00. HashMap, TreeSet
TreeSet
범위 탐색, 정렬
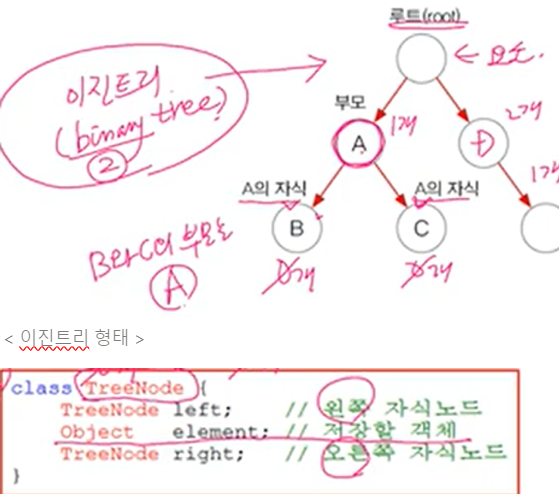
< 이진트리 형태 >

< TreeNode 구성 >
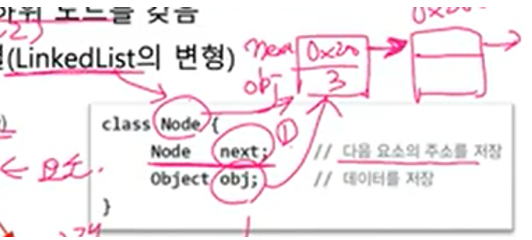
< LinkedList 구성 >
이진 탐색 트리(binary search tree)로 구현
범위 탐색과 정렬에 유리
이진 트리는 모든 노드가 최대 2개(0~2)의 하위 노드를 갖음
각 요소(node)가 나무(tree)형태로 연결 (LinkedList의 변형)이진 탐색 트리(binary search tree)
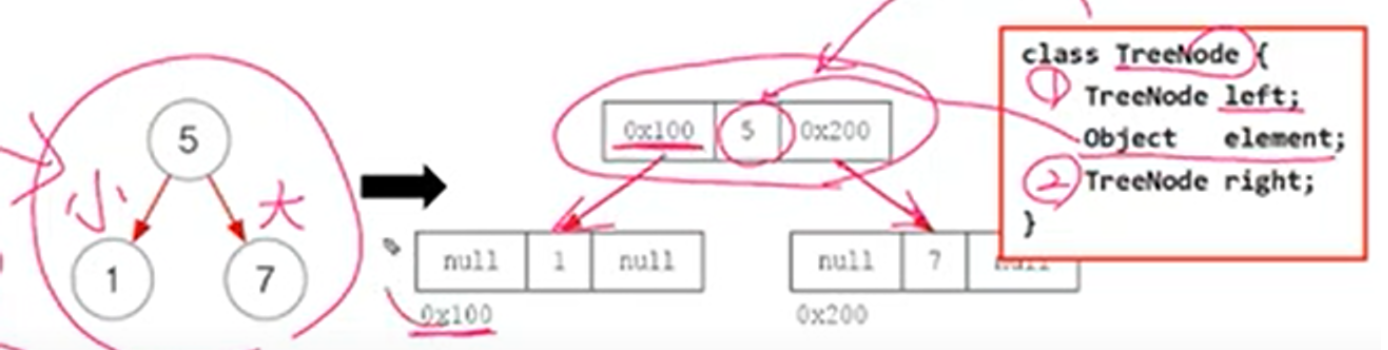
부모보다 작은 값은 왼쪽, 큰 값은 오른쪽에 저장
데이터가 많아질 수록 추가, 삭제에 시간이 더 걸림 (비교 횟수 증가)데이터 저장과정 boolean add(Object o)
TreeSet은 중복이 불가능하기 때문에 compare()을 호출해서 비교 후 데이터 저장
만약 같은게 있는데 add 한다면 저장실패 = false 리턴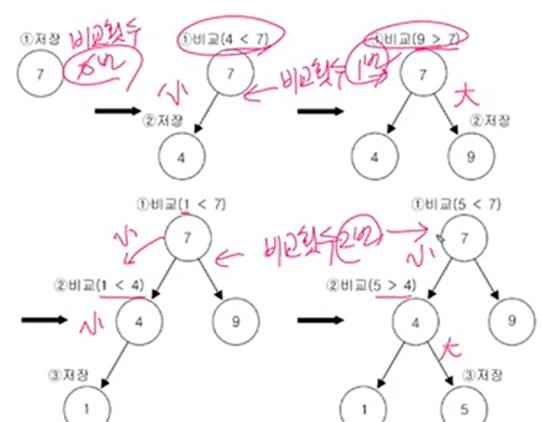
TreeSet에 7,4,9,1,5의 순서로 데이터를 저장한다고 가정하자
루트부터 트리를 까라 내려가며 값을 비교하여 작으면 왼쪽, 크면 오른쪽에 저장한다.
비교횟수는 점점 늘어나는 것을 확인 1..2..번주요 생성자와 메서드
| 생성자 또는 메서드 | 설명 |
|---|---|
| TreeSet() | 기본 생성자 |
| TreeSet(Collection c) | 주어진 컬렉션을 저장하는 TreeSet을 생성 (생성자) |
| TreeSet(Comparator comp) //Comparator : 비교기준제공 | 주어진 정렬 기준으로 정렬하는 TreeSet을 생성 (생성자) → 비교기준 제공 |
| Object first() | 정렬된 순서에서 첫 번째 객체를 반환 |
| Object last() | 정렬된 순서에서 마지막 객체를 반환 |
| Object ceiling(Object o) | 지정된 객체와 같은 객체를 반환 없으면 큰 값을 가진 객체 중 일 가까운 값의 객체를 반환 없으면 null |
| Object floor(Object o) | 지정된 객체와 같은 객체를 반환 없으면 작은 값을 가진 객체 중 제일 가까운 값의 객체를 반환 없으면 null |
| Object higher(Object o) | 지정된 객체보다 큰 값을 가진 객체 중 제일 가까운 값의 객체를 반환 없으면 null |
| Object lower(Object o) | 지정된 객체보다 작은 값을 가진 객체 중 제일 가까운 값의 객체를 반환 없으면 null |
| SortedSet subSet(Object formElement, Object toElement) | 범위 검색 (fromElement와 toElement 사이)의 결과를 반환한다. (끝 범위인 toElement는 범위에 포함되지 않음) |
| SortedSet headSet(Object toElement) | 지정된 객체보다 작은 값의 객체들을 반환된다. |
| SortedSet tailSet(Object formElement) | 지정된 객체보다 큰 값의 객체들을 반환된다. |
기본적으로 add(), remove(), size(), isEmpty(), iterator()는 제외
(Collection 프레임워크에서 공통으로 사용되는 메소드)
* TreeSet() : 비교 후 저장은 필수이다.
따로 비교해주는 작업이 포함되어 있지 않기 때문에 Comparable 객체를 사용해야 한다.
* TreeSet(Comparator comp) : 매개변수로 Comparator 비교 기준을 제공하는 객체를 받는다.
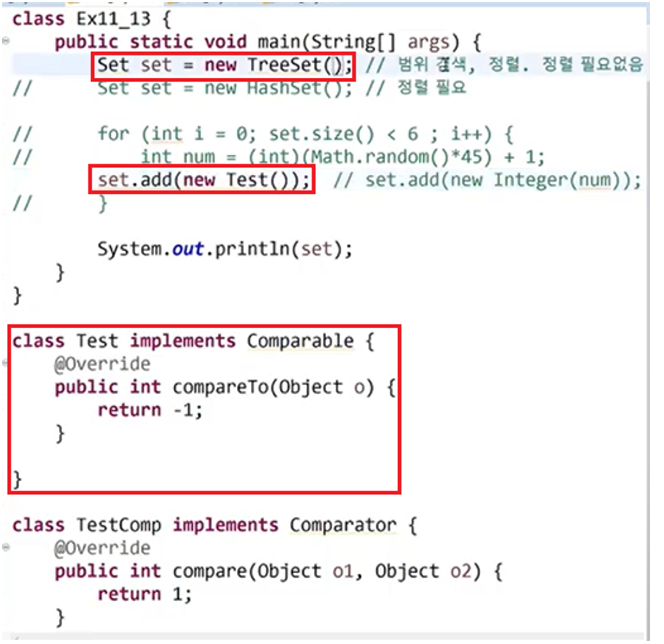
대신 TreeSet은 "비교"가 필수이다.
객체 생성 후, add로 저장할 때 비교 후 저장될 수 있도록 구현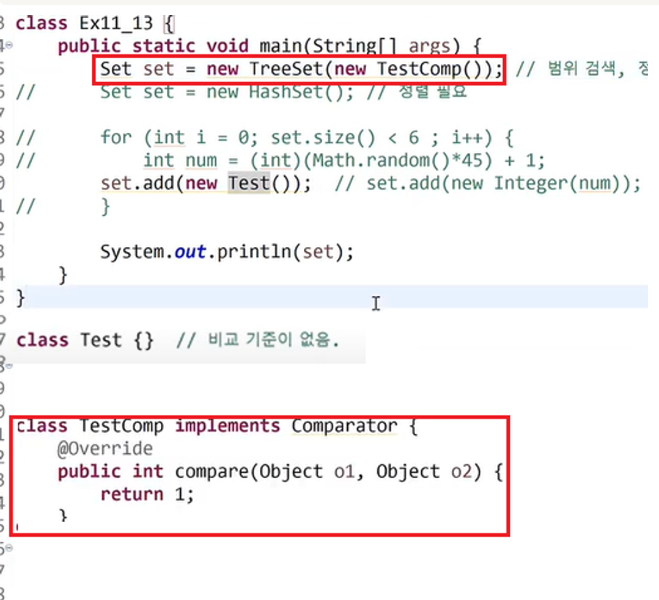
또는 TreeSet 객체 생성 시 동시에 생성자 매개변수로 Comparator 비교 객체를 구현한 클래스를 받아오는 방법이 있다.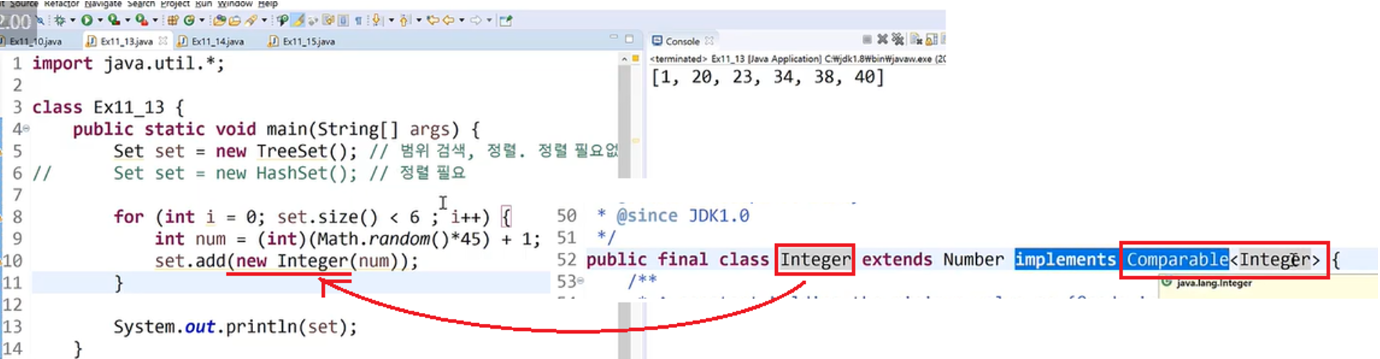
Integer는 이미 Comparable을 구현하고 있기 때문에 오류가 나지 않고
비교 후, 저장이 되는 것이다.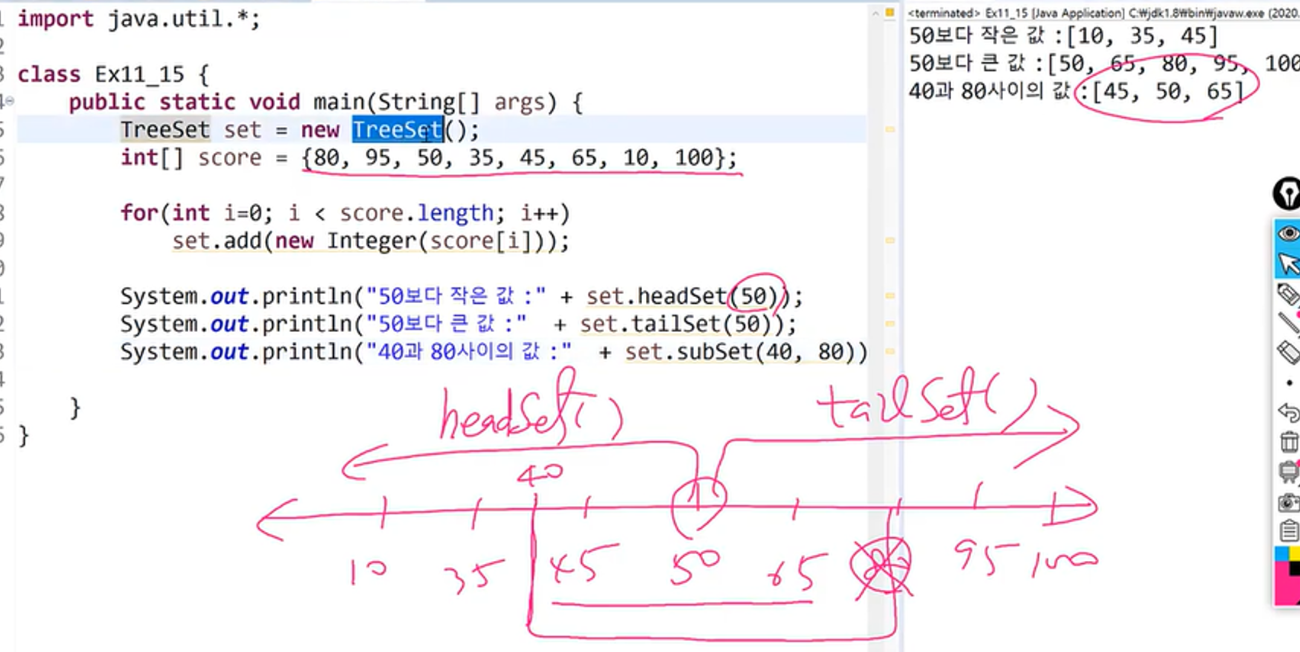
headSet, tailSet은 TreeSet에서 존재하는 메서드 이므로 Set으로 반환 값으로 받으면 안된다.범위 검색 subSet(), headSet(), tailSet()
위 예제처럼 TreeSet은 범위 검색에 유용한 메서드 제공
다음 그림에서 headSet(50) 메서드 사용하면 50보다 작은 값들을 출력 = 왼쪽으로 빠지는 값
tailSet(50) 메서드를 사용하면 그 외 나머지 오른쪽으로 빠지는 큰 값들을 출력
=> "이진 탐색 트리"HashMap
HashMap과 Hashtable - 순서X 중복(키X,값O)

* Map 인터페이스를 구현, 데이터를 키와 값으로 쌍으로 저장
* HashMap과 Hashtable은 동일하나 동기화의 유무가 차이가 있다.
Hashtable: 동기화 O / HashMap : 동기화 X
* HashMap : Map 인터페이스를 구현한 대표적인 컬렉션 클래스
LinkedHashMap: 순서를 유지해야 한다면 LinkedHashMap 사용
Linked는 연결한다는 뜻
* TreeMap : 범위 검색과 정렬에 유리한 컬렉션 클래스
HashMap보다 데이터 추가 삭제에 시간이 더 오래걸림
TreeSet과 차이점은 없다. 단지 키와 값이 존재한다는 것 뿐이다.HashMap의 키(key)와 값(value)

* 해싱(hashing) 기법으로 데이터를 저장, 데이터가 많아도 검색이 빠르다
* Map 인터페이스를 구현. 데이터를 키와 값의 쌍으로 저장
이미 있는 키의 이름으로 또 다시 put으로 저장하려고 하면 덮어 쓰인다.해싱(hasing) - (1/3) 환자 정보 관리

간호사가 많은 환자들의 정보를 어떻게 관리할까 하다가 좋은 방법을 발견한다.
출생년도로 분류해서 캐비넷에 저장하자!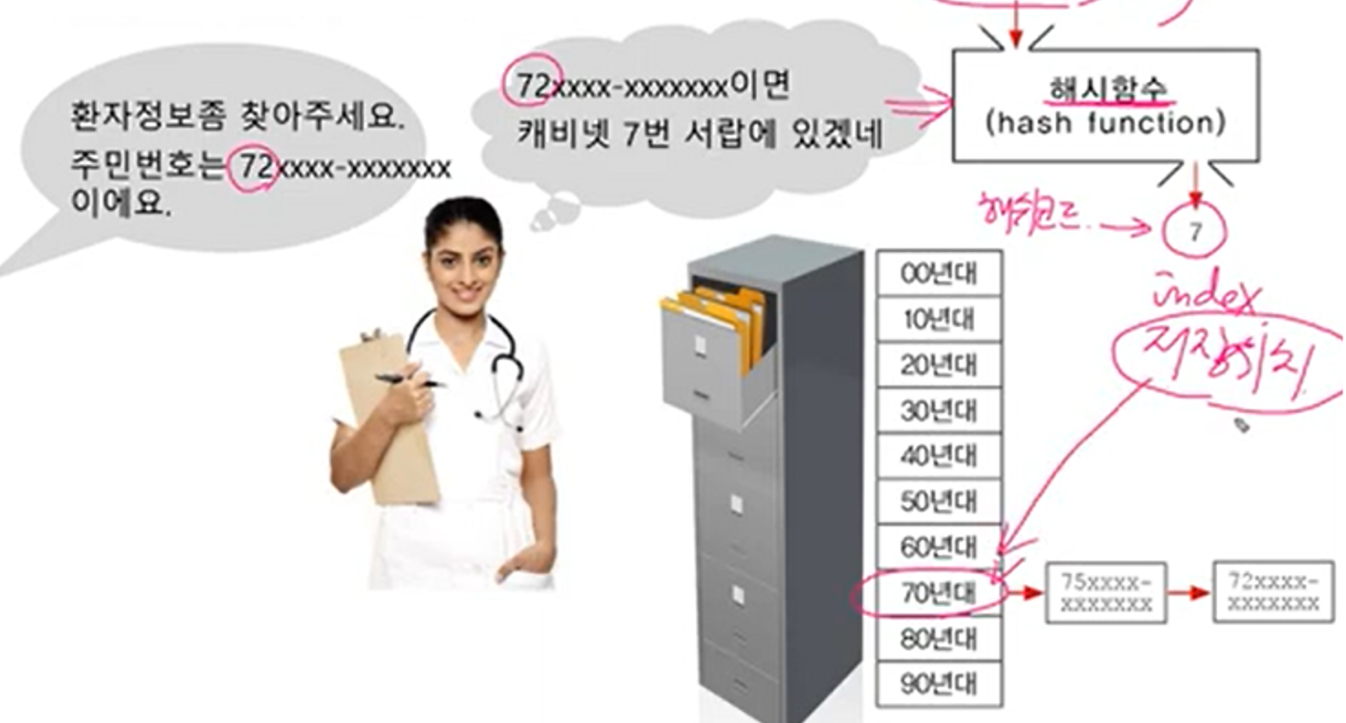
key 값으로 주민번호(ex>72xxxxxx-x,,)를 해시함수에 대입하면 해쉬코드(=index, 저장위치)(ex>7)를 반환해싱(hashing) - (2/3)
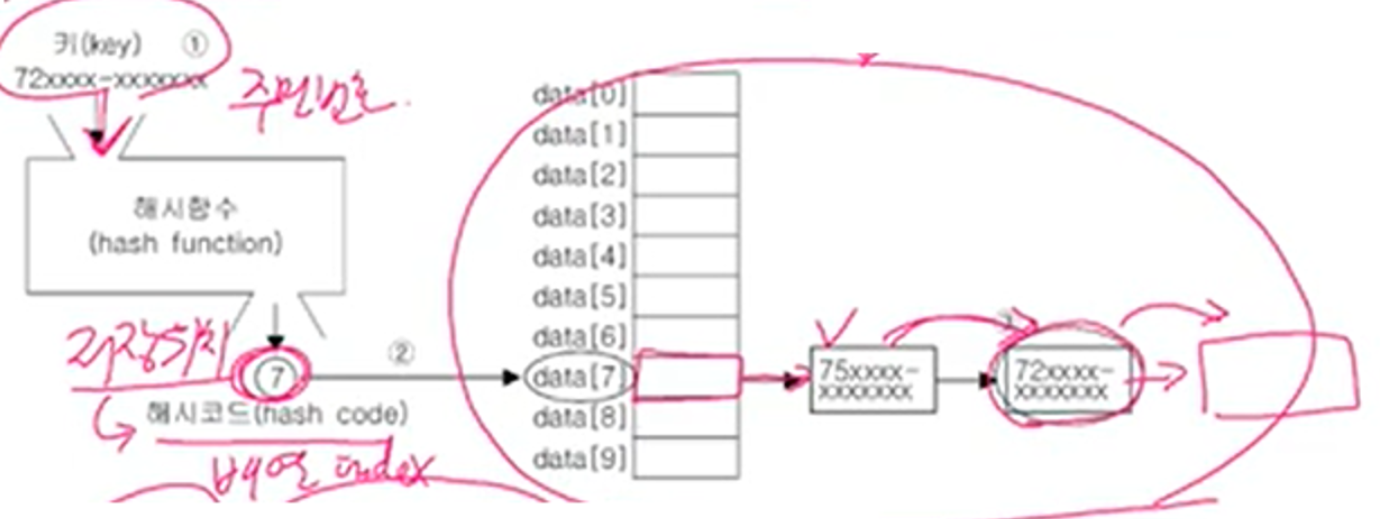
* 해시함수로 해시테이블에 데이터를 저장, 검색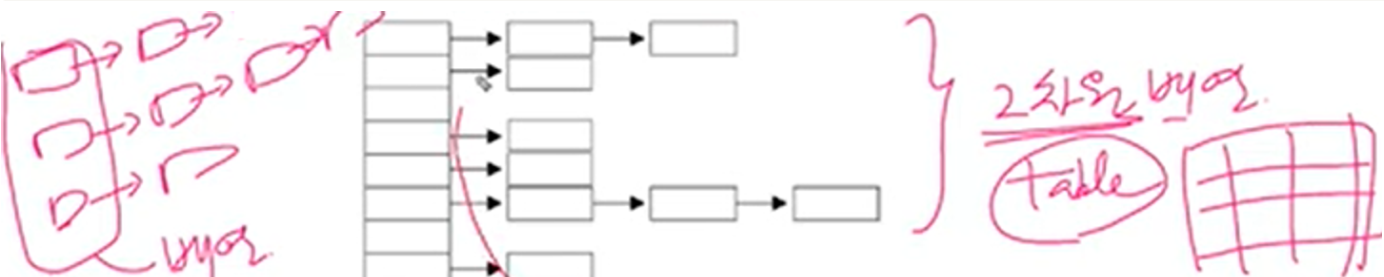
* 해시테이블은 배열과 링크드 리스트(LinkedList)가 조합된 형태
(LinkedList를 묶어놓으면 배열 형태)
* 왜? -> LinkedList로한 이유는 변경하기 쉽게 만들기 위해서
배열의 장점은 접근성이다.
* 해시함수는 Object.hash() 메서드를 이용해서 작성 (성능 중요)
해싱을 사용하는 클래스는
Hashtable, HashMap, HastSet이다.
hashCode() 메서드를 사용할 수 있다. (Object.hash() 오버라이딩)해싱(hashing) - (3/3)
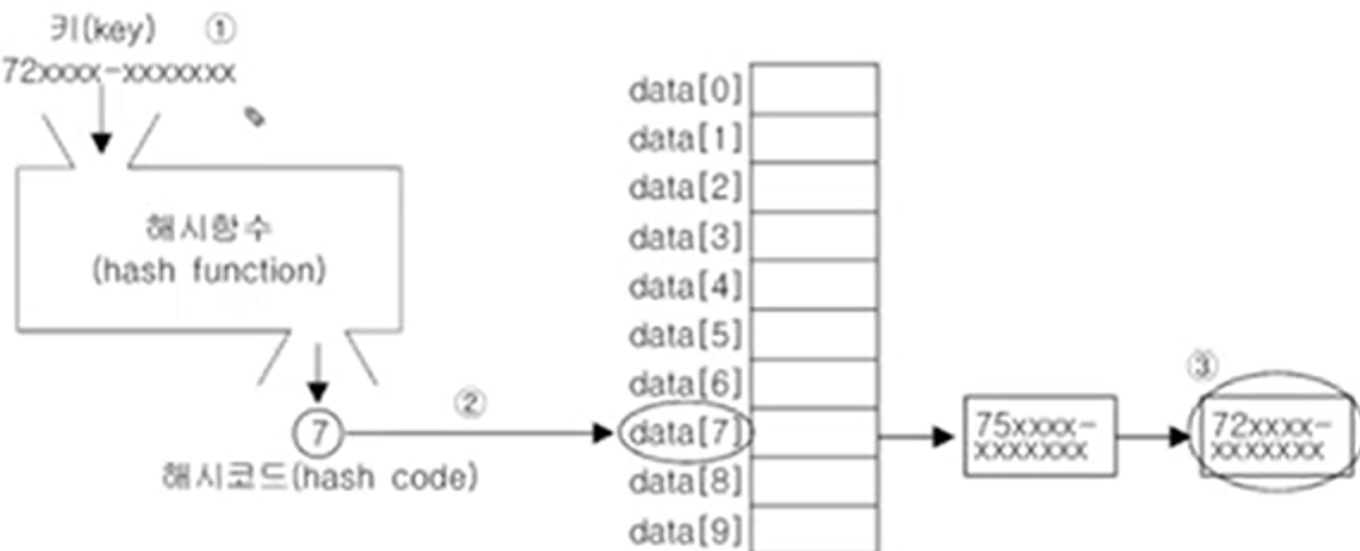
해시테이블에 저장된 데이터를 가져오는 과정
(1) 키로 해시함수를 호출해서 해시코드를 얻는다.
(2) 해시 코드(해시함수의 반환값)에 대응하는 LinkedList를 배열에서 찾는다.
(3) LinkedList에서 키와 일치하는 데이터를 찾는다.
* 해시 함수는 같은 키에 대해 같은 해시코드를 반환해야 한다.
서로 다른 키일지라도 같은 값의 해시코드를 반환할 수도 있다.
(3)을 보면 75xxxx-xx... 와 72xxxx-xx... 은 다른 키여도 인덱스가 7로 동일하므로
같은 값의 해시코드 반환한다.주요 생성자
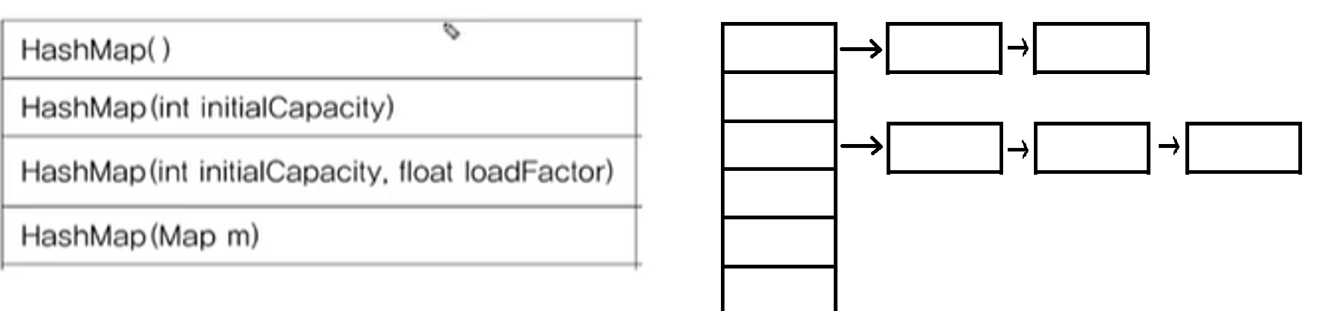
< Hashtable = 배열 + LinkedList >
HashMap은 Hashtable에 데이터를 저장한다.
Hashtable = 배열 + LinkedList
* HashMap(int initalCapacity) : 매개변수에 배열초기용량(=initalCapacity)을 받아온다.
* HashMap(int initalCapacity, floast loadFactor) : 배열과 관련된 것은 배열초기용량(=initalCapacity)과 로드팩터(=loadFactor) 등을 받아온다.
* HashMap(Map m): 외부에서 받은 Map을 HashMap으로 변경주요 메서드

* Object put(Object key, Object value) : key와 value로 데이터 저장
* void putAll(Map m) : 매개변수로 Map을 받아 저장
* Object remove(Object key) : key를 받아 해당 데이터 삭제
* Object replace(Object key, Object value) : 기존의 지정된 key 새로운 value(값)으로 변경
* Set entrySet() : key와 value 쌍들로 이루어진 Set을 얻을 수 있다.
* Set keySet() : key 값만 가져옴
* Set entrySet() : value 값만 가져옴
* Object get(Object key) : 특정 key 를 넣으면 value를 반환
* Object getOrDefault(Object key, Object defaultValue) : 매개변수로 가져온 key가 없을 때 defaultValue(=지정된 값) 반환
* boolean containsKey(Object key) : key가 포함되어 있는지 (T/F)
* boolean containsValue(Object value) : value가 있는지 (T/F)
* int size() : 크기
* boolean isEmpty() : 비었는지 (T/F)
* void clear() : 모두 삭제
* Object colne() : 복제예제
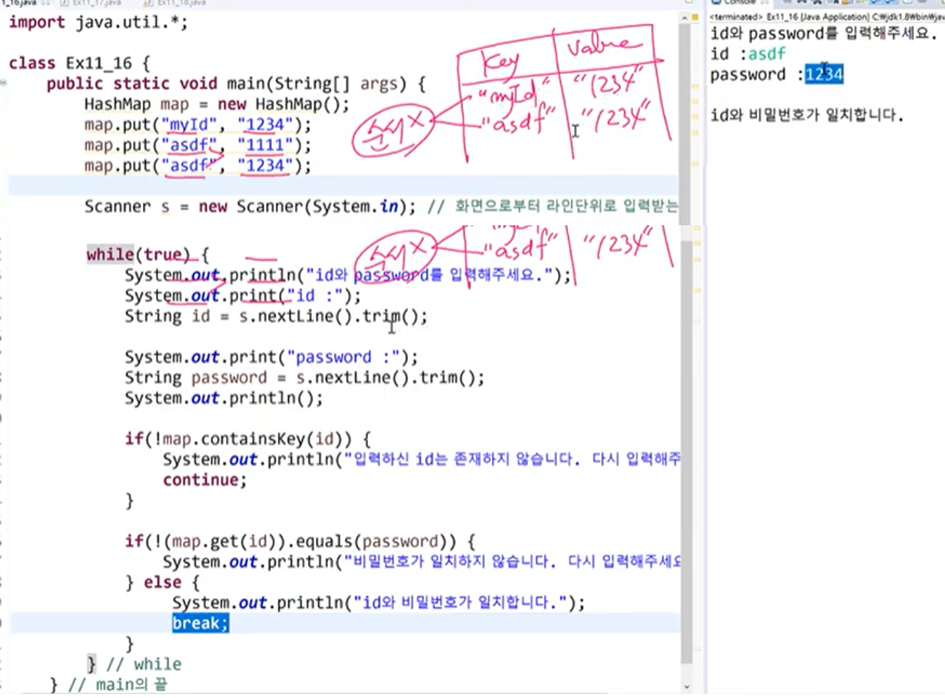
HashMap에 동일한 key로 put으로 저장하려고 하면 덮어씌운다 (초기에 1111값으로 저장했으나, 동일 key가 put으로 value가 1234로 요청되어 1234로 변경)
HashMap은 순서가 보장되지 않는다.
Scanner로 nextLine() -> String (문자열)을 입력 받는데, trim() 메소드로 공백 제거하여 id와 passwod에 저장되도록 한다.
!map.containsKey(id): id(=key)가 map에 포함되어 있지 않으면 콘솔에 "입력하신 id가 존재하지 않는다." 라고 출력
!(map.get(id)).equals(password): id(=key)에 일치하는 value, 즉 password를 반환받아 입력한 password와 동일하지 않다면 "비밀번호가 일치하지 않습니다." 출력 / 동일하다면 "id과 비밀번호가 일치합니다" 출력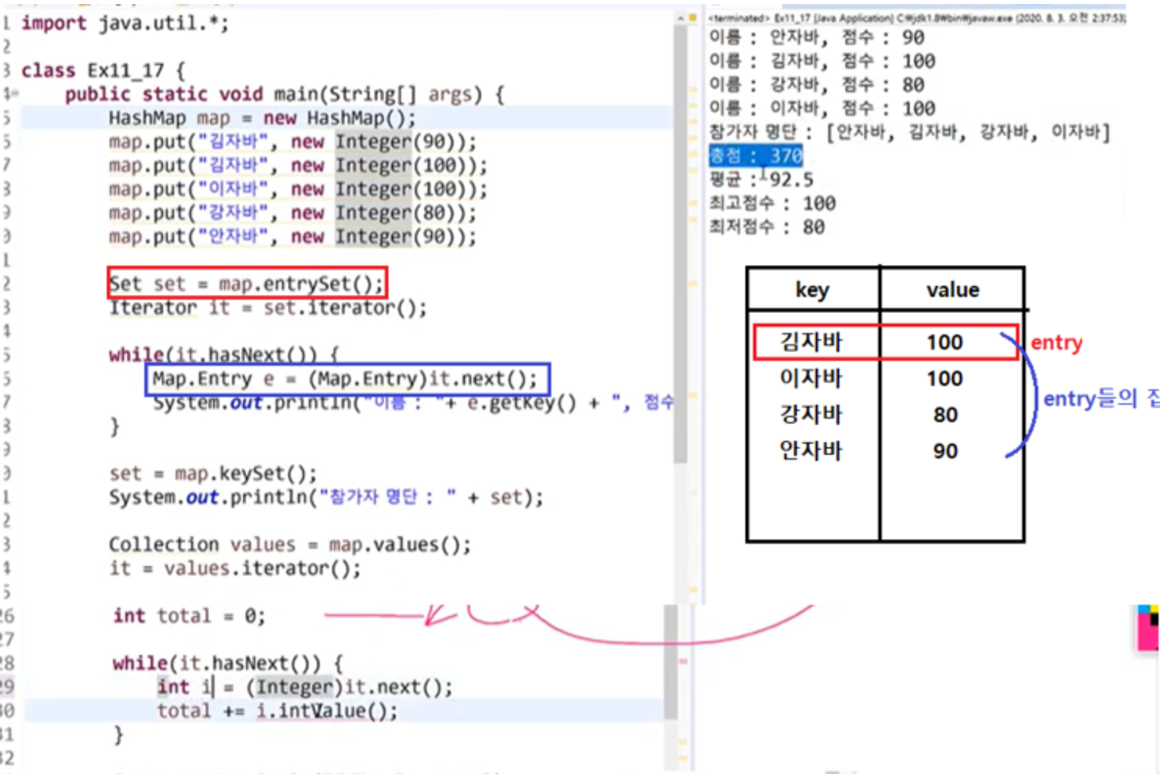
* map.entrySet() : map에 저장된 key와 value가 묶인 것이 entry인데, entry의 집합을 반환한다.
Set으로 반환 받은 entry의 집합은 Iterator로 hasNext() 메서드를 이용해 요소들이 있다면 Map.Entry로 형변환하여 변수 e를 리턴받는다.
e는 존재하는 요소들을 모두 출력하며 getKey()와 getValue()로 이름과 점수를 출력한다.
* map.keySet() : hashMap의 이름을 가져온다 (=key들)
* map.values() : hashMap의 점술수를 가져온다 (=value들)
Collection 으로 반환받아 values에 저장한다.
values.iterator()를 it에 저장하여 컬렉션을 순회하며 다음 요소들을 while문을 돌린다.
그리고 (Integer)로 형변환 하여 it의 next() 값들을 total에 저장한다.01. 학급회장(해쉬)
설명
학급 회장을 뽑는데 후보로 기호 A, B, C, D, E 후보가 등록을 했습니다.
투표용지에는 반 학생들이 자기가 선택한 후보의 기호(알파벳)가 쓰여져 있으며 선생님은 그 기호를 발표하고 있습니다.
선생님의 발표가 끝난 후 어떤 기호의 후보가 학급 회장이 되었는지 출력하는 프로그램을 작성하세요.
반드시 한 명의 학급회장이 선출되도록 투표결과가 나왔다고 가정합니다.입력
첫 줄에는 반 학생수 N(5<=N<=50)이 주어집니다.
두 번째 줄에 N개의 투표용지에 쓰여져 있던 각 후보의 기호가 선생님이 발표한 순서대로 문자열로 입력됩니다.출력
학급 회장으로 선택된 기호를 출력합니다.예시 입력 1
15
BACBACCACCBDEDE예시 출력 1
CSacanner의 next()와 nextLine()의 차이점과 주의할 점
package section4;
import java.util.HashMap;
import java.util.Scanner;
//학급 회장(해쉬)
public class ExampleOne {
public char solution(int n, String str) {
char answer = ' ';
int max = Integer.MIN_VALUE;
HashMap<Character, Integer> hashMap = new HashMap<>();
for (char c : str.toCharArray()) {
hashMap.put(c, hashMap.getOrDefault(c, 0) + 1);
}
for (char key : hashMap.keySet()) {
if (hashMap.get(key) > max) {
max = hashMap.get(key);
answer = key;
}
}
return answer;
}
public static void main(String[] args) {
ExampleOne T = new ExampleOne();
Scanner kb = new Scanner(System.in);
int n = kb.nextInt();
String str = kb.nextLine();
System.out.println(T.solution(n, str));
}
}해당 코드를
15
BACBACCACCBDEDE
를 입력하면 출력이 아무것도 안나오는 오류가 있었다.
**왜?**
-> 이유는 String str = kb.nextLine(); 때문이었다.
nextLine()은 엔터키를 입력으로 받아 한 줄을 ㅇ릭어들이는데, 이전에 입력받은 nextInt()로 인해 남아있는 엔터키를 읽어들여 아무 출력이 없다.
따라서 nextLine()을 쓸거면
int n = kb.nextInt();
kb.nextLine(); // 엔터 키 소비
String str = kb.nextLine();
라고 써주어서 엔터 키를 소비를 해주던가
int n = kb.nextInt();
String str = kb.next();
라고 써야 한다.* nextLine() : 사용자가 입력한 한 줄 전체를 읽어들인다.
개행 문자(\n)를 기준으로 한 줄을 읽어들이기 때문에, 공백이나 다른 특수 문자를 포함한 한 줄 전체를 가져온다.
사용자가 엔터 키를 입력할 때까지의 모든 문자열을 읽는다.
* next() : 공백이나 다른 구분자(delimiter)를 기준으로 한 단어(문자열)만을 읽어들인다.
사용자가 공백을 포함하지 않는 단어를 입력할 때까지의 문자열을 가져온다.코드1
import java.util.HashMap;
import java.util.Scanner;
//학급 회장(해쉬)
public class Main {
public char solution(int n, String str) {
char answer = ' ';
int max = Integer.MIN_VALUE;
//HashMap의 key값은 알파벳, value는 알파벳의 개수를 저장할 것이다.
HashMap<Character, Integer> hashMap = new HashMap<>();
for (char c : str.toCharArray()) {
//hashMap.getOrDefault(c,0)+1 : c의 Key 값을 가져오되(알파벳 개수), 없다면 0으로 리턴
//HashMap은 순서 X(순서가 보장되어 있지 않고), 중복 X(동일 Key이면 값(Value)는 덮어쓰기 된다
hashMap.put(c, hashMap.getOrDefault(c, 0) + 1);
}
//hashMap.keySet(): 모든 key들을 반환
for (char key : hashMap.keySet()) {
// hashMap.get(key): key 값(value)
if (hashMap.get(key) > max) {
max = hashMap.get(key);
answer = key;
}
}
return answer;
}
public static void main(String[] args) {
Main T = new Main();
Scanner kb = new Scanner(System.in);
int n = kb.nextInt();
String str = kb.next();
System.out.println(T.solution(n, str));
}
}02. 아나그램(해쉬)
설명
Anagram이란 두 문자열이 알파벳의 나열 순서를 다르지만 그 구성이 일치하면 두 단어는 아나그램이라고 합니다.
예를 들면 AbaAeCe 와 baeeACA 는 알파벳을 나열 순서는 다르지만 그 구성을 살펴보면 A(2), a(1), b(1), C(1), e(2)로
**알파벳과 그 개수가 모두 일치합니다.** 즉 어느 한 단어를 재 배열하면 상대편 단어가 될 수 있는 것을 아나그램이라 합니다.
길이가 같은 두 개의 단어가 주어지면 두 단어가 아나그램인지 판별하는 프로그램을 작성하세요. 아나그램 판별시 대소문자가 구분됩니다.입력
첫 줄에 첫 번째 단어가 입력되고, 두 번째 줄에 두 번째 단어가 입력됩니다.
단어의 길이는 100을 넘지 않습니다.출력
두 단어가 아나그램이면 'YES'를 출력하고, 아니면 'NO'를 출력합니다.예시 입력 1
AbaAeCe
baeeACA예시 출력 1
YES예시 입력 2
abaCC
Caaab예시 출력 2
NO코드
import java.util.HashMap;
import java.util.Scanner;
//아나그램(해쉬)
public class Main {
public String solution(String arr1, String arr2) {
String answer = "YES";
HashMap<Character, Integer> map = new HashMap<>();
//map에 arr1의 문자열의 문자들와 해당 문자들의 개수를 담았다.
for (char x : arr1.toCharArray()) {
map.put(x, map.getOrDefault(x, 0) + 1);
}
for (char x : arr2.toCharArray()) {
/**
* if문 : 아나그램이 아닌 상황
*/
//key가 존재하는지 (t/f) 존재하면 t를 반환하므로 ! 를 앞에 붙여준다
//key의 값이 0 : arr2에 key가 존재하는데도 불구하고 arr2은 arr1(=x)의 문자열의 문자보다 1개 더 많다는 뜻
if (!map.containsKey(x) || map.get(x) == 0) return "NO";
map.put(x, map.get(x) - 1);
}
return answer;
}
public static void main(String[] args) {
Main T = new Main();
Scanner kb = new Scanner(System.in);
String arr1 = kb.next();
String arr2 = kb.next();
System.out.println(T.solution(arr1, arr2));
}
}03. 매출액의 종류
설명
현수의 아빠는 제과점을 운영합니다. 현수아빠는 현수에게 N일 동안의 매출기록을 주고 연속된 K일 동안의 매출액의 종류를
각 구간별로 구하라고 했습니다.
만약 N=7이고 7일 간의 매출기록이 아래와 같고, 이때 K=4이면
20 12 20 10 23 17 10
각 연속 4일간의 구간의 매출종류는
첫 번째 구간은 [20, 12, 20, 10]는 매출액의 종류가 20, 12, 10으로 3이다.
두 번째 구간은 [12, 20, 10, 23]는 매출액의 종류가 4이다.
세 번째 구간은 [20, 10, 23, 17]는 매출액의 종류가 4이다.
네 번째 구간은 [10, 23, 17, 10]는 매출액의 종류가 3이다.
N일간의 매출기록과 연속구간의 길이 K가 주어지면 첫 번째 구간부터 각 구간별
매출액의 종류를 출력하는 프로그램을 작성하세요.입력
첫 줄에 N(5<=N<=100,000)과 K(2<=K<=N)가 주어집니다.
두 번째 줄에 N개의 숫자열이 주어집니다. 각 숫자는 500이하의 음이 아닌 정수입니다.출력
첫 줄에 각 구간의 매출액 종류를 순서대로 출력합니다.예시 입력 1
7 4
20 12 20 10 23 17 10예시 출력 1
3 4 4 3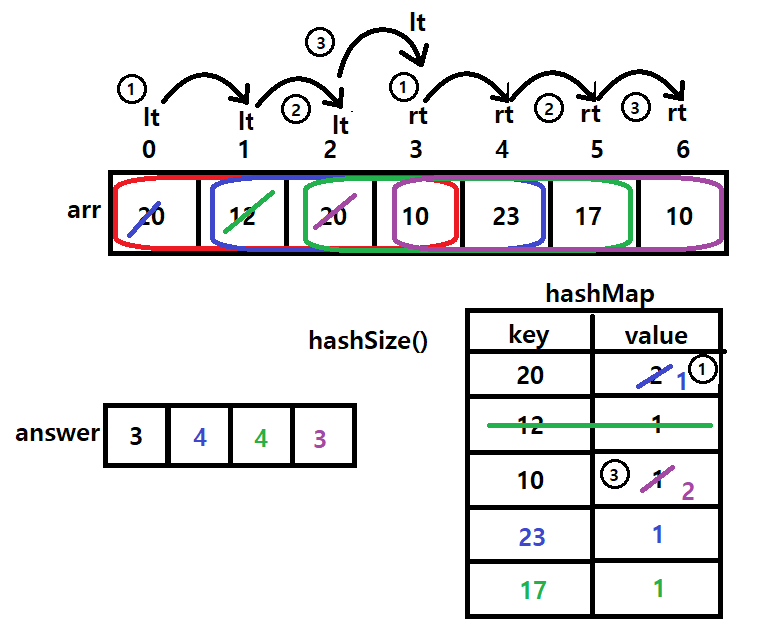
< Two pointers 알고리즘 으로 풀이 >
Sliding Window + HashMap 형태
한 칸씩 밀려나가면서 구간 별로, 중복되는 숫자는 하나로 취급하여 몇 개인지 구하는 문제
중복을 허용하지 않으므로 HashMap의 Key-Value를 이용해보자
Value를 동일 Key라면 +1씩 늘려주고 그대로 HashMap의 size로 카운드코드 1
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Scanner;
//매출액의 종류
public class Main{
public List<Integer> solution(int n, int k, int[] arr) {
List<Integer> list = new ArrayList<>();
HashMap<Integer, Integer> map = new HashMap<>();
**/**
* 방법 1 , sliding window 방식
*/**
for (int i = 0; i < k; i++) {
//초기에 0부터 3 인덱스까지의 arr을 map에 저장
//arr[0]와 arr[2]는 20이므로 동일 Key이다. -> Key는 중복이 불가능하고, value를 2로 설정해주자
map.put(arr[i], map.getOrDefault(arr[i], 0) + 1);
}
//초기 0번부터 3까지의 map 사이즈 (20,12,10 -> 3) list에 저장
list.add(map.size());
//다음 인덱스 번호의 값을 map에 추가해주고, 맨 처음으로 오는 인덱스 번호의 값을 map에서 삭제
for (int i = k; i < n; i++) {
//맨 처음으로 오는 key를 map에서 삭제시에 value가 1이라면 map에 key-value 자체를 제거
if (map.get(arr[i - k]) == 1) map.remove(arr[i - k]);
//1보다 크다면 포함하는 구간이 처음으로 오는 key와 동일 key를 가지고 있다면 value만 -1 해준다 (key-value 형상 자체는 남아있음)
else if (map.get(arr[i-k]) > 1) map.put(arr[i - k], map.get(arr[i - k]) - 1);
//arr의 다음 인덱스 번호 값을 map의 key에 추가하고, value도 +1 해준다.
map.put(arr[i], map.getOrDefault(arr[i], 0) + 1);
//구간의 크기(=중복x)를 list에 저장
list.add(map.size());
}
return list;
}
public static void main(String[] args) {
MainT = new Main();
Scanner kb = new Scanner(System.in);
int n = kb.nextInt();
int k = kb.nextInt();
int[] arr = new int[n];
for (int i = 0; i < n; i++) {
arr[i] = kb.nextInt();
}
for (int x : T.solution(n, k, arr)) {
System.out.print(x + " ");
}
}
}코드 2
package section4;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Scanner;
//매출액의 종류
public class ExampleThree {
public List<Integer> solution(int n, int k, int[] arr) {
List<Integer> list = new ArrayList<>();
HashMap<Integer, Integer> map = new HashMap<>();
/**
* 방법 1 , sliding window 방식
*/
// for (int i = 0; i < k; i++) {
// //초기에 0부터 3 인덱스까지의 arr을 map에 저장
// //arr[0]와 arr[2]는 20이므로 동일 Key이다. -> Key는 중복이 불가능하고, value를 2로 설정해주자
// map.put(arr[i], map.getOrDefault(arr[i], 0) + 1);
// }
// //초기 0번부터 3까지의 map 사이즈 (20,12,10 -> 3) list에 저장
// list.add(map.size());
// //다음 인덱스 번호의 값을 map에 추가해주고, 맨 처음으로 오는 인덱스 번호의 값을 map에서 삭제
// for (int i = k; i < n; i++) {
// //맨 처음으로 오는 key를 map에서 삭제시에 value가 1이라면 map에 key-value 자체를 제거
// if (map.get(arr[i - k]) == 1) map.remove(arr[i - k]);
// //1보다 크다면 포함하는 구간이 처음으로 오는 key와 동일 key를 가지고 있다면 value만 -1 해준다 (key-value 형상 자체는 남아있음)
// else if (map.get(arr[i-k]) > 1) map.put(arr[i - k], map.get(arr[i - k]) - 1);
// //arr의 다음 인덱스 번호 값을 map의 key에 추가하고, value도 +1 해준다.
// map.put(arr[i], map.getOrDefault(arr[i], 0) + 1);
// //구간의 크기(=중복x)를 list에 저장
// list.add(map.size());
// }
**/**
* 방법 2, two pointers 알고리즘 방식 (rt, lt)
*/**
//3일을 구간 먼저 세팅
for (int i = 0; i < k - 1; i++) {
map.put(arr[i], map.getOrDefault(arr[i], 0) + 1);
}
int lt = 0;
for (int rt = k - 1; rt < n; rt++) {
//4일 구간 마저 세팅
map.put(arr[rt], map.getOrDefault(arr[rt], 0) + 1);
//구간의 숫자 개수 count
list.add(map.size());
//구간 중 처음에 위치했던 key의 value를 -1로 설정
map.put(arr[lt], map.get(arr[lt]) - 1);
//구간 중 처음 위치했던 key의 value가 0이라면 삭제
if (map.get(arr[lt]) == 0) map.remove(arr[lt]);
lt++;
}
return list;
}
public static void main(String[] args) {
ExampleThree T = new ExampleThree();
Scanner kb = new Scanner(System.in);
int n = kb.nextInt();
int k = kb.nextInt();
int[] arr = new int[n];
for (int i = 0; i < n; i++) {
arr[i] = kb.nextInt();
}
for (int x : T.solution(n, k, arr)) {
System.out.print(x + " ");
}
}
}04. 모든 아나그램 찾기 (해쉬, 투포인터, 슬라이딩 윈도우)
설명
S문자열에서 T문자열과 아나그램이 되는 S의 부분문자열의 개수를 구하는 프로그램을 작성하세요.
아나그램 판별시 대소문자가 구분됩니다. 부분문자열은 연속된 문자열이어야 합니다.입력
첫 줄에 첫 번째 S문자열이 입력되고, 두 번째 줄에 T문자열이 입력됩니다.
S문자열의 길이는 10,000을 넘지 않으며, T문자열은 S문자열보다 길이가 작거나 같습니다.출력
S단어에 T문자열과 아나그램이 되는 부분문자열의 개수를 출력합니다.예시 입력 1
bacaAacba
abc예시 출력 1
3힌트
출력설명: {bac},{acb},{cba} 3개의 부분문자열이 "abc"문자열과 아나그램입니다.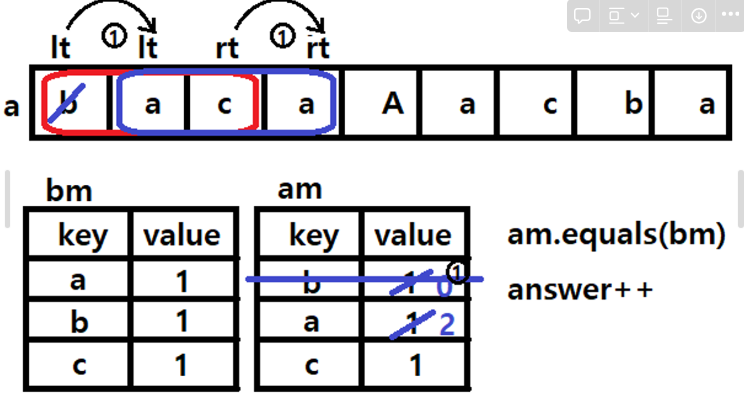
코드 1 - 메소드로 생성해 호출
import java.util.HashMap;
import java.util.Scanner;
//모든 아나그램 찾기
public class Main {
public int solution(String s, String t) {
int answer = 0;
char[] charArray = s.toCharArray();
HashMap<Character, Integer> map = new HashMap<>();
for (int i = 0; i < t.length()-1; i++) {
map.put(charArray[i], map.getOrDefault(charArray[i], 0) + 1);
}
int lt = 0;
for (int rt = t.length()-1; rt < s.length(); rt++) {
map.put(charArray[rt], map.getOrDefault(charArray[rt], 0) + 1);
// 현재 부분문자열에 대한 아나그램 여부 판단
if (map.equals(getFrequencyMap(t))) {
answer++;
}
map.put(charArray[lt], map.get(charArray[lt]) - 1);
if (map.get(charArray[lt]) == 0) map.remove(charArray[lt]);
lt++;
}
return answer;
}
private HashMap<Character, Integer> getFrequencyMap(String str) {
HashMap<Character, Integer> map = new HashMap<>();
for (char ch : str.toCharArray()) {
map.put(ch, map.getOrDefault(ch, 0) + 1);
}
return map;
}
public static void main(String args[]) {
Main T = new Main();
Scanner kb = new Scanner(System.in);
String s = kb.next();
String t = kb.next();
System.out.println(T.solution(s,t));
}
}코드 2 - 초기에 모두 세팅
import java.util.HashMap;
import java.util.Scanner;
//모든 아나그램 찾기
public class Main {
public int solution(String a, String b) {
int answer = 0;
HashMap<Character, Integer> am = new HashMap<>();
HashMap<Character, Integer> bm = new HashMap<>();
//b의 문자열을 HashMap인 bm에 저장
for (char x : b.toCharArray()) bm.put(x, bm.getOrDefault(x, 0) + 1);
//a의 문자열을 b의 문자열 길이보다 -1 작은 길이만큼 HashMap인 am에 저장 (만약 b가 3개의 문자가 담긴 문자열이라면 2개의 문자만 map에 저장)
for (int i=0; i < b.length()-1; i++) am.put(a.charAt(i), am.getOrDefault(a.charAt(i), 0) + 1);
//마지막 문자를 am에 저장하고, am과 bm이 동일한지(=아나그램인지) 확인 후 answer++
//이후에는 am의 첫번째로 저장한 entry에 value 값을 -1 해주고, value가 0이라면 해당 entry를 삭제
int lt = 0;
for (int rt = b.length()-1; rt < a.length(); rt++) {
am.put(a.charAt(rt), am.getOrDefault(a.charAt(rt), 0) + 1);
if(am.equals(bm)) answer++;
am.put(a.charAt(lt), am.get(a.charAt(lt)) - 1);
if (am.get(a.charAt(lt)) == 0) am.remove(a.charAt(lt));
lt++;
}
return answer;
}
public static void main(String args[]) {
Main T = new Main();
Scanner kb = new Scanner(System.in);
String a = kb.next();
String b = kb.next();
System.out.println(T.solution(a,b));
}
}05. K번째 큰 수
설명
현수는 1부터 100사이의 자연수가 적힌 N장의 카드를 가지고 있습니다. 같은 숫자의 카드가 여러장 있을 수 있습니다.
현수는 이 중 3장을 뽑아 각 카드에 적힌 수를 합한 값을 기록하려고 합니다. 3장을 뽑을 수 있는 모든 경우를 기록합니다.
기록한 값 중 K번째로 큰 수를 출력하는 프로그램을 작성하세요.
만약 큰 수부터 만들어진 수가 25 25 23 23 22 20 19......이고 K값이 3이라면 K번째 큰 값은 22입니다.입력
첫 줄에 자연수 N(3<=N<=100)과 K(1<=K<=50) 입력되고, 그 다음 줄에 N개의 카드값이 입력된다.출력
첫 줄에 K번째 수를 출력합니다. K번째 수가 존재하지 않으면 -1를 출력합니다.예시 입력 1
10 3
13 15 34 23 45 65 33 11 26 42예시 출력 1
1433장을 뽑기 때문에 3중 for문을 쓰면 된다.
여기서 주의할 점은 '중복' 값이 있을 수 있다. 25 25 23 23 22... 이러면 25가 겹치고, 23도 겹친다.
중복된 값은 한번만 셀 수 있다.
**Set은 중복을 허락하지 않기 때문에 기존에 들어있으면 넣지 않는다. (중복제거)**
Set 안에서 정렬까지 되어있으면 좋을 것 같다.
**자동으로 내림차순이던 오름차순이던 정렬해주고 싶을 때는 TreeSet
=> 중복X, 자동정렬
이진트리**코드
import java.lang.reflect.Array;
import java.util.Collections;
import java.util.Scanner;
import java.util.TreeSet;
//K번째 큰 수
public class Main {
public int solution(int n, int k, int[] arr) {
//k번째 수가 존재하지 않으면 -1 출력
int answer = -1;
//기본 생성자로 만들면 오름차순이지만, Collections.reverseOrder()를 사용하면 내림차순
TreeSet<Integer> Tset = new TreeSet<>(Collections.reverseOrder());
for (int i = 0; i < n; i++) {
for (int j = i + 1; j < n; j++) {
for (int l = j + 1; l < n; l++) {
Tset.add(arr[i] + arr[j] + arr[l]);
}
}
}
int cnt = 0;
for (int x : Tset) {
//Set에 저장된 숫자가 for문이 돌 때마다 cnt++
cnt++;
//cnt가 k번째 수와 동일하면 Set에 내림차순으로 정렬된 k번째 수 리턴
if (cnt == k) return x;
}
return answer;
}
public static void main(String[] args) {
Main T = new Main();
Scanner kb = new Scanner(System.in);
int n = kb.nextInt();
int k = kb.nextInt();
int[] arr = new int[n];
for (int i = 0; i < n; i++) {
arr[i] = kb.nextInt();
}
System.out.println(T.solution(n, k, arr));
}
}
Velog에 기록 중