1. Introduction
- Unsupervised Language Models trained on data generated by humans.
- It cannot understand common mistakes by human (human want the model to be biased to high-quality answer)
- It is important to select the model's desired responses and behavior from its knowledge. Using RL
- Existing skills using curated sets of human preference
(pretraining preference learning) - But the most efficient strategy is SFT
RLHF
- Fit a reward model to a human preference
- After that, use RL to optimize a language model policy
- more complex than SFT (training multiple LMs, sampling from the LM policy)
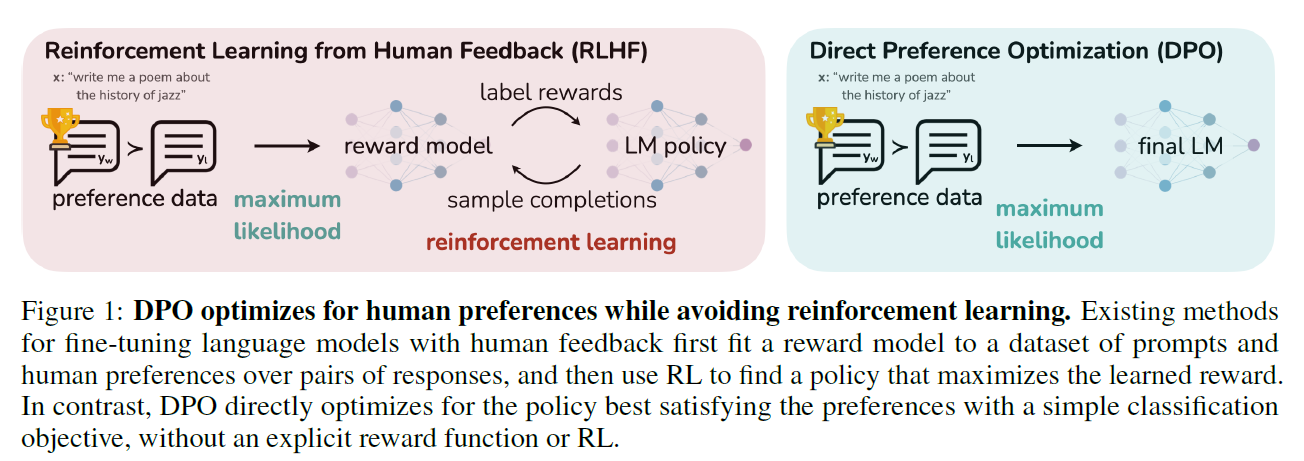
DPO (Direct Preference Optimization)
- Without explicit reward modeling / RL
- implicitly optimizes the same objective as existing RLHF (reward maximization with KL-divergence constraint)
- simple to implement, starightforward to train
- dynamic, per-example importance weight prevents model degeneration
- rely on theoretical preference model (Bradley-Terry / Plackett-Luce)
- define the preference loss as a function of the policy
2. Related Work
- Zero-Shot, Few-Shot
- instruction tuning
- fine-tune on human preference datasets under BT, PL model (RLHF, using PPO, REINFORCE)
Outside the context of LM
- Learning Policies from preferences has been studied in both bandit and reinforcement learning settings.
- Contextual Bandit Learning (CDB, Contextual Dueling Bandit, using Von Neumann Winner(policy whose expected win rate against any other policy is at least 50%))
- Preference-Based RL (learning binary preference generated by unknown scoring function)
3. Preliminary
Review RLHF Pipelines
SFT Phase
- Fine Tune LM with high-quality dataset of downstream task
- Obtain
Reward Modeling Phase
-
Use SFT Model and prompt to get pairs of answers and
-
Human labels the answer
- (winner and loser)
-
These are assumed to be generated by some latent reward model
- Actually this is not accessable
- use Bradley-Terry or Plackett-Luce
-
BT model's human preference distribution
-
Assuming a static dataset sampled from , parametrize a reward model and estimate the parameters using maximum likelihood
- For Binary Classification, the negative log-likelihood is
where is logistic function - for Language Model, is often initialized from with the addition of a linear layer on top of the final transformer layer produces a single scalar prediction
- For Binary Classification, the negative log-likelihood is
RL Fine-Tuning Phase
-
Use learned reward function to provide feedback to the language model
- the optimizing problem is formulated as
- is a parameter controlling the deviation from the base reference policy (namely, )
- In practice, is also initialized to
- As language generation is descrete, use reward function
and maximize with PPO
- the optimizing problem is formulated as
Bradley-Terry Model (for backup)
Rank entities by pairwise comparisons
where is real-valued score
Plackett-Luce Model (for backup)
Rank entities by its worth
4. Direct Preference Optimization
- Applying RL to large-scale model is challenging
- DPO bypasses the reward modeling step and directly optimizes a LM using preference data
Deriving DPO Objective
Start with RL objective as prior work
the optimal solution is
Even if we use MLE estimate of the ground-truth reward function , it is difficult to estimate which is the partition function.
Using Logarithm, the reward function is expressed as
For Bradley-Terry case, using above, the optimal RLHF policy satisfies
Then the DPO loss becomes
Finally, the loss is independent of which means it bypasses the explicit reward modeling step. Also, the theoretical property of Bradley-Terry model holds.
What does the DPO update to?
The gradient of the Loss function of DPO with respect to is
where is the reward implicitly defined by two LMs.
This loss increases the likelihood of and decreases the likelihood of . Also, the examples are weighed by how much dispreferred , scaled by .
Our experiment suggests the importance of weighing.
DPO outline
The general DPO pipeline is:
-
Sample completions , from reference model
-
label with human preference to construct offline dataset
-
Optimize the language model to minimize given and and (Also one can reuse publicly available dataset)
-
If is available, set otherwise, set by maximizing likelihood of preferred completions
5. Theoretical Analysis of DPO
5.1 Your Language Model Is Secretly a Reward Model

First Lemma is well-known under-specification issue with Plackett-Luce family. We should impose additional idenfifiability constraints. The final objective is to recover an arbitrary reward function from the optimal class.
Proof for Lemma 1

Proof for Lemma 2

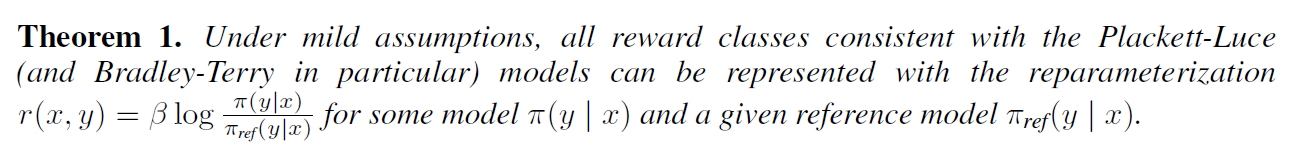

Theorem 1 also specifies exactly which reward function within each equivalence class the DPO reparameterization selects.
The reward function satisfies
i.e. is valid distribution.
Also, we can impose certain constraints on the under-constrained Plackett-Luce family such that we preserve the class of reward models.
5.2 Instability of Actor-Critic Algorithms
In RL Fine-Tuning step from RLHF, the optimization objective is
This is equivalent reward to DPO. Without the normalization term in which can be interpreted as the soft value function of , the learning could be unstable as the policy gradient could have high variance.
Prior work used human completion based reward normalization but DPO yields baseline-free reward.
6. Experiments
-
well-controlled text-generation : maximize reward and minimize KL-divergence
- IMDb
- preference pair : pretrained sentiment classifier
- SFT : GPT-2-large
-
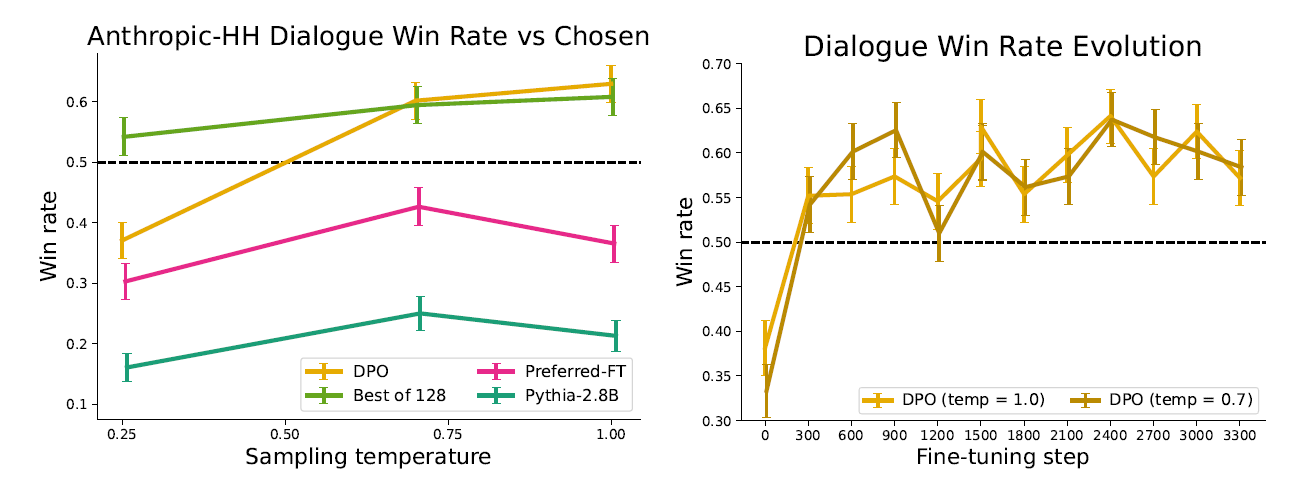
summarization and dialog : DPO performance on larger models and more difficult RLHF task
- Summarization : Reddit TL;DR dataset
- Single-Turn dialogue : Anthropic Helpful and Harmless dataset
-
Evaluation with win rate against baseline policy, GPT-4 for proxy of human
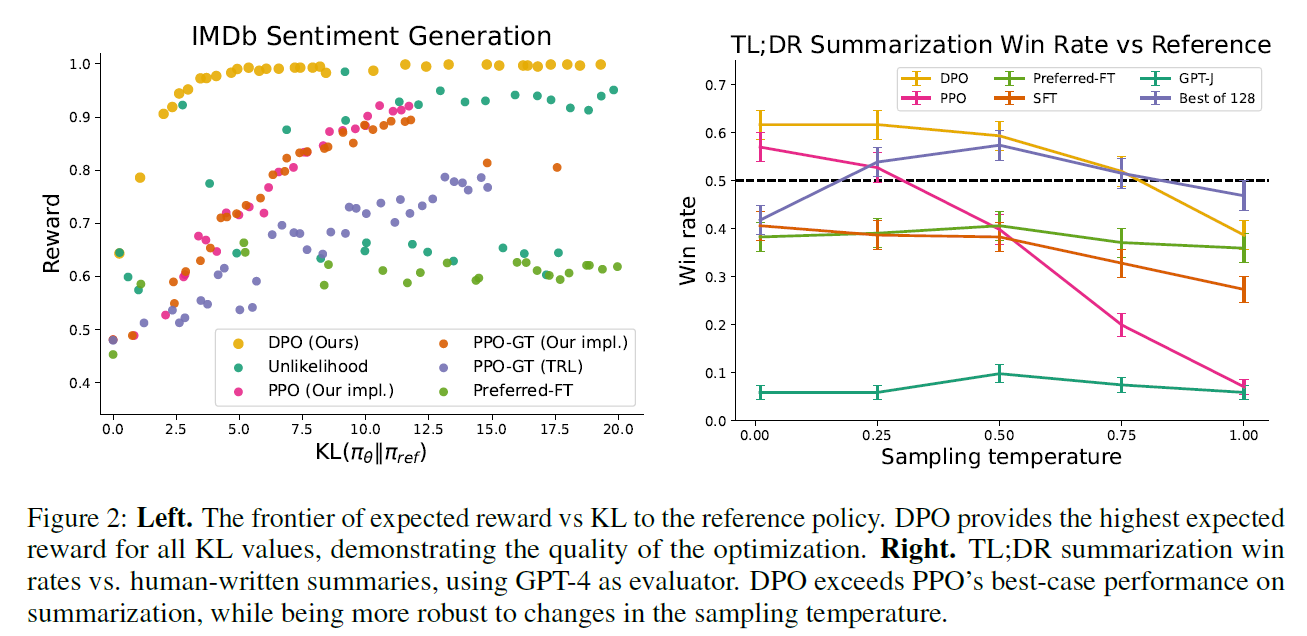
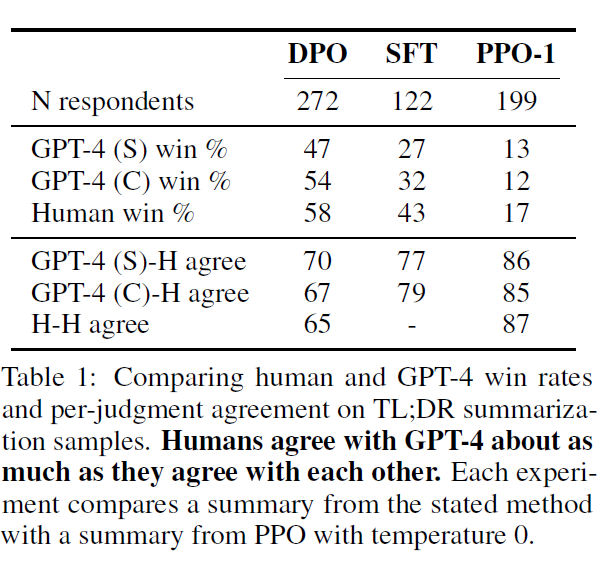
GPT-4(S) : "Which Summary is better?"
GPT-4(C) : "Which Sumary is more concise?"
7. Discussion
- rather than standard RL approach, DPO identifies a mapping between LM policies and reward functions
training LM to satisfy human preference directly with simple cross entropy loss without RL - No hyperparameter tuning is enough to perform like RLHF
- Need High-Quality Automated Judgement (GPT-4 is impacted by prompt)
- This study applied DPO up to 6B models larger models?
