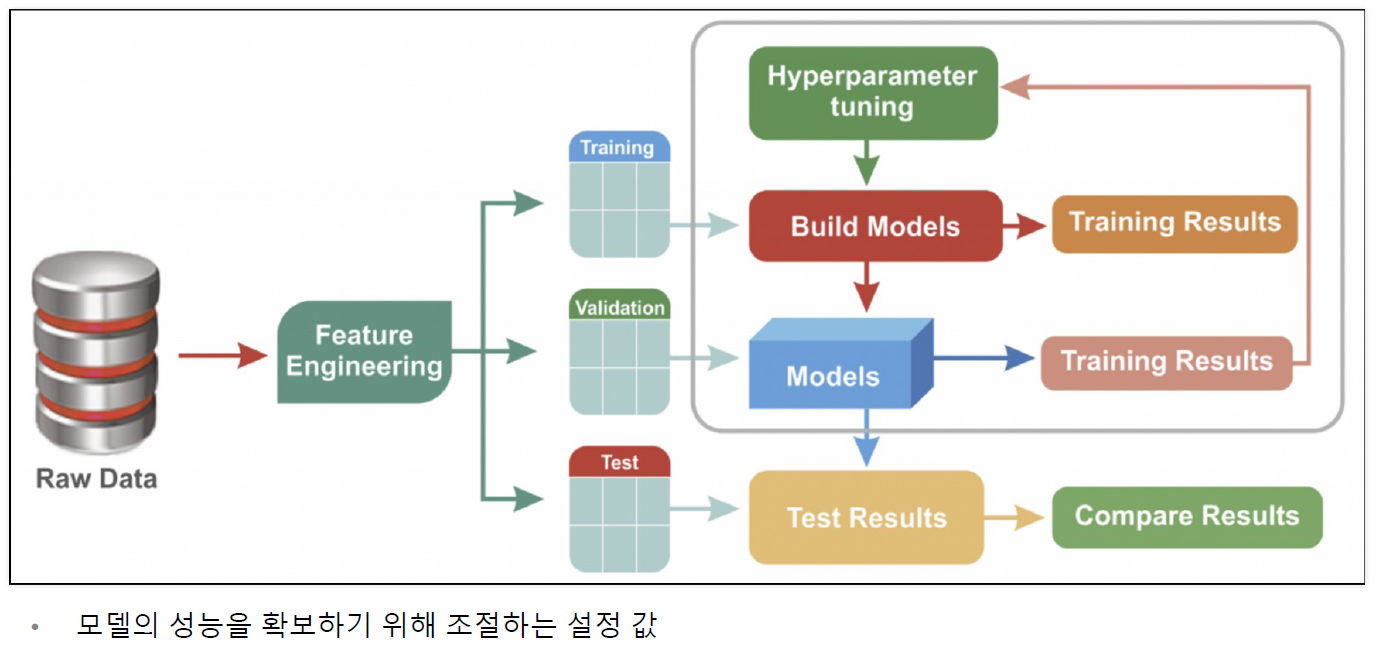
하이퍼파라미터 튜닝
- 학습 모델을 훈련 중인 경우, 각 데이터 세트와 모델에는 일종의 변수인 다양한 하이퍼파라미터 세트가 필요합니다.
- 이를 결정하는 유일한 방법은 여러 실험을 통해 하이퍼파라미터 세트를 선택하고 모델을 통해 실행하는 것
- 여기서 설정할 수 있는 값은 의사 결정 트리의 분기 수 (max_depth) 뿐이다
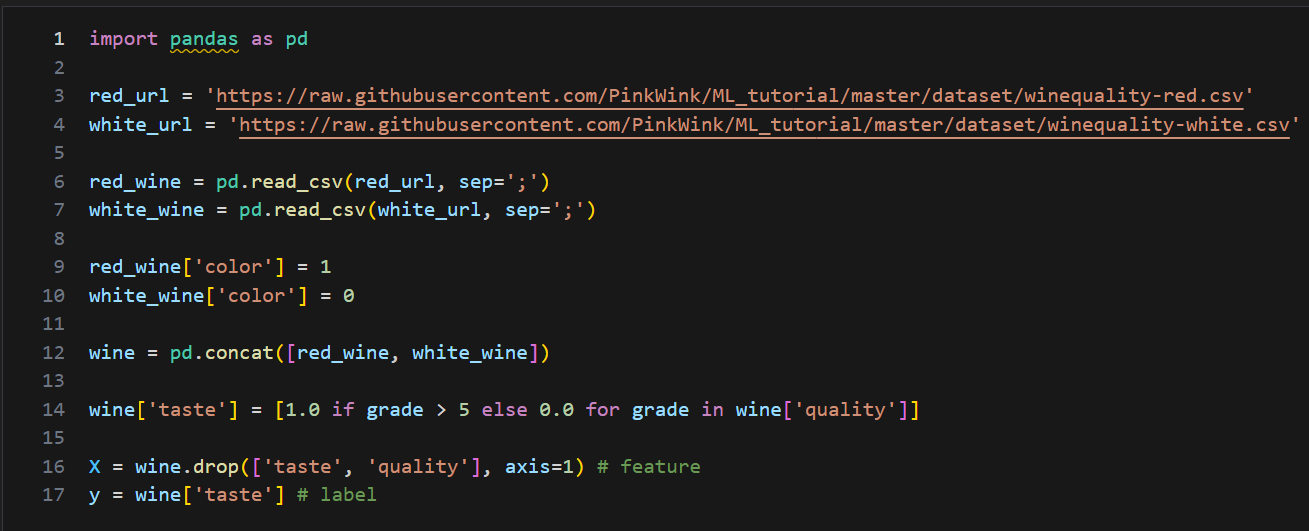
와인 데이터 불러오기
GridSearchCV : 하이퍼파라미터 목록과 성능 지표를 지정하면 알고리즘이 가능한 모든 조합을 통해 작동하여 가장 적합한 것을 결정
- estimator : 사용할 모델
- param_grid : 테스트 할 파라미터 집합, 딕셔너리 형태 ( key에 파라미터 이름, value에 값 ), 설정할(정의된) 하이퍼파라미터
- scroring : None이 default, 성능 평가를 어떤 기준으로 할 것인지? 사용하는 모델, 목표에 따라 다른 scoring method를 사용하면 됨.
- accuracy,roc_auc_score,average_precision 등을 사용할 수 있고 일반적으로 skitlearn에서 제공하는 accuracy를 사용하지만 별도의 함수도 직접 지정할 수 있다.
- n_jobs : 학습 시 사용할 CPU의 코어 개수, -1은 CPU의 코어 전부 사용
- refit : True가 default, estimator를 best 하이퍼파라미터로 재학습 시킬것인지?
- cv : None이 default, cross validation(교차검증)을 위해 분할되는 fold 수(데이터를 나눈 수)
- verbose : 0가 default, 큰 수를 입력할수록 print되는 내용이 더 많아짐
- returntrain_score : False면 cv_results가 training score 값을 갖고 있지 않음
from sklearn.model_selection import GridSearchCV
from sklearn.tree import DecisionTreeClassifier
params = {'max_depth' : [2, 4, 7, 10]} # 수정할 하이퍼파라미터 지정
wine_tree = DecisionTreeClassifier(max_depth=2, random_state=13)
gridsearch = GridSearchCV(estimator=wine_tree, param_grid=params, cv = 5)
gridsearch.fit(X, y)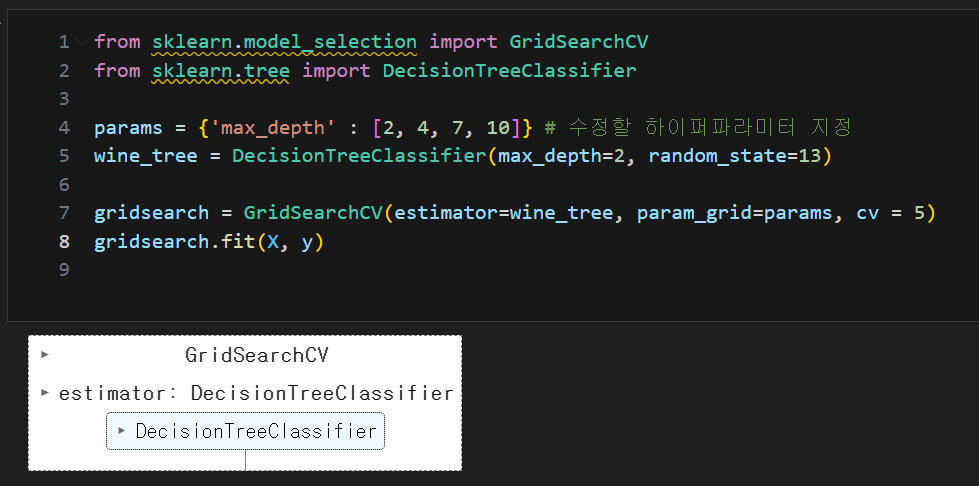
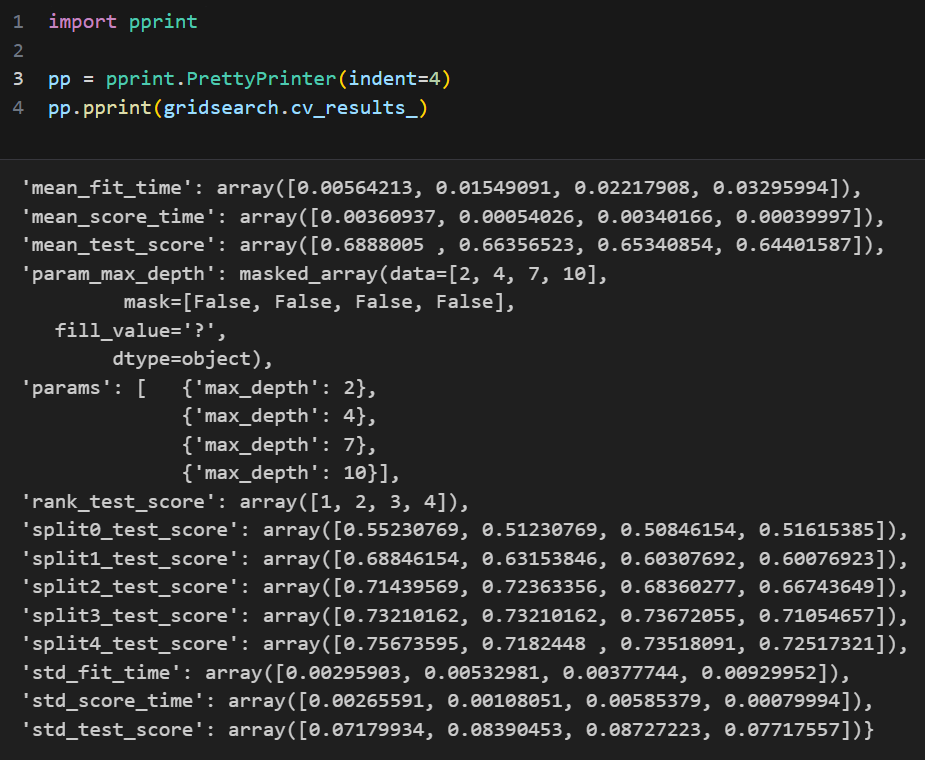
GridSearchCV 결과 확인 : pprint
- pprint.PrettyPrinter(indent = )
- indent = : 각 수준의 들여쓰기 칸 수
- gridsearch.cvresults
- .cvresults : gridsearch cv에 fit 시킨 결과 출력
from sklearn.model_selection import GridSearchCV
from sklearn.tree import DecisionTreeClassifier
params = {'max_depth' : [2, 4, 7, 10]} # 수정할 하이퍼파라미터 지정
wine_tree = DecisionTreeClassifier(max_depth=2, random_state=13)
gridsearch = GridSearchCV(estimator=wine_tree, param_grid=params, cv = 5)
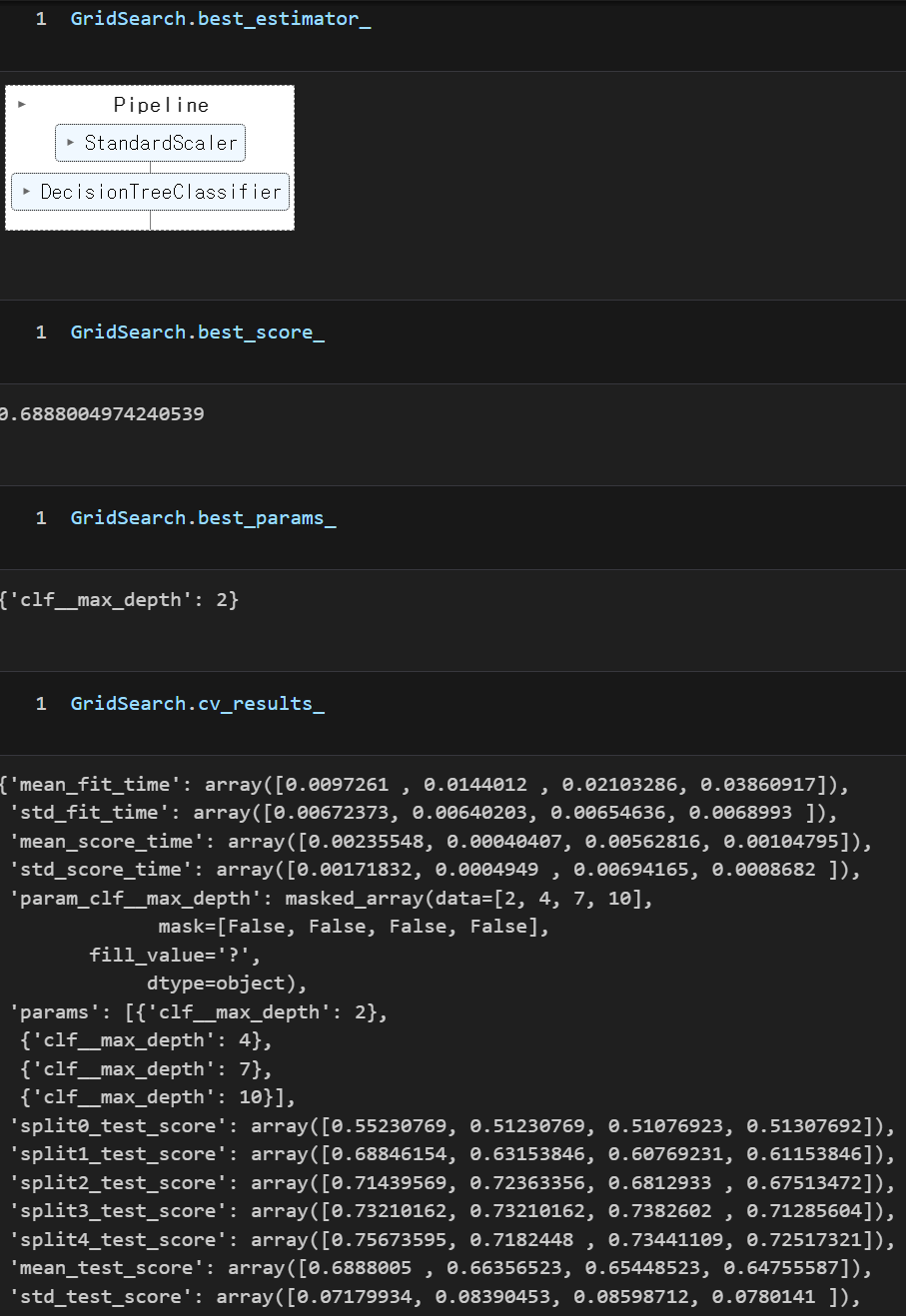
gridsearch.fit(X, y)- mean_fit_time: 각 매개변수 조합에 대한 평균 학습 시간
- mean_score_time: 각 매개변수 조합에 대한 평균 평가 시간
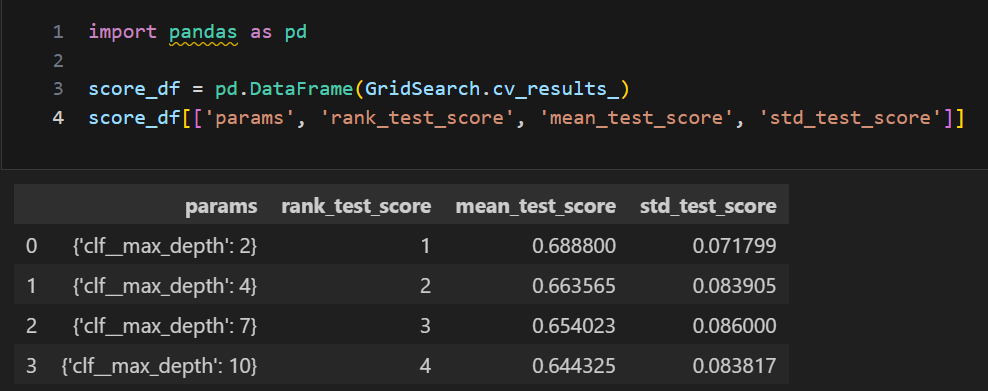
- mean_test_score: 각 매개변수 조합에 대한 평균 검증 성능 점수
- param_max_depth: 사용된 매개변수 중 'max_depth'의 값
- params: 사용된 모든 매개변수 조합
- rank_test_score: 평균 검증 성능 점수를 기준으로 한 순위
- split0_test_score부터 split4_test_score: 교차 검증의 각 폴드에 대한 테스트 성능 점수
- std_fit_time: 각 매개변수 조합에 대한 학습 시간의 표준 편차
- std_score_time: 각 매개변수 조합에 대한 평가 시간의 표준 편차
- std_test_score: 각 매개변수 조합에 대한 검증 성능 점수의 표준 편차
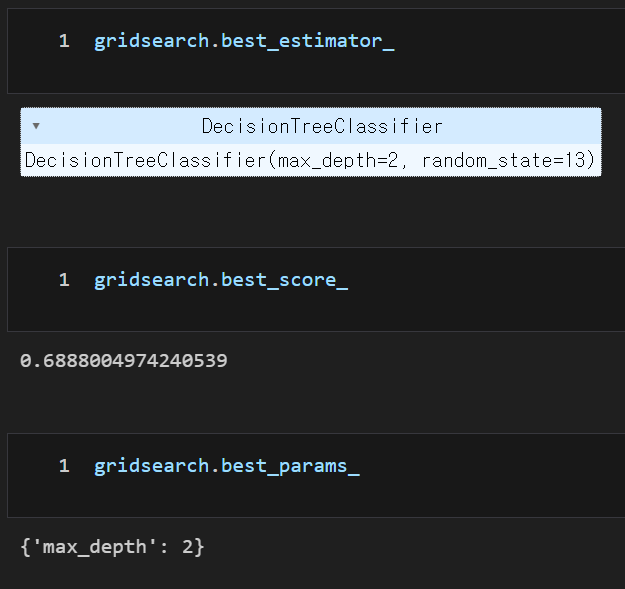
최고의 성능을 가진 모델, best_
- 가장 좋은 성능 모델 : .best_estimator__
- 가장 좋은 점수 : .best_score__
- 가장 좋은 하이퍼파라미터 : .best_params__
pipeline에 GridSearch 적용 : estimator=pipeline
from sklearn.pipeline import Pipeline
from sklearn.tree import DecisionTreeClassifier
from sklearn.preprocessing import StandardScaler
estimators = [
('scalar', StandardScaler()),
('clf', DecisionTreeClassifier())
]
pipe = Pipeline(estimators)
param_grid = [{'clf__max_depth': [2, 4, 7, 10]}]
# 딕셔너리 형태 {'스탭이름' + _ _(언더바 2개) + 하이퍼파라미터(=속성) : 설정)}
GridSearch = GridSearchCV(estimator=pipe, param_grid=param_grid, cv = 5)
GridSearch.fit(X, y)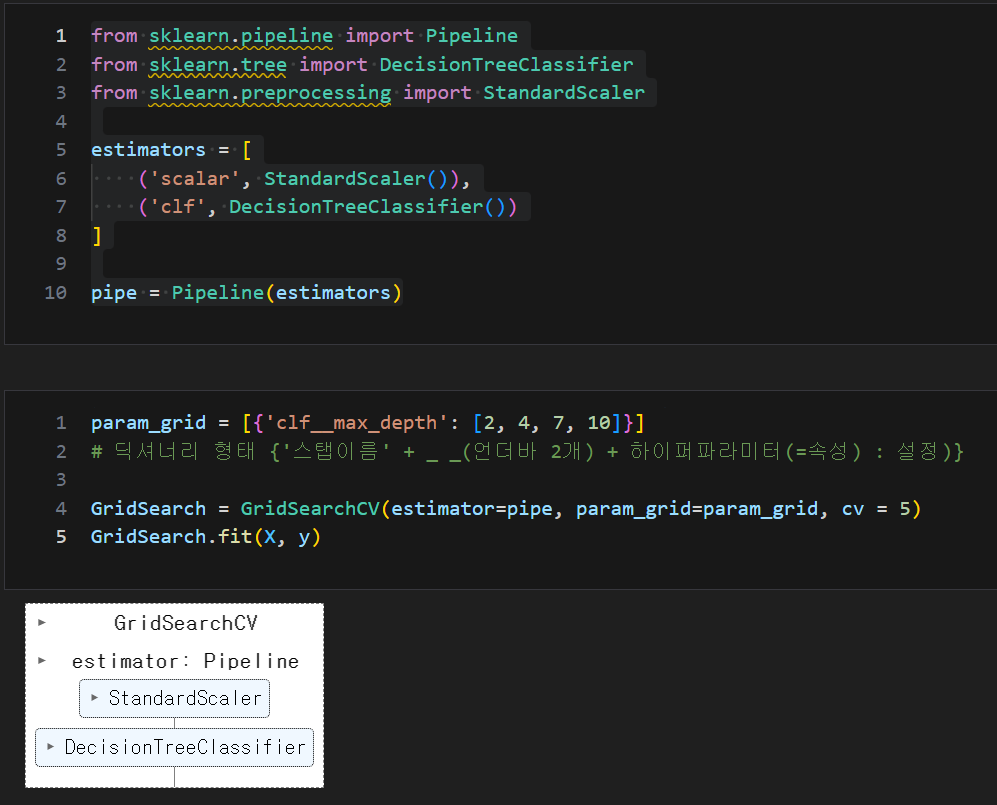
- 시각화
import matplotlib.pyplot as plt
from sklearn.tree import plot_tree
plt.figure(figsize=(8, 8))
feature_names_list= X.columns.tolist()
plot_tree(GridSearch.best_estimator_['clf'],
feature_names=feature_names_list,
rounded=True, filled=True)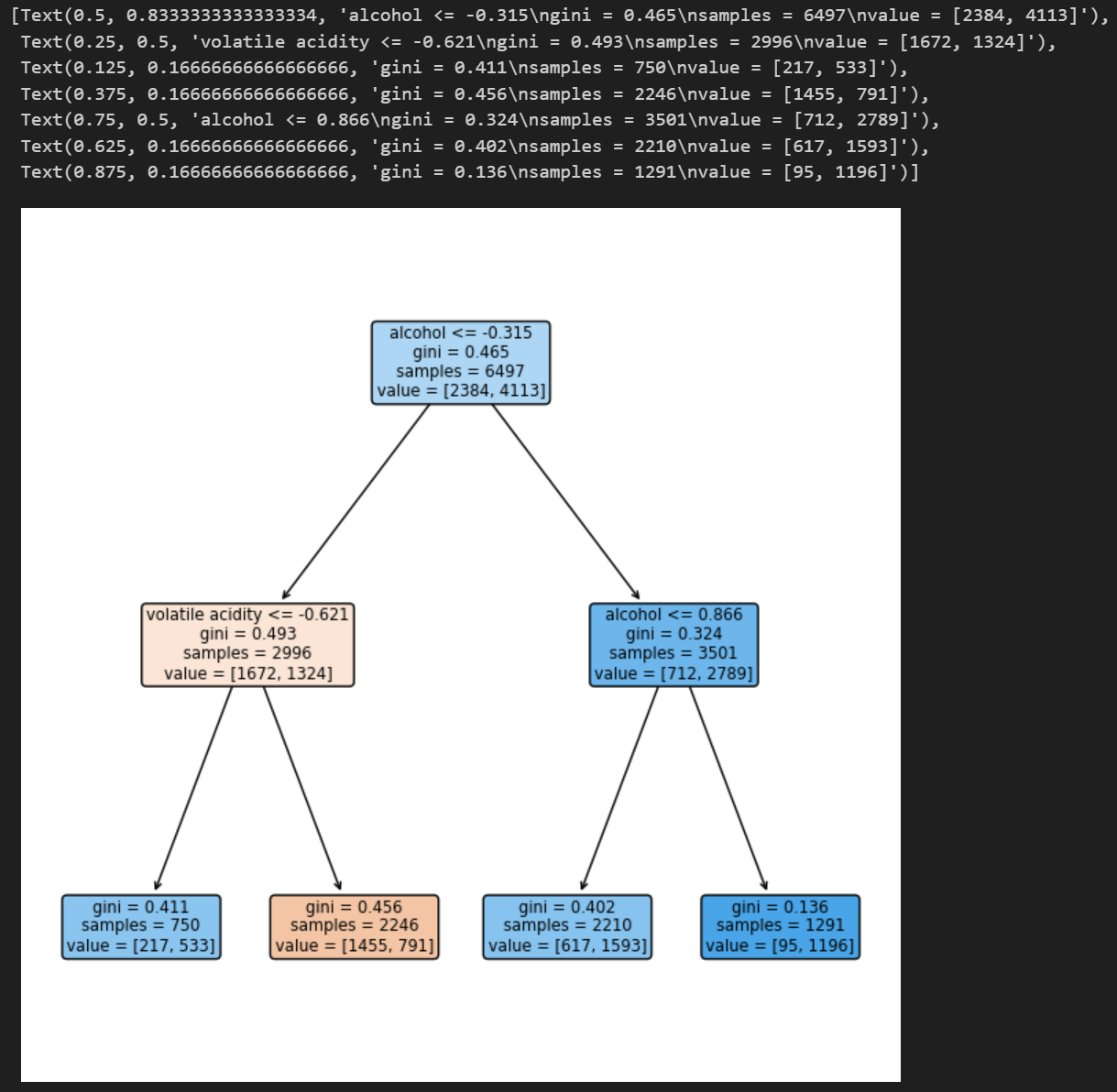

비전공 데이터 분석가 도전