Convolutional Neural Network (CNN)
Convolutional Layer
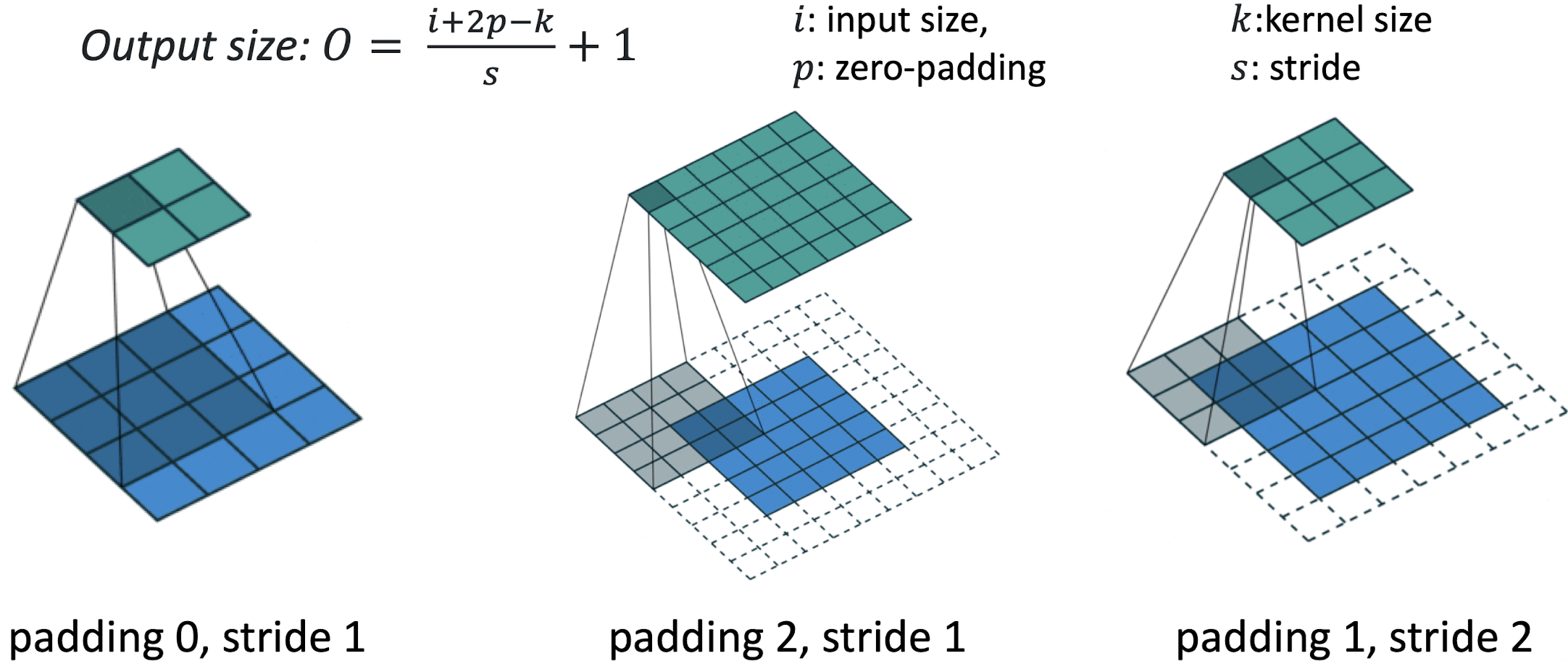
위 그림에 나와 있는 식은 Input Size, Kernel Size, Zero-Padding과 Stride에 따른 Output Size를 계산하는 식이다.
Dilation
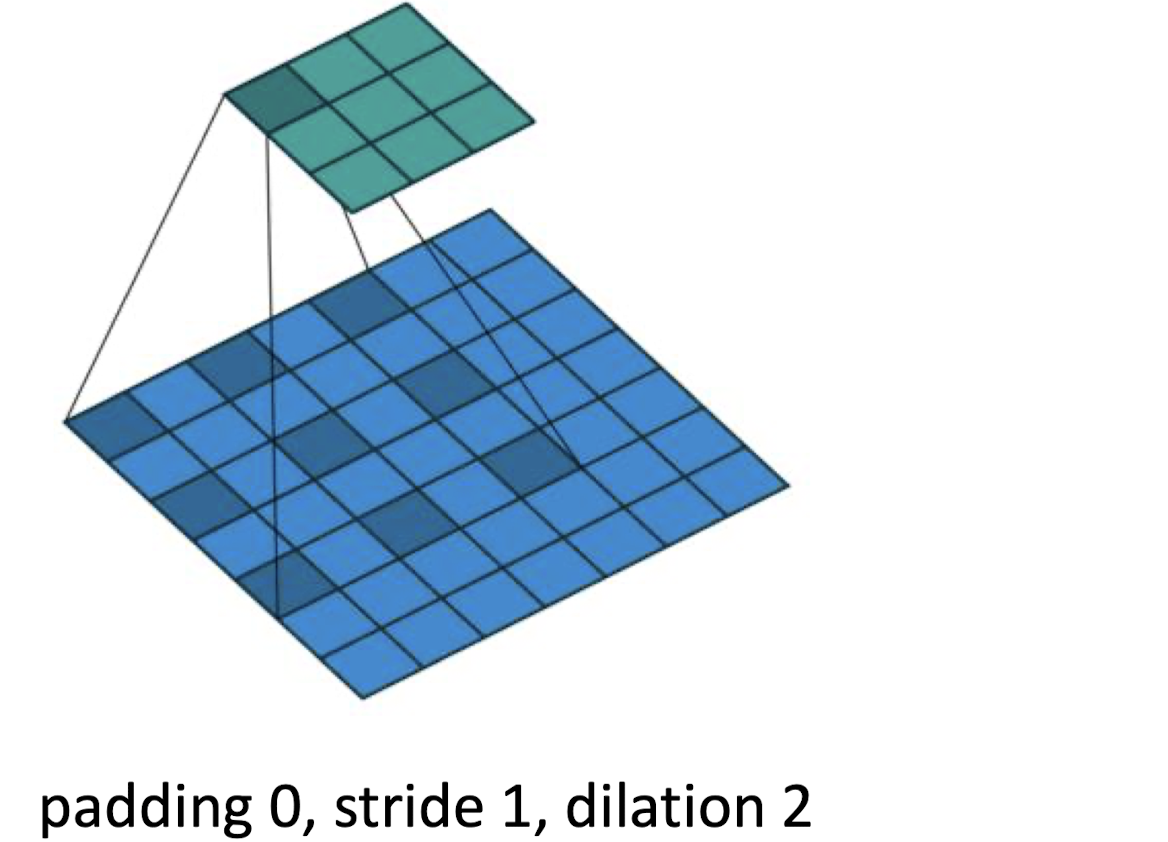
Dilation한 Convolution Layer는 Input을 몇 칸씩 띄어가면서 반영한다.
Conv2D에서 dilation_rate을 지정함으로서 구현할 수 있다.
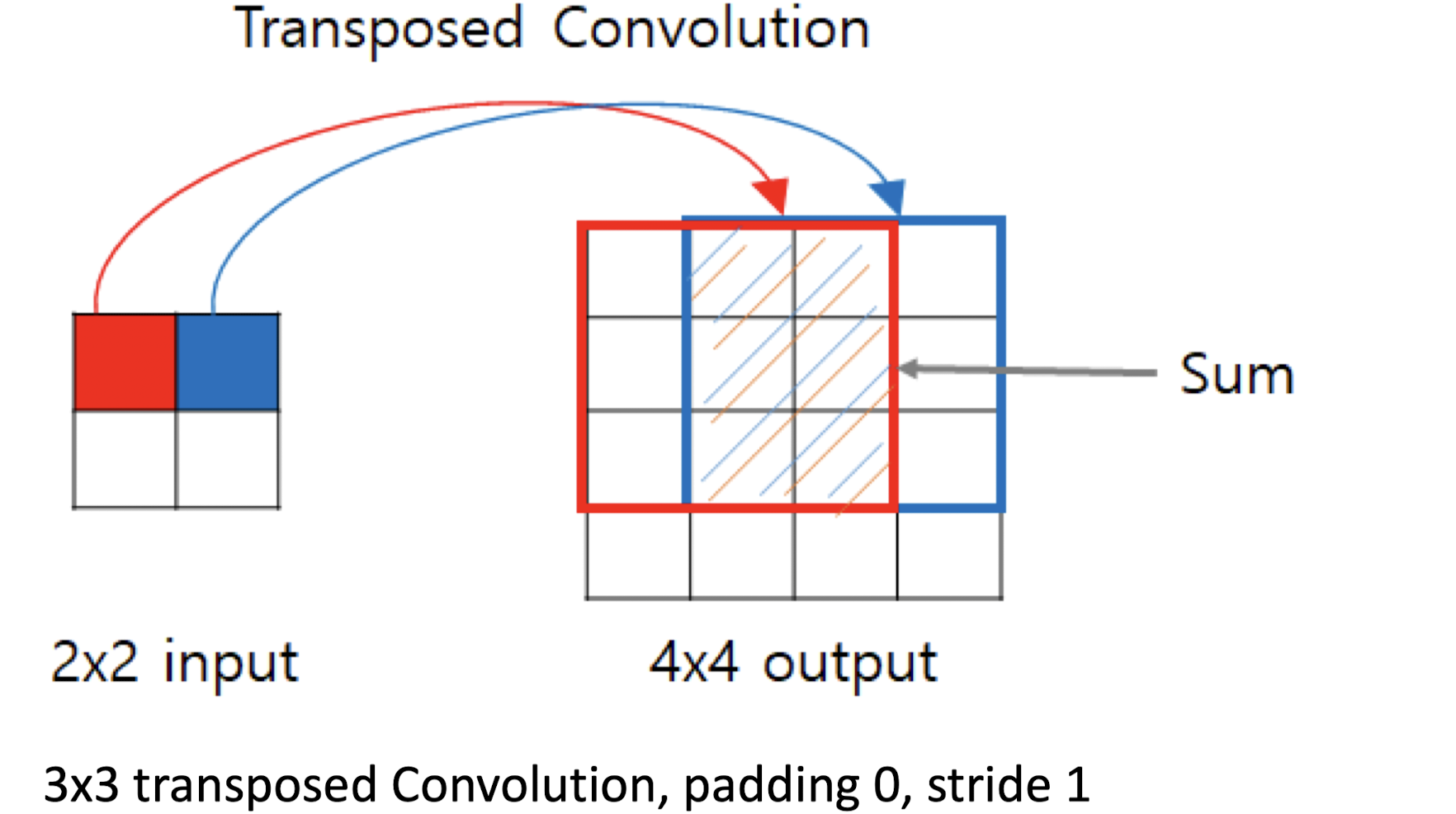
Transposed Convolution
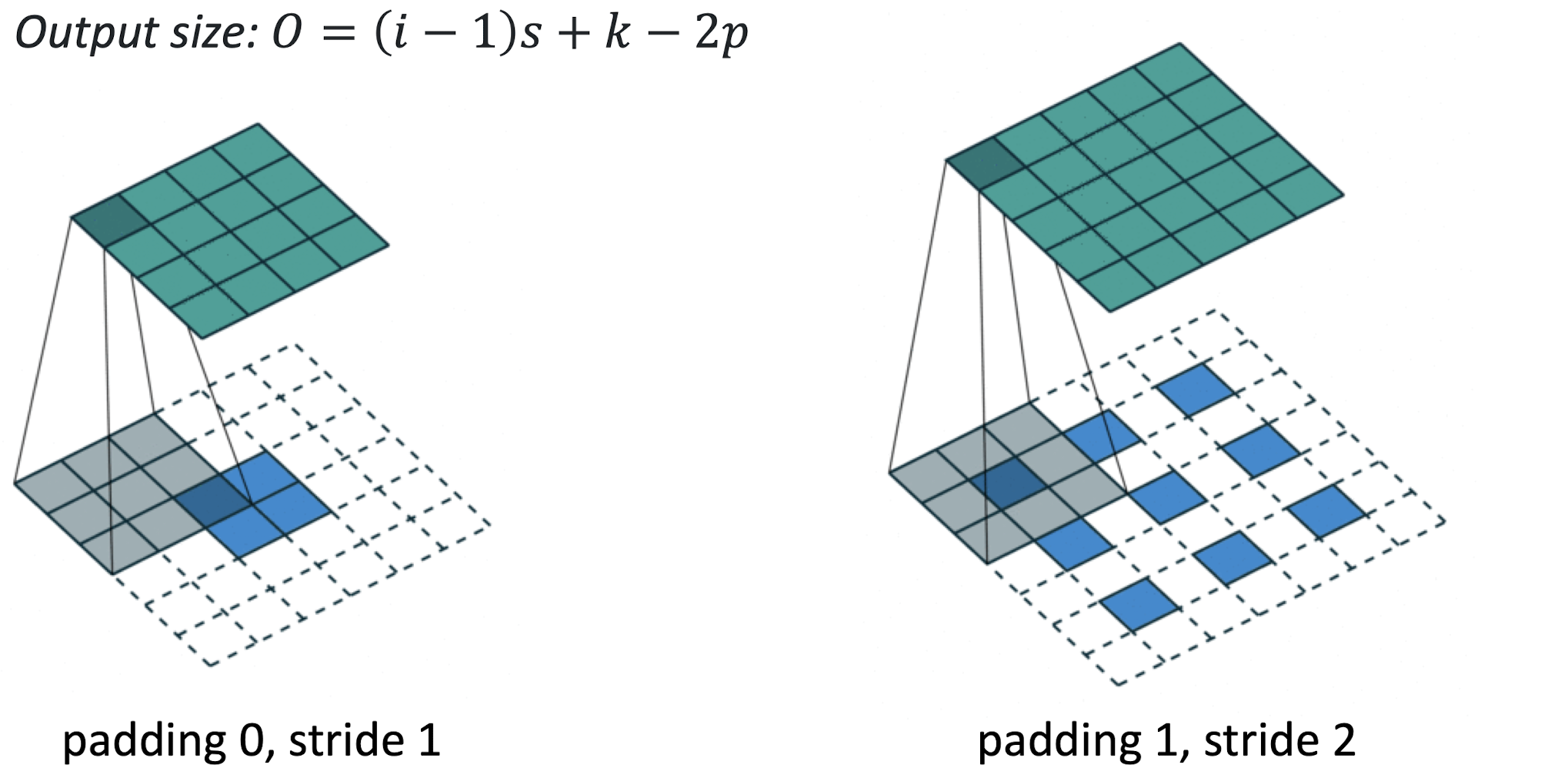
Transposed Convolution이란 데이터를 원래 크기로 되돌리기 위한 과정이다.
Output Size는 Convolutional Layer의 Output Size 계산식에서 i와 O를 치환해서 구한 식을 통해 얻을 수 있다.
Pooling Layer
Pooling Layer란 데이터 사이즈를 줄이기 위한 Layer이다.
Pooling Layer의 종류로는 Max Pooling, Average Pooling, L2-norm Pooling이 있다.
Max Pooling
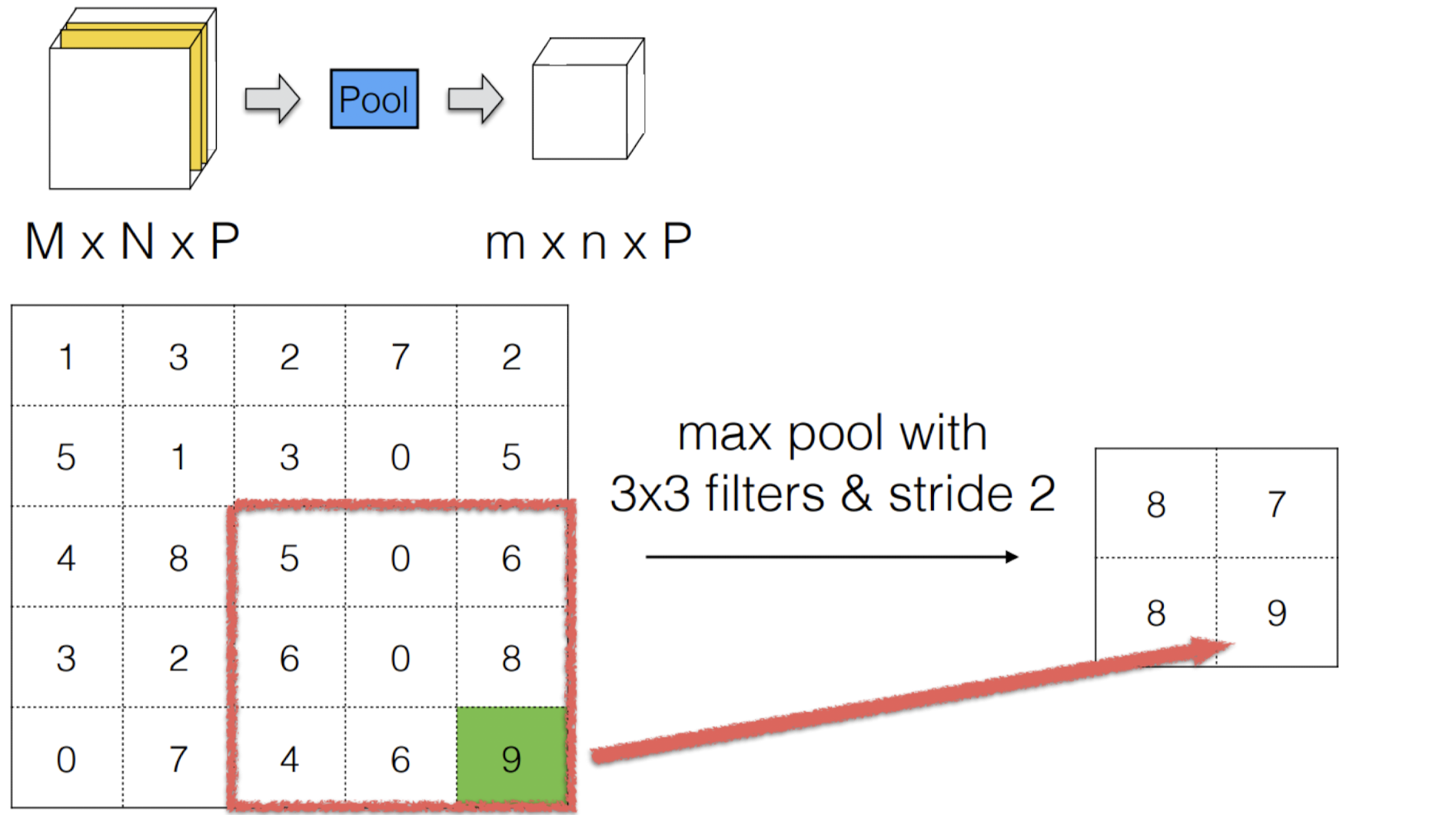
Max Pooling이란 filter 크기 중에 가장 큰 값만을 선택하는 것이다.
이렇게 함으로써 데이터 사이즈를 줄일 수 있다.
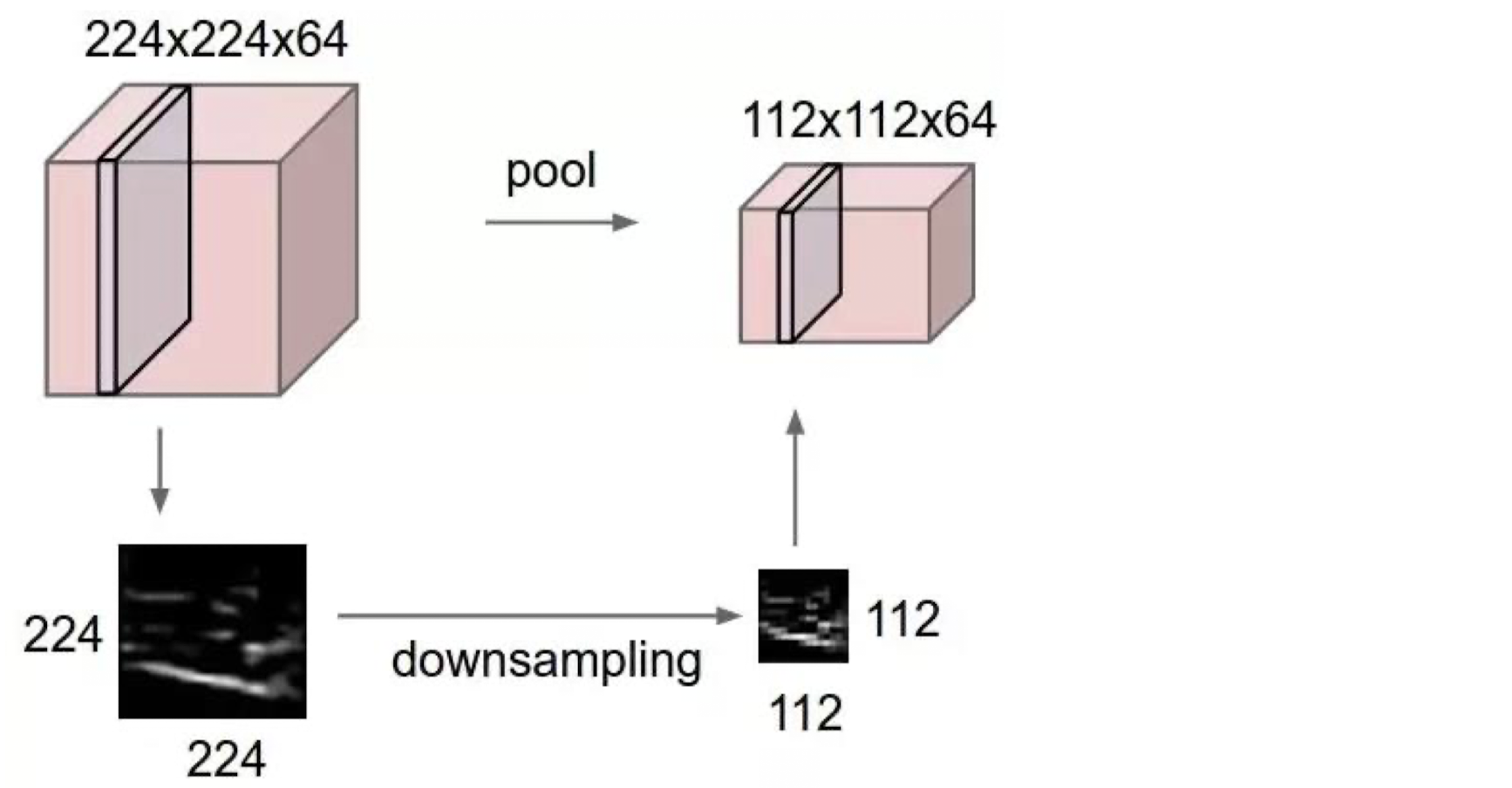
Max Pooling을 통해 데이터를 Downsampling한 모습이다.
Softmax Layer
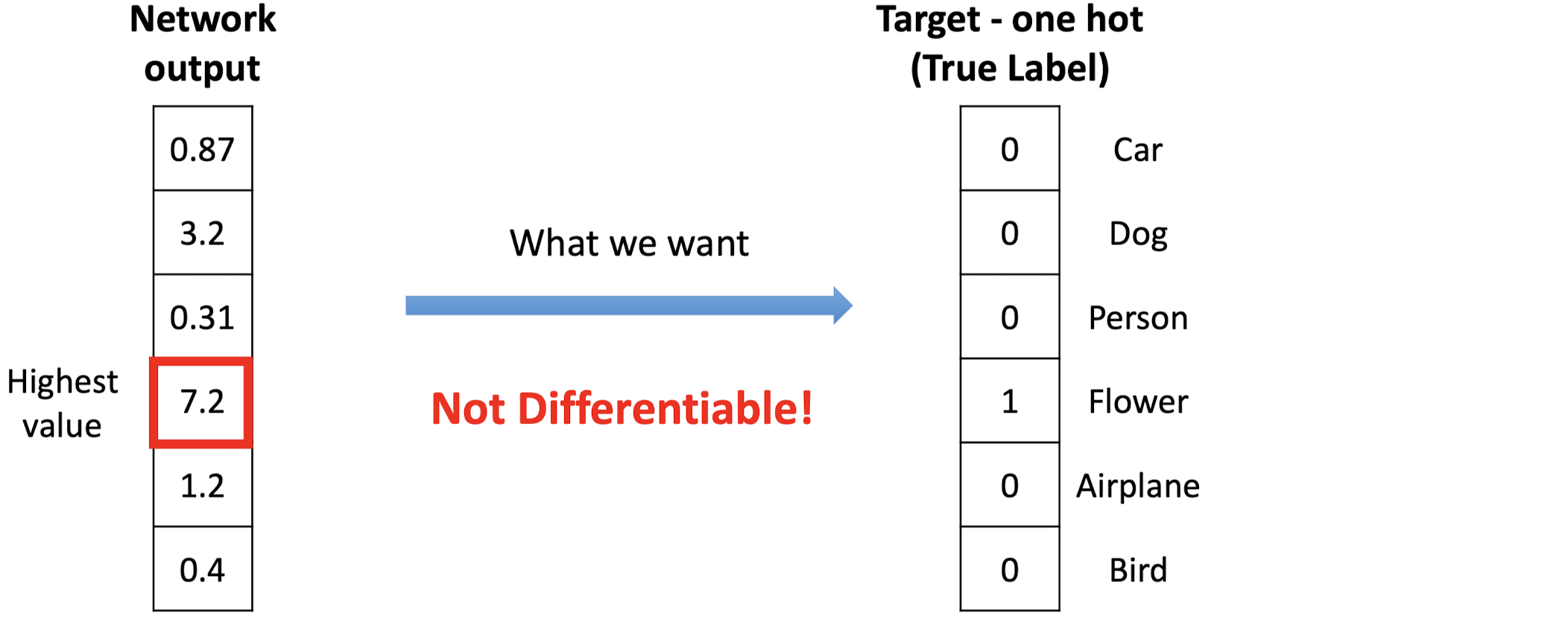
Softmax Layer에서는 Output을 타겟 확률과 매핑한다.
이때, 두 변수 사이에 미분 관계가 성립하도록 하기 위해 사용하는 방법이 Softmax이다.

위의 수식을 사용해 나온 Softmax 결과값과 타켓 확률은 미분 가능해진다.
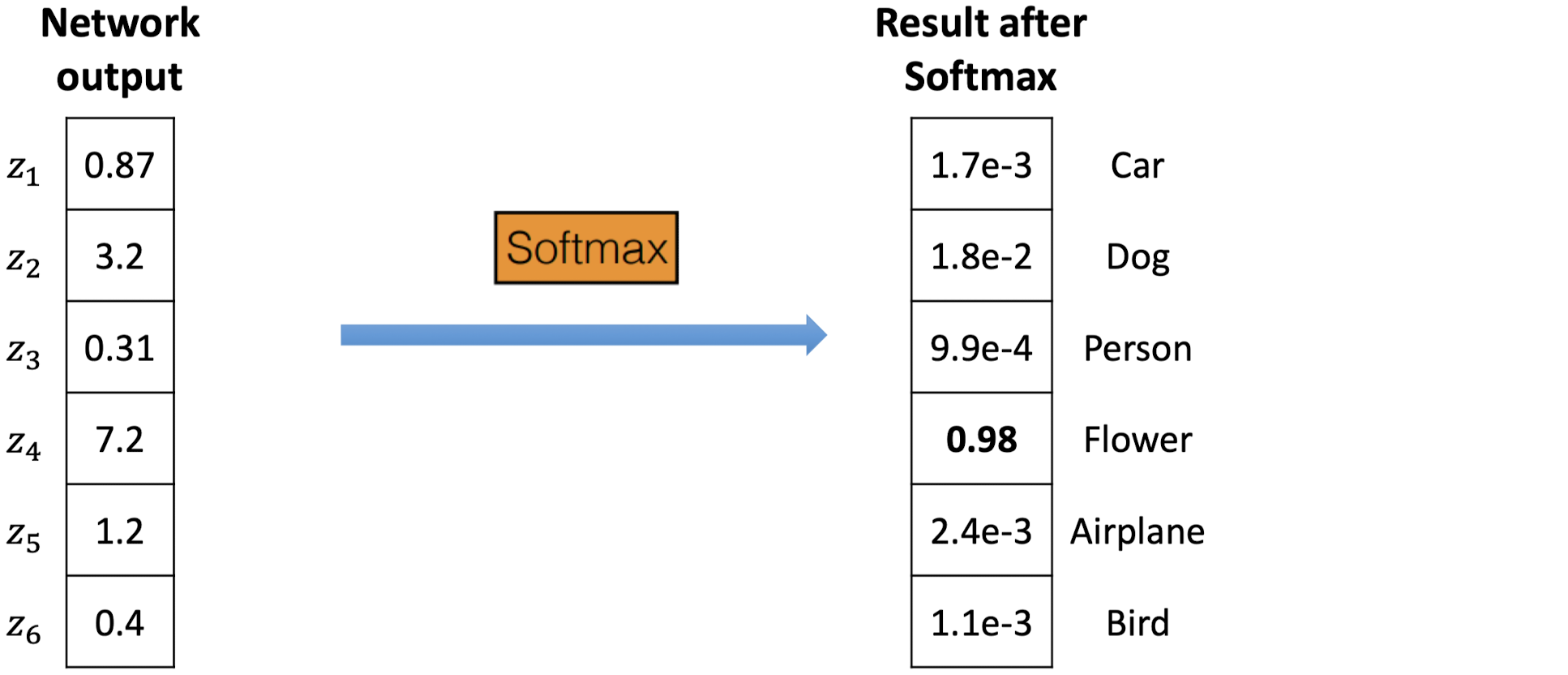
위의 그림처럼, Softmax를 거치면 결과값이 합쳐서 1이 되고, 차이가 커진다.
Cross Entropy Loss
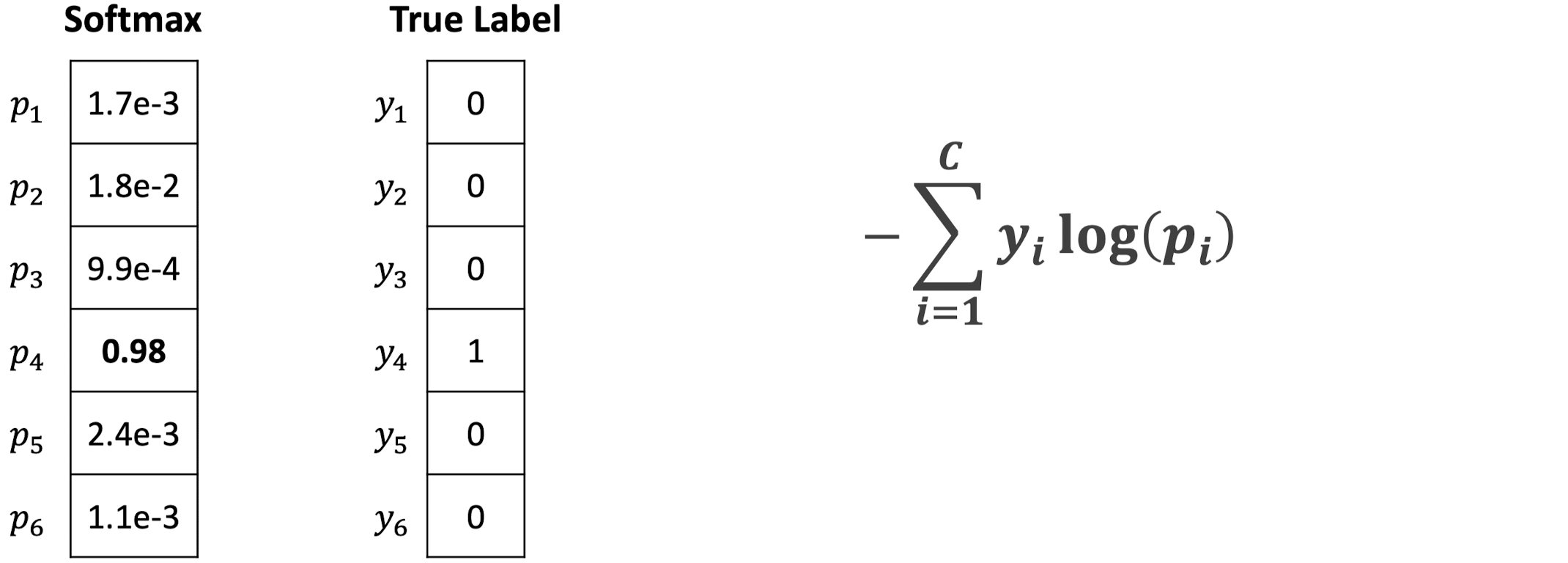
Cross Entropy Loss를 통해 확률 분포끼리 비교할 수 있다.
밑의 그림은 True Label이 1일 때 x축을 p_i, y축을 -log(p_i)로 하는 그래프이다.

p_i 값이 1에 가까울수록 Loss가 작은 것을 확인할 수 있다.
Activation Function

위의 그림처럼 Linear한 관계만 있다면 복잡한 계층도 결국엔 하나의 Matrix 곱으로 귀결된다. 이렇게 되면 CNN의 다층 구조의 의미가 퇴색해진다.
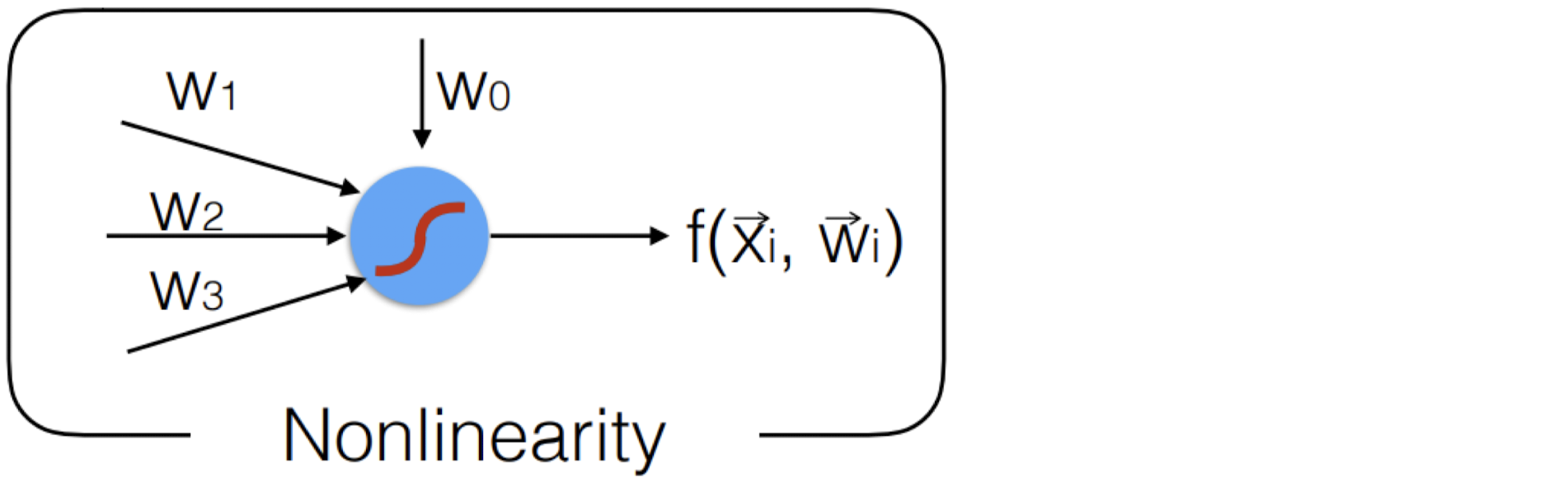
따라서 Activation Function을 이용해 Nonlinearity하게 만드는 것이 CNN의 핵심이다.
이때 Backpropagation을 수행하기 위해선 CNN의 전 계층이 미분 가능해야 한다.
미분 가능하도록 해주는 함수가 Activation Function이다.
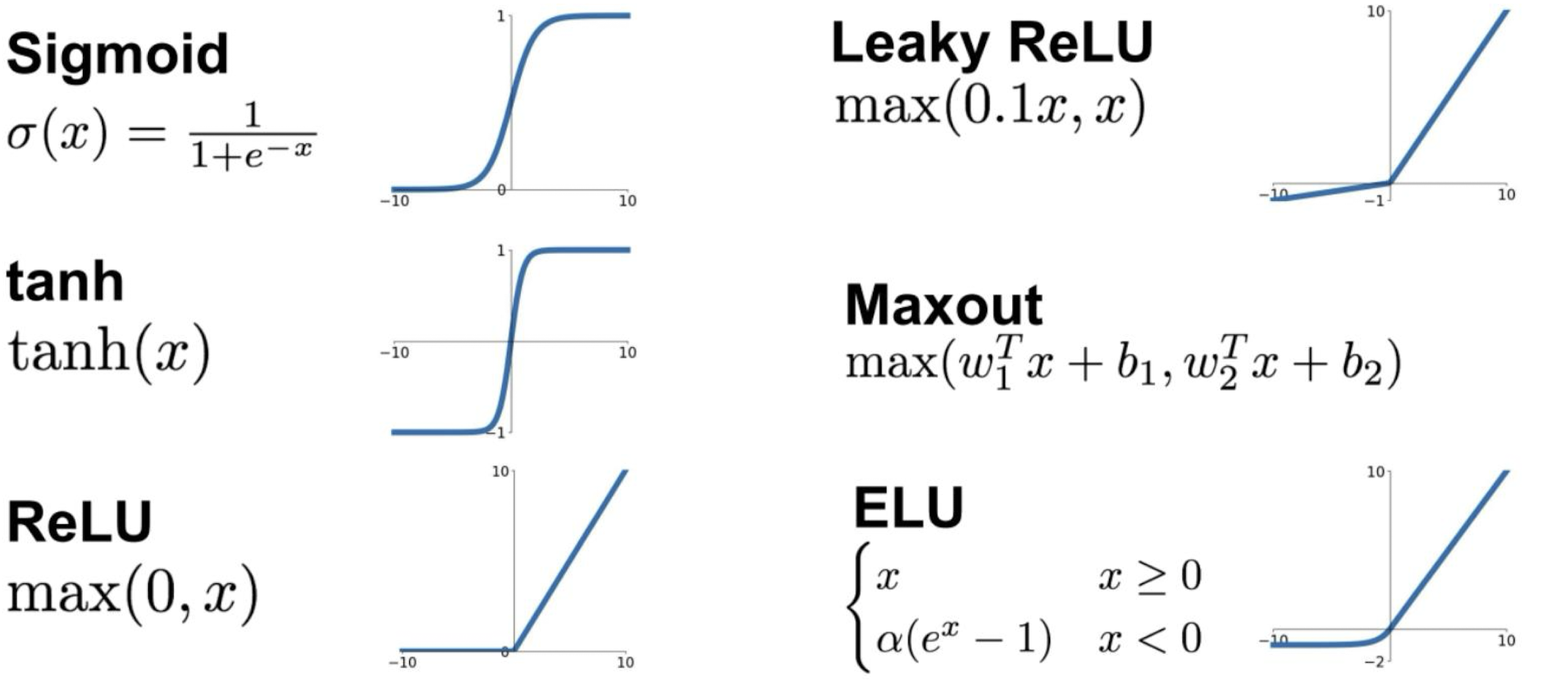
각 Activation Function들은 장단점이 있다.
몇 가지 Activation Function의 장단점에 대해 알아보자.
Sigmoid
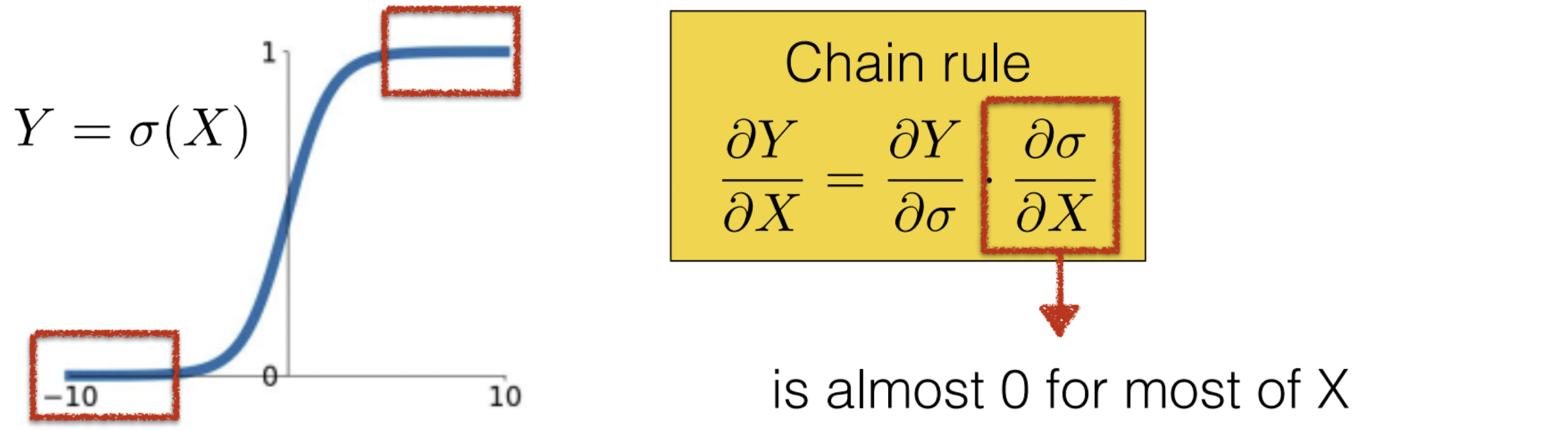
Backpropagation 시에 Chain Rule에 의해 Activation Function의 값이 0에 가까우면 전체 미분값 자체가 0에 가까워져서 미분값이 거의 쓸모 없어지는데, 이것을 Gradient Vanishing라고 한다.
Sigmoid는 미분값이 0에 가까워 Gradient Vanishing이 일어나는 구간이 많다는 단점이 있다.
ReLU
ReLU는 Sigmoid에 비해 적어도 x > 0 인 절반의 영역에서는 Gradient Vanishing이 일어나지 않는다는 장점이 있다. 또한, 계산이 단순해서 계산 속도가 빠르다.
그러나 이것은 반대로 말하면 나머지 절반의 영역에서는 여전히 Gradient Vanishing이 일어난다는 말이다.
Leaky ReLU / ELU
Leaky ReLU나 ELU에서는 Gradient Vanishing이 일어나지 않는다는 장점이 있다.
Leaky ReLU의 경우 Transposed Convolution에 사용되기도 한다.
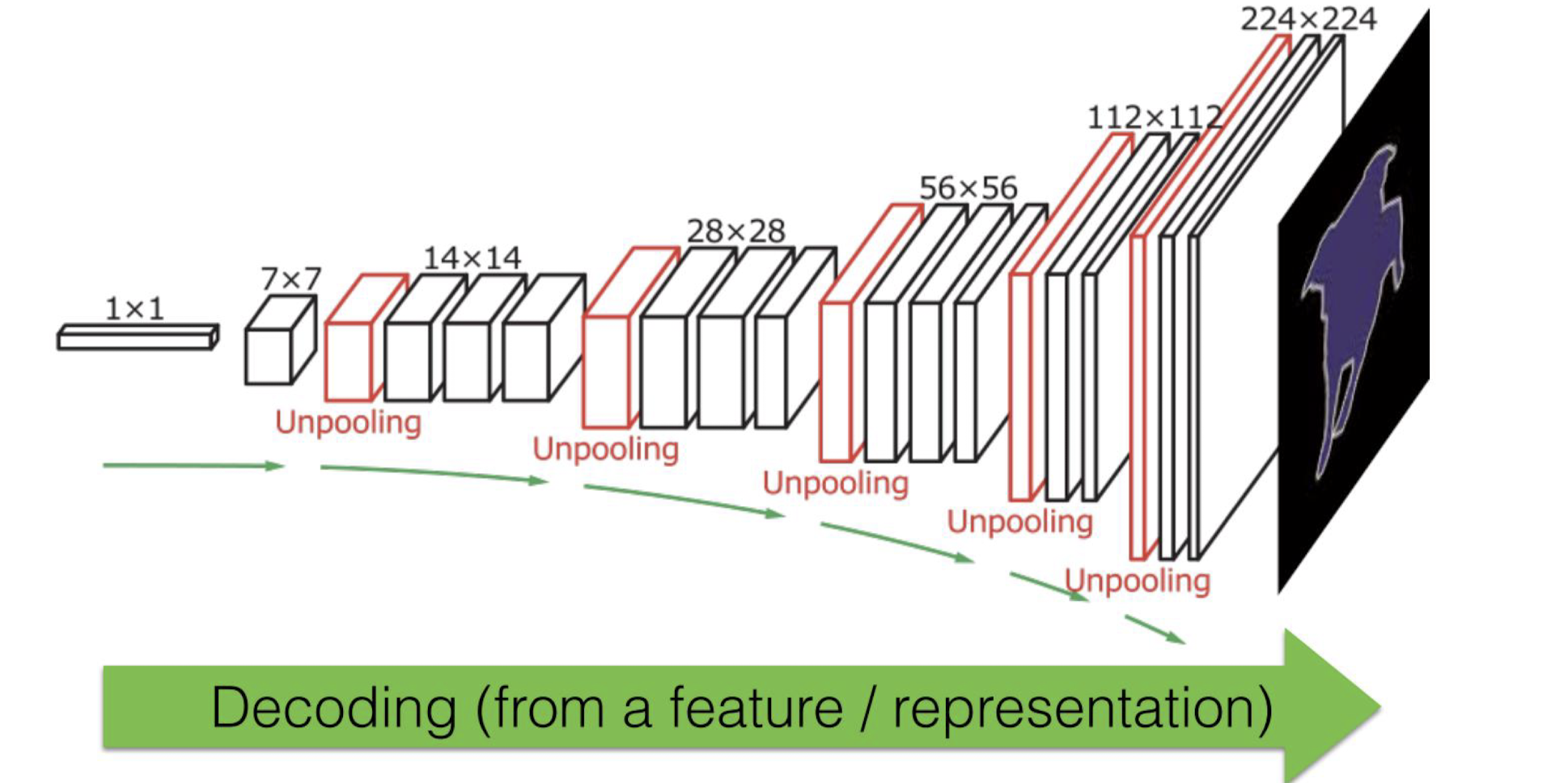
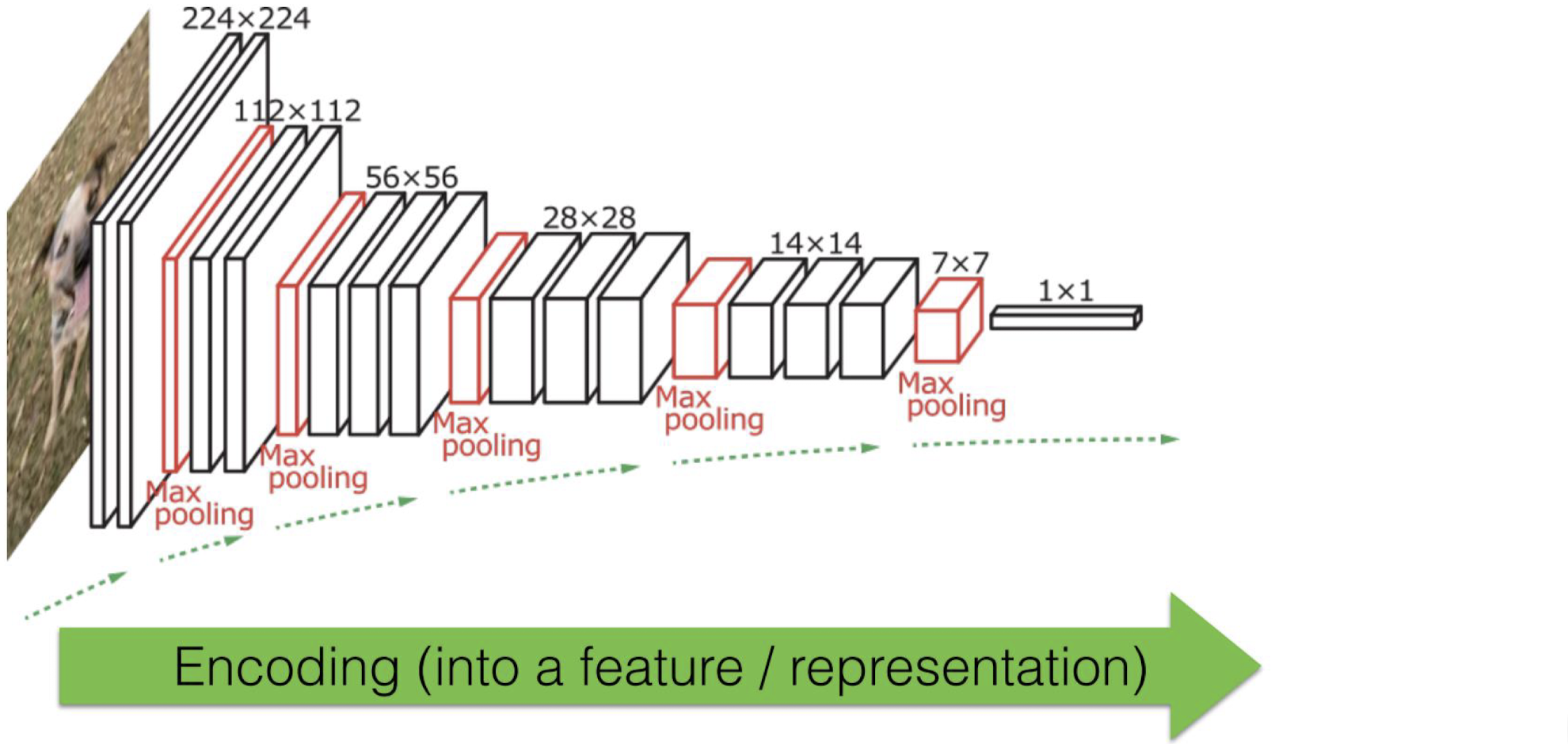
CNN 수행 과정
Encoder
Decoder