
AI RUSH 는 NAVER 에서 주최하는 AI 모델링 챌린지입니다. 좀 더 자세히 설명드리자면 어떠한 문제가 주어지고 그 문제를 머신 러닝 및 딥 러닝 알고리즘을 이용하여 해결하는 챌린지입니다.
해당 게시글은 주최측의 승인을 받고 게시된 글입니다!
선발 과정

특이하게도(?) 지원 선발에 있어 서류뿐만아니라 코딩 테스트 과정이 존재했습니다.
서류의 문항 중 AI 관련 개발 경험 및 실적(과제, 프로젝트, 논문 등)을 묻는 문항이 존재하였습니다.
이와 관련하여 석사 학위 과정중 진행하였던 산학 과제 관련 내용을 작성하였습니다. 또한, 직접 개발하였던
Object Detection Annotation Tool 과 기여했던 깃헙 프로젝트들(ultralytics/yolov3, yjh0410/yolov2-yolov3_PyTorch)과 어떠한 기여를 했는지에 관하여 작성하였습니다.
운 좋게도 서류는 통과...!
코딩 테스트와 관련하여 3 문제가 출제 됐었는데 1 문제 밖에 풀지 못했습니다. 코딩 테스트와 관련하여서는 규정상 유출할 수 없기 때문에 어떠한 문제가 나왔는지 설명은 드릴 수 없습니다.
운 좋게도 코딩 테스트는 통과...!
아래는 제가 풀었던 백준 문제들을 볼 수 있는 링크입니다.
https://www.acmicpc.net/user/0hye
이정도 분량(2020.08.27 기준 92 문제) 이상의 문제를 푸신 분들이라면 한 문제는 맞출 수 있을 정도?의 수준이였다고 생각됩니다...! 다음에는 3문제를 모두 맞출 수 있도록 자료구조/알고리즘 문제를 많이 풀어보도록 해야겠습니다.
본선 1 라운드

코딩 테스트 이후에는 본격적으로 AI 챌린지가 시작되었습니다. 대회는 1 라운드, 2 라운드로 나누어 진행됐습니다.
1 라운드에서는 크게 Vision, NLP(Natural Language Processing) 과제로써 스팸 이미지 필터링, 혐오 댓글 분류 문제가 출제되었습니다. 대회 진행은 NAVER의 머신러닝 플랫폼인 NSML을 중심으로 진행됐습니다.
NSML
-
NSML 은 연구에 불필요한 작업들을 제거하고, GPU 자원의 효율적인 사용을 위해 개발된 MLaaS(Machine Learning as a Service), 클라우드 플랫폼입니다.
-
딥러닝 알고리즘 설계 과정에서 쉽고 빠른 연구 개발을 돕는 역할을 수행합니다. 단순히 CLI(Command Line Interface)와 Web Interface 만으로 복잡한 설정 없이 AI 학습을 진행할 수 있으며, 진행 과정을 모니터링 할 수 있습니다.
1 라운드를 진행하기전에 Model 을 학습시킬만한 컴퓨팅 파워가 없어 많이 걱정했었습니다. 하지만, 다행히 NAVER 에서 개발한 NSML 을 통해 컴퓨팅 파워 걱정없이 정말 할 수 있는 시도는 모조리 다 해볼 수 있었습니다. 무려 최대 8개의 GPU(NVIDIA V100)를 사용해볼 수 있었습니다(2 라운드에선 10개). 그렇다보니 병렬적으로 실험할 수 있었습니다. 지금껏 Single GPU 만 사용해보았는데 Multi GPU를 사용하여 병렬적으로 실험을 진행해보니 그 진행속도는 어마어마 했습니다...!
Model 의 학습이 끝나면, Weight 와 함께 Model 을 NSML 에 제출할 수 있습니다. 제출을 하게되면 클라우드 상에서 Test Set에 대한 Model 의 성능 평가가 이루어지고 해당 성능을 기준으로 순위가 기록됩니다. 그렇다보니 대회가 종료될때까지 시시각각으로 순위가 변동하였는데, 변하는 순위를 보며 심장이 쫄깃했습니다.
NSML 에 관한 보다 자세한 설명을 위해 관련 영상을 링크로 첨부합니다!
https://www.youtube.com/watch?v=3Ry8maPHP9g
https://www.youtube.com/watch?v=21ylProAbxA
다시 문제 풀이에 대해 설명드리도록 하겠습니다!
저는 1 라운드에서 Vision 과제에 해당하는 스팸 이미지 필터링 문제를 선택하였습니다.
스팸 이미지 필터링 문제의 경우, 단순히 스팸 이미지냐 아니냐를 구분하는 이진 분류 문제는 아니였습니다. 총 4 클래스의 이미지를 분류해야 했으며 1 클래스는 정상, 나머지 3 클래스는 스팸 이미지와 관련된 클래스 였습니다.
문제의 정량적 평가 척도로써 Test Set 에 대한 각 클래스별 F1 score의 Geometric Mean 값이 사용되었습니다.
해당 문제의 경우 클래스간의 데이터 수가 굉장히 불균형했습니다(Class Imbalance). 이에 따라 이를 해결하기 위한 기법에 집중해야 했으며, 재밌게도 주어진 학습 데이터셋의 데이터중 Unlabeled 데이터 의 갯수가 Labeled 데이터의 갯수보다 많았습니다. 그렇기에 Unlabeled 데이터를 잘 활용하는 것이 성능 향상의 열쇠라고 생각하고 접근을 했습니다.
먼저, Unlabeled 데이터를 해결하기위해 저는 Undersampling 방법을 사용했습니다. 이것만으로 Class Imbalance 문제가 크게 완화되었습니다. 이외에 Focal Loss 나 Loss 를 계산함에 있어 클래스별로 서로 다른 Weight 를 곱하는 방법 등을 시도해보았지만 크게 성능 향상이 없었습니다.
Unlabeled 데이터를 활용함에 있어 Facebook AI 의 연구인 Billion-scale semi-supervised learning for image classification을 참고하였고 이를 통해 성능을 향상시킬 수 있었습니다.
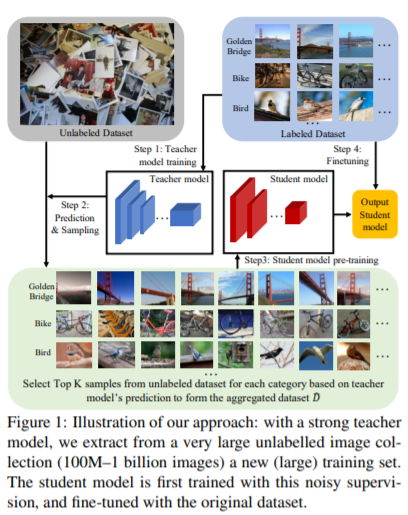
굉장히 간단한 방법이니 한 번 가볍게 논문을 읽어보시거나 리뷰 글을 읽어보심을 추천드립니다!
이외로 Model 의 경우 Imagenet pretrained EfficientNetb5 를 사용하였고 최종적으로 5 fold 로 데이터셋을 나눈 후 5 개의 EfficientNetb5 를 학습시켰으며, 각 모델의 예측 결과를 Multivoting 하여 가장 많이 Voting 된 클래스를 결과로 출력하였습니다. 추가적으로 모델을 학습시킴에 있어 M 에폭만큼 학습시킨다 하였을때 N 에폭(N < M)까지는 모델의 마지막 Fullcy Connected Layer 만 학습시키도록 하였고, N 에폭 이후로는 모든 Layer 의 Parameter 를 학습시켰습니다.
대회를 진행하며 EfficientNet 을 구현한 깃헙 프로젝트에 기여를 할 수 있었습니다!
https://github.com/lukemelas/EfficientNet-PyTorch/pull/209
https://github.com/lukemelas/EfficientNet-PyTorch/pull/212
Optimizer 는 AdamW 를 Default Parameter 로 사용하였고, Learning Rate Policy 의 경우 Warmup + Cosine Annealing 기법을 사용했습니다.(추후 참가자분과 대화를 나눴었는데 Adam 과 Warmup 이 궁합이 안좋다는 얘기를 들었습니다...!)
최종적으로 1 라운드에서 4위를 기록할 수 있었습니다.
본선 2라운드
1라운드에서 각 문제별로(스팸 이미지 필터링, 혐오 댓글 분류) 25위안에 속한 참가자들은 최종적으로 2라운드에 진출할 수 있었습니다. 1라운드와 달리 2라운드는 2인 1팀으로 대회가 진행됐으며 팀별로 최대 3개의 문제를 풀 수 있었습니다.
혼자서 2라운드를 진행했다면 금방 포기할 수도 있었을텐데 대회 마지막까지 포기하지 않고 함께 힘써주신 김승욱 팀원님 덕분에 끝까지 최선을 다할 수 있었습니다.
2라운드에서 출제된 문제는 다음과 같습니다.
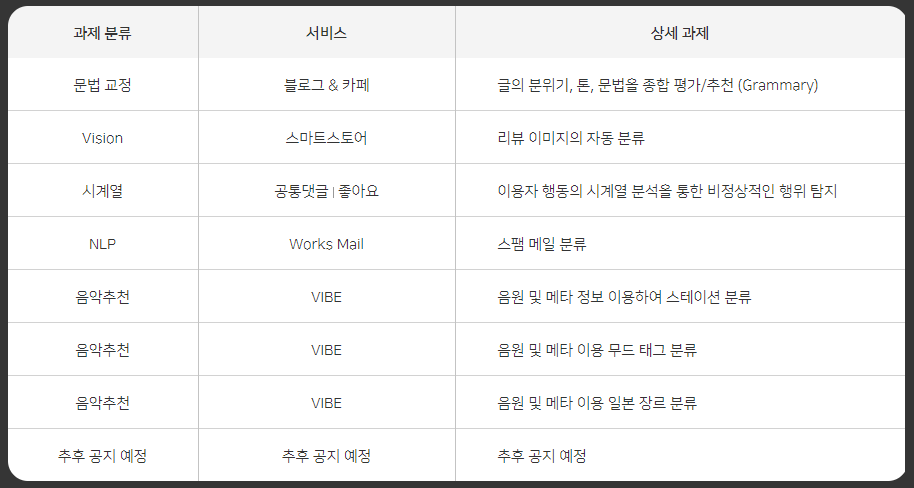
저희 팀은 Vision-스마트스토어-리뷰 이미지의 자동 분류와 음악추천-VIBE-음원 및 메타 이용 무드 태그 분류 문제를 선택하였습니다.
이 중 저희 팀은 리뷰 이미지의 자동 분류 문제를 집중적으로 풀었습니다. 해당 문제는 네이버 쇼핑(스마트스토어)란에 올라온 리뷰 이미지에 적절한 태그(착용샷, 요리 완성 등)를 추천(=분류)하는 문제입니다.
문제의 정량적 평가 척도로써 Test Set 에 대한 각 클래스별 F1 score의 Geometric Mean 값이 사용되었습니다.
해당 문제 또한 1라운드때와 마찬가지로 Class Imbalance 문제가 존재하였으며 학습 데이터셋에 Noisy Labeled Data 가 다수 포함되어 있었습니다. 추가적으로 인풋 데이터로써 이미지 뿐만아니라 텍스트 데이터인 카테고리까지 Metadata 로써 주어졌습니다.
먼저, Class Imbalance 문제를 완화시키기 위하여 Undersampling 기법을 이용해보았지만 오히려 성능이 더욱 하락하는 문제가 발생하였습니다. 이에따라 Undersampling 은 사용하지 않았고 학습 과정에서 Mini Batch 단위로 데이터를 샘플링 하고 Loss 를 계산할때, 이를 미니 배치 단위로 곧바로 평균내지 않고 Class 별로 Loss 를 평균내고 이를 합산하도록 Loss Function 을 수정하였습니다. 이를 통해 성능을 향상시킬 수 있었습니다.
Noisy Labeled Data는 필터링 기법을 통해 걸러내고자 했습니다. 관련 논문으로 SELF: LEARNING TO FILTER NOISY LABELS WITH SELF-ENSEMBLING 와 Co-teaching: Robust Training of Deep Neural Networks with Extremely Noisy Labels 를 읽어보았을때 유효한 방법이라 생각하여 시도해보았지만 구현상의 문제인지 큰 재미를 보지못했습니다. 이후 시도한 방법은 데이터셋을 K-Fold 로 나누고 각 세트별로 K 개의 모델(사실 이때도 세트별로 Ensembleing 된 모델을 학습 시켰습니다)을 학습시킨 뒤, 모델별로 대응되는 K 개의 Validation Set 에 대해 Inference를 거친뒤에 정답인 데이터만을 필터링하고, 이렇게 Filtering 된 K 개의 Validation Set 을 다시 합쳐 이를 Filtering 된 데이터셋으로 사용하여 모델을 다시 학습시켰습니다. 이를 통해 성능을 향상시킬 수 있었습니다. 또한, Label Smoothing 기법이 Noisy Label Dataset 에서 효과가 있다하여 적용해보았지만 성능이 저하되었습니다. (다른 상위팀의 경우 Label Smoothing 을 통해 큰 성능 향상을 이룬 것을 확인할 수 있었습니다.)
마지막으로 카테고리를 사용함에 있어, 텍스트 데이터인 카테고리를 원핫 인코딩 벡터로 변환시킨 후에 Fully Conncected Layer 를 한 층 통과시킨다음 이를 이미지를 인풋으로 하는 CNN 모델의 아웃풋 피쳐와 Concatenation 시킨 뒤에 최종적으로 Fully Connected Layer + Softmax Layer 를 거쳐 클래스를 예측하도록 디자인하였습니다. 카테고리를 추가적인 피쳐로 사용했을때 가장 큰 성능 향상이 있었습니다.
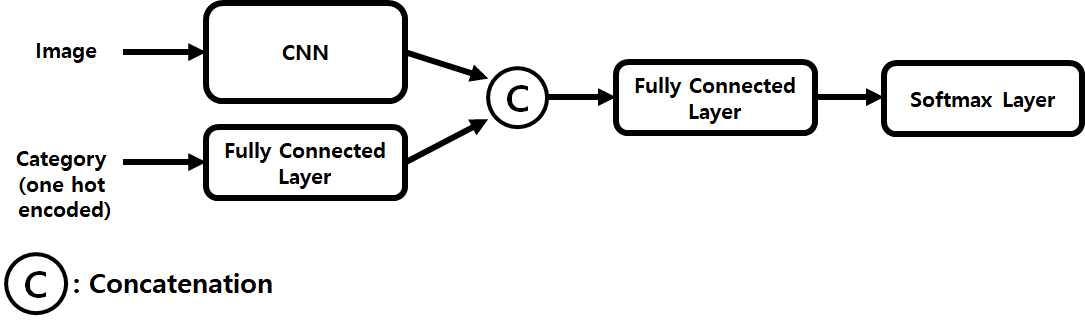
카테고리를 사용함에 있어 NLP 에서 주로 사용되는 1D Convolution, LSTM 등을 사용하여 보다 뛰어난 피쳐를 추출해보고자 시도하였으나, 오히려 성능이 저하되었습니다. 아래와 같이 간단한 구조를 사용하여 피쳐를 추출하였을때 가장 성능이 높았습니다.
사실 텍스트 데이터는 처음 다루어 보았기에 이를 충분히 활용하지 못한 거 같아 아쉬움이 컸습니다.
또한, 카테고리 별 클래스 분포를 분석해본 결과 카테고리에 따라 분류될 수 있는 클래스가 있고 분류될 수 없는 클래스가 있었습니다. 예로 카테고리가 식품인 상품 판매글에 리뷰 사진이 올라왔을때 해당 사진에는 "착용샷"이라는 태그를 추천해줄 필요가 없습니다. Neural Network 의 경우 학습 과정에서 이러한 특징을 자동적으로 학습하겠지만, Prior Knowledge 를 최대한 활용하여 Model 이 학습하는데 드는 Burden 을 최대한 줄여주고자 카테고리별로 특정 클래스 만을 분류하는 Model 을 각각 학습시키고 추론하도록 하였습니다. 이를 통해 성능을 향상시킬 수 있었습니다.
그러나, 수상자들의 Solution 을 보니 하나의 Model 로 모든 클래스를 분류하도록 디자인한것을 확인할 수 있었습니다.
위 문장은 이해하면 소름돋는 문장입니다. 네, 그렇습니다. 저는 이번 대회에서 수상을 하지 못했습니다!!!
마지막으로 모델은 Ensembled(x5) EfficientNetb3 를 사용했으며, Optimizer 는 Adam 을 Default Parameter 로 사용하였고, Learning Rate Policy 의 경우 Cosine Annealing 기법을 사용했습니다.
최종적으로 저희 팀은 해당 과제에서 5위를 기록하였습니다. 대회가 종료된 후 수상팀들(1~3위)의 솔루션 발표시간이 있었는데 이때 정말 많이 배울 수 있었습니다.
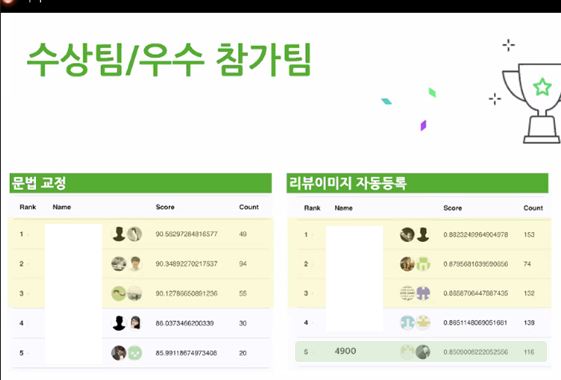
소감
대회가 진행된 2개월 동안 시간가는줄도 모르고 정말 밤을 새워가며 몰입할 수 있었습니다. 정말 인생에서 가장 행복했던 기간이였습니다. 실제 필드에서 쓰이는 데이터를 직접 다뤄본다는 게 너무나도 좋은 경험이였으며, 머신 러닝 및 딥 러닝 기술을 상용 서비스에 접목함에 있어 어떠한 문제들(Class Imbalance, Noisy Label 등)이 존재하는지를 알 수 있었습니다. 학위 과정을 밟는동안 정말 폭 좁고 얕게(?!)... 공부를 했었는데 이번 기회를 통해 다양한 분야를 공부해야겠다는 다짐을 할 수 있었습니다.
+)
2라운드는 NAVER 인턴으로서 NAVER 본사에 오프라인으로 잠깐이나마 출근할 수 있었는데 건물을 입장할때마다 정말 가슴이 웅장해졌습니다...

이제는 반납해야되는 사원증... 안녕!!!
좋은 기회를 제공해주신 대회 관계자분들께 이 자리를 빌어 감사의 인사를 드립니다!!

6개의 댓글

안녕하세요! 글 너무 인상깊게 잘 읽었습니다, 감사합니다 ^^
다름이 아니라, 분석 프로젝트 진행 과정에서 궁금한 점이 있는데요. 혹시 분석 과제를 할 때 제공되는 데이터 외 다른 데이터를 추가로 끌어와 써도 문제가 되지 않았는지 여쭤보고 싶어요. 답변 주시면 감사하겠습니다!^^
코테 많이 어렵나요..? 공채처럼 캠 키고 하는지도 궁금합니다