1. Introduction
- Misunderstanding in person often arise
- A single message framed in different ways can lead to different conclusions.
- LLMs also have their frames Humans' frame and LLMs' frame can be different
- prompt by human critically influences the quality of response
- An individual's unique frame of thought challenging to assess the clarity of their questions and to align their frames with those of LLMs
Motivating Example

- Chain of Thought (CoT) relying on user-led follow-up questions to correct its previous wrong answers
- When GPT-4 explains its reasoning, it appears that the model has several ambituities toward the questions.
- This ambiguity in question is recognized in benchmark (even challenging for human)
Reduce ambiguity and contextualize information in a way that aligns with the existing frame of the LLMs
Suggested Approach
- Let the LLM to rephrase the question and incorporate additional details for better answering
- Rephrased question tend to enhance semantic clarity and resolve inherent ambiguity

- One-Step RaR rearticulate the given question and respond in a single prompt
- Two-Step RaR rephrasing LLM and responding LLM
- facilitates the transfer of rephrased questions from more capable LLMs to less advanced models
- CoT augmentations either at the beginning or the end of a query
- RaR directly modify the query itself easily combined with CoT
- unsupervised and training-free
2. Rephrase and Respond
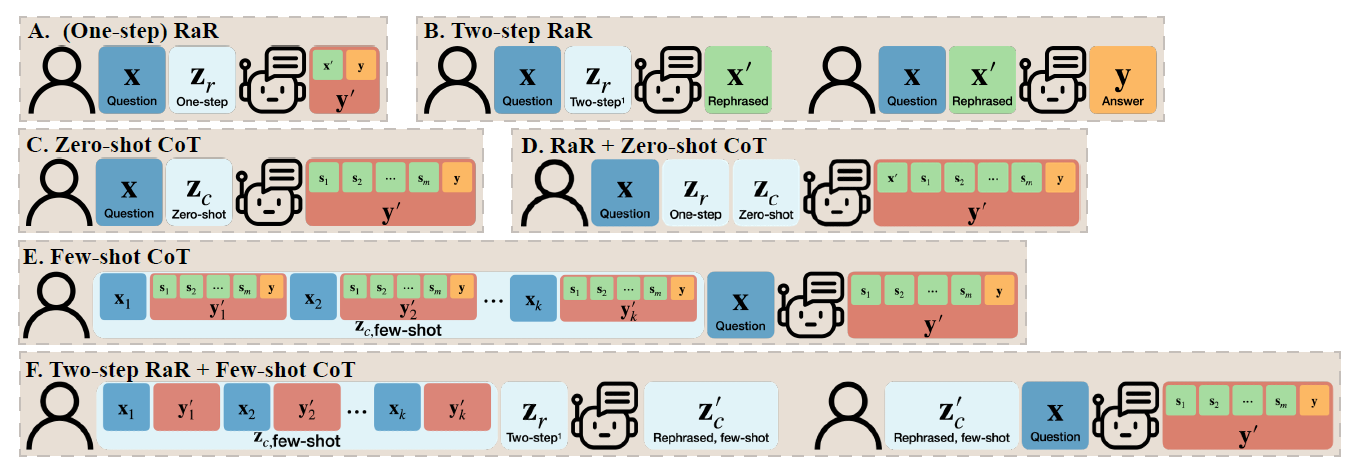
2.1 One-step RaR
"{question}"
Rephrase and expand the question, and respond

2.2 Two-step RaR
among Humans, a more detailed and precise question elicits in more accurate and decisive responses.
Rephrasing LLM prompt
"{question}"
Given the above question, rephrase and expand it to help you do better answering. Maintain all information in the original question.
Responding LLM prompt
(original) {question}
(rephrased) {rephrased_question}
Use your answer for the rephrased question to answer the original question.
- These two models can be either the same or different models
- Rephrased by strong model (GPT-4) helps weaker model (Vicuna) to respond to the question
- By Rephrasing step, it can universally improve the question quality and enable a fairer comparison in benchmarks
- In two-step method, maintaining original context helps better understanding and prevents the possible divergence of LLMs from the original questions

3. RaR Effectively Improves LLM Responses
The results are presented in four primary dimensions
- One-step RaR is a simple and effective prompt to improve LLM performances
- Two-step RaR effectively enhances the response accuracy of GPT-4 across diverse tasks
- LLMs, while all benefit from Two-Step RaR, have different proficiency in rephrasing questions
- a weak LLM can benefit more from a question rephrased by a strong LLM
3.1 Benchmark Tasks
Tasks
- Knowledge Classification
- Knowledge Comparision
- CSQA
- Date Understanding : Full dataset
- Last Letter Concatenation
- Coin Flip
- Sports
Rest tasks are performed with randomly drawed 220 questions.
Used Accuracy to evaluate performance. (Firstly exact matching and then manual inspection)
3.2 Performance on GPT-4
3.2.1 One-step RaR
One-step RaR provides a universal, plug-and-play black-box prompt that allows for efficient and effective performance improvement of LLMs on general tasks
- outperformed Two-step RaR on 6 out of 10 tasks.
3.2.2 Two-step RaR
- Examining the question quality is pivotal when evaluating the LLM performance on QA tasks
- Two-step RaR provides a universal method for LLMs to improve the question quality autonomously by rephrasing the question
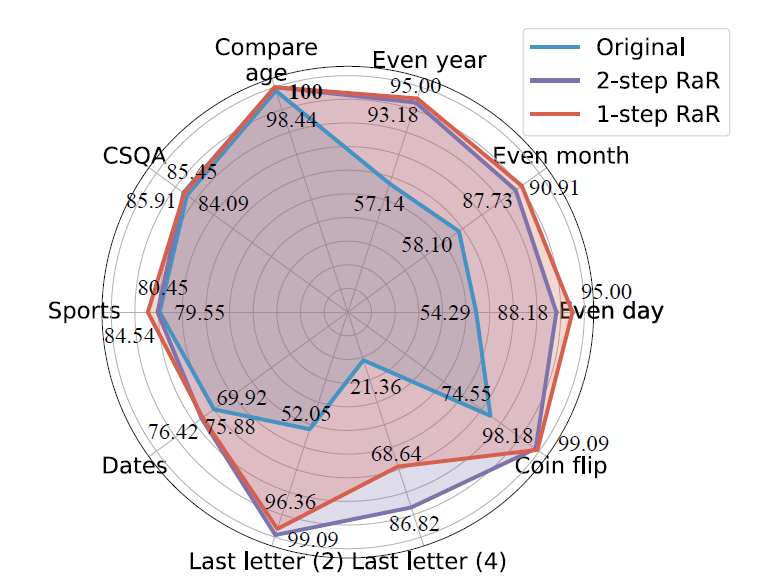
3.3 Performance across Various LLMs
- Testing GPT-3.5 and Vicuna
- Can all these LLMs provide consistent response improvement by rephrasing?
- Can GPT-4-rephrased questions improve the performance of other LLMS?
3.3.1 Can All LLMs Rephrase Questions?
- Vicuna-13b-v1.5 and GPT-3.5-turbo-0613
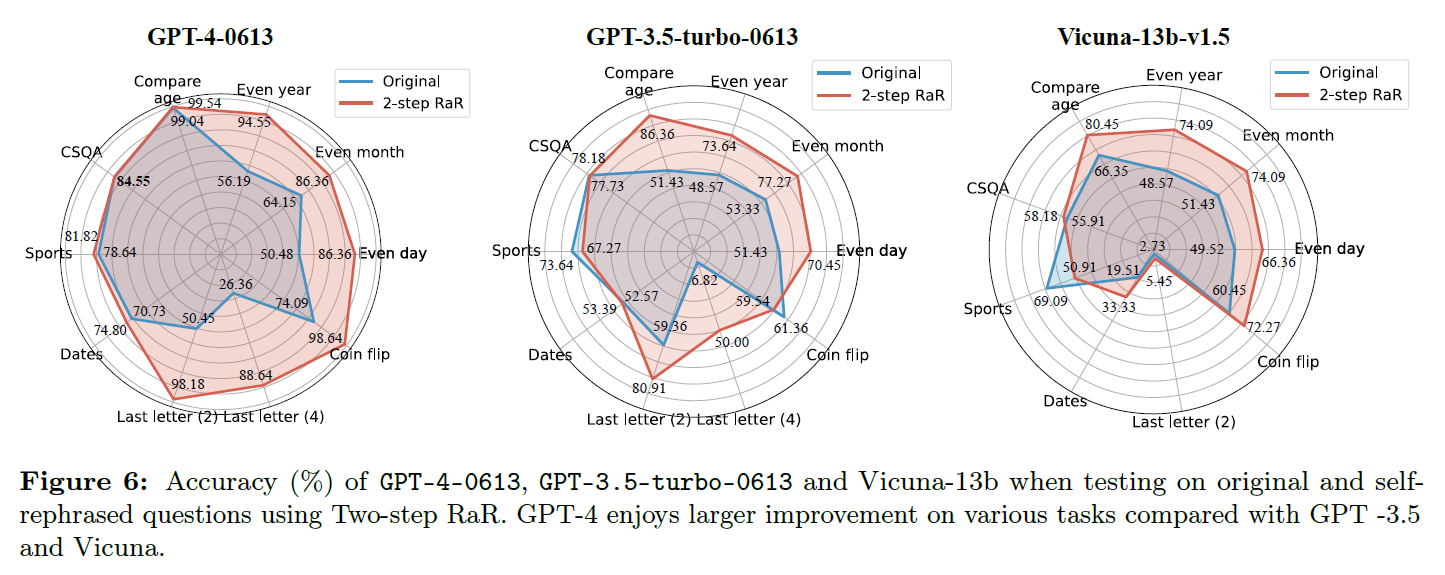
- Overall performance is increased
- Vicuna showed near-zero performance on Last Letter Concat (4)

- Vicuna changed 'yesterday' to 'today'
- GPT-3.5 occationally introduce extra details or misinterpretations (even day, recent game)
- GPT-4 is able to make clarifications like human
- GPT-3.5 tents to introduce "Please rephrase and provide additional details if necessary to enhance your response accuracy" resulting in another rephrased question not the actual answer. Removed "rephrase" in GPT-3.5
All models can benefit from rephrasing questions, with more advanced models expected to gain a larget improvement
3.3.2 Are the Rephrased Questions Transferable?
- GPT-4 generated question Vicuna response
- remarkably enhance performance on several tasks
- self-rephrased question exhibit low quality

The rephrased questions are transferable: the questions rephrased by GPT-4 can improve the response quality on Vicuna
3.4 Multiple Rephrasings
- Iterative self-rephrasing by GPT-4 yields consistent clarifications when using Two-step RaR

- "even day" concept is clarified in 3rd round of rephrasing
- the question gets more and more elaborate after multiple rephrasings
GPT-4 can potentially clarify concepts with multiple rephrasing, even if it fails to make it in the initial attempt.
4. Comparison with Chain of Thought
4.1 Mathematical Formulation
- Denote LLM as
- LLM takes as input and generate the sentence following the distribution
- Using Augmented prompt by instruction to generate a response following
- target sequence and extended text that encompasses the desired answer (mostly generated by CoT)
4.1.1 Chain of Thought
- The concept of CoT is to generate a text such that it includes intermediate CoT steps and the final answer
Process of CoT


4.1.2 One-step RaR
-
Generate a rephrased question that retains the same semantic content as and the answer
-

-
After that example, that generates
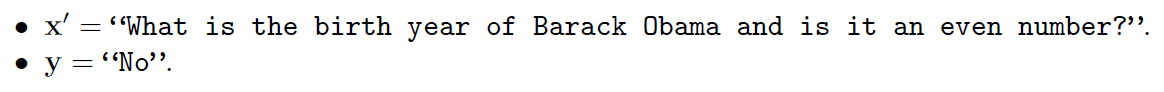
4.1.3 Two-step RaR


4.1.4 Combining RaR and CoT
-
Zero-shot CoT concat two instructions to obtain
- given the above question, rephrase and expand it to help you do better answering. Lastly, let's think step by step to answer
-
Few-shot CoT use Two-step RaR to improve its few-shot examples
- This only uses rephrased few-shot examples instead of

- This only uses rephrased few-shot examples instead of

Overall Process
4.2 Empirical Comparision with Zero-Shot CoT
- There is some example where Zero-Shot CoT fails and RaR successes
- Question Quality is prioritized before model's reasoning capabilities
Tasks
-
Chinese Idiom Inferring first letter (most difficult)
- masking one character at each 4-char Chinese Idiom
- challenging for GPT
-
StereoSet judging the given sentence if it is a stereotypical
Evaluation
- Chinese Idiom GPT-4's zero-shot accuracy + manual checking
- StereoSet
- Language Modeling score (related vs unrelated)
- Stereotype score (stereotypical vs anti-stereotypical)
- Fair score (Neither of the two related options can be solely concluded from the context)

Result
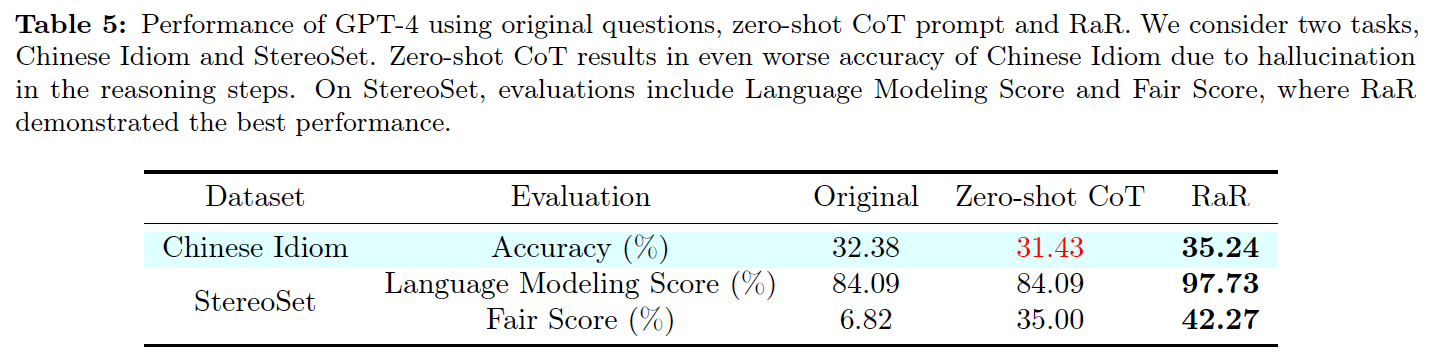
- LLM tends to hallucinate during intermediate steps in hard task like Chinese Idiom (similar to Hallucination Snowballing)
- Zero-shot CoT may result in undesired reasoning towards bias and toxicity
- In StereoSet, Zero-shot CoT fails to improve score
Question quality comes before reasoning
- Coin Flip task
- A coin is heads up. aluino flips the coin. arthor flips the coin. Is the coin still heads up?
- LLMs like GPT-4 might perceive the flipping as a random toss incorrect answer
- If human tells that flipping means reverse, GPT-4 finally start answering (acc. 74.55%)
- After self-rephrasing, the accuracy is improved to 97.73%

4.3 Empirical Improvement on Few-Shot CoT
- Few-shot CoT most effectife CoT technique
- How do LLMs respond when the human-crafted examples are flawed or contain errors? adversely influenced
Tasks
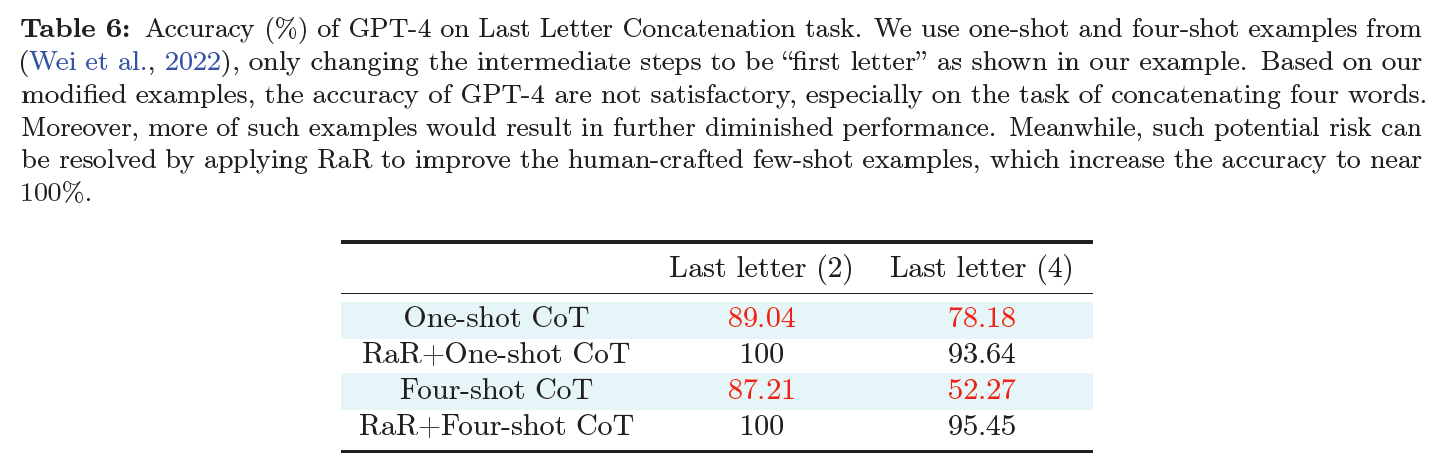
- Last Letter Concatenation
- give example with taking first letters of two words and the answer for last letter concatenation (flawed example)
Result

- GPT-4 tends to stick to the logic of modified prompt incorrect answer
- combining RaR can handle this issue
5. Related Work
5.1 Prompting Methods
- Well-crafted system message
- Autonomous refinement of prompts
- multiple LLMs to generate candidates and evaluate these prompts
- iteratively refine them
- CoT (Zero-shot / Few-shot)
- Thinking for Doing (T4D)
5.2 Self-Correcting Methods
- LLM to refine its own responses (post-hoc prompting)
- LLM's self feedback
- other model
- external references
- this has potential limits
6. Conclusion
- misunderstandings that occur between humans and LLMs
- RaR method (Rephrase and Response)
- All models gain enhanced performance throuch question rephrasing
- Question rephrasing is transferable across models
- RaR is complementary to CoT

퍼가요~