데이터 정렬, df.sort_values()
- sort_values(by='정렬기준 column', ascending=True) , ascending=True : 오름차순(작은->큰)
CCTV_Seoul.sort_values(by='소계', ascending=True).head(5)- sort_values(by='정렬기준 column', ascending=False) , ascending=False : 내림차순(큰->작은)
CCTV_Seoul.sort_values(by='소계', ascending=False).head(5)
특정 컬럼만 읽기, df['columnA']
- 데이터프레임 중 특정 컬럼만 읽어올 시 컬럼이 숫자로 되어 있으면 불러올 수 없고 문자로만 가능
- 2개 이상 컬럼선택 : df[['columnA'], [columnB]]
슬라이싱, df[:, :]
- [ n:m, 'columnA':'columnB' ]
- n:m : 인덱스 범위, n부터 m-1까지, 이름으로 slice하는 경우 끝을 포함
- 'columnA':'columnB' : 칼럼 범위
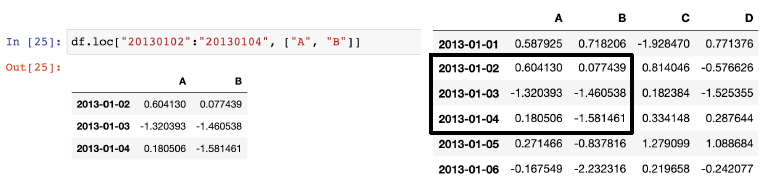
CCTV_Seoul.loc[:4, '구별':'소계']
#인덱스 0부터 3까지, 컬럼 '구별'부터 '소계'까지 슬라이싱슬라이싱, df.loc[] / df.iloc[]
- df.loc[ 'n' : 'm', [ 'columnA', 'columnB' ] ], 문자 그대로 슬라이싱

- df.iloc[ n : m , A : B ], 행, 열의 숫자로 슬라이싱
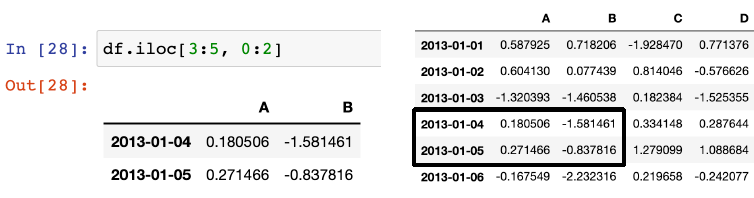
리스트로 슬라이싱, df.iloc[[], []]
- df.iloc[ [ 1, 2, 4 ], [ 0, 2 ] ], 행, 열의 숫자를 리스트로 담아 슬라이싱
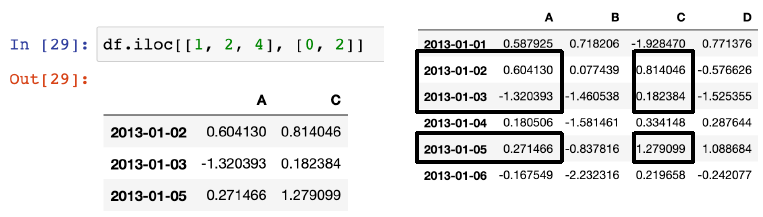
조건에 따른 데이터프레임 불러오기, df[condition]
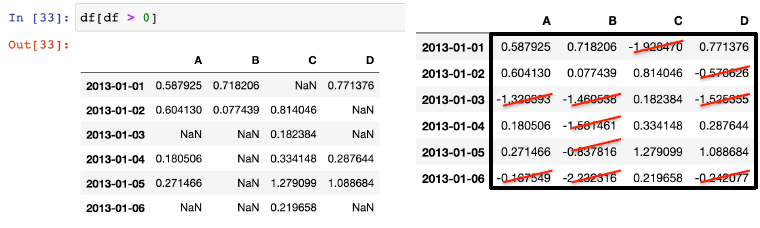
새로운 컬럼과 데이터 추가, df[column] = [리스트]
- 기존 컬럼이 있으면 수정 없다면 추가
특정요소가 있는 확인, df.isin([리스트])

isin을 통한 행 추출, df[df.isin([리스트])]

특정컬럼 제거, del['column']
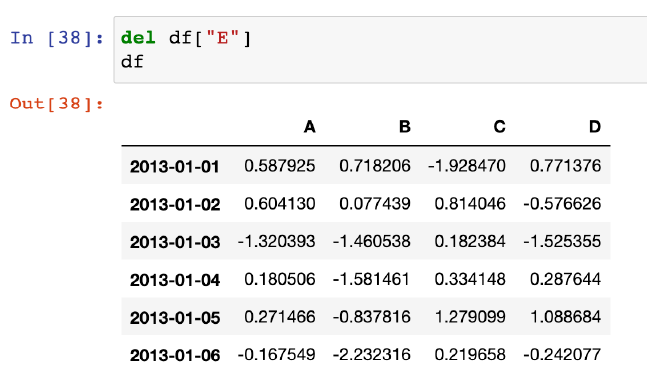
특정컬럼 제거, drop(['index' or 'column'], axis = 1 or 0)
- 인덱스(행) 삭제 시 axis = 0, 컬럼(열) 삭제 시 axis = 1
- 다수의 칼럼 및 인덱스 삭제 : ['1', '2', '3']와 같이 리스트로 묶어주기
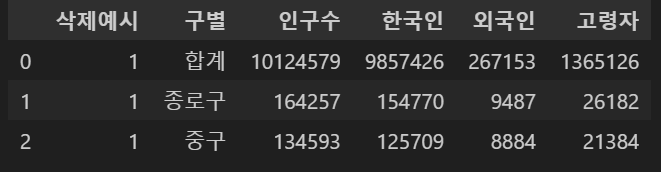
pop_seoul.drop([0], axis=0, inplace=True)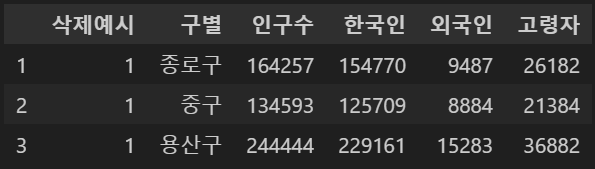
열을 특정 위치에 추가, df.insert(loc, column, value)
- loc: 열이 삽입될 위치를 지정하는 정수 인덱스 또는 열 이름
- column: 추가할 열의 이름
- value: 추가할 열의 값(스칼라, 배열 또는 시리즈)
pop_seoul.insert(0, '삭제예시', 1)
pop_seoul.head(3)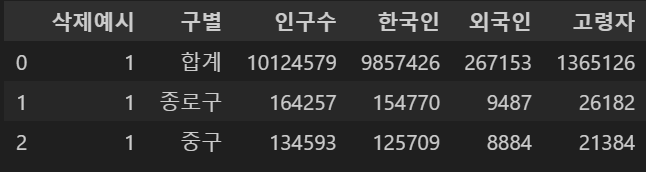
컬럼 및 인덱스의 고유 데이터 확인, df['index' or 'column'].unique()
- 중복없이 데이터 종류 확인
pop_seoul['구별'].unique()
array(['종로구', '중구', '용산구', '성동구', '광진구', '동대문구', '중랑구', '성북구', '강북구',
'도봉구', '노원구', '은평구', '서대문구', '마포구', '양천구', '강서구', '구로구', '금천구',
'영등포구', '동작구', '관악구', '서초구', '강남구', '송파구', '강동구'], dtype=object)컬럼별 연산
pop_seoul['외국인비율'] = pop_seoul['외국인']/pop_seoul['인구수'] * 100
pop_seoul['고령자비율'] = pop_seoul['고령자']/pop_seoul['인구수'] * 100
pop_seoul.head()
CCTV_Seoul['최근증가율'] = (
(CCTV_Seoul['2016년'] + CCTV_Seoul['2015년'] + CCTV_Seoul['2014년'])
/ CCTV_Seoul['2013년도 이전'] * 100)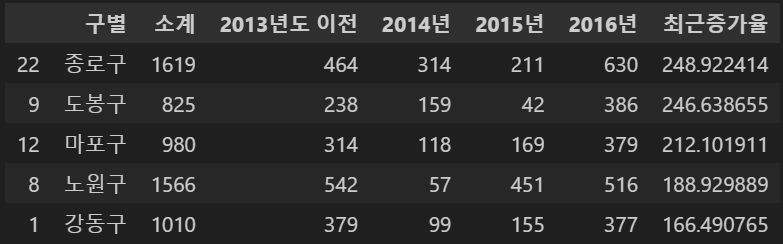
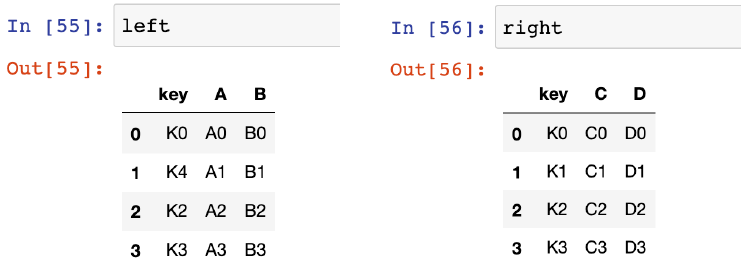
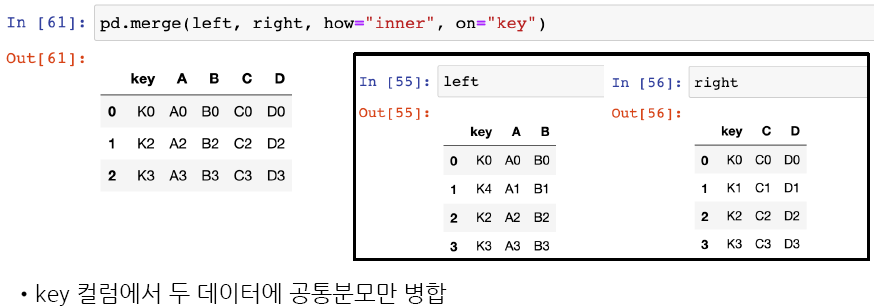
데이터프레임 병합, pd.merge(left, right, how, on ..)
- left, right: 병합할 데이터프레임 지정
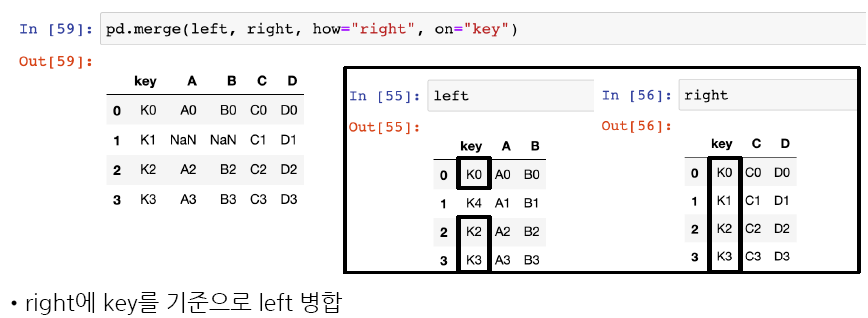
- how: 병합 방법을 지정하는 문자열로 일반적으로 사용되는 값으로는 'left', 'right', 'outer', 'inner' 등이 있으며 기본값은 'inner'
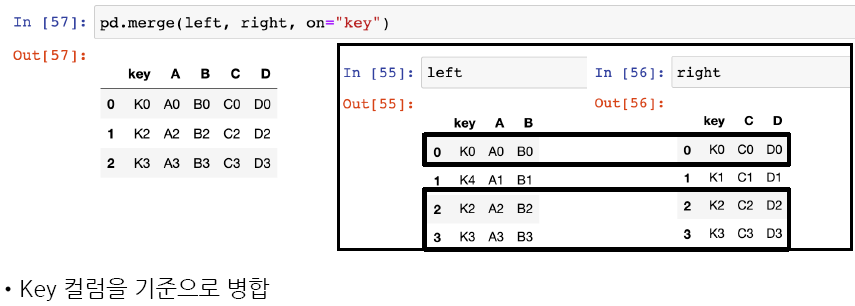
- on: 병합할 기준이 되는 열(또는 열의 리스트)의 이름, 이 매개변수를 사용하면 데이터프레임을 열 이름을 기준으로 병합 가능
- 만약 on 매개변수를 지정하지 않으면, 데이터프레임의 인덱스를 기준으로 병합
- left_on 및 right_on: 병합할 기준 열의 이름이 서로 다른 경우 사용
- left_index 및 right_index: 병합할 때 데이터프레임의 인덱스를 사용할지 여부를 지정, 기본값은 False
- merge 기준에 의한 값이 없다면 NaN값으로 표시


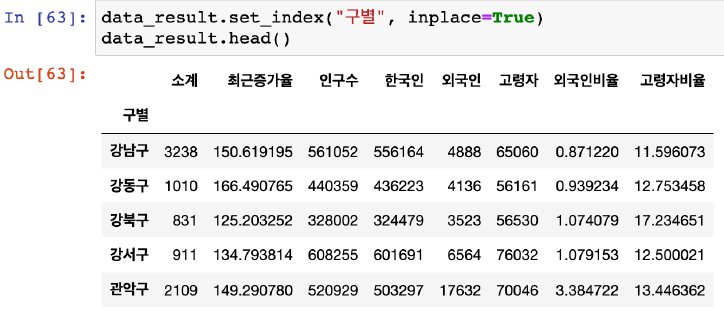
컬럼 데이터를 인덱스로 지정, df.set_index('column')
- 유니크한 컬럼을 인덱스로 지정 필요
인덱스 초기화, df.reset_index(drop=False)
- drop=False 시 초기화 후 0번째에 새로운 컬럼 미생성
- drop=True 시 초기화 후 0번째에 새로운 컬럼 생성
data_result.reset_index(drop=False, inplace=True)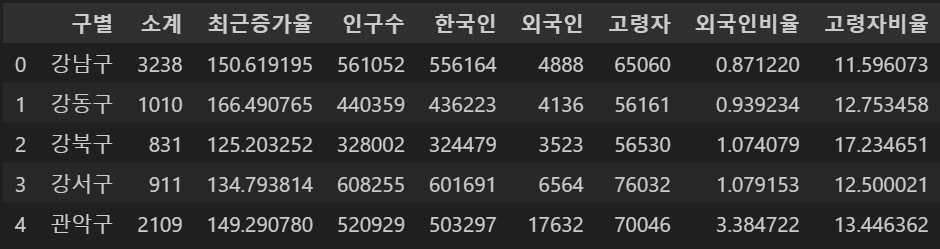
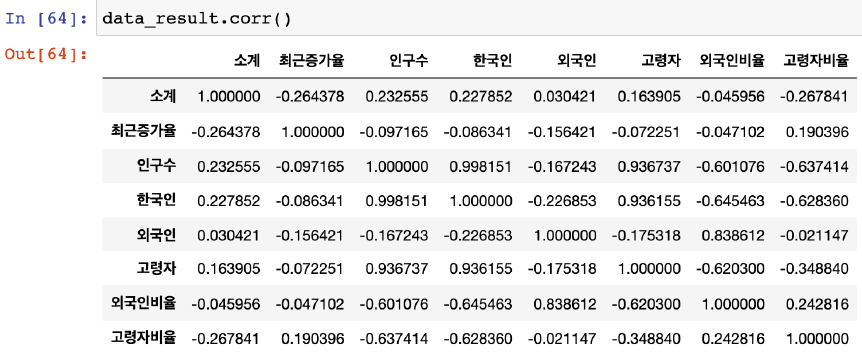
데이터 상관관계 확인, df.corr()
- 0.2 이상의 데이터부터 최소한의 의미가 있는 것으로 판단
- (-) 값이더라도 -0.2 이하는 의미가 역으로 생각하여 의미가 있는 것으로 판단

비전공 데이터 분석가 도전