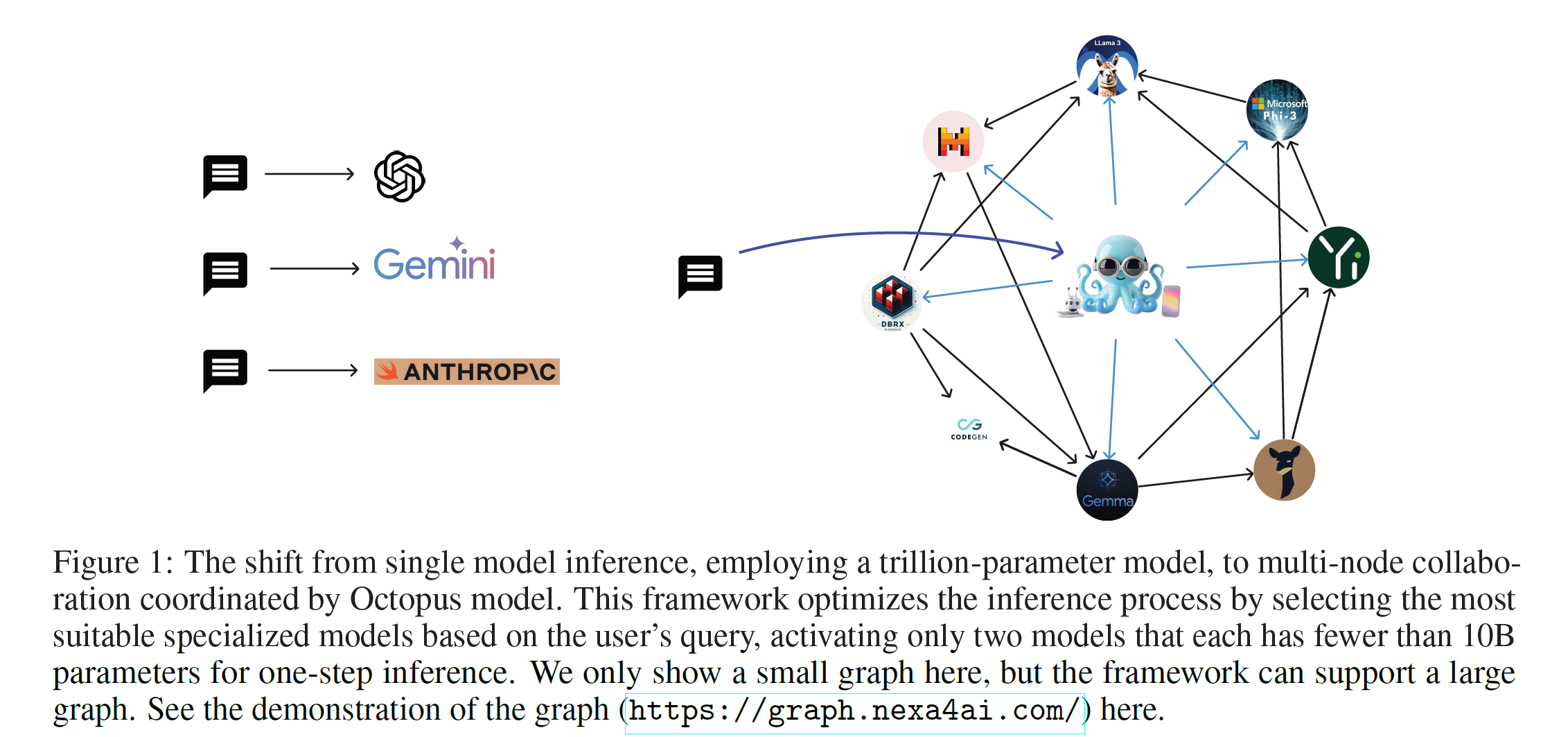
1. Introduction
-
LLMs became very powerful and used in lots of fields
-
Due to Llama 2 and 3, the open-source LLMs has seen significant growth
- user may select the optimal model based on the use case
-
Graph data structure
- can be used to represent the relationships between models, the optimal use cases and their capabilities
- create a powerful framework for seamless model integration, intelligent query routing and optimized perofrmance
-
on-device AI models
-
enhances security, reduces latency
-
cloud-on-device collaboration
- seamless integration with cloud-based models
- light task for on-device models, complicated task for cloud models
- IoT may plays a crutial roles by connecting a vast network of devices
-
2. Related Works
Graph data format
-
BFS, DFS
-
PageRank
-
GNN
-
GAT (Graph Attention Networks), GCN (Graph Convolution Networks)
AI agents with functional tokens
-
functional tokens can select suitable models or functions
-
make synergy with Octopus framework
-
selects the best neighbor, restructures the information and transmits optimized information
Multi-Agent LLMs
-
harness collective intelligence from specialized agents
-
integration difficulties, data sharing issues and maintaining smooth coordination between agents
-
exploring possibilities like cross-domain expertise and real-time collaboration
-
parallel function calling self-connections
-
sequential action processing graph traversal
LLM Scaling law
- leverating distributed computing and node expansion to addresses the scalability issues nearly unlimited node scalability
3. Methodology
3.1 LM for classification from Octopus v2
- functional token in Octopus v2
- for the choice from the set , for the reformulated information derived from the query
- used in selecting the optimal choice, reformulating the query to transmit
- select the best neighboring nodes, pass the information to subsequent nodes
3.2 LMs as nodes in graph
- directed and heterogeneous graph
- master nodes : coordinate queries by directing to worker nodes
- worker nodes : transfer necessary information for task
- master node passes the information and worker nodes handle
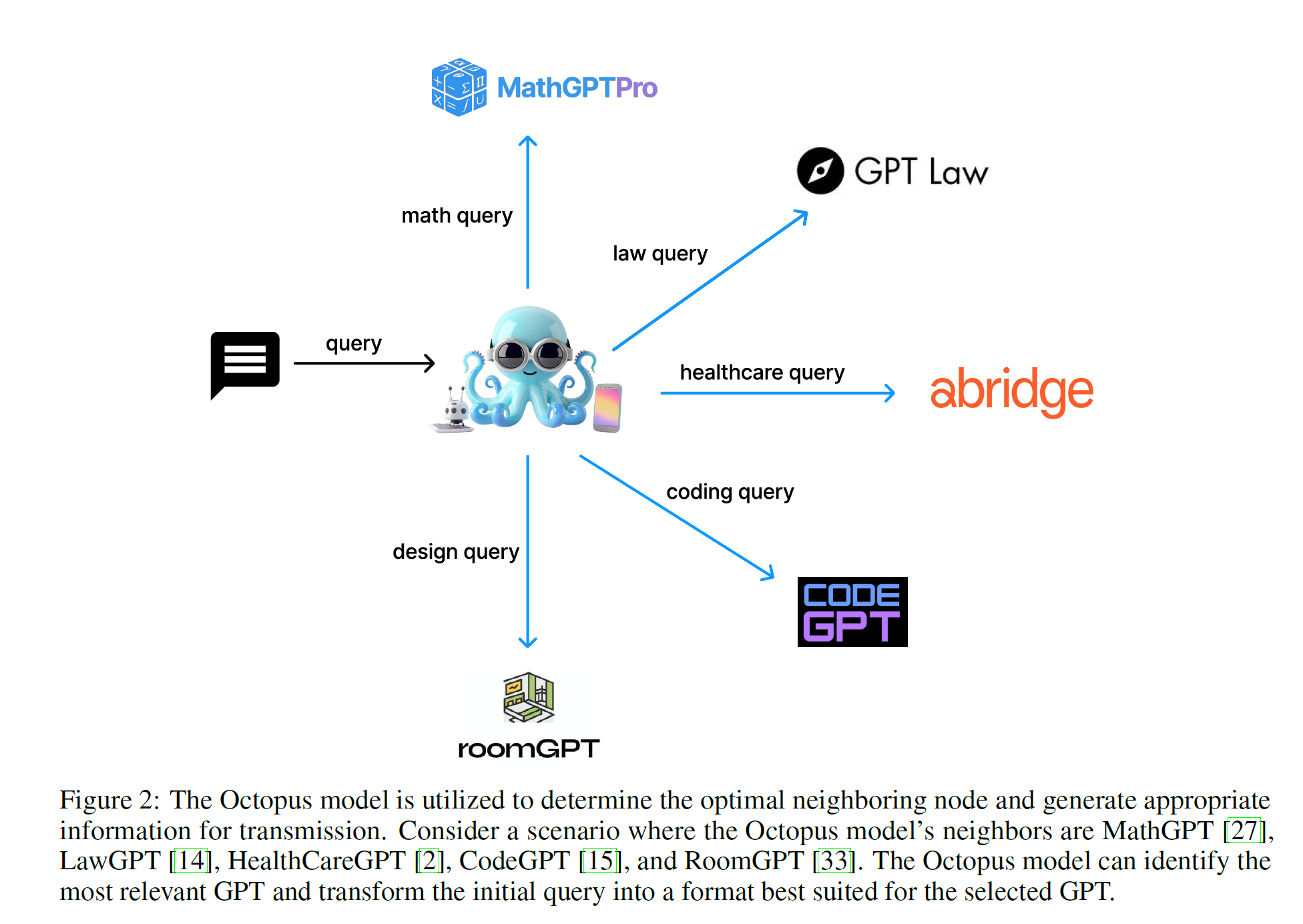
- user queries and responses
- single-step task involves only one worker node
- second term is from Octopus v2
- uses Octopus v2 to select the best neighboring worker and reformat the query to
- third term is to calculating the result by worker
- Multi-step task involves several sequential interactions
- simply expands the formula
-
to answer one query from the user, only activating two small models is needed
-
use functional token to get rid of RAG
3.3 Task planning using graphs for multistep operations
- traditional approach
-
all available functions are listed
-
LLM generated the plan with the user query and the list
-
small model cannot grash the extensive descriptions effectively
-
it doesn't consider the inherent relevance among function descriptions
using Graph
-
- Graph-based approach
- only neighboring nodes are considered
- reducing the complexity
- using Octopus v2
-
enabling rapid query redirection and reformatting
-
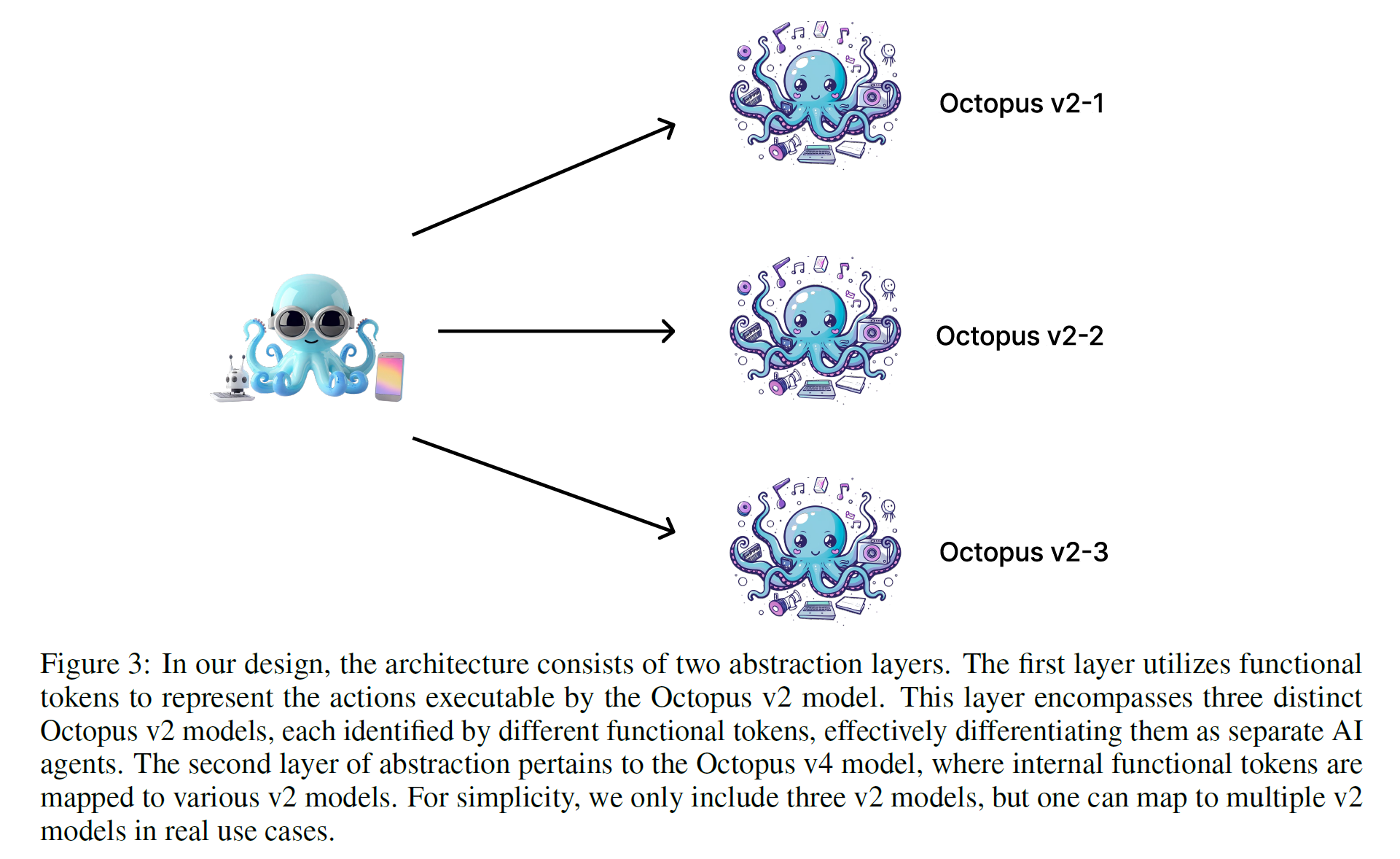
apply the functional token to make it as a single AI agent which can take single function callings for each LMs
-
or the single noce can be an ordinary LM (Llama3, Phi3)
-
At thi another layer, user Octopus v3 to choose from the nodes
-
3.4 Functional token and dataset collections
-
conceptualize each model as a distinct function
-
for specific models, detail the required prompt template in the function's doc string


- construct the dataset using similar strategy to Octopus v2
- synthetic data to train the functional tokens
- increase the temperature to accommodate diverse queries
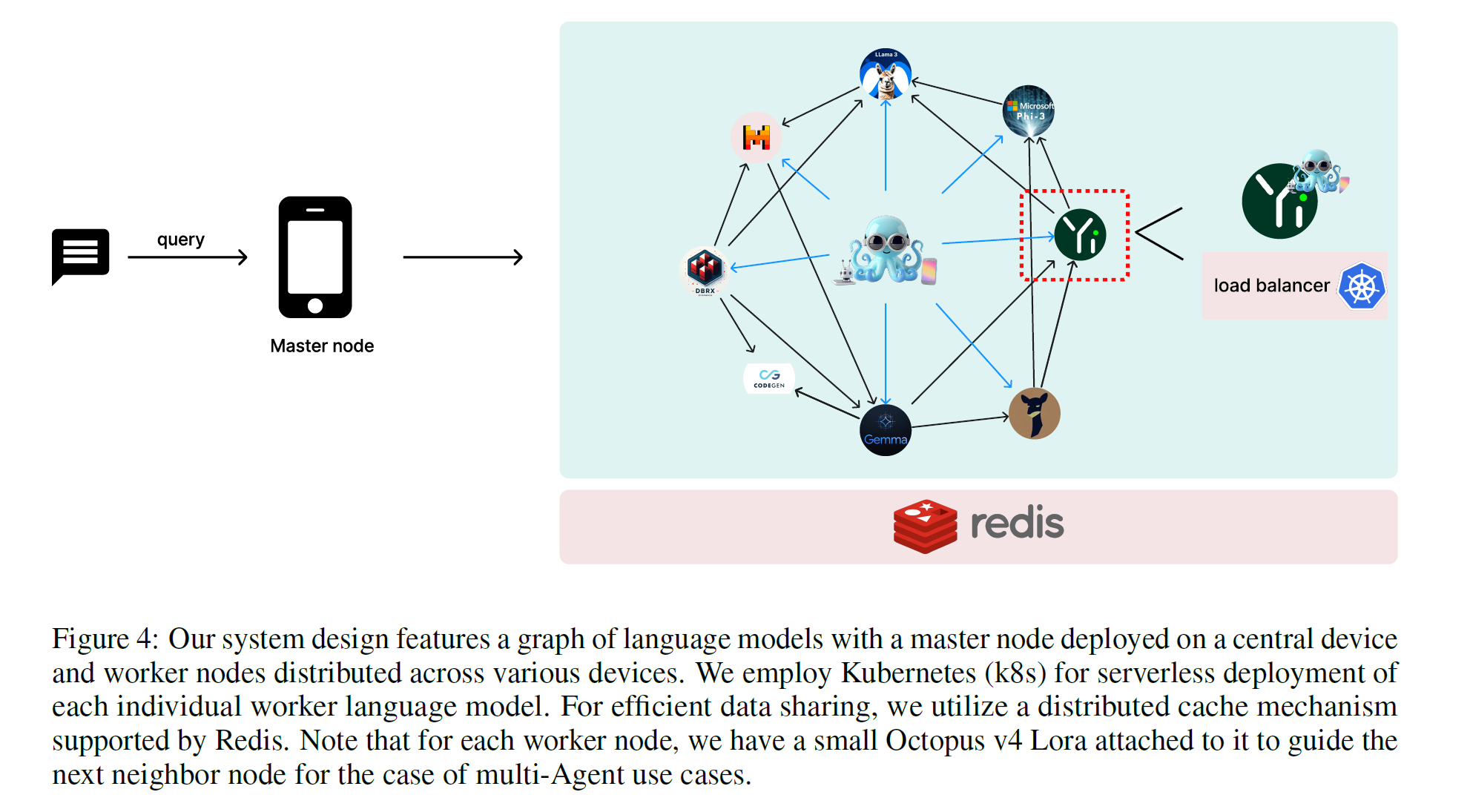
3.5 System design of LM graph
- Worker node deployment
- as an individual LM
- serverless architecture
- limit the worker size to 10B
- Master node deployment
- base model with fewer than 10B
- compact LoRA can be integrated to extend functional token capabilities
- single base model with multiple LoRA, one per each worker
- LoraX library
- Communication
-
worker and master is distributed acrosso various devices
-
internet connectivity is essential
-
master on-device, worker cloud
-
4. Experiments
4.1 Task and models
- MMLU with 17 distinct models
-
Specialized models from HF based on benchmark, popularity and endorsements
-
Not all tasks have specialized model used Llama 3 with system prompt is used instead of the specialized model (Humanities task)
4.2 MMLU evaluation
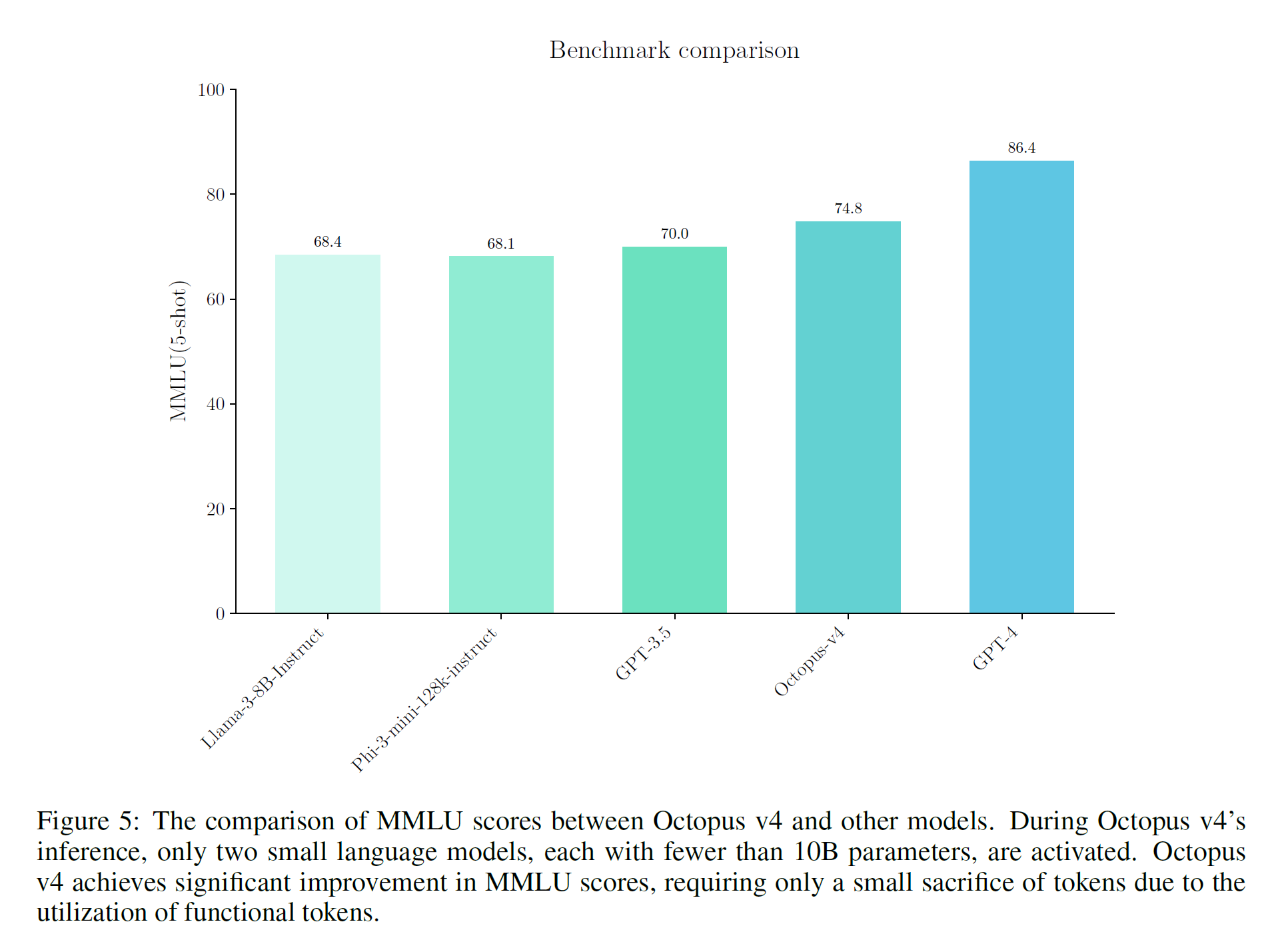
-
example query

-
<nexa_4> is functional token which maps to math gpt
5. Discussion and Future works
5.1 How to train a vertical model
- fine-tune with domain-specific expertise
- gather substancial corpus
- ensure the data is diverse, well-organized, embodies the knowledge
- clean the data
- Use HF SFT Trainer
5.2 Future work
-
integrating a variety of vertical specific models
-
Multimodal case (Octopus 3.5)
6. Comment
주어진 Query를 보고 유사도에 기반해 다음 행동을 정하는 RAG가 아니라, 애초에 학습 과정에서 토큰에 값을 붙여주면 더 빠르게 행동을 선택할 수 있다는 아이디어. Agent를 활용할 때 도움이 될듯
