1. Introduction
-
Recent LLMs scaling with performance scaling law MoE
- Often require non-trivial changes to the training and inference framework
- hinders widespread applicability
-
Scaling up and retain simplicity is important
Depth Up-Scaling (DUS)
- Scaling the base model along the depth dimension and continually pretraining the scaled model
- Not using MoE
- No additional Module
- No changes for framework
- Applicable for all Transformer architecture
- Solar > Mistral 7B, LLaMA 7b
- Solar-Instruct > Mixtral-8x7b
2. Depth Up-Scaling
- Use pretrained weights of base models to scale up
- continually pretrain the scaled model
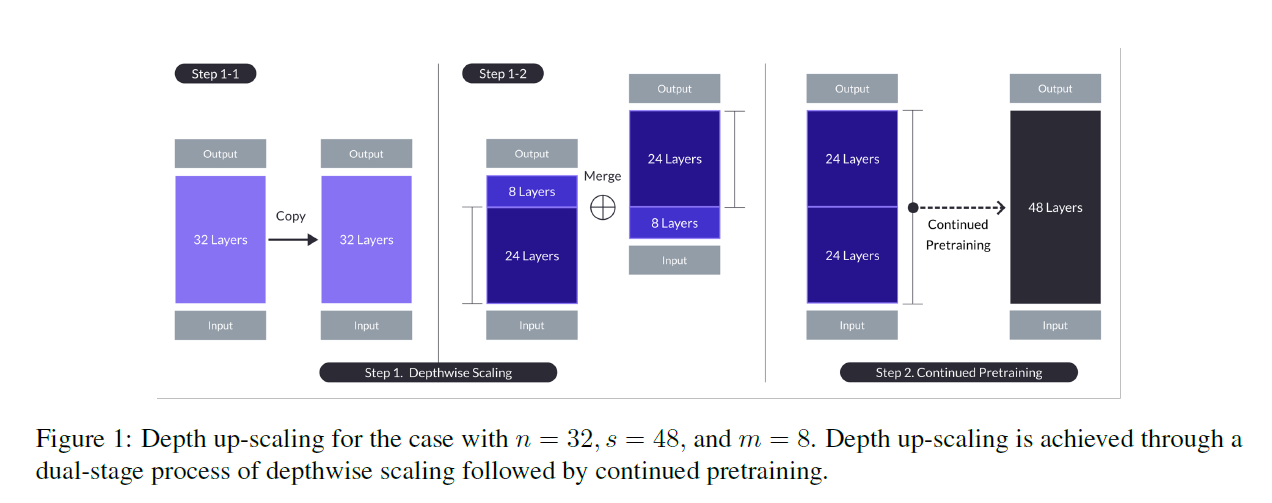
Base Model
- Any -layer transformer architecture is OK (used 32-layer Llama 2)
- Initialized Llama-2 architecture + pretrained weights from Mistral-7B
Depthwise Scaling
- From the base model with layers, set the target layer count for the scaled model (largely dictated by the available hardware)
- Copy the base model
- remove final layers for original model and initial layers for duplicated model
- concatenate to form layers (, , for SOLAR)
Continued Pretraining
- The performance of scaled model initially drops below that of the base model
- rapid performance recovery is observed
- particular way of depthwise scaling has isolated the heterogeneity in the scaled model
- if we just repead all layers so that the number of total layer to be , the layer distance or the difference in the layer indices is too large at the seam
- SOLAR sacrificed the middle layers thereby reducing the discrepancy at the seam
- the success of DUS is obtained by both depthwise scaling and continued pretraining
Comparison to other up-scaling methods
- DUS do not require a distinct training framework, additional modules (ex. gating networks, dynamic expert solution), specialized CUDA kernel
- seamlessly integrate into existing training and inference frameworks with high efficiency
3. Training Details
Instruction Tuning
- QA Format + synthesized math QA dataset
- seed math data from Math dataset only to avoid contamination
- using a process similar to MetaMath, rephrase the question and answers of the seed data Synth. Math-Instruct
Alignment Tuning
- Instruction-tuned model is further fine-tuned to be more aligned with human or strong AI like GPT4 preference using DPO
- Open-Source + Synth.Math-Instruct
- Speculated that rephrased answer > original answer
- Made DPO tuple with {prompt(rephrased question), chosen(rephrased answer), rejected(original answer)} Synth.Math-Alignment
4. Result
Training Dataset
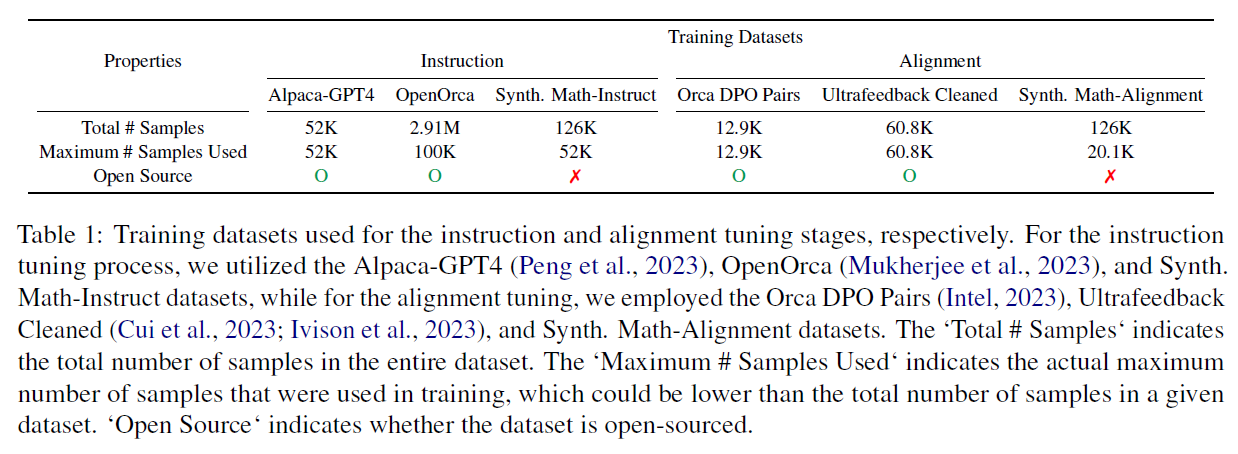
- Didn't always used all dataset
- Synth. Math-Instruct can be replaced with MetaMathQA
Result
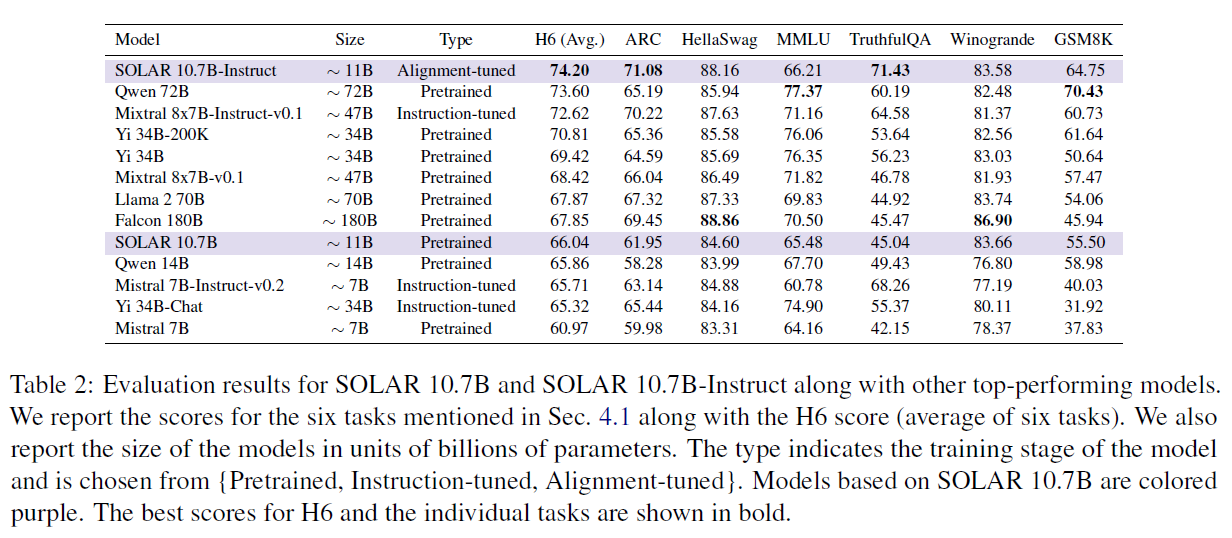
- Merged some of models that they trained while instruction and alignment tuning stages.
- Implemented their own merging method
Ablation on Instruction Tuning
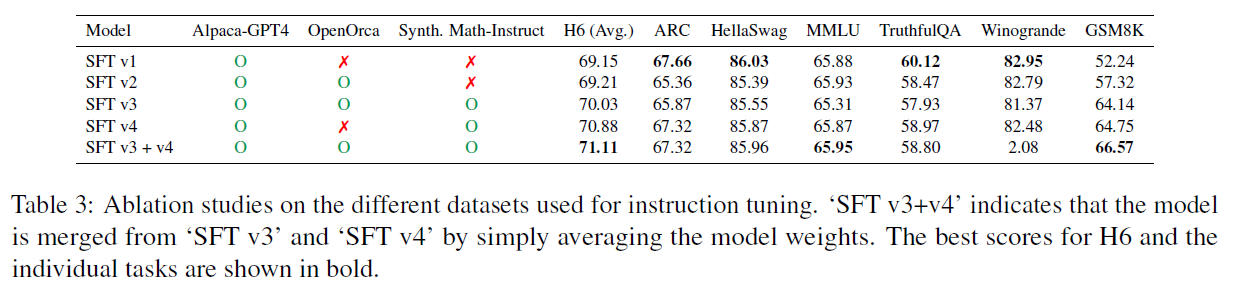
- Alpaca-GPT4 and OpenOrca makes the model to behave differently (SFTv1 and SFTv2)
- Synth. Math-Instruct was helpful (SFTv3, SFT v4)
- Merging models that specialize in different tasks is a promising way to obtain a model that performs well generally
Ablation on Alignment Tuning
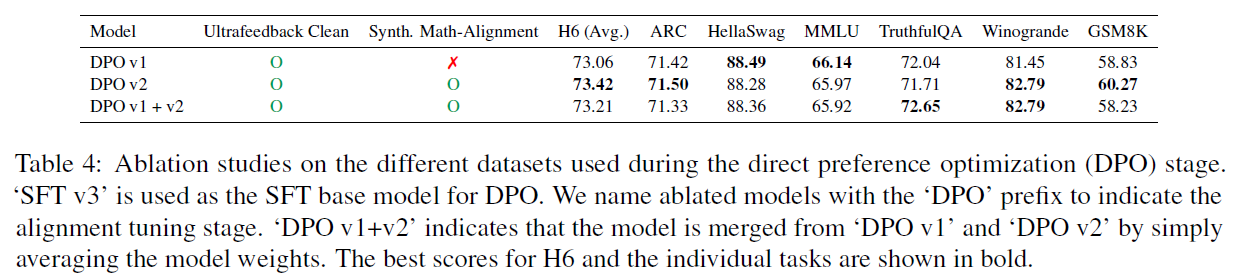
- Adding Synth. Math-Alignment was helpful
- Merging is not beneficial as DPOv2 is strict improvement over DPOv1
Ablation on SFT base models

- the performance gaps in certain tasks in the SFT base models don't always carry over to the alignment-tuned models
Ablation on Merge Methods
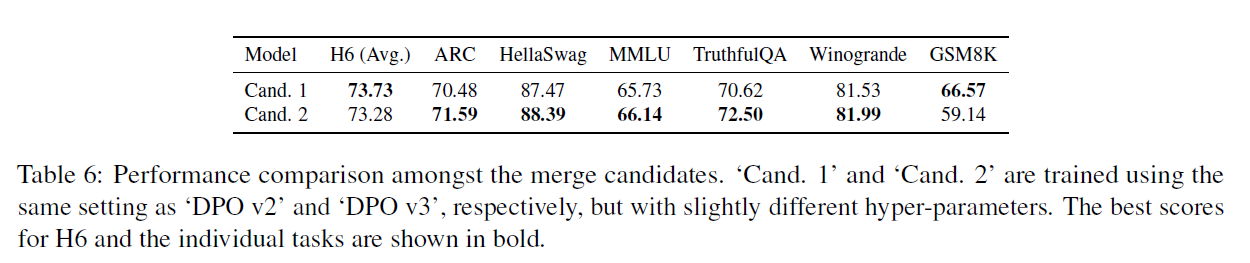
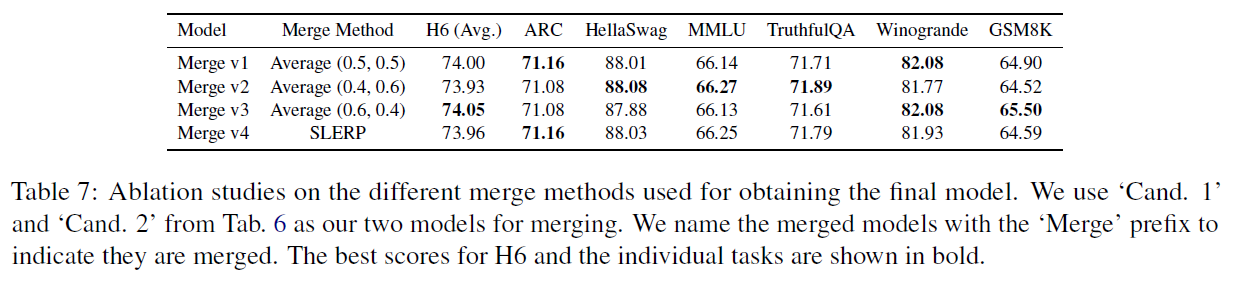
- As merge candidates have sufficiently different strengths, merge method may not be as crucial.
- Merge 1 is SOLAR 10.7b-Instruct
5. Conclusion
- Depth up-scaled model SOLAR 1.7b
- DUS is effective in scaling up from smaller ones
