Transformer
background
인공신경망 기계번역
-
word translation
- ex: I Love You 라는 문장이 입력되면 이것을 context vector로 만든 후, 다른 언어로 Generate함
- context vector로 만드는 과정 : Encoder -> 문제점 context vector는 문장의 마지막 단어에 큰 영향을 받음. 다른 요소들을 집중할 요소 필요(Attention)
- context vector로 문장을 만드는 과정 : Decoder
- ex: I Love You 라는 문장이 입력되면 이것을 context vector로 만든 후, 다른 언어로 Generate함
-
sequence to sequence + attention : 방대한 양의 정보를 함축적으로 표현하는 것에 대해 효율적
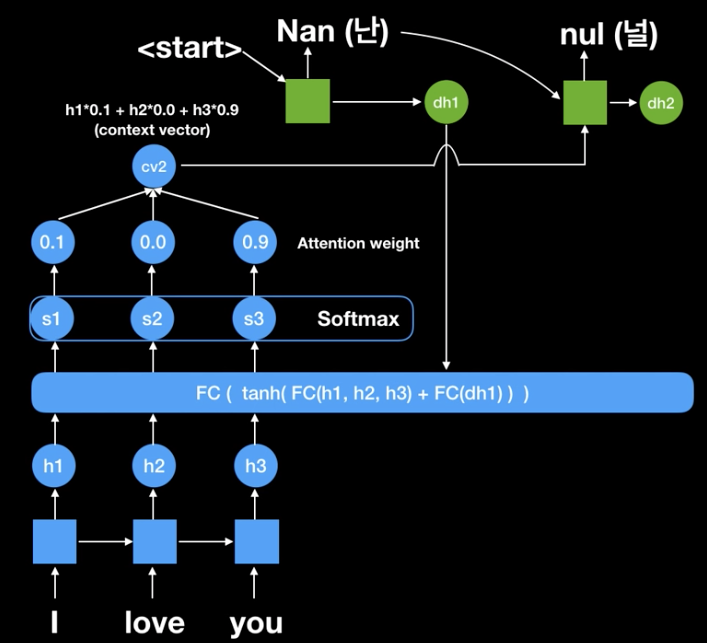
- 첫 번째 context vector인 난(Nan)이 출력 될 때, I는 0.1 love는 0, you는 0.9로 attention하여 출력된 것임.
- Teacher Forcing : seq2seq 모델에서 틀린 값을 Predict 했을 때, 굳이 정답으로 바꿔서 다음입력으로 넣어줌(학습 효율화, 가속화 위해).
이전 부분들은 손으로 메모해놨었음...
-
의문점 : Encoder, Decoder의 갯수가 각각 같을 필요는 없다... 그렇긴한데 그래도 일단은 같은게 좀 대략적으로 보면 맞지 않을까??
-
각 Encoder, Decoder 사이에 데이터가 움직일 때는 똑같은 shape임
- 중간에 사이즈를 줄이는 부분(512->64)도 결국은 Multi-head attention이 8개로 하기 때문에 그것들 이어 붙이면 같은 사이즈가 되는 셈
크게 크게 살펴보는 Self-Attention
- 필요 시나리오 예시 : 문장에서 "그것"이 가리키는 것을 모델이 어떻게 인식을 할까? -> 모델이 "그것"이 동물과 연결을 하여 이해할 수 있어야 함
- RNN의 경우 : hidden state 유지, 업데이트를 통해 처리 중인 단어와 과거 단어들 과의 맥락을 연관시킴
- Transformer의 경우 : Self-attention

Self-Attention을 더 자세히 보겠습니다.
Self-attention process
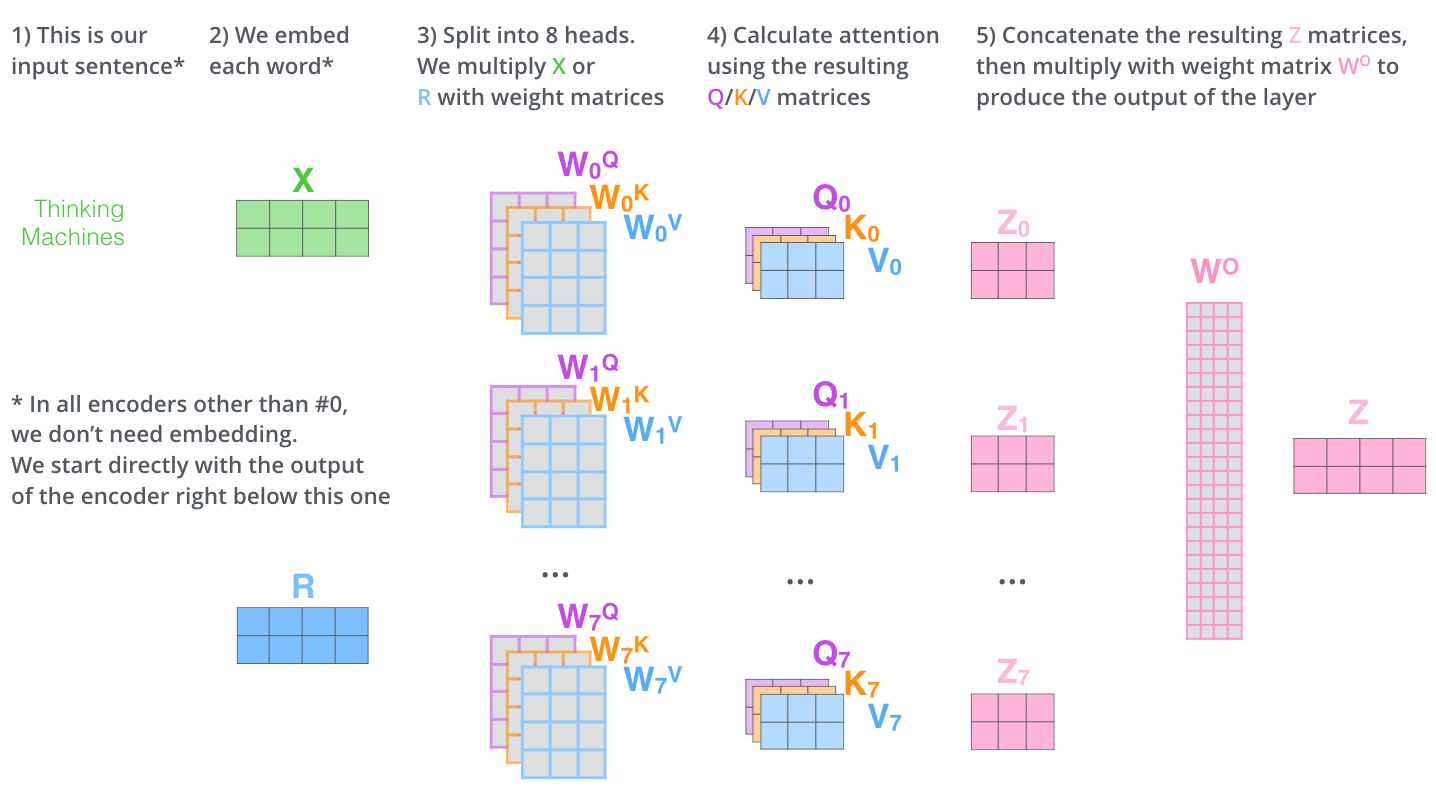
- encoder에 입력된 벡터로부터 3개의 벡터 만들어냄
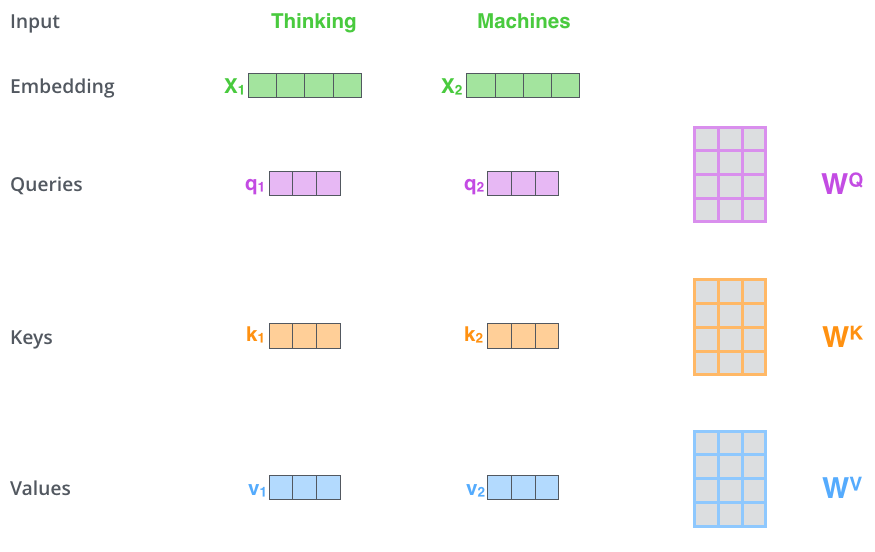
- Query vector, Key vector, Value vector : 각 vector를 추출하기 위한 행렬이 있음 , 기존 벡터들보다 더 작은 사이즈, 각 벡터의 의미는 뒤에서..
- 이유 : multi-head attention의 계산 복잡도를 일정하게 만들고자 내린 구조적인 선택
- 의문 :
사이즈 512 벡터 하나에 대해서 3개의 사이즈 64 벡터를 만드는데, 계산적 복잡도가 일정한 것인가? 아님 기존보다 복잡하지 않게 하기 위함인가?-> multi-head 가 8개로 attention이 진행되므로 512에서 8로 나눈 64로 진행이 되는 것
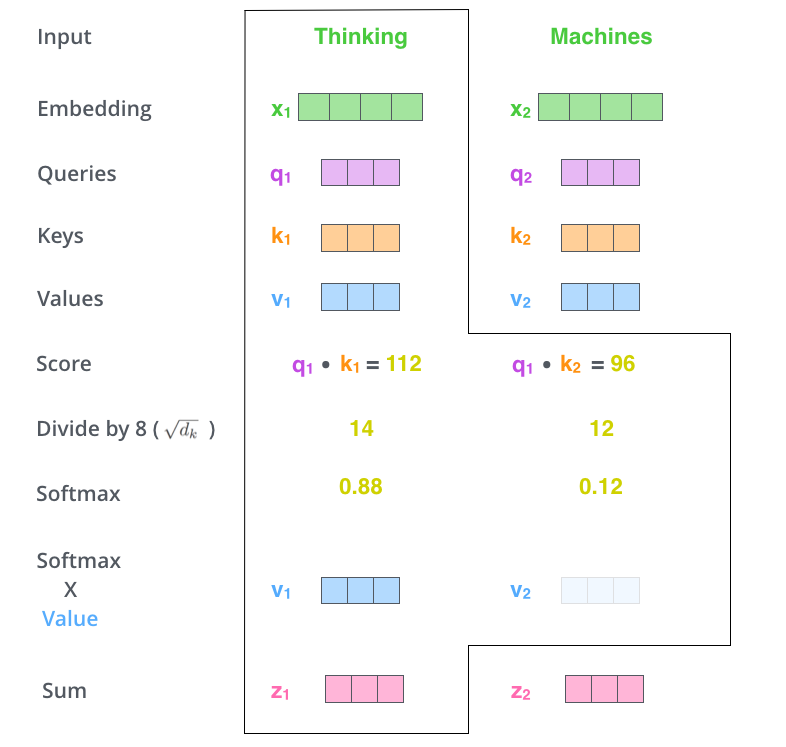
- 점수 계산 : 현재 위치의 단어를 encode할 때 다른 단어들에 대해서 얼마나 집중을 해야 할지 결정
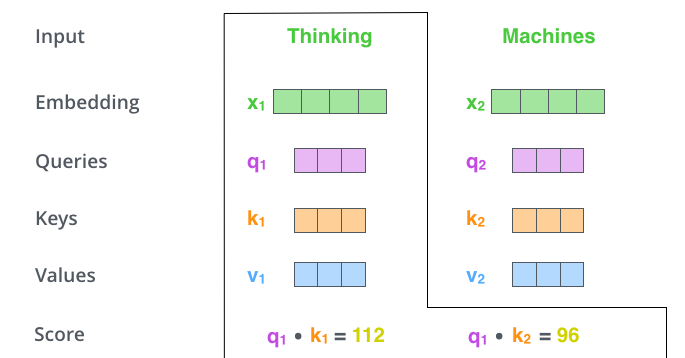
- 현재 단어의 Query vector, 점수 매기려하는 다른 위치에 있는 단어의 Key vector의 내적으로 계산
- 2에서 구한 점수를 8로 나누고, 이 값을 softmax 계산을 통과시켜 모든 점수들을 양수로 만들고 합을 1로 만듦
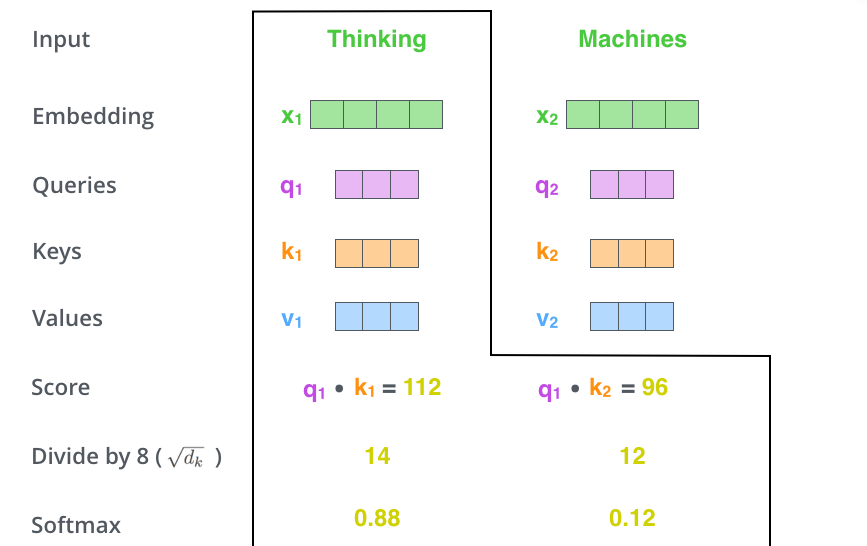
- 8의 의미 : key 벡터 사이즈인 64의 제곱근으로 나눠줌으로써 안정적인 gradient를 구함
- softmax 결과의 의미 : 현재 위치의 단어의 encoding에 있어서 얼마나 각 단어들의 표현이 들어갈지 결정.
-
3과 동일한 작업을 다음 단어에 대해서 진행(여러 단어의 경우 이러한 과정이 늘어나겠지?)
-
입력의 각 단어들의 value 벡터에 3,4에서 구한 점수를 곱함
- 집중을 하고 싶은 관련 있는 단어들 남기고, 관련 없는 단어들은 작은 가중치를 곱함으로써 다음 단어를 예측함에 있어서 의미를 없애버리기 위함
- 5에서 얻은 weighted value 벡터들을 다 합함 -> 현재 위치에 대한 self-attention layer 출력
위에서 나온 결과 벡터를 feed-forward neural network의 입력으로 보냄
Self-attention의 행렬 계산
- Query, Key, Value 행렬 계산
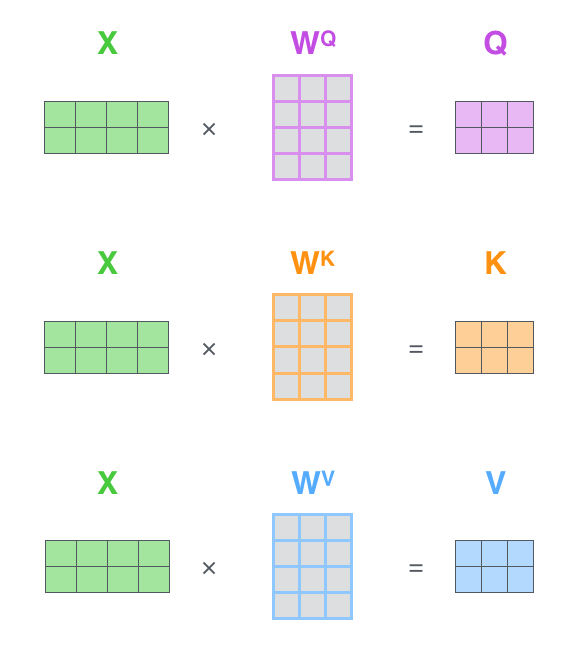
- X : 입력 문장의 각 단어 의미
- 하나의 식으로 압축
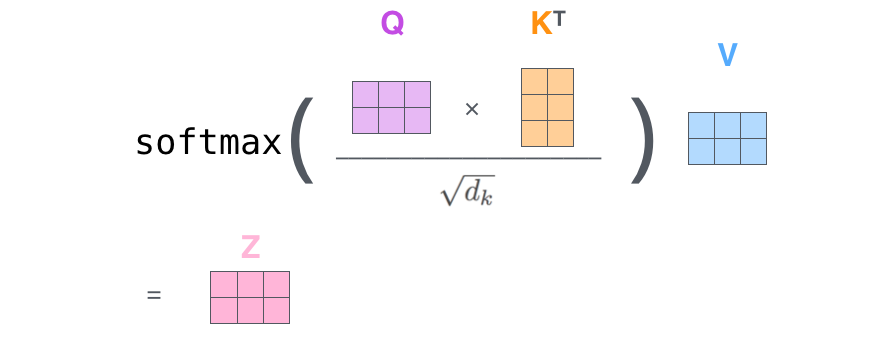
The Beast With Many Heads
- 본 논문 contribution : self-attention layer + "multi-headed" attention mechanism 으로 성능 향상
- 현재 위치의 단어에만 집중하는 것이 아닌 다른 위치의 단어에 집중하는 능력 확장 -> 단어간 개연성, 연관성을 알아냄에 있어 강력할 듯
- attention layer가 여러 개의 "representation 공간"을 가지게 함
- multi-headed attention 으로 여러 query/key/value weight 행렬을 가짐
- 8개의 multi-head attention이 있다는 것은 각 word embedding 마다 8개의 query, key, value vector가 있다 = 다양한 representation 공간에서 표현이 되고 각 공간마다 목적이 다르기 때문에, 문장을 구성하는 단어끼리 다양한 목적과 방법으로 관계를 파악한다고 이해
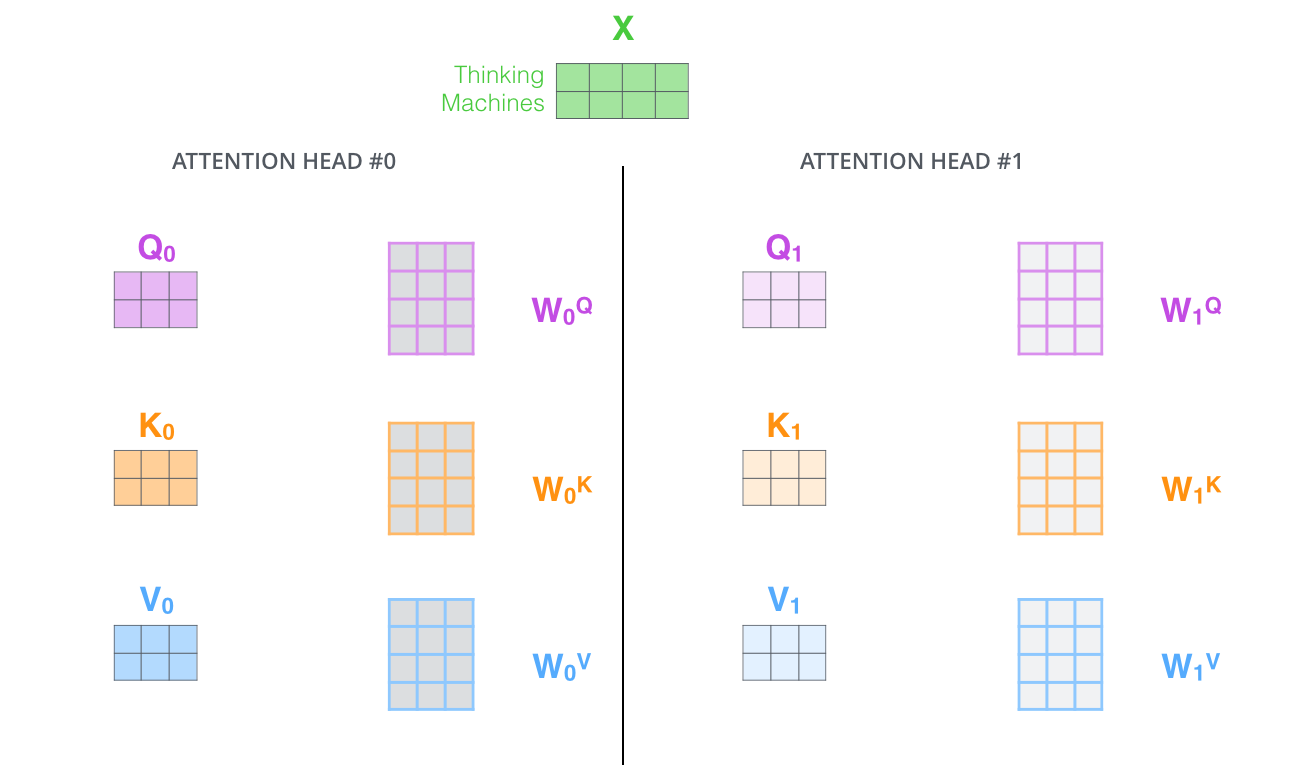
- multi-headed attention을 이용하기 위해 각 head 마다 다른 query/key/value weight 행렬들을 모델에 가지게 됨
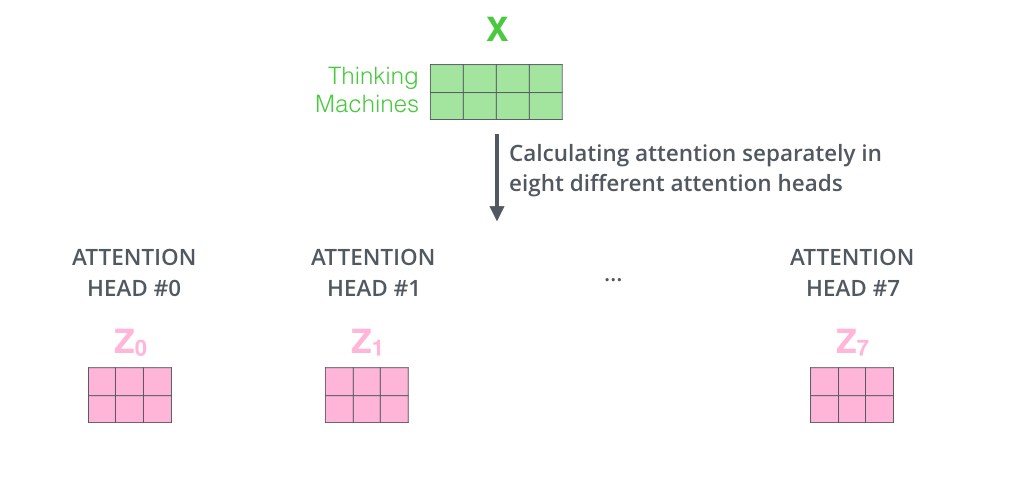
- 8개의 서로 다른 Z 행렬을 가지게 됨
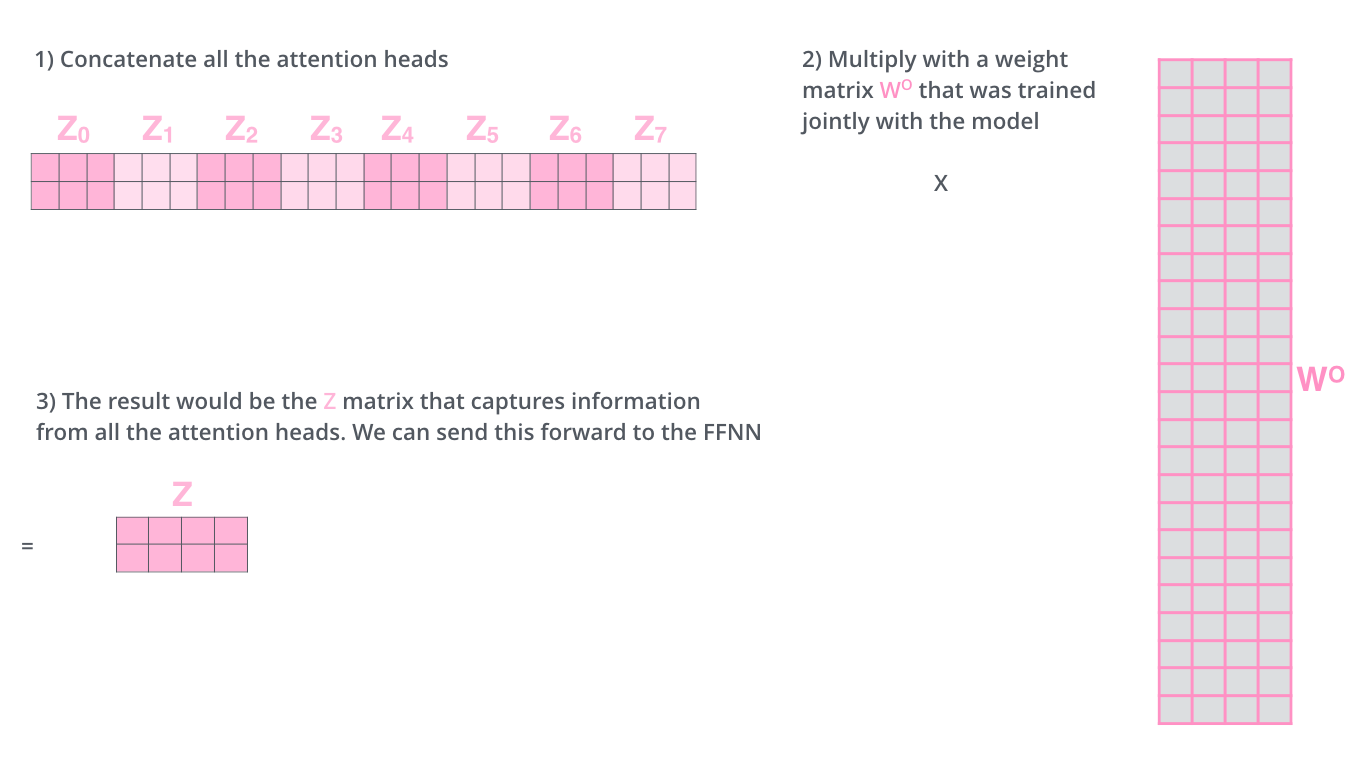
- 8개의 행렬을 바로 feed-forward layer로 보낼 수 없음 -> 8개의 행렬을 이어 붙여서 하나로 만들고 행렬 를 곱함 ??? 는 어떤 행렬이지...
- multi-headed attention을 이용하기 위해 각 head 마다 다른 query/key/value weight 행렬들을 모델에 가지게 됨
- 요약
- 결과 예시

- 'it'이라는 단어를 볼 때, 두 개의 attention head에서 유독 'the', 'animal', 'tire'에 대한 attention 값이 높은 것을 확인할 수 있음
- 인간이 문장을 보고 it의 의미를 추론할 때도 다양한 관점으로 볼 것인데 그러한 각 관점들이 8 multi-head로 구현이 된 것이라 보는게 제일 좋을 듯
multi-head를 ensemble과 비슷하게 봐도 될 듯...?
Positional Encoding을 이용해서 시퀀스의 순서 나타내기
- Transformer에서 RNN과 달리 입력 문장에서 단어들의 순서에 대해 고려하는 방법 - 각 모델의 embedding에 "positional encoding"을 추가
- "Positional encoding" : 단어의 위치, 시퀀스 내의 다른 단어 간의 위치 차이에 대한 정보 알 수 있게 해줌
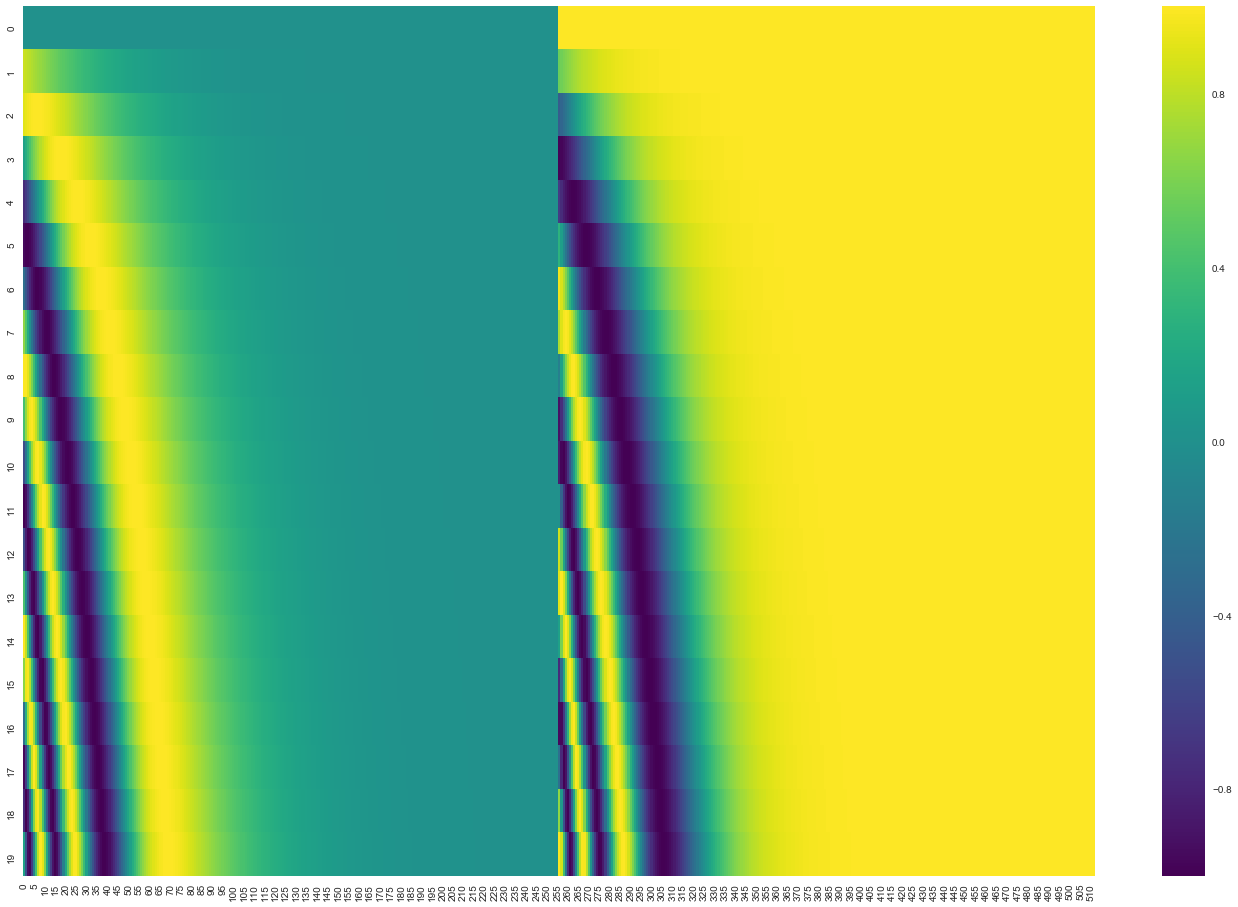
- scalability에서 큰 이점을 가진다네...
- "Positional encoding" : 단어의 위치, 시퀀스 내의 다른 단어 간의 위치 차이에 대한 정보 알 수 있게 해줌
The Residuals
![]()
- Encoder 내 sub-layer 들이 residual connection 과 연결, sub-layer 후에 layer-normalization 과정을 거침
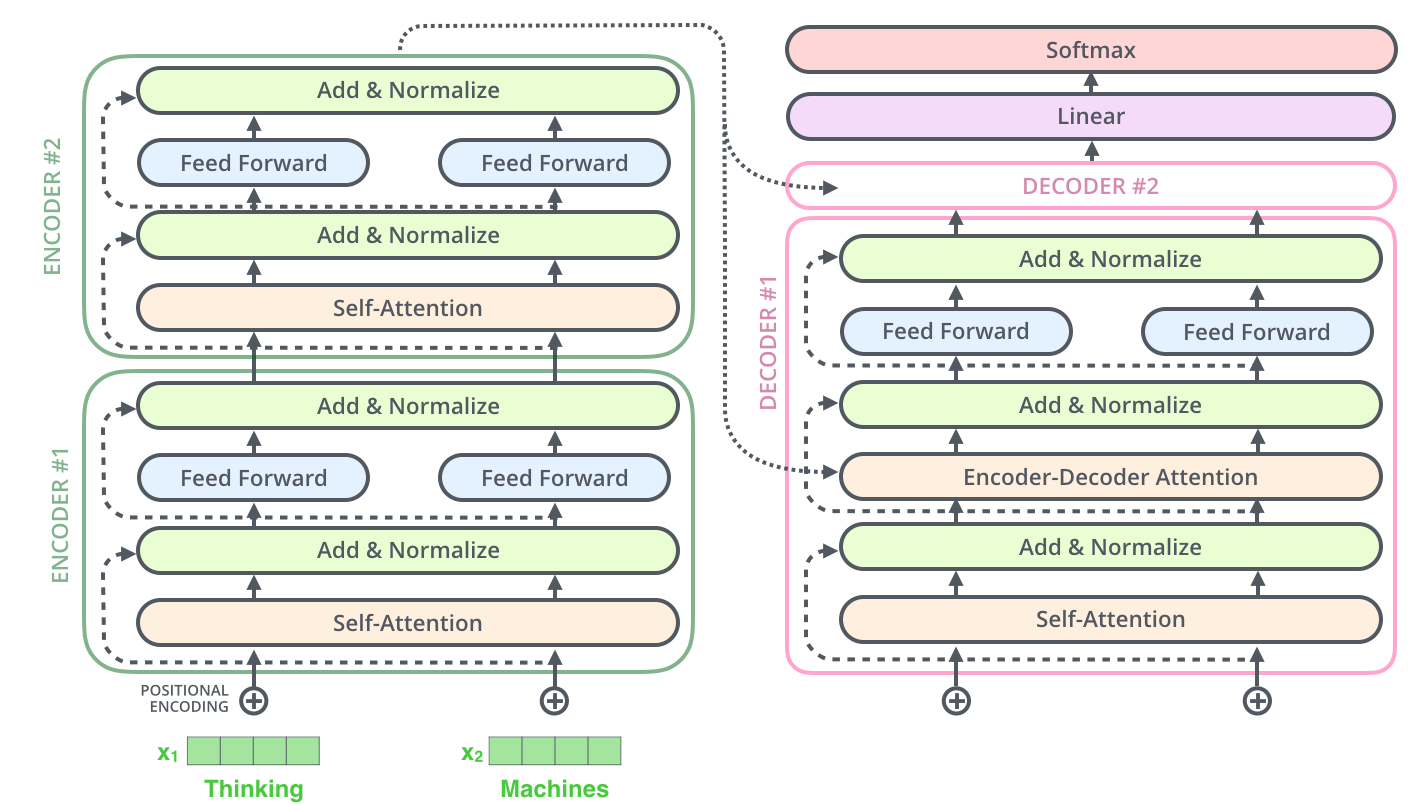
- Decoder 내의 sub-layer 들에도 똑같이 적용
The Decoder Side
- Decoder도 Encoder의 각 부분들에 대해서는 비슷하게 동작
- Input : Encoder의 출력을 attention 벡터 K, V로 변형
- Encoder 동작의 결과
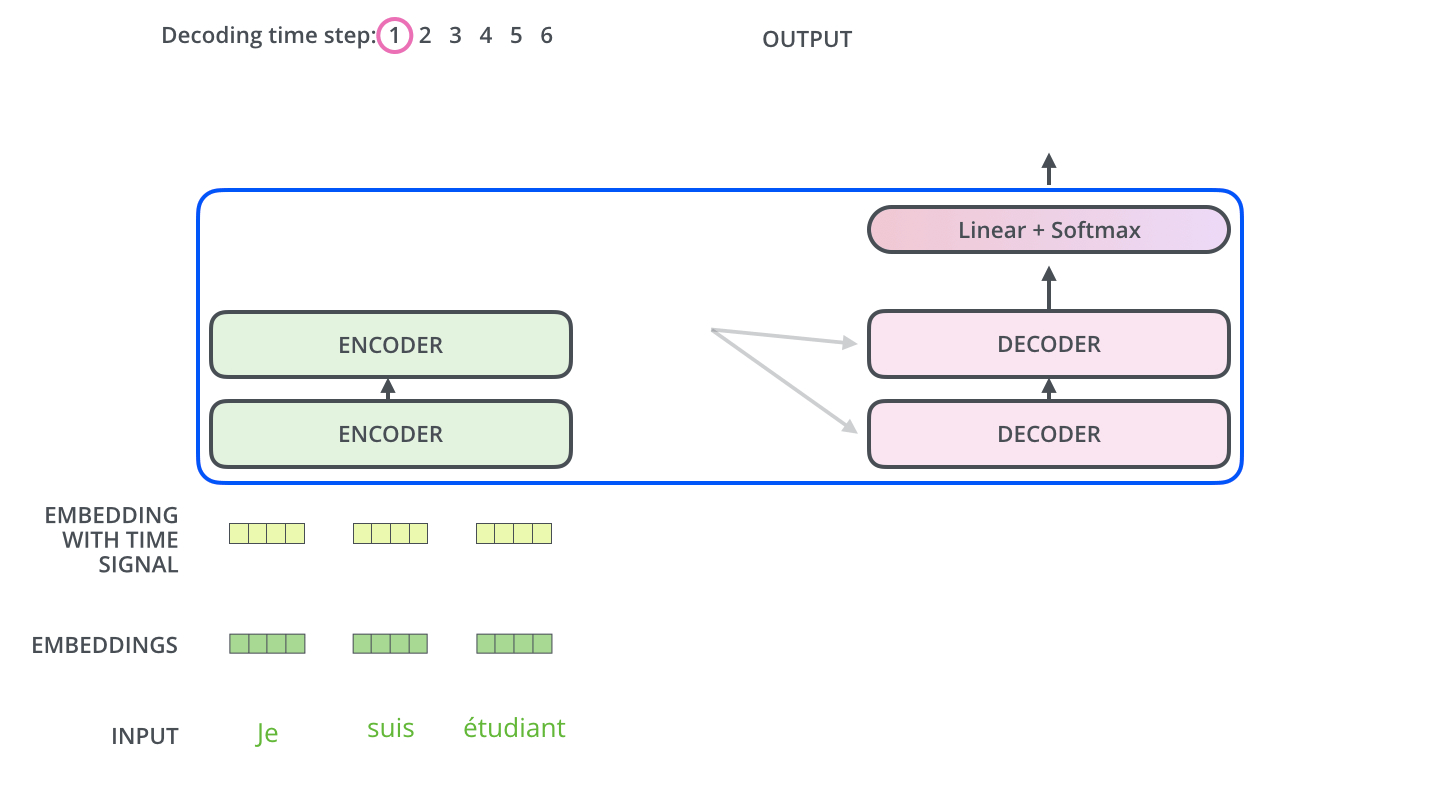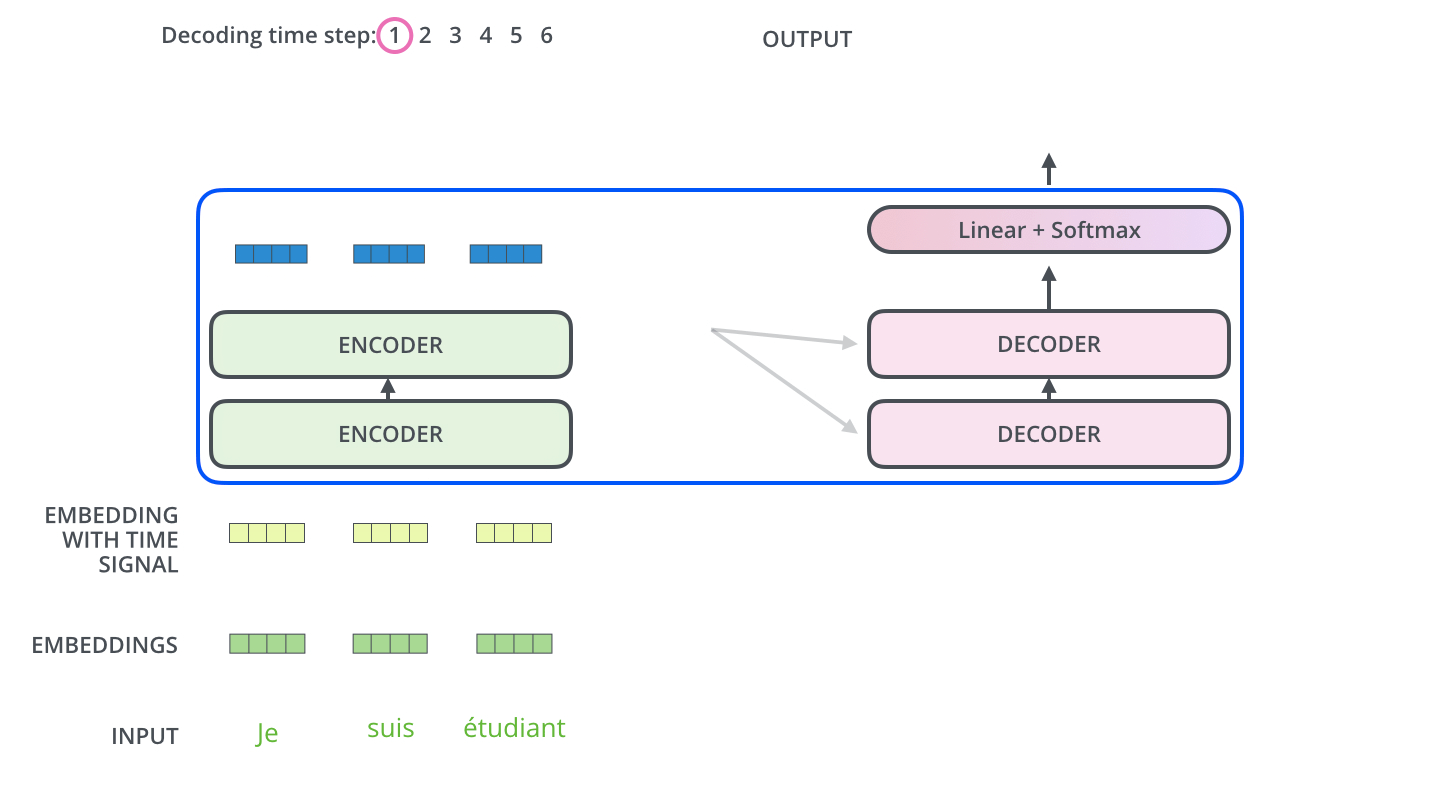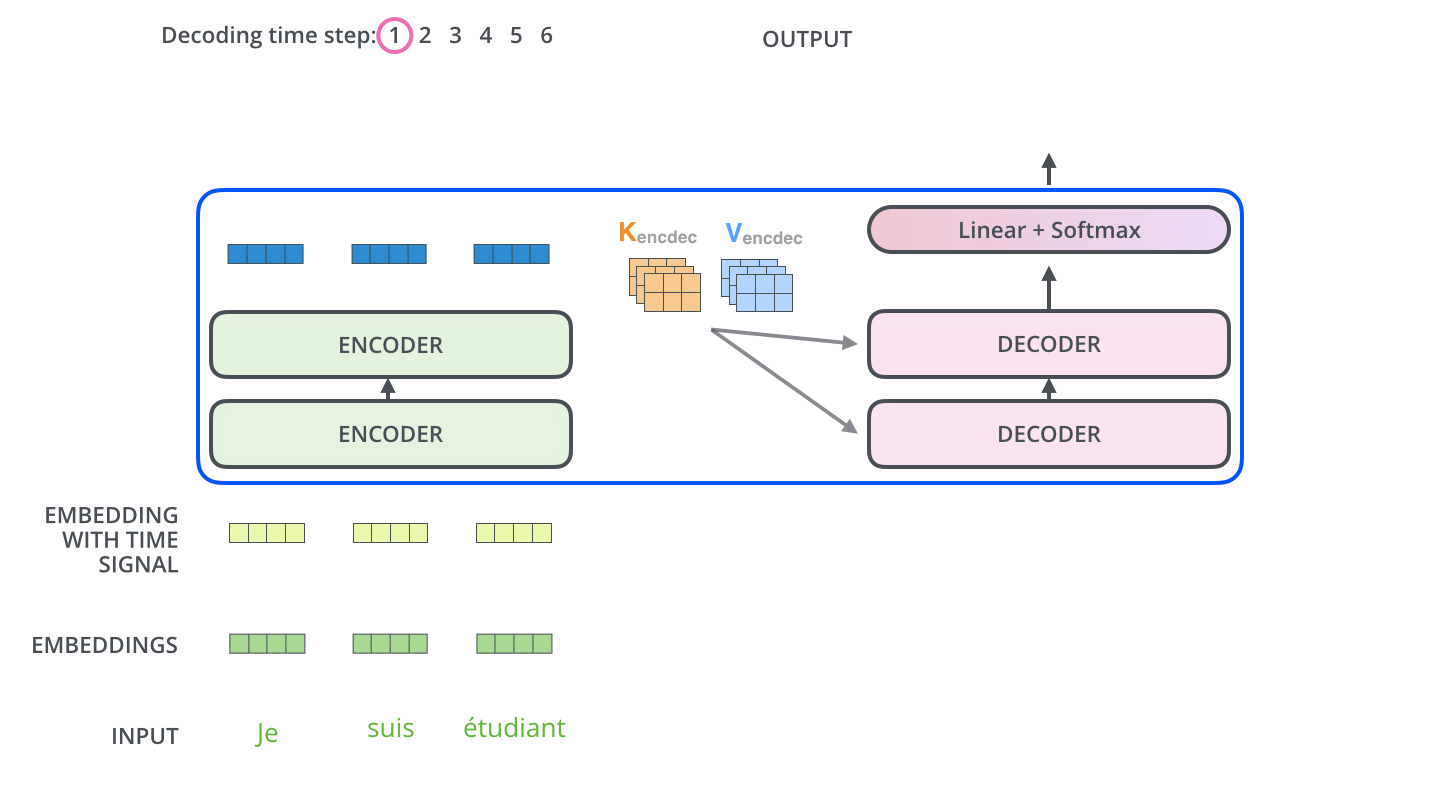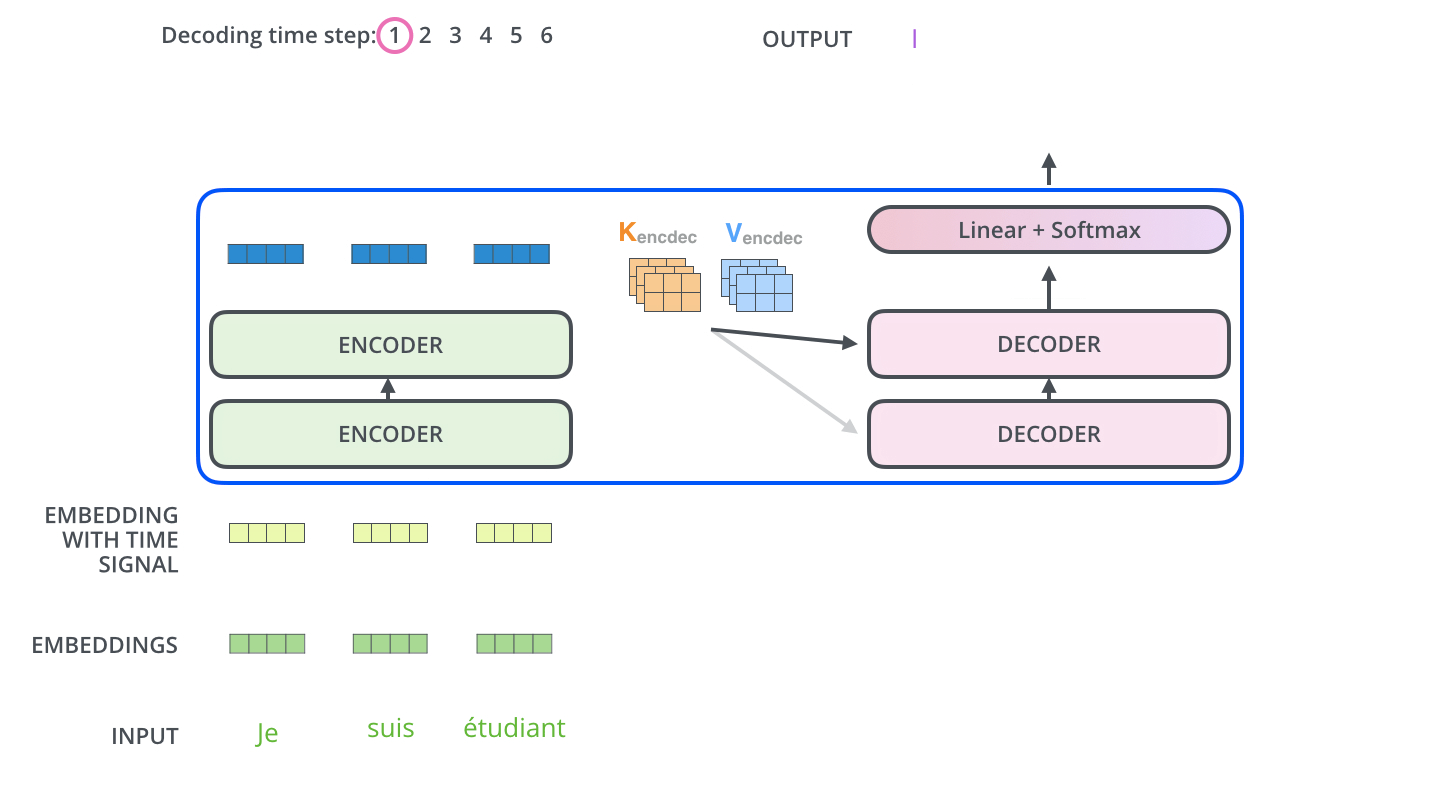
- Encoder 동작의 결과
- Decoding 동작
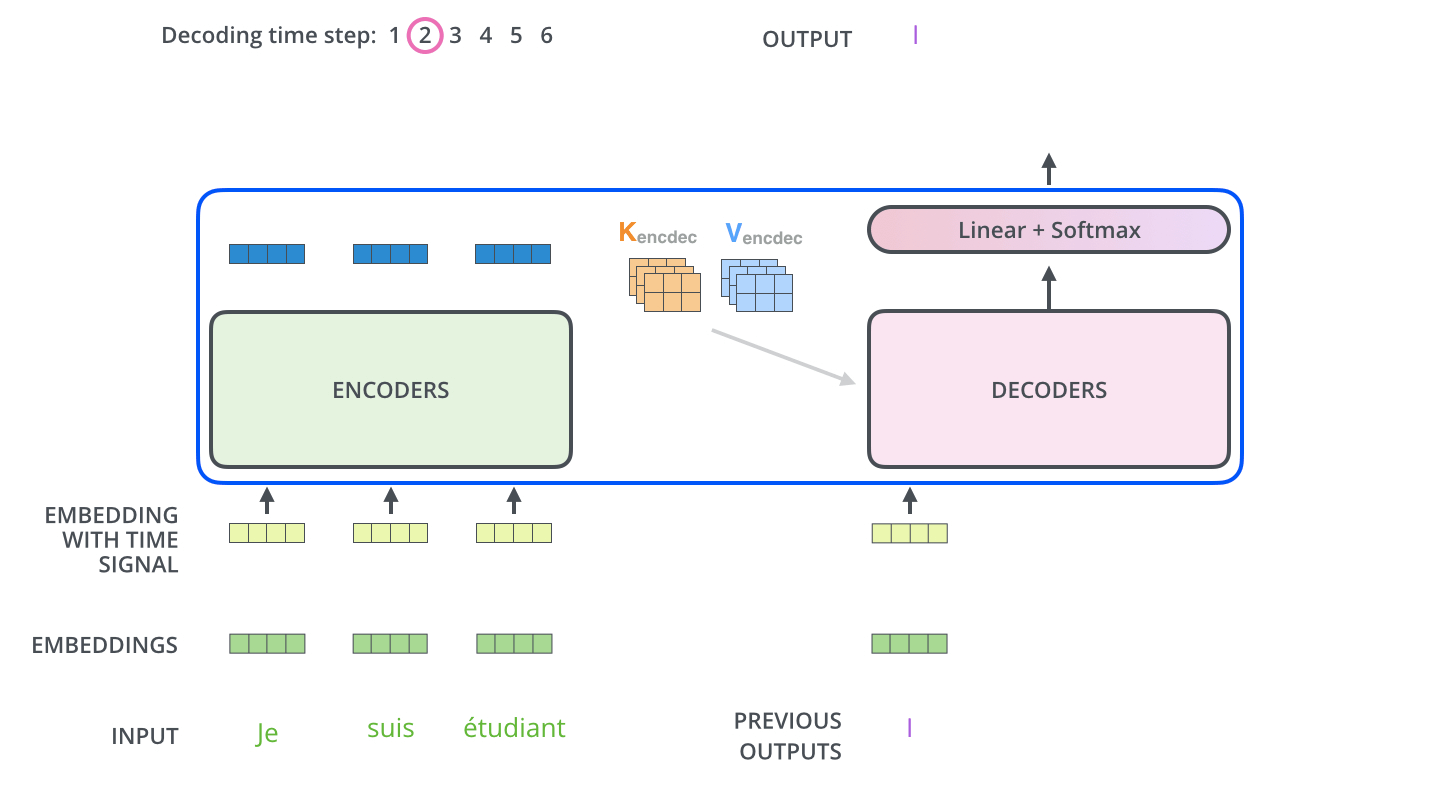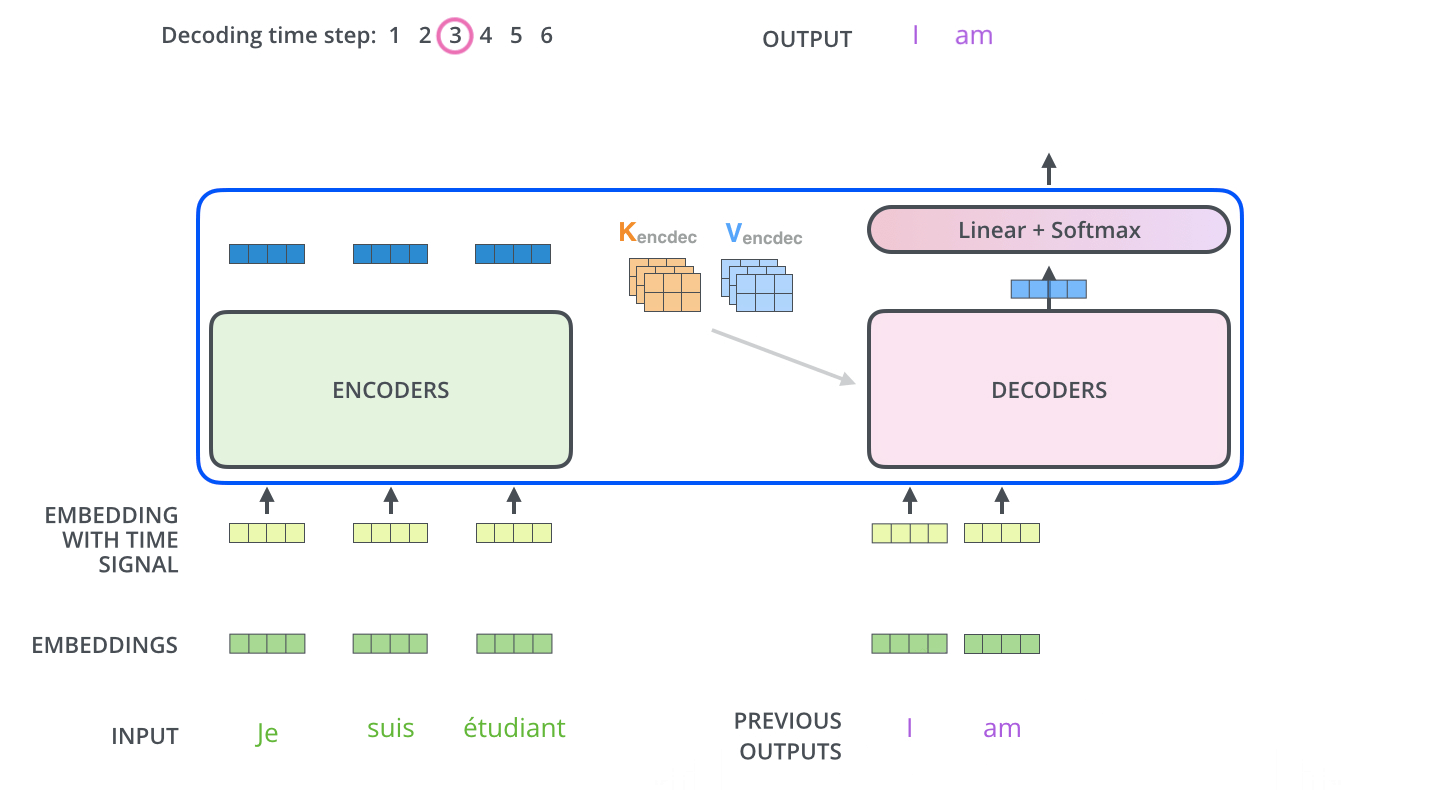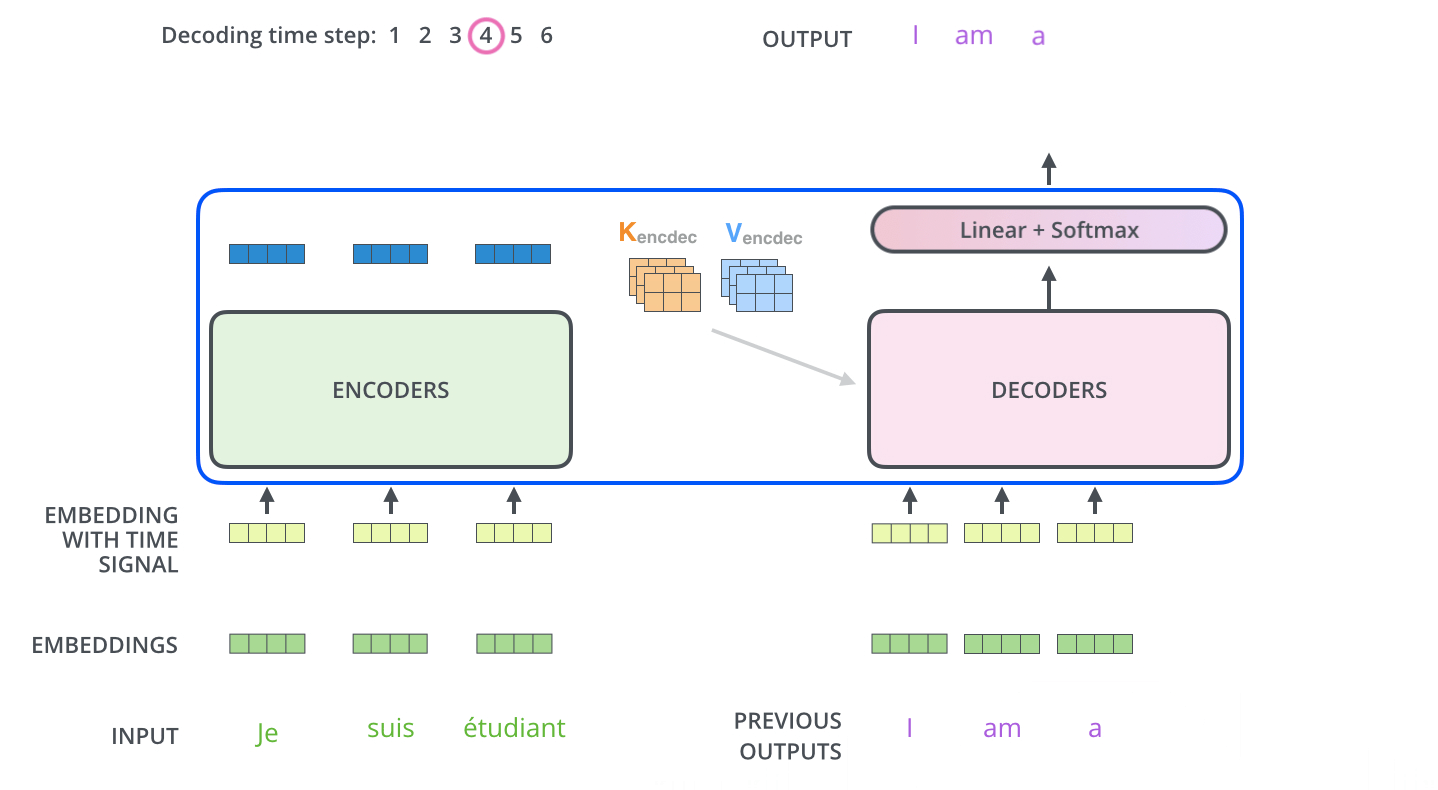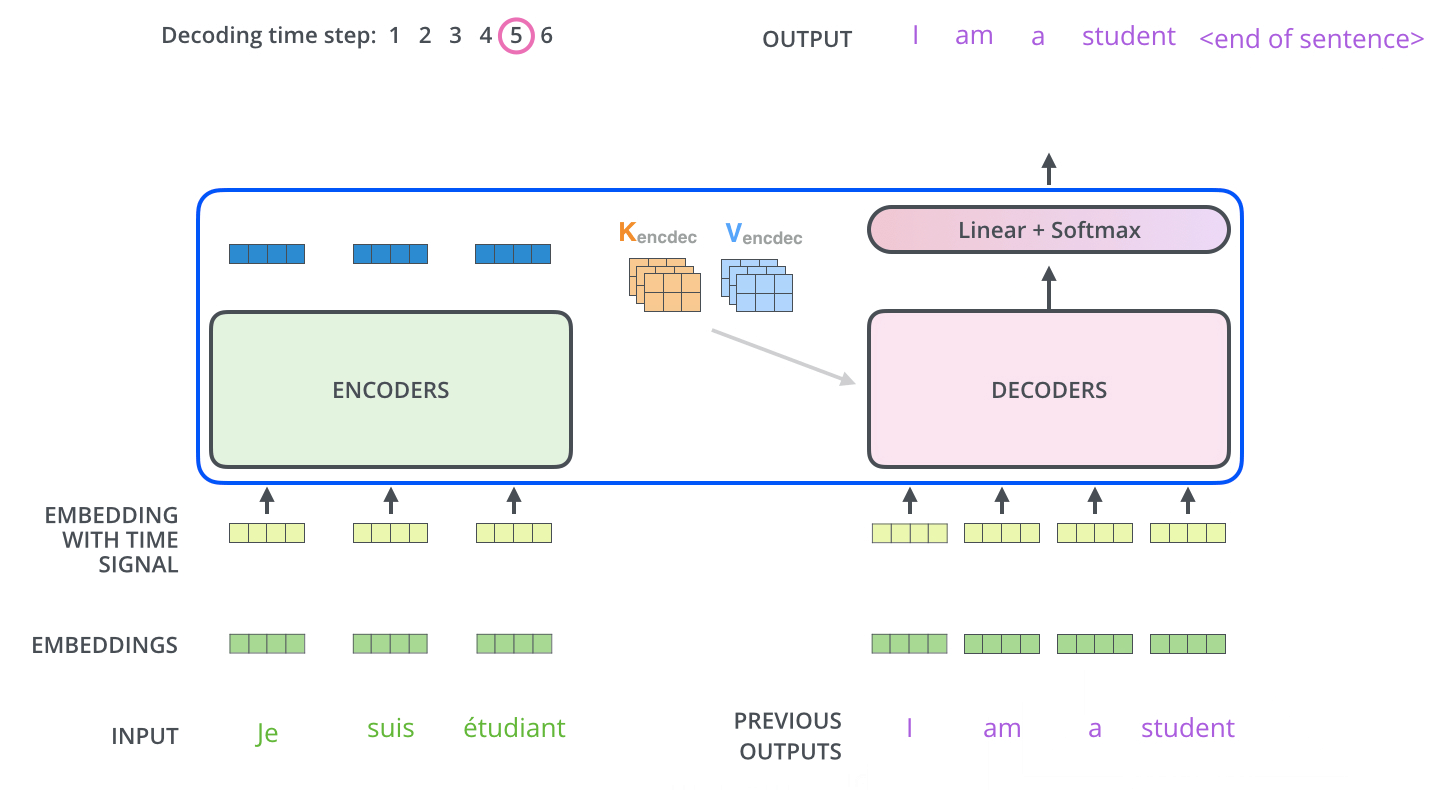
- 출력 시퀸스(출력 문장의 한 단어)를 각 단계마다 Decoder 동작을 통해 얻음( 출력할 때까지 동작)
- 각 Decoder 단계는 이전 decoder의 결과를 입력으로 받아서 embed 한 후 positional encoding 추가하여 위치 정보까지 더해서 처리
- masked multi-head attention
self-attention layer: Decoder의 self-attention은 현재 위치 이전 위치들에 대해서만 attend 함. 계산 과정에서 softmax 취하기 전 현재 스텝 이후의 위치들에 대해서 masking 해줌으로 가능..? - Encoder-Decoder attention : Query 행렬들을 그 밑의 layer에서 가져오고 Key, Value 행렬들은 encoder의 출력에서 가져오는 것 제외하곤 multi-head self-attention과 동일하게 동작
- 출력 시퀸스(출력 문장의 한 단어)를 각 단계마다 Decoder 동작을 통해 얻음( 출력할 때까지 동작)
마지막 Linear Layer, Softmax Layer
- Linear Layer : fully-connected 신경망. decoder가 마지막으로 출력한 벡터를 그보다 훨씬 더 큰 사이즈의 벡터인 logits vector로 투영
- ex : 10000개의 영어 단어를 학습하였을 때, logits vector의 크기는 10000이 된다. 벡터의 각 셀은 그에 대응하는 각 단어에 대한 점수가 됨 -> linear layer의 결과로 나오는 출력에 대한 해석이 가능해짐
- Softmax Layer : Linear layer에서 나온 점수들을 확률로 변환해줌. 가장 높은 확률 값을 가지는 셀에 해당하는 단어가 해당 스텝의 최종 결과물이 됨
나머지 뒷 부분은 구현과 연관된 부분이라 다음에..\
참조

Be Smart with 성실한 호기심