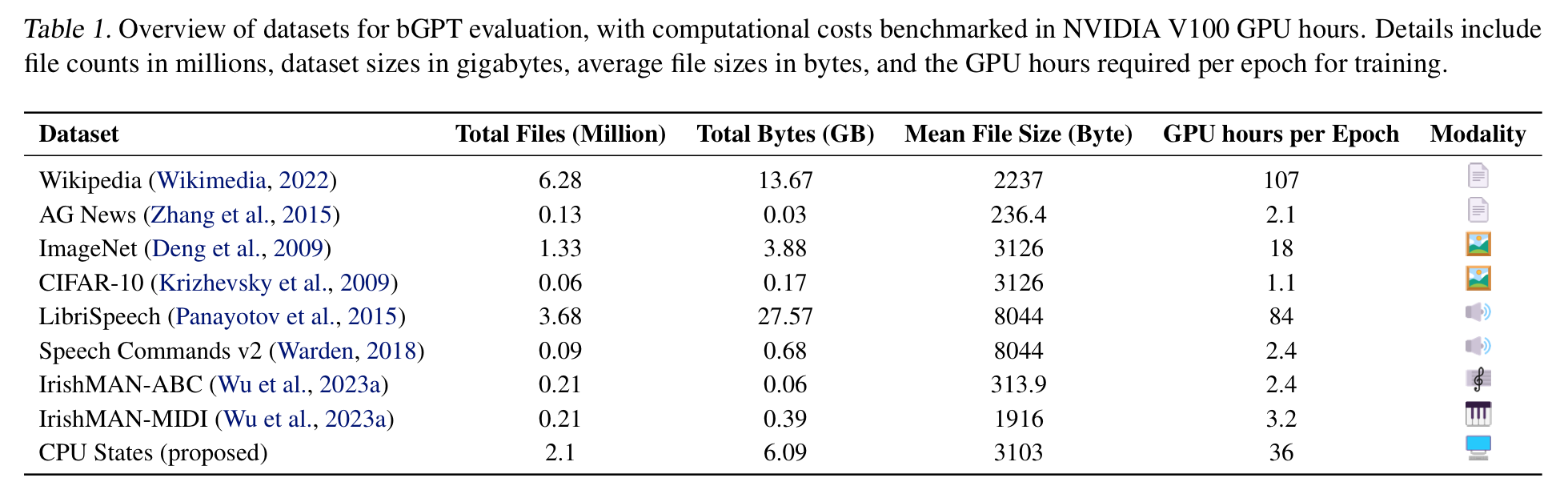
- used open-source datasets
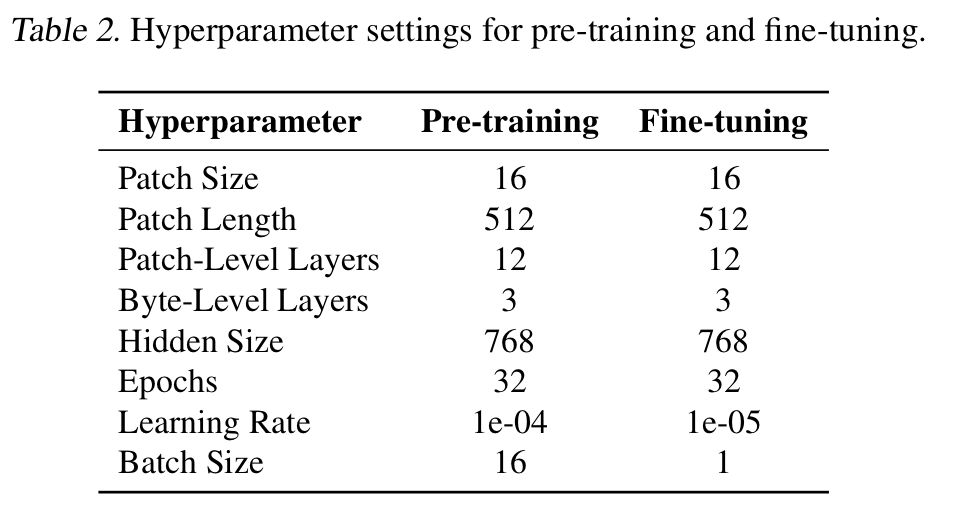
-
110M parameter bGPT matches the standard Transformer based model scale
-
avoided hyper parameter tuning and data augmentation for all evaluatioins
-
Acc for classification
-
Bits-Per-Byte for other generative modelling
5.2 Digital Media Processing
-
used standard pre-training and fine-tuning approach
-
: using ImageNet
-
: Wikipedia
-
: LibriSpeech
-
: LibriSpeech + ImageNet
-
: LibriSpeech + ImageNet + Wikipedia
-
: randomly initialized, baseline
-
first fine-tuned with next byte prediction on AGNews, CIFAR-10, Speech Commands v2
-
then fine-tuned for classification
5.2.1 Baselines
-
GPT2-small for text
- pretrained on English Wikipedia with same sattings as bGPT
-
ViT-B/16 for image
- pretrained on ImageNet
- results are taken from original studies
-
AST for audio
5.2.2 Results

-
When pretraining data and fine-tuning data are match, the model shows performance in downstream tasks
-
Despite not having modality-specific prior knowledge, bGPT still manage to achieve performances similar to baseline
-
but much lower than ViT as sequential processing nature of byte models is not suitable for processing 2D data
- simply scaling while retaining this sequential processing holds
-
and shows compatible accuracy to the unimodal models but there is a small loss
- Trade-off in byte models : mixed modality dilutes the depth of domain-specific understanding but it fosters versatility
-
positive transferring (pretrain with Audio/Image and fine-tune with Image/Audio) shows improvements over random initialization
- audio and image have some shared byte pattern
-
negative transferring (from text to other modalities) shows the structured pattern learning in pretraining is not applied
- text has distinct byte-level organizational patterns than audio and image
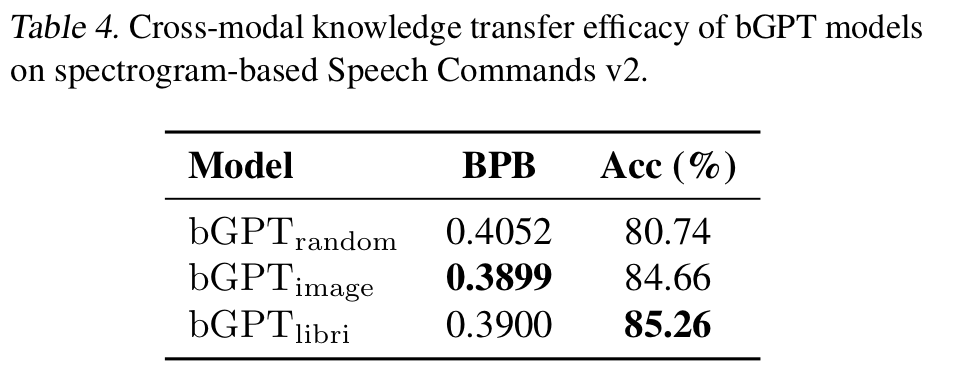
-
To investigate cross-modal knowledge transfer
- convert the Speech Commands v2 into 32 * 32 BMP spectrograms
- 8KB audio to 3KB images
- there is some information loss
-
image model for its data format consistency with spectrograms
-
libri model for its information similarity
-
disparity in CIFAR-10 does not extend to this spectrogram task observing image and libri models' BPB
- CIFAR-10 shares fewer patterns with spectrograms than spectrograms and raw audio
-
libri model has the higher accuracy than image model with speech content spectrogram
-
byte models have an inherent capability to discern and translate abstract data features and patterns regardless of modality and format
5.3 Algorithm and Hardware Simulation
-
To evaluate bGPT's ability in simulating algorithms and hardware
-
Lack of baseline models and widely used datasets evaluating scalability of bGPT on binary data
-
data conversion and CPU state modelling
-
to ( to
-
all models are randomly initialized
-
for data conversion, used IrishMAN dataset (ABC motation and MIDI files)
5.3.1 Data Conversion
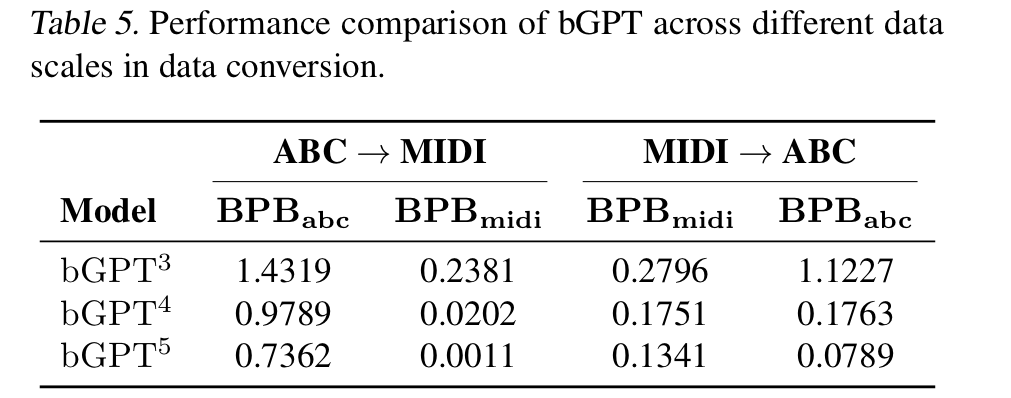
- for ABC to MIDI, assesses generative modelling as it generates content from scratch and evaluates data conversion as full ABC byte sequence is given
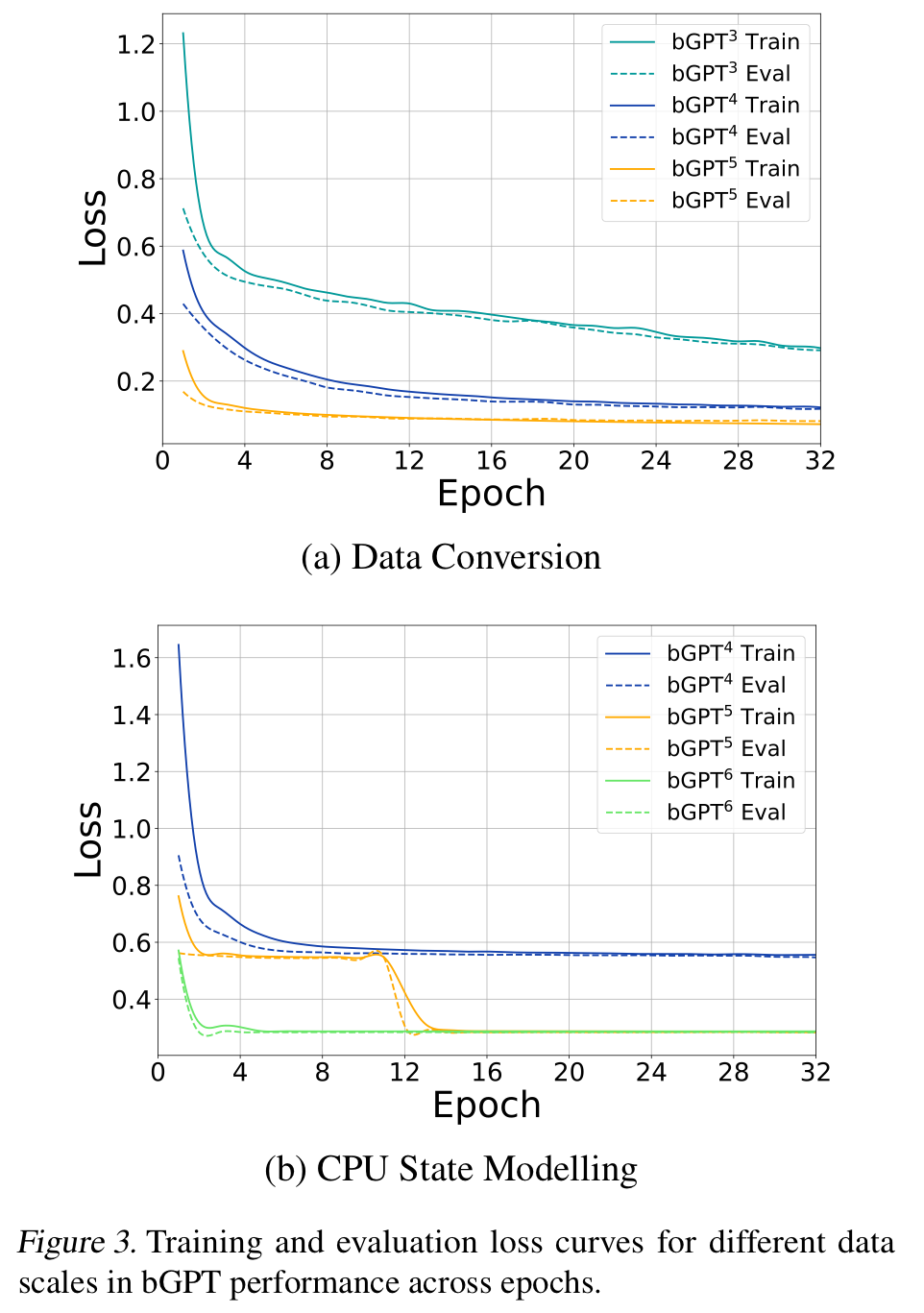
-
increased data volume directly enhances model performance in simulating data conversion
-
from Table 5, the BPB is decreasing as the model size grows
-
high BPB value for ABC in both directions
- ABC to MIDI focuses on simulating an existing algorithm with necessary information while the reverse process requires inferring and reconstructing missing information in MIDI (score structure, musical ornament, expression)
- as MIDI is binary and ABC is text, model may find it easier to learn patterns within MIDI files
5.3.2 CPU State Modelling
-
to replicate CPU functionality
-
selecting the highest probability byte at each step
-
accuracy byte-wise comparisons with actual states
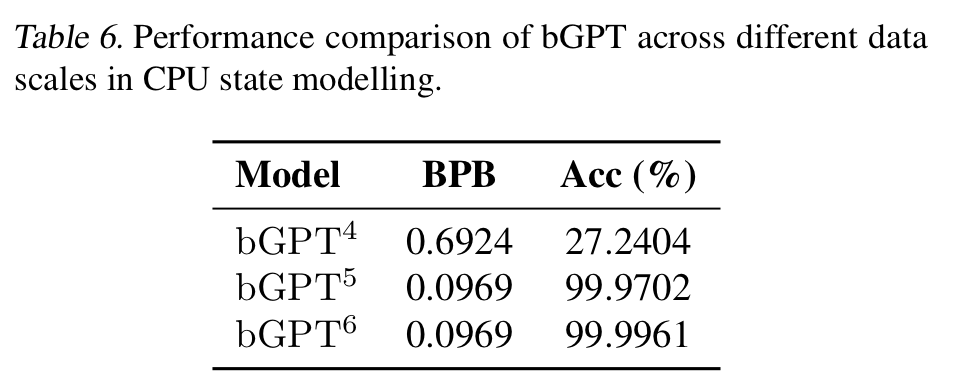
-
data volume significantly influences modelling performance
-
efficiency beyond simple memorization (each test case consists of average of 128 instructions)
-
After epoch 11, showed significant improvement of performance deeper understanding of CPU states may stem from a qualitative enhancement in capability
-
Aligns with emergent abilities in LLMs
-
Is this learning genuine?
- performance boosts are due to non-linear metrics or overfitting
- but BPB is linear and smooth
- this improvement is stem from a real comprehension of CPU
-
bGPT shows strong scalability on native binary data with emergent abilities in data conversion and CPU state modelling
6. Conclusions
-
bGPT : as a versatile simulator for the digital world
-
extending deep learning to binary data processing
-
effective in modeling digital media data + modality-agnostic knowledge transfer
-
strong scalability in modelling native binary data and signs of emergent abilities
-
without modality specific designs, it shows compatible performance
-
opportunities for improvement
- currently tested for short audio and low-resolution images
- data conversion between ABC and MIDI
- only simplified CPUs
-
Future research
- reducing computational cost
- scaling models and dataset to cover more broader data
- improving model performance for underexplored tasks
7. Impact Statements
-
it necessitates a careful examination if its ethical implications
-
its simulate or reverse-engineer algorithms
- can significantly boost technological innovation in cybersecurity, software, hardware
- poses a risk to intellectual property as training bGPT on paired source code and executable software might enable the reverse-engineering of proprietary software
-
it gives opportunities for advancing understanding of digial world but be careful for ethical, societal, legal implications
8. Comment
- 결국 모든 컴퓨터 데이터는 0과 1이므로 바이트로 접근해서 멀티모달을 실현한다는 아이디어. 이외 CPU 상태를 통한 리버스 엔지니어링 태스크도 꽤 흥미로웠음. 역시나 사이즈가 문제지만, 한가지 의문인 점은 바이트로 표현하면 현재 모델들에 비해 컨텍스트 길이가 엄청 길어야 할텐데, 이 부분에 대한 대응은 크게 없어보임.
