pandas 출력
import pandas as pd
(import를 통하여 pandas 사용 선언)
Python 모듈에 대한 naming 규칙
- import Module
(Module을 사용하겠다 선언, Module.function) - import Module as md
(Module을 앞으로 md 형식과 같이 호출하겠다) - form Module import function
(Module 내에 있는 function 함수만 사용하겠다)
엑셀 및 CSV 파일 읽기
read_csv, read_excel
dftarget = pd.read csv ('../EDA_Level_Test_03 (배포용)/datas/Summer-Olympic-medals-1976-to-2008.csv', encoding = 'utf-8' )
- csv : 파일 형식으로 엑셀은 excel로 변환하여 사용하며 텍스트 파일은 csv로 조회
- '../EDA_Level_Test_03 (배포용)/datas/Summer-Olympic-medals-1976-to-2008.csv'
: 파일이 저장된 위치로 ' ../ '은 상위 폴더 이름이고 ' / ' 이후 tap버튼으로 저장 위치 조회 - encoding = 'utf-8' : 한글 인코딩 설정
- 인코딩 에러 무시 필요 시 encoding_errors = 'ignore' 설정 필요
- header = 불러오고자하는 행부터 출력, usecols = 필요한 열만 출력
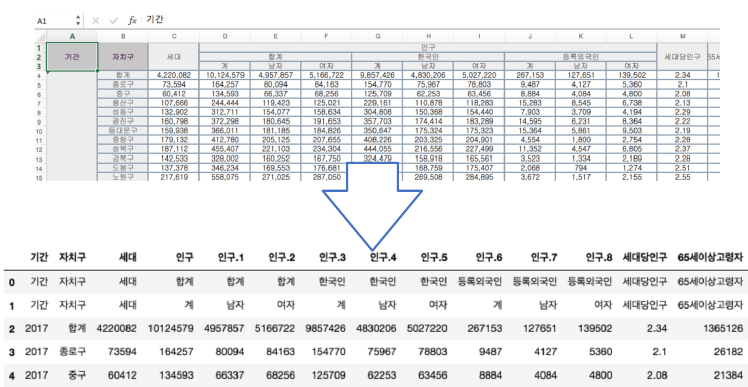
pop_seoul = pd.read_excel('../data/01. Seoul_Population.xls', header = 2, usecols='B, D, G, J, N')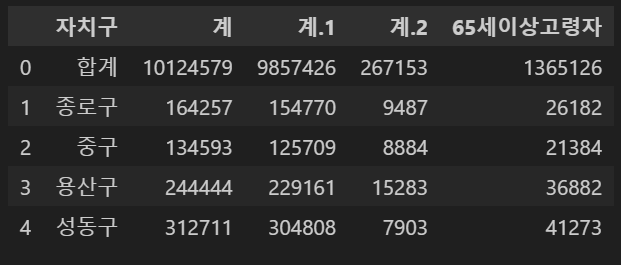
sep 확인하기
- xlsx파일은 엑셀 파일이기 때문에 구분 기준을 설정할 필요가 없음
- csv의 경우 기본은 콤마(,)로 값을 구분, 직접 csv파일을 메모장으로 열어보면서 값들이 공백으로 혹은 여타 다른 구분자로 구분되어있거나 한 것을 직접 확인
pandas DataFrame 구조
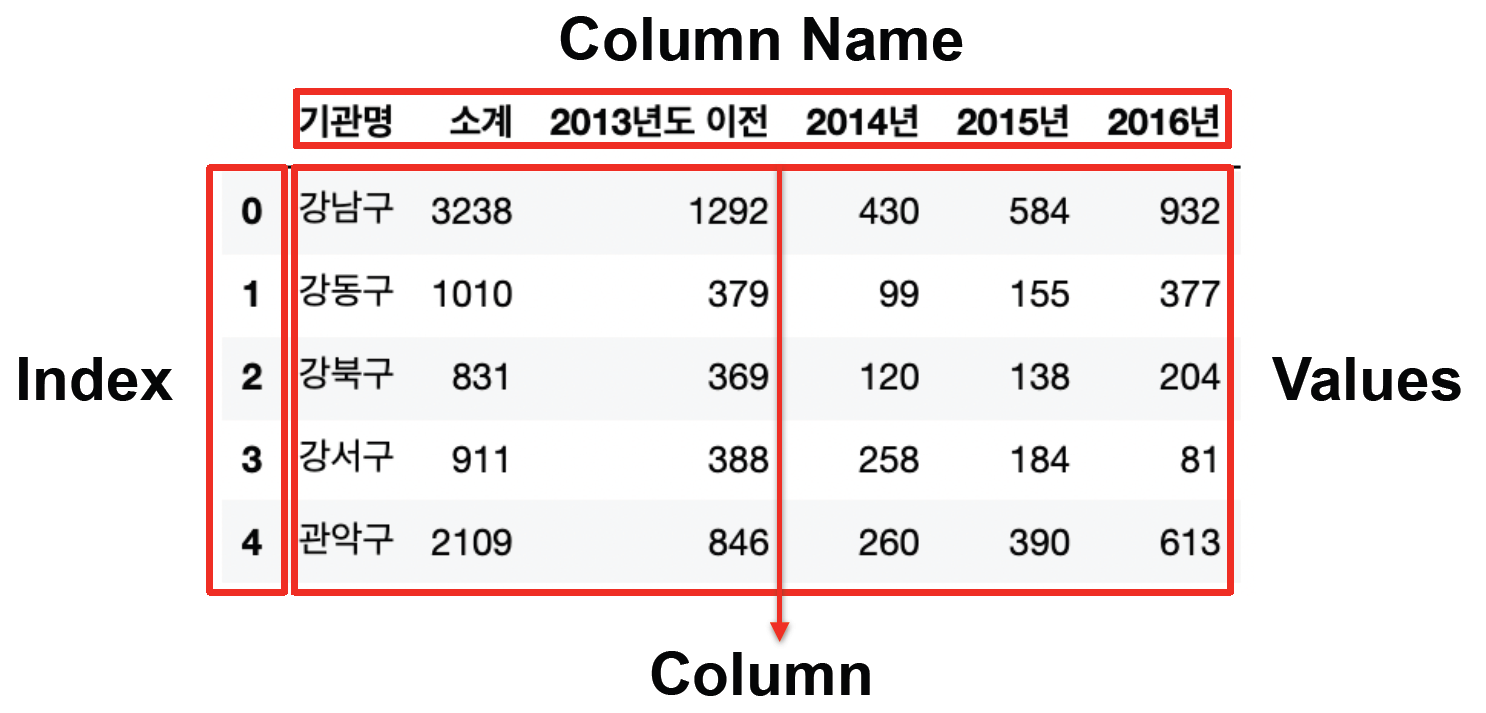
파일 읽기
앞에서부터 보여주기, df.head()
CCTV_Seoul.head(3)
#.head() : 앞에서부터 보여주기, "()" = 앞에서부터 몇까지 보여줄지 설정뒤에서부터 보여주기, df.tail()
CCTV_Seoul.tail(3)
#.tail() : 끝부터 보여주기, "()" = 뒤에서부터 몇까지 보여줄지 설정칼럼 이름 조회, df.columns
(dataframe변수).columns : 모든 칼럼 조회
CCTV_Seoul.columns
#.columns : 컬럼명을 리스트 형식으로 반환
Index(['기관명', '소계', '2013년도 이전', '2014년', '2015년', '2016년'], dtype='object')(dataframe변수).columns[?] : ? 번째 칼럼 조회
CCTV_Seoul.columns[0]
# .columns[] : []번째 컬럼 반환
'기관명'인덱스 조회, df.index
데이터 프레임 내 값 조회, df.values
CCTV_Seoul.values
# .values : DataFrame의 value값 확인
array([['강남구', 3238, 1292, 430, 584, 932],
['강동구', 1010, 379, 99, 155, 377],
['강북구', 831, 369, 120, 138, 204],
['강서구', 911, 388, 258, 184, 81],
['관악구', 2109, 846, 260, 390, 613],
['광진구', 878, 573, 78, 53, 174],
['구로구', 1884, 1142, 173, 246, 323],
['금천구', 1348, 674, 51, 269, 354],
['노원구', 1566, 542, 57, 451, 516],
['도봉구', 825, 238, 159, 42, 386],
['동대문구', 1870, 1070, 23, 198, 579],
['동작구', 1302, 544, 341, 103, 314],
['마포구', 980, 314, 118, 169, 379],
['서대문구', 1254, 844, 50, 68, 292],
['서초구', 2297, 1406, 157, 336, 398],
['성동구', 1327, 730, 91, 241, 265],
['성북구', 1651, 1009, 78, 360, 204],
['송파구', 1081, 529, 21, 68, 463],
['양천구', 2482, 1843, 142, 30, 467],
['영등포구', 1277, 495, 214, 195, 373],
['용산구', 2096, 1368, 218, 112, 398],
['은평구', 2108, 1138, 224, 278, 468],
['종로구', 1619, 464, 314, 211, 630],
['중구', 1023, 413, 190, 72, 348],
['중랑구', 916, 509, 121, 177, 109]], dtype=object)데이터프레임의 기본 정보 확인, df.info()
- DataFrame의 기본 정보를 확인 가능하며 각 컬럼의 크기와 데이터형태 확인
CCTV_Seoul.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 25 entries, 0 to 24
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 기관명 25 non-null object
1 소계 25 non-null int64
2 2013년도 이전 25 non-null int64
3 2014년 25 non-null int64
4 2015년 25 non-null int64
5 2016년 25 non-null int64
dtypes: int64(5), object(1)
memory usage: 1.3+ KB데이터 프레임의 통계적 정보 확인, df.describe()
CCTV_Seoul.describe()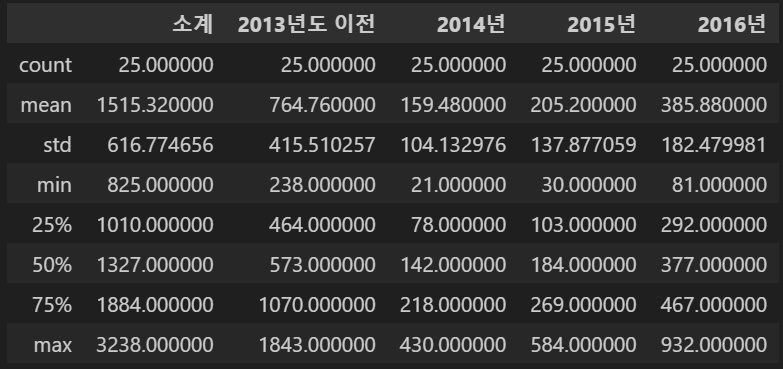
컬럼 이름 바꾸기, df.rename()
().rename(columns={데이터프레임네임[칼럼위치]: '바꿀컬럼명칭'})
().rename(columns={'현재컬럼명칭': '바꿀컬럼명칭'})
CCTV_Seoul.rename(columns={CCTV_Seoul.columns[0] : '구별'}).head(3)일괄적으로 이름 바꾸기
pop_seoul.rename(
columns={
pop_seoul.columns[0]:'구별',
pop_seoul.columns[1]:'인구수',
pop_seoul.columns[2]:'한국인',
pop_seoul.columns[3]:'외국인',
pop_seoul.columns[4]:'고령자'
},
inplace = True)
pop_seoul.head()원본 내용 바꾸기, inplace=True

비전공 데이터 분석가 도전