EDA
1.EDA_1 Analysis Seoul CCTV
pandas 출력 import pandas as pd (import를 통하여 pandas 사용 선언) Python 모듈에 대한 naming 규칙 import Module (Module을 사용하겠다 선언, Module.function) import Module as
2.EDA_2 Analysis Seoul CCTV
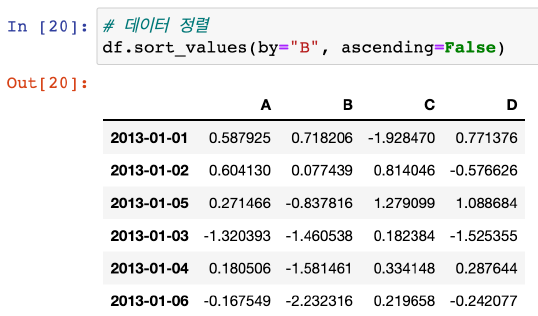
sort_values(by='정렬기준 column', ascending=True) , ascending=True : 오름차순(작은->큰)sort_values(by='정렬기준 column', ascending=False) , ascending=False : 내림차순(큰-
3.EDA_3 Analysis Seoul Crime
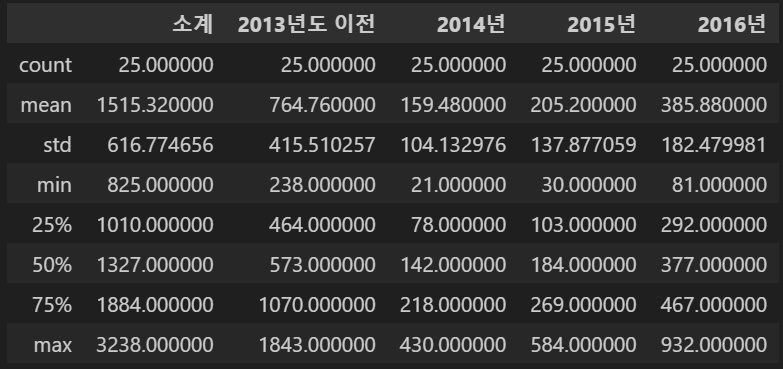
천단위 구분 삭제 및 숫자형 인식, thousands="," 숫자값들이 콤마(,)를 사용하고 있어 문자로 인식 될 가능성이 있음 천단위 구분(thousands=",")임을 인식시켜 콤마를 삭제하고 숫자형으로 읽기
4.EDA_4 Web Data
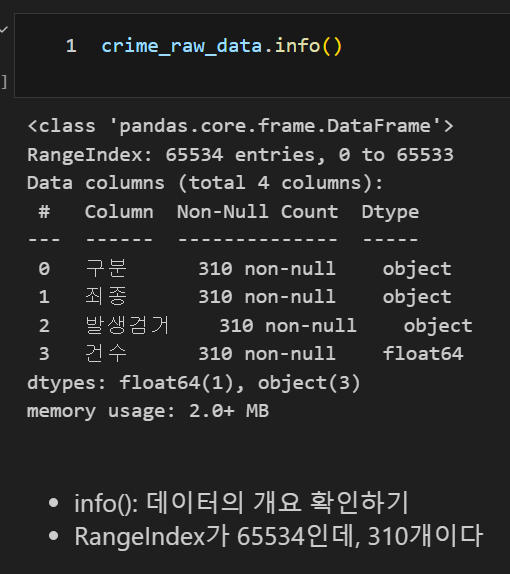
구별 데이터 정리 원하는 컬럼 인덱스 지정, index_col=지정할 컬럼 순서 컬럼 삭제 하나의 컬럼을 하나의 컬럼으로 나누기 , df[column1] / df[column2] 
By.ID: 요소의 id 속성을 사용하여 요소를 찾습니다.By.CLASS_NAME: 요소의 클래스 이름을 사용하여 요소를 찾습니다.By.NAME: 요소의 name 속성을 사용하여 요소를 찾습니다.By.TAG_NAME: 요소의 태그 이름을 사용하여 요소를 찾습니다.By.
6.EDA_6 NAVER API

네이버 개발자 센터 https://developers.naver.com/main/Application 어플리케이션 등록어플리케이션 이름 ds_study 사용 API 검색데이터랩(검색어트렌드)데이터랩(쇼핑인사이트)환경추가 WEB 설정 http://loc
7.EDA_7 Population
value = : NaN값을 value에서 지정한 값으로 채워라method : {'backfill', 'bfill', 'pad', 'ffill', None}, default None pad / ffill: 바로 직전 데이터를 가져와서 채워줘라 backfill / b