1. Introduction
- SOTA models' complexity computation / memory / communication bandwidth
- LoRA
- quantizing model parametros
- Prior work has been limited to fine-tuning tools for pretrain from scratch is absent
Can neural networks be trained from scratch using Low-Rank Adapters?
- common computing clusters often have slower cross-node training with gradient accumulation as slow communication speed and bandwidth
- Low-Rank adapters compress the communication between these processors while preserving essential structural attributes
- Vanila LoRA underperforms in training a model from scratch
- using parallel low-rank updates can bridge this gap
Difference to existing works
- data and model parallelism
-
stores different copies of the LoRA parameters
-
trained on different shards
- different from traditional federated learning which replicates the same model across devices
-
their method enables distributed training with infrequent synchronizations allowing for single-device inference
-
- Previous works
- ReLoRA : trains and merges LoRA into main weights
- FedLoRA : train LoRA parameters for finetuning within a federated learning framework training multiple LoRA and averaging them
- AdaMix : averages all MLP in MoE into a single MLP needs constant synchronization during the forward and backward pass
2. Preliminaries
- as a scalar, as a vector, as a matrix, as a distribution or a set
- as a function, as a composition of functions, as a loss-function
2.1 Parameter Efficient adapters
-
Adapters : trainable functions that modify existing layers in an neural network
-
LoRA : subclass of linear adapters
- the linearity of LoRA allows for the trained parameters to be integrated back in to the existing weights
- the linearity allows models to maintain the original inference cost
LoRA
-
Given input and a linear layer parameterized by the weight
-
LoRA re-parameterizes the function as
- , ,
- rank
-
Forward pass incurs an extra computational overhead
-
the significance of LoRA pertains to the optimizer memory footprint
- AdamW stores two states for each parameter double the memory consumption
- using LoRA, the memory cost is is less than the original model's
- QLoRA saves in 4-bit precision to achieve more memory saving
3. Method
- standard training performance can be recovered using LoRA
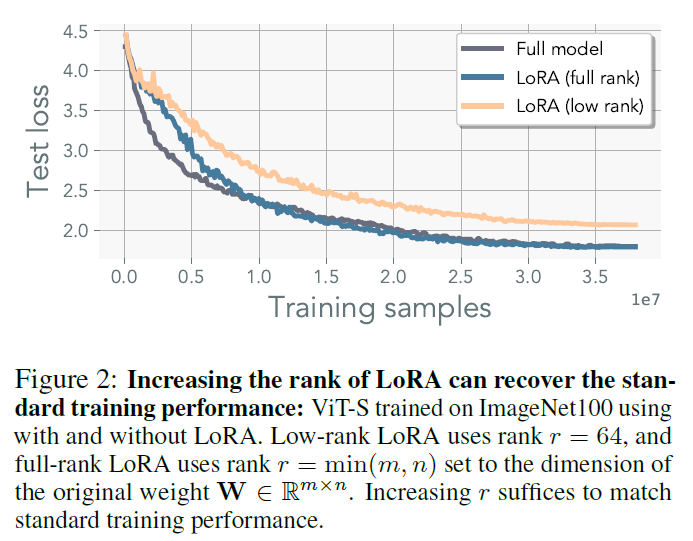
-
Low-Rank LoRA shows inferior performance to the models using standard optimization
-
LoRA is incapable of recovering weights that exceed the rank
-
Although there is a solution within a low-ranmk proximity of the initialization, it still needs the high-rank updates
3.1 Motivation : Multi-head merging perspective
-
this will show why LoRA heads in parallel can achieve the performance of standard pre-training
-
elevating the rank to the is sufficient to replicate standard pre-training performance
- it compromises the memory efficienty of low-rank adapters
-
leveraging multiple low-rank adapters in parallel
-
given a matrix of the form and ,
-
then it is possible to represent the product as two lower-rank matrices
- let and be the column vectors
- then we can construct , and ,
- then this approximates the high-rank matrix into a linear combination of low-rank matrices
- the same comclusion can be reached by beginning with a linear combination of rank-1 matrices
- This forms the basis for a novel multi-head LoRA
-
Multi-head LoRA (MHLoRA)
-
given a matrix and constant
-
-
reparameterizes full rank weights into a linear combination fo low-rank weights
-
single parallel LoRA head can approximate the trajectory of a single step of the multi-head LoRA given that the parallel LoRA heads are periodically merged into the full weights
- using the same rank for all the LoRA parameters
- used hat for the single parallel LoRA head
- when either or
-
The first scenario is rank deficient unable to recover the original model performance
-
The latter case necessitates that accumulates all the information of the LoRA parameters at every iteration if we use a merge operator at every iteration, recovering the exact update is possible
-
one can recover the exact gradient updates of the MHLoRA
-
in distributed setting, only the LoRA params/gradients have to be communicated across devices good when the interconnect speed is limited
3.2 LoRA soup: delayed LoRA merging
-
To reduce the communication cost of LTE
- local updates
- model-averaging
-
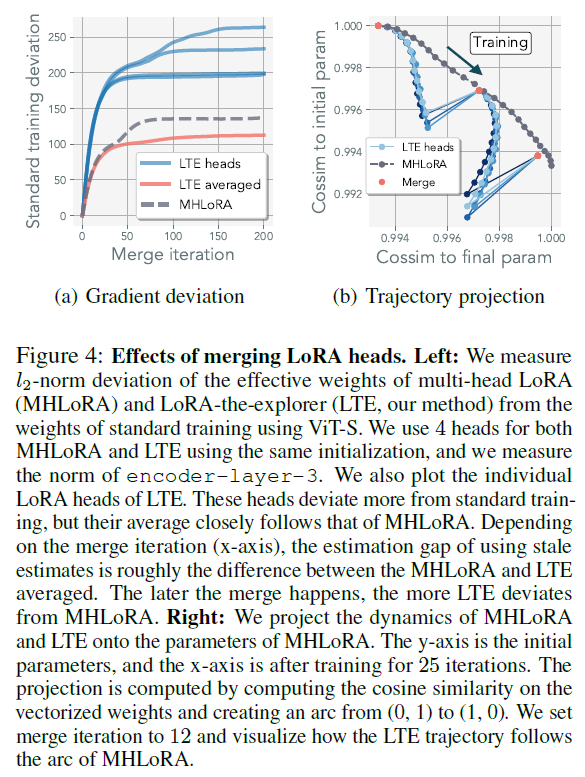
allow LoRA parameters to train independently for longer period befor e merge operator
- for stale estimate the parameters
-
Merging every iteration ensures the representation will not diverge
-
using stale estimetes relaxes this equivalence it can still match the standard training performance
-
As its estimate is inaccurate, the optimization trajectory diverge from the optimization path of MHLoRA
-
it doesn't imply that the model won't optimize
-
just different path from MHLoRA
-
used simple averaging (left more sophisticated merging as future work)
-
3.3 LoRA-the-Explorer: parallel low-rank updates
-
achieving an informative update that does not require materialization of the full parameter size during training
-
parameterizing such that it can be stored in low-precision and communicated efficiently (using quantized weights and keeping a high-precision copy)
-
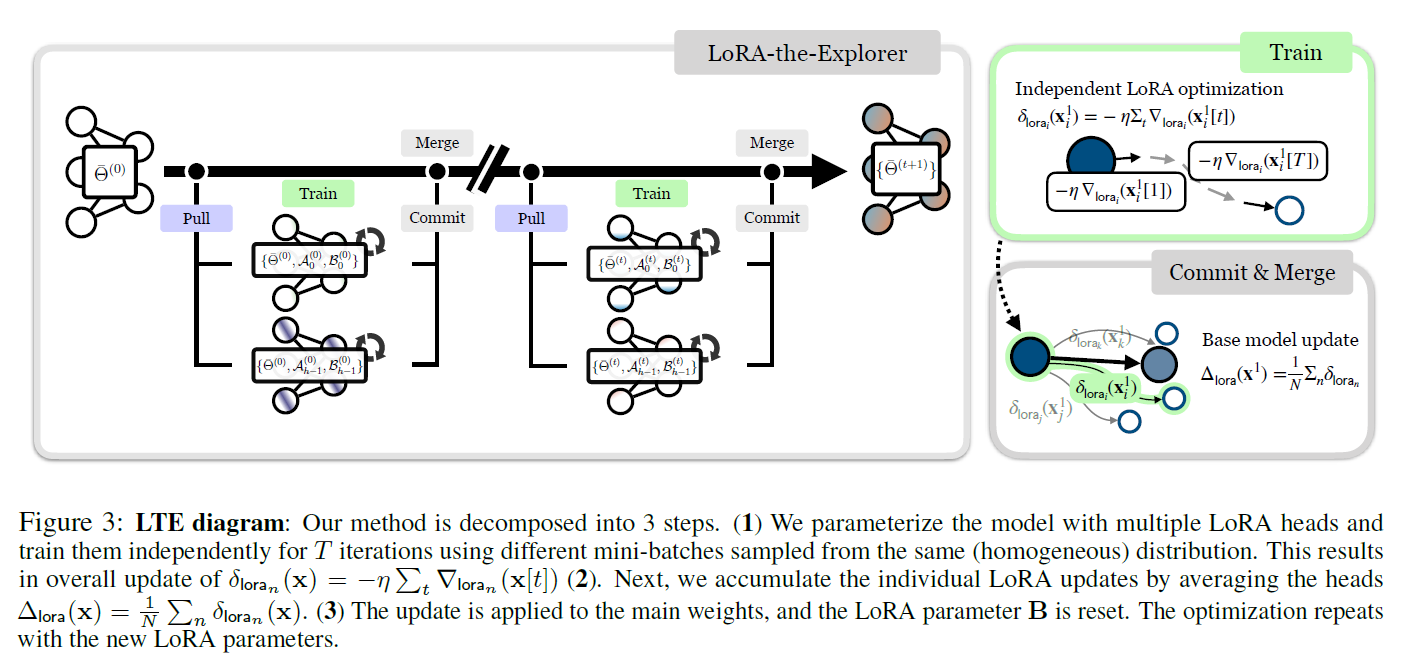
LoRA-the-Explorer (LTE) : optimization algorithm that approximates full-rank updates with parallel low-rank updates
-
creates -different LoRA for each linear layer at initialization
-
each worker is assigned the LoRA parameter and creates a local optimizer
-
independently sample data from the same distribution
-
for each LoRA head , optimize the parameters with own partition for iterations to get
-
don't synchronize the optimizer state across workers
-
After the optimization, synchronize the LoRA parameters to compute the final update for the main weight
-
then update the LoRA parameters with the updated weights
- re-initialize the LoRA parameter or use the same value with correction term
-
since it doesn't train directly on the main parameter , using quantized parameter is possible
- keep the high-precision weight only in the master node or offload it from device during training
-

3.4 Implementation details
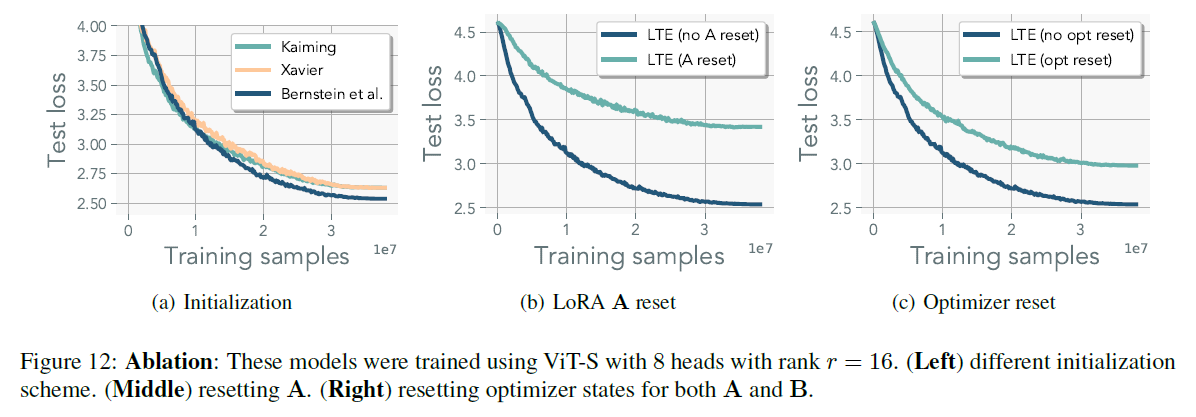
Not resetting matrix A and optimizer states
- investigated whether the matrices would converge to the same sub-space during training
- If so, resetting or using regularizer are needed
- is orthogonal to remain consistent throughout training
- without reset, it performed better (re-learning and re-accumulating the optimizer are wasting optimization steps)
scaling up and lowering learning rate
-
scaling has the same effect as tuning the lr common misconception
-
during experiment, there is no comparable performance when using to be 1~4
-
using large and slightly lowering worked best
-
standard practice : set proportional to the rank , i.e.
-
used and
-
lr doesn't scale linearly with
-
only affects the forward computation
- it modifies the contribution of the LoRA parameters in the forward pass implacation on the effective gradient
-
scales quadratically with the alignment of and
-
Significance of Initialization Strategies
- used the initialization scheme that utilizes a semi-orthogonal matrix scaled by
- originally designed for standard feed-forward models
- whereas LoRA operates under the assumption that is zero-initialized with a residual connection
- in Ablation study, Kaiming initialization and Xavier initialization performing similar
4. Experiments
- in transformer experiment, they misused the scaling factor instead of the standard scaling (they will revise the hyper-parameter)
4.1 Iterative LoRA Merging
-
iteratively merging LoRA is a key component in recovering the full-rank representation
-
they assess the effectiveness of merging a single LoRA head in context of linera networks trained on synthetic LS regression datasets
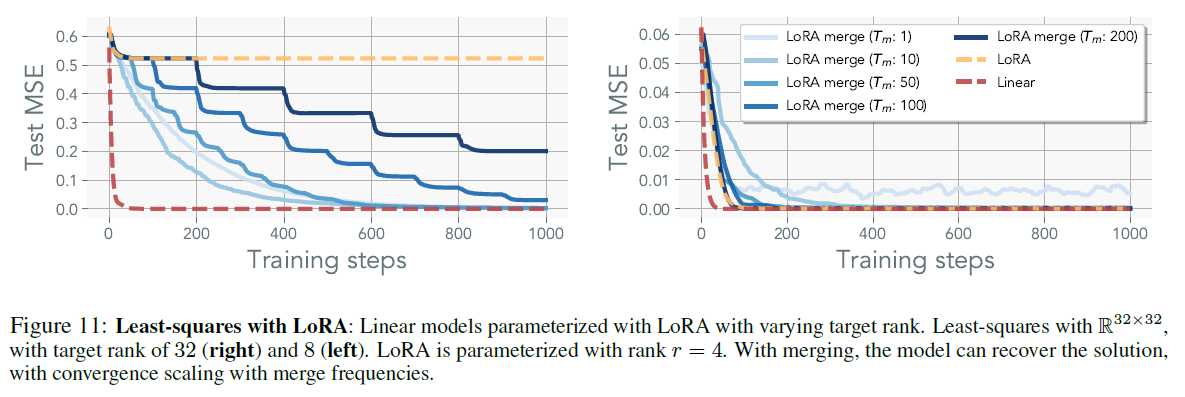
-
without merging, the model performance is not changing
-
iterative merging recovers the GT solution with the rate increasing with higher merge frequency
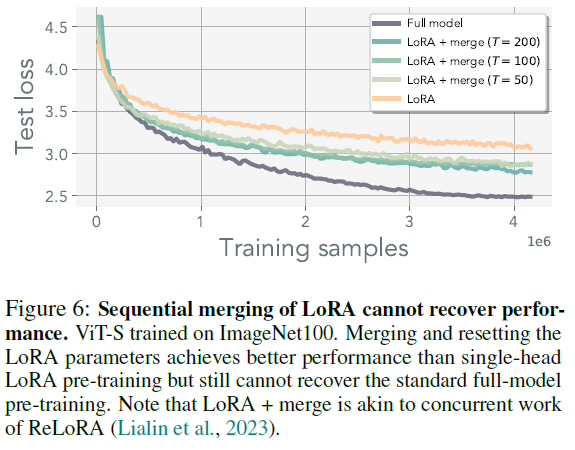
- in Vit-S with patch size 32 on ImageNet100
- merging of a single LoRA head outperforms standalone LoRA
- frequent merging delays convergence (LoRA parameter re-initialization and momentum state inconsistencies)
- performance doesn't match potential local minima when training with rank-deficient representation
- they found the merge iteration of is still stable when using batch size of 4096
- with higher , additional training may be required
- with increased merge iteration, smarter merging techniques may be necessary
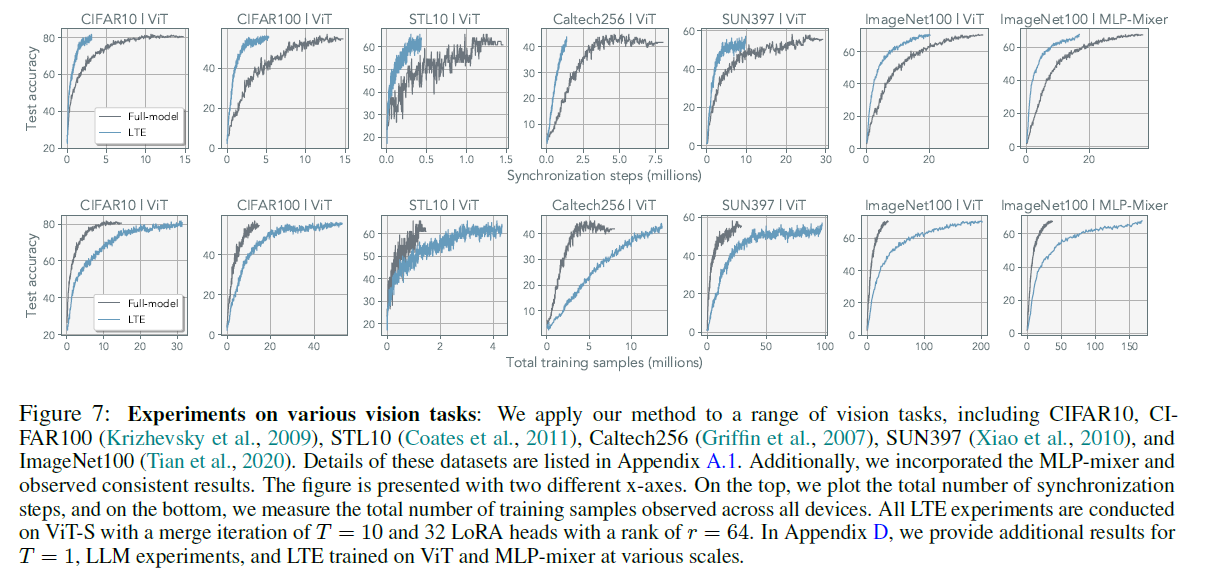
- to further test the generalizability, they conducted various vision tasks on MLP-Mixer
4.2 LoRA parameter alignment
- the efficacy of their optimization algorithm
- individual heads to explore distince subspaces within the parameter space

- average cosine similarity and Grassman distance between the heads
- conducted with data samples drawn from same distribution
- each set of LoRA parameters was exposed to a different set of samples
- LoRA heads do not converge to the same representation
- this orthogonality is maximized when using different parameters and different data (mini-batches)
- individual heads to explore distince subspaces within the parameter space
4.3 Ablation study: the effect of LoRA heads, rank, and merge iteration

-
monotonic improvement in performance with an increased number of heads and ranks
-
extending the merge iteration negatively impacts performance
-
in LS regression, excessive merging hurts model accuracy
-
with large enough rank and head, the model converges to better accuracy even if the test loss was similar
-
averaging of the LoRA heads has a regularization effect similar to model ensembling
-
ViT-S as the primary architecture
- hidden size = 384
- MLP dimension = 1536
- number of heads * rank of the LoRA > the largest dimension of the model worked well
- number of heads > rank longer iterations were required
4.4 Gradient noise with parallel updates
-
in ablation, they fixed cumulative batch size of 4096 and epoch of 1200
-
each LoRA head received a reduced batch size of 4096/heads
-
scaling the rank exerts a greater impact than increasing the number of heads
-
proportional scaling of gradient noise with smaller mini-batches
-
gradient noise contribute to slower convergence in addition to the use of stale parameter estimates
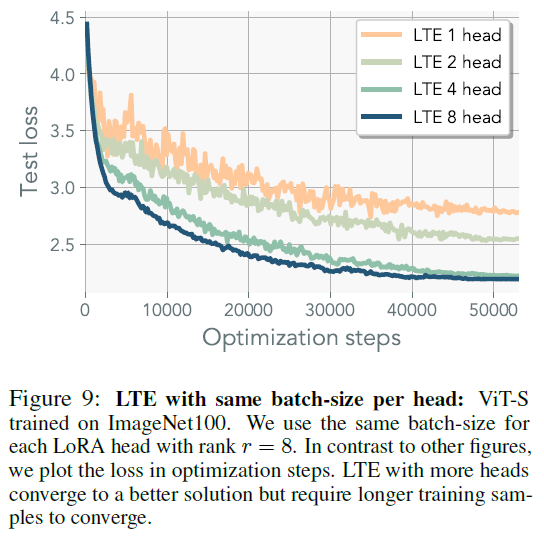
-
increasing the number of heads necessitates more sequential FLOPs but it offers efficient parallelization
-
-
using a larger batch size for gradient estimation may prove beneficial in distributed training
4.5 Performance Scaling on ImageNet-1K
- scaled up to ImageNet 1K
- doubled batch size to 8192
- didn't changed the way mini-batches were sampled
- scheduling the randomness for the mini-batches is not explored
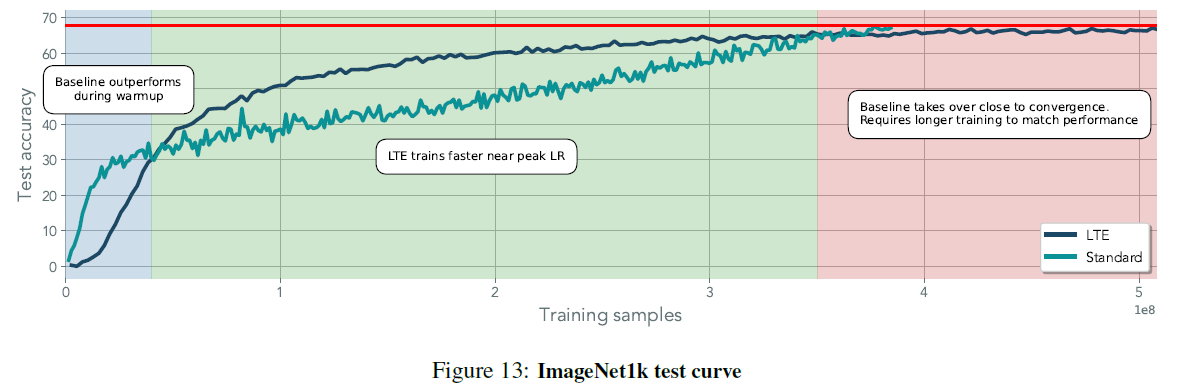
- in Initial training, LTE outperformed standard training
- as training completed, standard training overtook LTE
- LTE needs additional iterations to achieve comparable performance
- standard training appeared to benefit more from a lower lr compared to LTE
-
this study is focused on training deep networks with parallel low-rank adapters (not efficiency!)
-
hypothetical computation analysis for future scaling efforts
-
model size and for LTE
-
the number of devices for each method and
-
with quantization, each LTE device require a memory footprint of
-
as base model is 16-bit and if we use 4-bit quantizing,
-
with AdamW, DDP necessitates an additional parameters (total )
-
for LTE, is needed
-
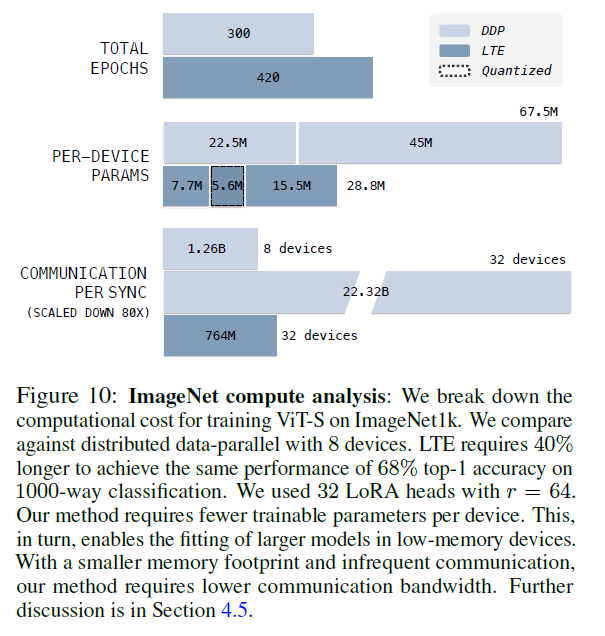
Assuming the training is parameter bound by the main weights , LTE can leverage GPUs roughly 1/3 size of DDP
-
LTE requires 40% more data and 20% slowdown per iteration with quantization (QLoRA)
-
on average, each LTE device observes 1/3 less data than a device in DDP
-
Communication bottleneck
- In multi-node systems, the communication scales with the size of the model and is bottlenecked at interconnect speed
- using standard all-reduce, the gradient shared between each device for a total communication of
- for LTE, as it communicate every iteration so
- using parameter server method (1 and broadcast), gradients are sent to the main parameter server and averaged
- DDP with a parameter server would use
- LTE with parameter server would use
- LTE can leverage lower-bandwidth communication as the parameters shared between devices are strictly smaller by a factor of
-
5. Related works
-
Training with adapters
- LoRA
- MoE PEFT and averaging
- Additive adapters
- Adapters for NLP, vision, video, incremental learning, domain adaptation, vision-language, text-to-vision, perceptual learning
-
Distributed Training and Federated Learning
- Federated Learning in low-compute devices, high-latency training, privacym, cross and in-silo learning
- communication efficiency
- local steps
- decentralized training
- gradient checkpointing
- reversible gradient computation
- gradient or weight compression
- Combining models in federated learning
- FedAvg
- weight averaging
- probabilistic frameworks for merging
- updating with stale parameters
- Server momentum and adaptive methods
- bi-level optimization schemes
-
Linear mode connectivity and model averaging
- deep models can be connected through nonlinear means
- linear paths with constant energy exist in trained models
- for models with different initialization, parameter permutations can be solved to align them linearly
- model averaging
- model stitching
- Anna Karenina principle
- model averaging within ensembles
- utilizing an average model as a target
6. Conclusion
-
Low-rank adapters for model pre-training
-
LTE : bi-level optimization method that capicalizes on the memory-efficient properties of LoRA
-
how to accelerate convergence during the final 10% of the training?
-
how to dynamically determine the nuimber of ranks or heads?
-
is heterogeneous parameterization of LoRA feasible where each LoRA has a different rank?
-
what strategies for merging can achieve higher performance?
-
This study is showing viability
-
tests on larger models are needed
-
this will pave the way for pre-training models in computationally constrained or low-bandwidth environments
- less capable and low-memory devices can train a large model
- wisdom of the crowd
7. Comment
메인 파라미터들을 건드리지 않고 어댑터를 이용해 전체 모델을 근사하여 복원한다는 아이디어. rank r의 LoRA를 다시 rank 1로 decompose하여 바로 합치는 것이 아니라 주기적으로 병합해주는 것. 왜 lora를 다시 분해한다는 생각은 안해봤을까.
