Residual Block이란
Neural network들에 대해서 배우기 시작하며, 정보가 뉴럴네트워크의 각 층을 순차적으로 지난다는 점이 동물의 뇌와는 다르다고 생각했습니다.
(https://commons.wikimedia.org/wiki/File:Example_of_a_deep_neural_network.png)" by BrunelloN. Licensed under CC BY-SA 4.0 International)
{kind=link}
동물의 뇌에서 뉴런들의 연결은 좀 더 중구난방(?)으로 연결되어있어서 정보가 뉴런 층들을 순차적으로 지나지 않고 여기저기로 퍼지는 구조이죠
("Neurons" by Leterrier, NeuroCyto Lab, INP, Marseille, France. Obtained from NIH Image Gallery | Flickr. Licensed under CC BY-NC 2.0)
그래서 서로 멀리 떨어져 있는 뉴런 layer들을 이어주는 skip connection이 있는 "residual block"을 이용한 뉴럴 네트워크가 조금 더 생물학적 뇌의 구조와 비슷하단 생각이 들었습니다. Residual block의 개념은 단순합니다: 한 layer의 결과값을 바로 다음 layer에만 넣어주는 것이 아니라 좀 더 뒤에 있는 layer에도 넣어주는 것입니다. 이 연결을 skip connection이라 하고, 이 skip connection이 있는 레이어들을 residual block이라고 부릅니다.
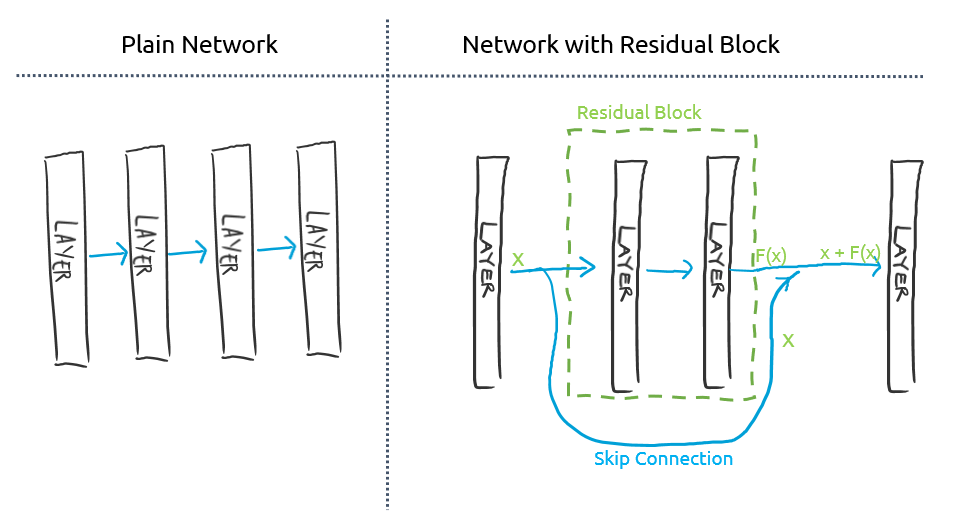
(Image by Author)
점선으로 둘러싸인 residual block의 입장에서 보면, 들어오는 인풋 x가 있다고 할 때, 이 x를 그 블럭 내 레이어들을 통과시켜서 얻은 결과값 f(x)에다가 인풋 x를 그대로 더해준 것이 그 블럭의 최종 아웃풋이 됩니다.
Pytorch로 Residual Block 만들어보기
이를 구현하는 코드도 간단합니다 (pytorch):
from torch import nn
class ResBlock(nn.Module):
def __init__(self, block):
super().__init__()
self.block = block
def forward(self, x):
return self.block(x) + x #f(x) + x6줄이면 되네요.
그럼 이 residual block을 CNN에 넣어보도록 하겠습니다.
우선 평범한 CNN을 만듭니다 (저는 6개의 3x3 convolution레이어를 넣었습니다):
class Conv6(nn.Module):
def __init__(self, n_class=10):
super().__init__()
self.name = 'conv6'
self.model = nn.Sequential(
nn.Conv2d(3, 32, 3, 1, 1),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.Conv2d(32, 32, 3, 1, 1),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.Conv2d(32, 32, 3, 1, 1),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.Conv2d(32, 32, 3, 1, 1),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.Conv2d(32, 32, 3, 1, 1),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.Conv2d(32, 32, 3, 1, 1),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.Flatten(),
nn.Linear(32*32*32, 256),
nn.ReLU(),
nn.Linear(256, 10)
)
def forward(self, x):
return self.model(x)이 중 몇몇 레이어를 residual block으로 묶어보겠습니다:
class Conv6Res(nn.Module):
def __init__(self, n_class=10):
super().__init__()
self.name = 'conv6res'
self.model = nn.Sequential(
nn.Conv2d(3, 32, 3, 1, 1),
nn.BatchNorm2d(32),
nn.ReLU(),
ResBlock(
nn.Sequential(
nn.Conv2d(32, 32, 3, 1, 1),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.Conv2d(32, 32, 3, 1, 1),
nn.BatchNorm2d(32),
nn.ReLU()
)
),
ResBlock(
nn.Sequential(
nn.Conv2d(32, 32, 3, 1, 1),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.Conv2d(32, 32, 3, 1, 1),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.Conv2d(32, 32, 3, 1, 1),
nn.BatchNorm2d(32),
nn.ReLU(),
)
),
nn.Flatten(),
nn.Linear(32*32*32, 256),
nn.ReLU(),
nn.Linear(256, 10)
)
def forward(self, x):
return self.model(x)이렇게 하면 residual block이 있는 네트워크 완성입니다.
Residual block이 없는 plain CNN인 Conv6와 residual block이 들어있는 CNN인 Conv6Res을 CIFAR10 데이터셋에 대해 트레이닝하여 비교해보겠습니다. 우선 Conv6()부터
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
import torch
from torch import nn
from torch.utils.data import Dataset, DataLoader
from torchvision import datasets, transforms
# Downloading the CIFAR10 dataset
transform = transforms.Compose(
[transforms.ToTensor(),
transfomrs.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5))]
)
cifar_tr = datasets.CIFAR10(root=os.getcwd(), train=True, download=True, transform=transform)
cifar_test = datasets.CIFAR10(root=root, train=False, download=True, transform=transform)
# Split training data into train set and validation set
def split_train_valid(dataset, valid_ratio=0.1):
data_size = len(dataset)
indices = list(range(data_size))
np.random.seed(1)
np.random.shuffle(indices)
split_point = int(np.floor(valid_ratio*data_size))
val_index, train_index = indices[:split_point-1], indices[split_point:]
train = torch.utils.data.Subset(dataset, train_index)
valid = torch.utils.data.Subset(dataset, val_index)
return train, valid
cifar_train, cifar_valid = split_train_valid(dataset=cifar_tr)
# Make DataLoaders for train/validation/test sets
cifar_loaders = [DataLoader(dataset=d, batch_size=128, shuffle=True, drop_last=True) for d in [cifar_train, cifar_valid, cifar_test]]
# Define model to train
model = Conv6()
# Define loss function and optimizer
loss = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# Use GPU if available (CPU if not)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# Train the model
print("===== Train Start =====")
num_epochs = 40
history = {"train_loss": [], "train_acc": [], "valid_loss":[], "valid_acc":[]} # record of loss and accuracy in each epoch for plotting later
for epoch in range(num_epochs):
train_loss, train_acc = 0, 0
model.train()
for (x, y) in cifar_loaders[0]: #cifar_loaders[0] is train set DataLoader
x = x.to(device)
y = y.to(device)
y_hat = model(x)
loss = loss(y_hat, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss += loss.to("cpu").item()
train_acc += (y_hat.argmax(1)==y).type(torch.float).to('cpu').mean().item()
train_loss /= len(cifar_loaders[0]) #len(DataLoader) is batch size (ie, 128)
train_acc /= len(cifar_loaders[0])
history["train_loss"].append(train_loss)
history["train_acc"].append(train_acc)
# Evaluate model on validation set
valid_loss, valid_acc = 0, 0
model.eval()
with torch.no_grad():
for (x, y) in cifar_loaders[1]: # Validation set DataLoader
x = x.to(device)
y = y.to(device)
y_hat = model(x)
loss = loss(y_hat, y)
valid_loss += loss.to('cpu').item()
valid_acc += (y_hat.argmax(1)==y).type(torch.float).to('cpu').mean().item()
valid_loss /= len(cifar_loaders[1]) #len(DataLoader) is batch size
valid_acc /= len(cifar_loaders[1])
history["valid_loss"].append(valid_loss)
history["valid_acc"].append(valid_acc)
if epoch % 10 == 0:
print(f"Epoch: {epoch}, train loss: {train_loss:>6f}, train acc: {train_acc:>3f}, valid loss: {valid_loss:>6f}, valid acc: {valid_acc:>3f}")
# Test the model on the test set
print("===== Test Start =====")
test_loss, test_acc = 0, 0
model.eval()
with torch.no_grad():
for (x, y) in cifar_loaders[2]:
x = x.to(device)
y = y.to(device)
y_hat = model(x)
loss = loss(y_hat, y)
test_loss += loss.to('cpu').item()
test_acc += (y_hat.argmax(1)==y).type(torch.float).to('cpu').mean().item()
test_loss /= len(cifar_loaders[2])
test_acc /= len(cifar_loaders[2])
print(f"Test loss: {epoch_loss:>6f}, Test acc: {epoch_acc:>6f}")
같은 방법으로 residual block이 들어있는 모델(즉, model = Conv6Res())도 트레이닝해보면 다음과 같은 결과가 나옵니다:

Residual Block의 효과
위의 Conv6()와 Conv6Res() 두 모델의 accuracy는 별 차이 없지만, residual block은 뉴럴 네트워크의 레이어 갯수가 점점 많아지면서 오히려 performance가 저하 되는 'degradation'현상을 막아주는 것이 주 역할이므로 레이어가 더 많은 deeper 뉴럴 네트워크들에서 residual block의 효과를 보겠습니다.위의 Conv6와 Conv6Res와 같은 구조로 레이어의 갯수가 6개, 9개, 12개, 15개, 18개, 21개인 모델들을 만들어 같은 방법으로 트레이닝 시켜보았습니다:
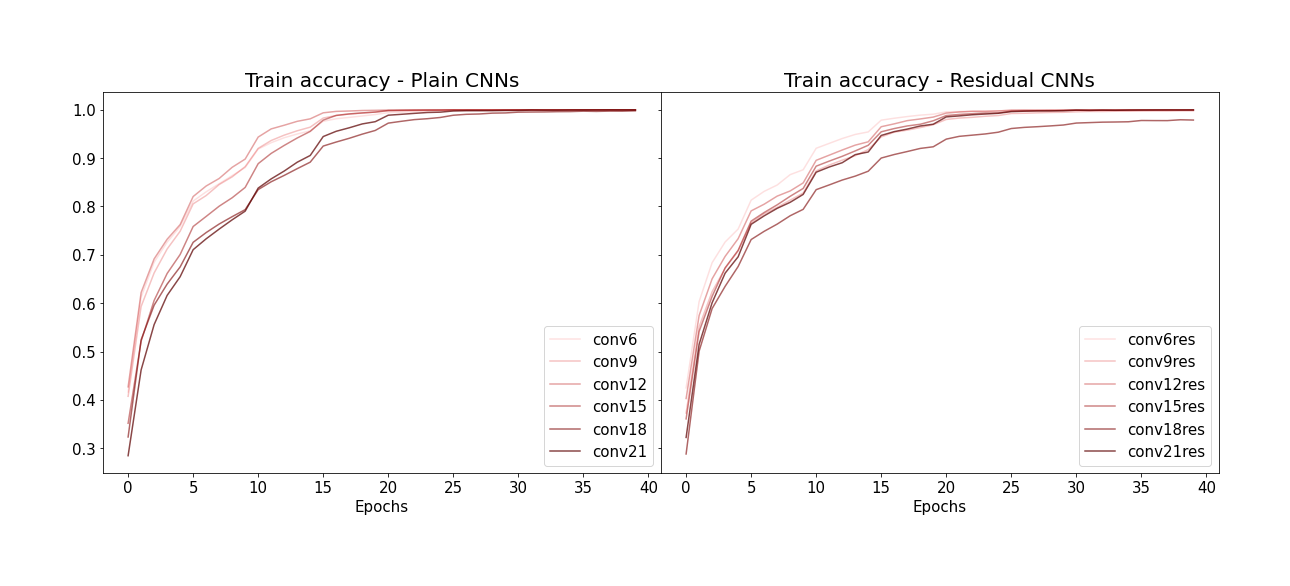
(Image by Author)
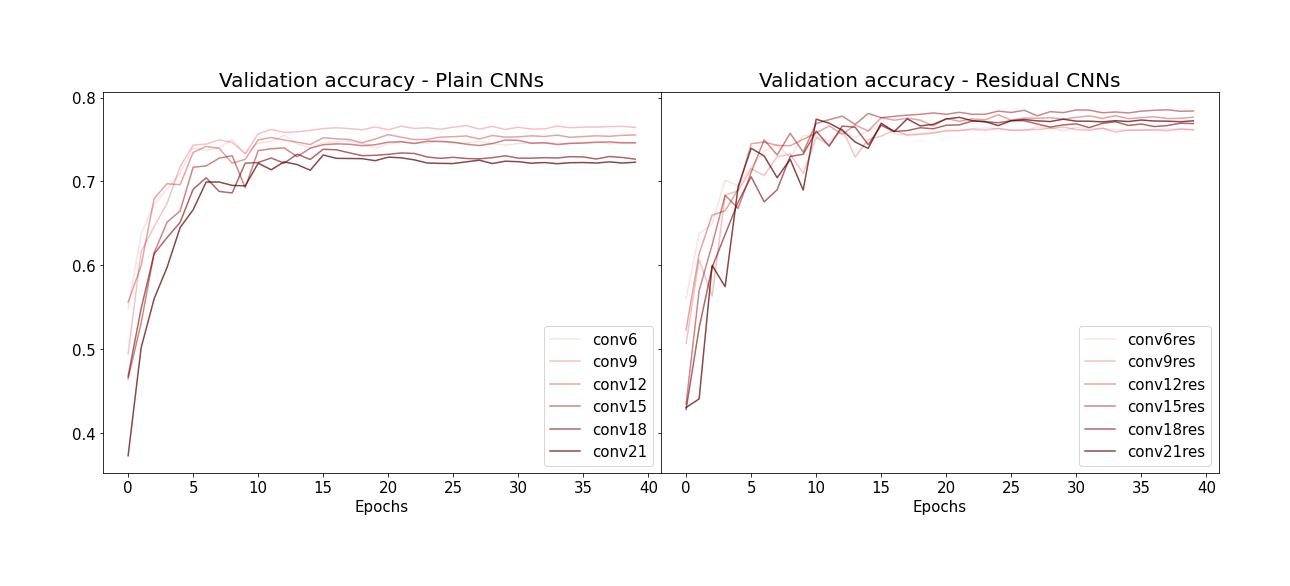
Residual block을 사용하지 않은 plain CNN의 경우, 레이어 갯수가 많아질수록 (그래프 상에서 선의 색이 짙어질수록) train accuracy가 오히려 대체로 떨어지는 것을 볼 수 있습니다. 이건 overfitting에 의한 현상이 아니고 (training data에 대한 accuracy니까요) 뉴럴네트워크의 레이어 수가 많아질수록 accuracy가 떨어지는 degradation 현상 때문인 것 같습니다. 반면 residual block이 있는 CNN들의 경우 이 현상이 덜해보입니다.
Validation set에 대한 accuracy도 같은 양상을 보입니다 (plain CNN들은 레이어 갯수가 많아질수록 퍼포먼스가 떨어지는데 비해, residual CNN들은 그렇지 않음):
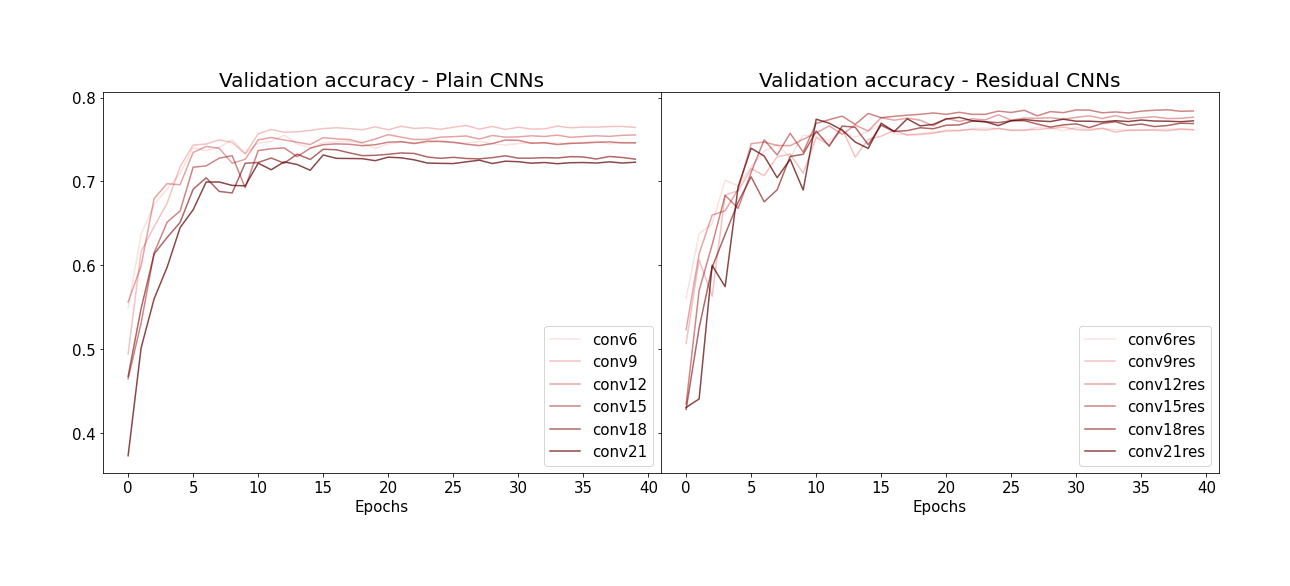
(Image by Author)
마지막으로 레이어 갯수 별로 test set accuracy를 보겠습니다:
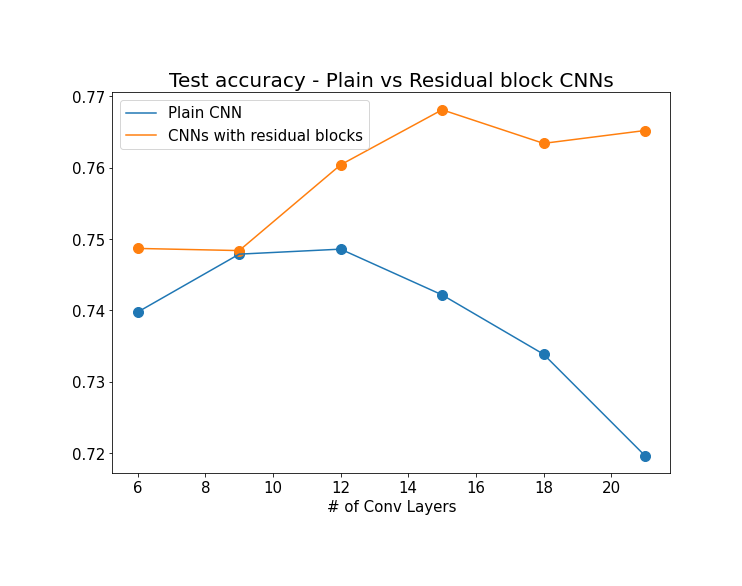
(Image by Author)
Plain CNN의 경우 레이어가 일정 갯수 이상으로 증가하면 test set에 대한 accuracy가 점점 떨어지는데 비해 residual block을 이용한 CNN들은 accuracy가 증가하는 양상을 보입니다. 레이어가 10개 정도만 넘어가도 degradation 현상이 일어난다는게 좀 신기하네요 (이 예시에선 pooling 레이어를 하나도 쓰지 않았는데, pooling 레이어가 있는 구조들은 degradation현상이 일어나려면 레이어 갯수가 더 많아야 할 것 같습니다).
따라서 레이어가 많은 뉴럴 네트워크를 만들 땐 residual block의 사용은 거의 필수적입니다. 이 개념을 적극적으로 사용하여 퍼포먼스를 향상시킨 응용예시도 다양합니다 (ResNeXt, DenseNet 등). Residual block의 구조도 block 내의 batch normalization layer, activation layer, weight layer들의 순서와 조합을 어떻게 하느냐에 따라 다양하게 만들 수 있어서 이를 이용해서도 퍼포먼스 향상이 가능합니다 (Residual network의 응용 예시들과 논문들을 깔끔하게 정리해 놓은 medium포스트: An Overview of ResNet and its Variants | by Vincent Feng | Towards Data Science).
결론
레이어를 잔뜩 쌓은 인공신경망들이 여러 분야에서 좋은 성능을 보이고 있습니다. 이런 인공신경망들의 training을 가능하게 하는 개념 중 하나가 residual block이어서, 가장 간단한 residual block을 직접 만들어보고 레이어 갯수에 따라 residual block들이 가지는 효과를 보았습니다. 인공신경망의 구조가 생물학적 뇌의 구조에 점점 비슷해져가는 것 같아 신기하네요 :D
감사합니다 잘 읽었습니다.