ML
1.ML_iris
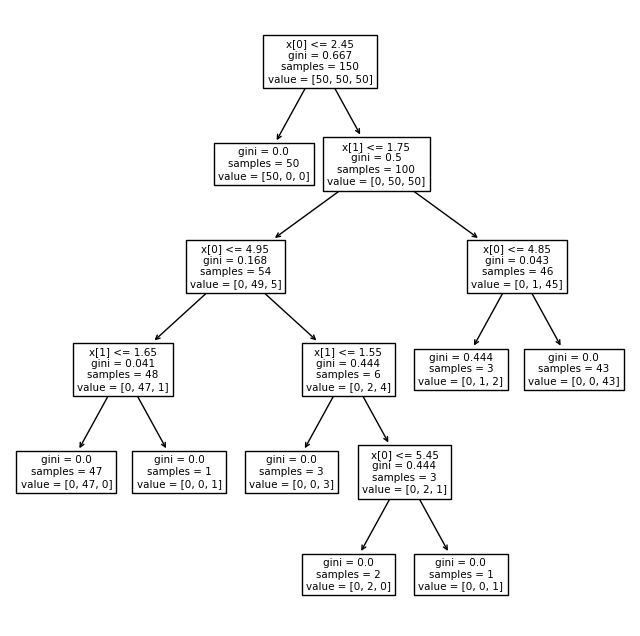
데이터 불러오기 sklearn dataset은 python dict 형과 유사 DataFrame 만들기 boxplot을 통하여 각 컬럼별 중복 구
2.ML_titanic
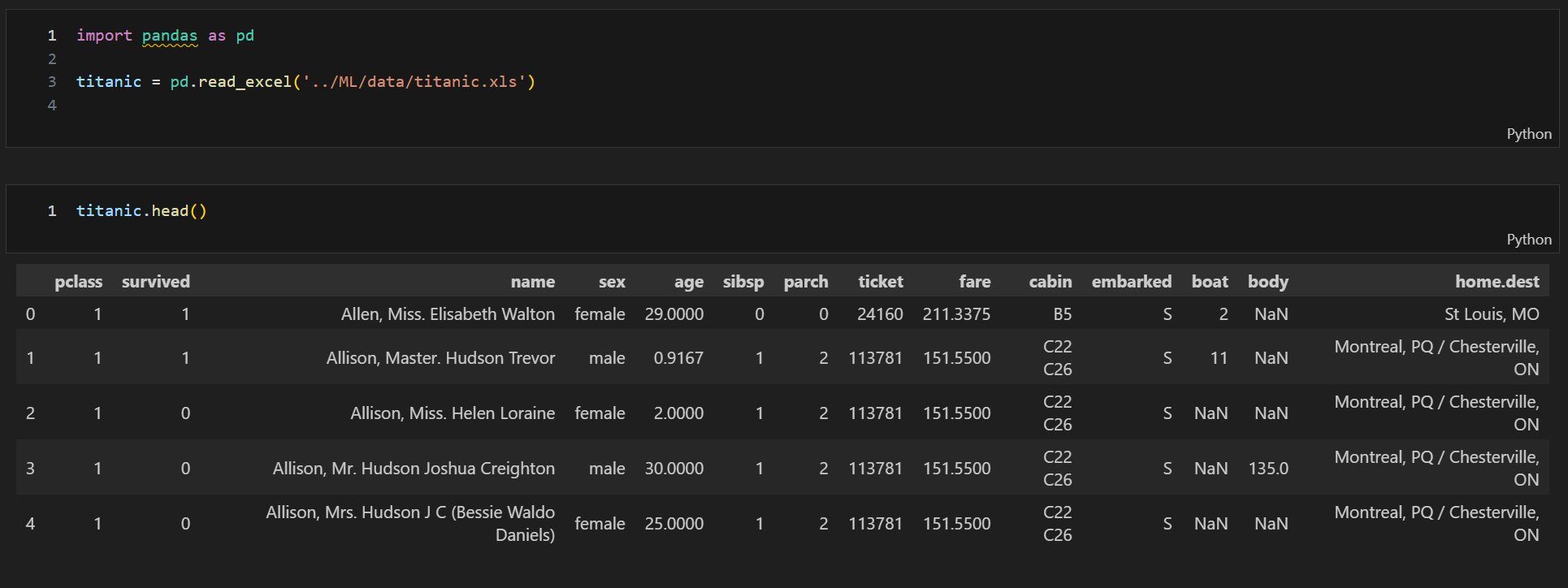
생존률과 생존자 시각화성별에 따른 생존 상황 확인 \- 그래프 확인 시 남성의 생존 가능성이 더 낮다경제력 대비 생존율 확인 및 선실 등급별 성별 시각화3등실에 20대 남성이 많다나이별 승객 현황 \-아이들과 20~30대가 많다등실별 생존률에 따른 연령 분포 \-
3.ML_label_encoder, min-max_scaling, standard_scaler, robust_scaler
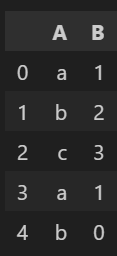
label_encoder
4.ML_wine
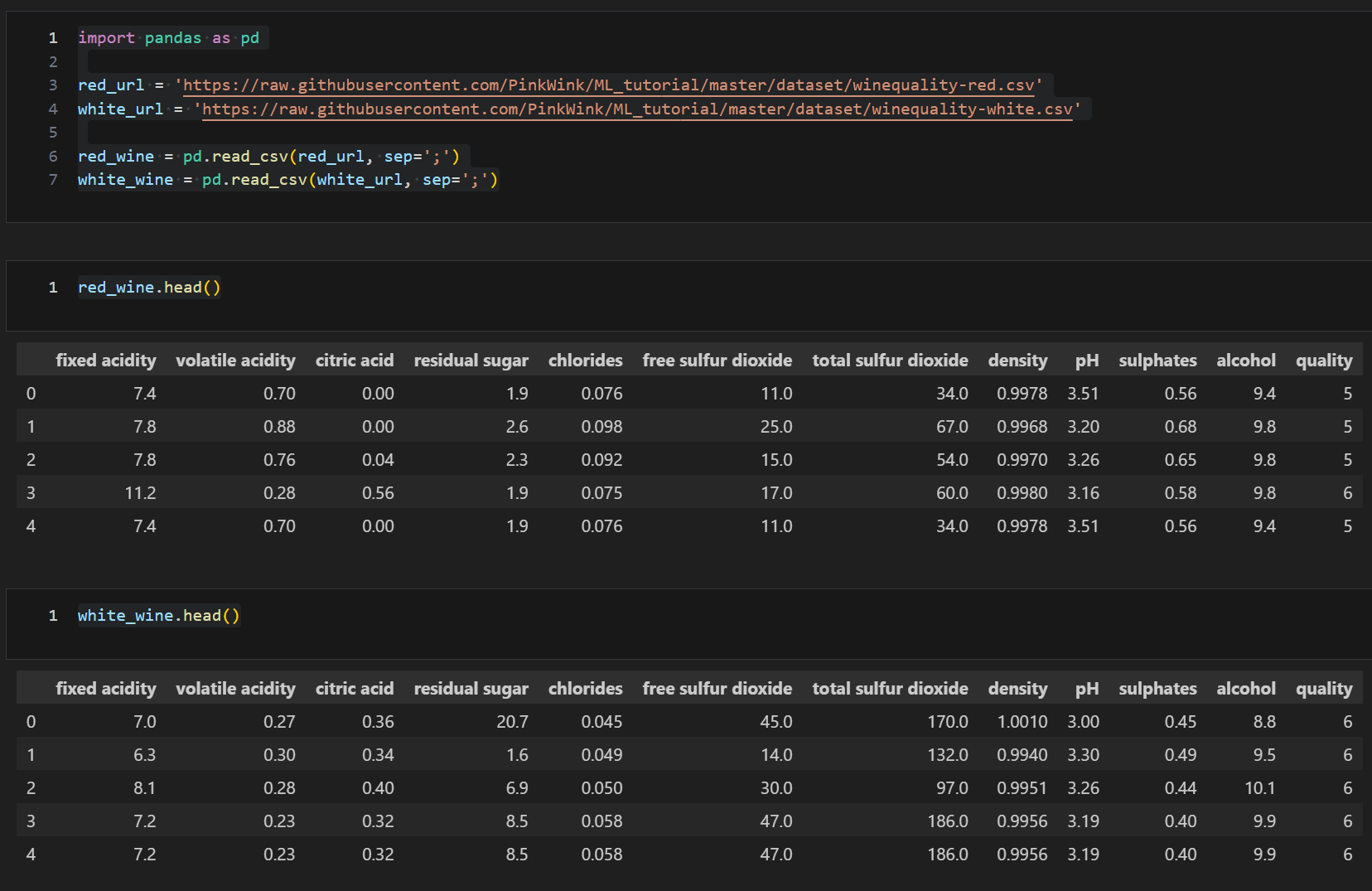
데이터 불러오기 및 합치기
5.ML_pipeline
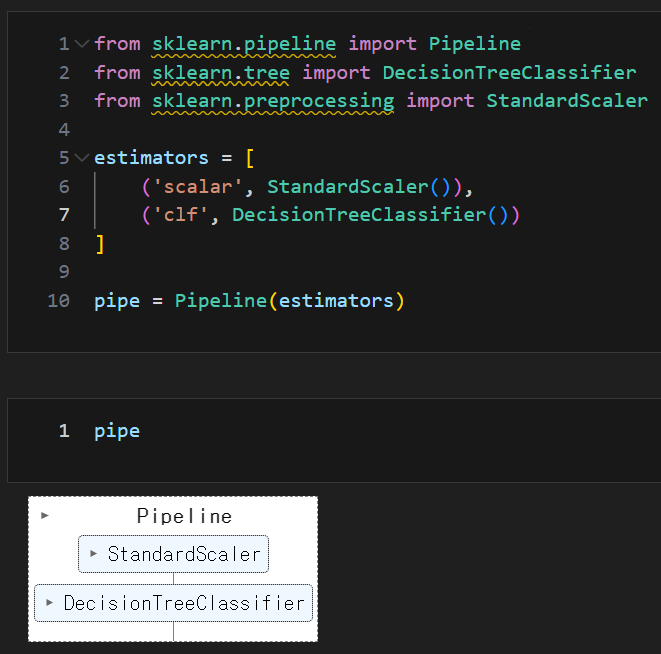
코드를 하나씩 실행해보면서 머신러닝을 진행하다보면 혼돈이 발생할 수 있다데이터의 전처리와 여러 알고리즘의 반복 실행, 하이퍼 파라미터의 튜닝 과정을 번갈아 하다보면코드의 싱행 순성에 혼선 발생 가능상기 사항들을 극복하기 위하여 한 과정에 처리하는 sklearn의 Pip
6.ML_cross_validation
교차검증
7.ML_Hyperparameter_Tuning
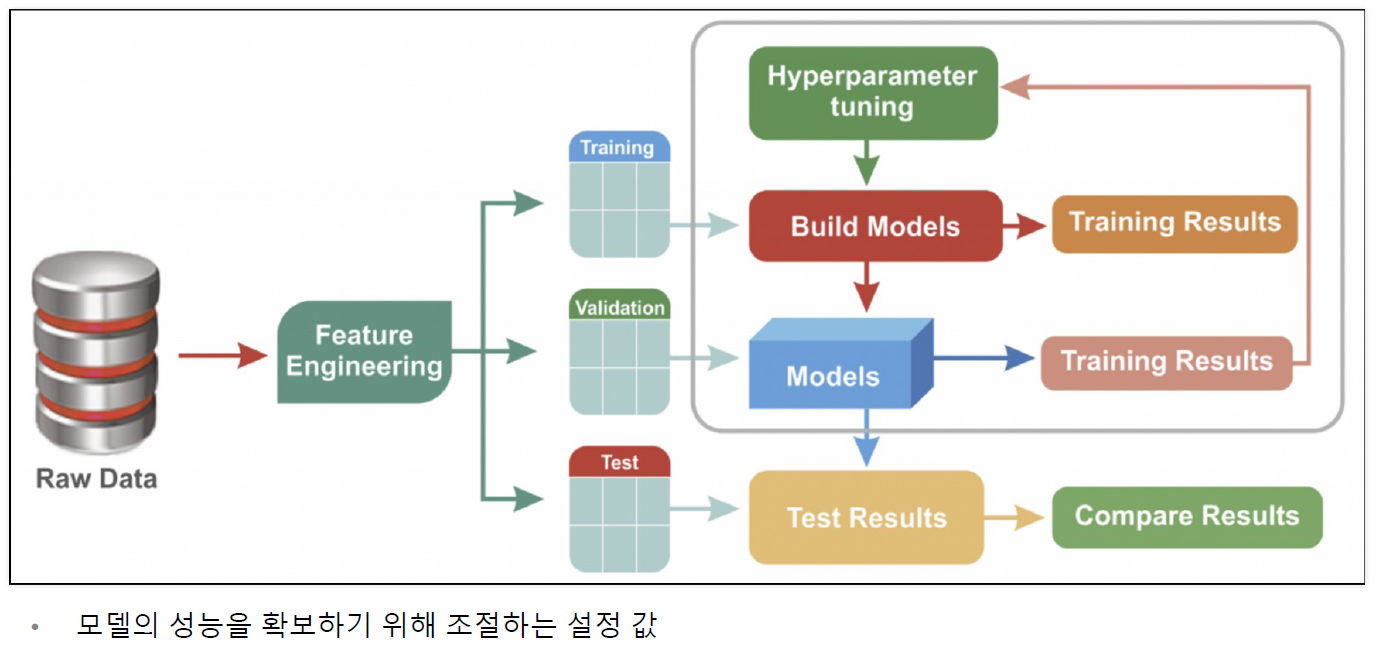
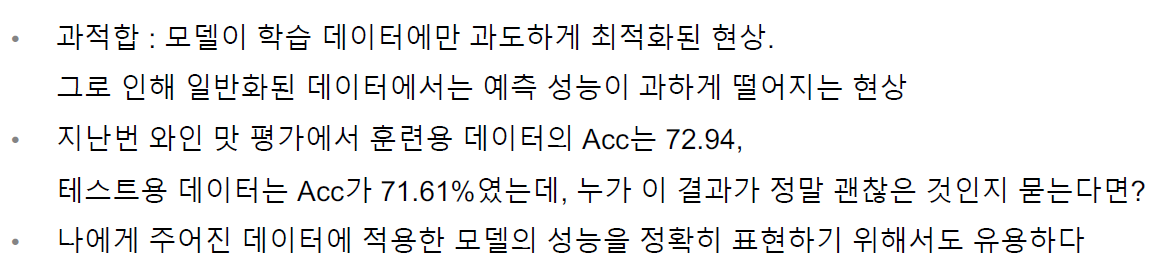
학습 모델을 훈련 중인 경우, 각 데이터 세트와 모델에는 일종의 변수인 다양한 하이퍼파라미터 세트가 필요합니다. 이를 결정하는 유일한 방법은 여러 실험을 통해 하이퍼파라미터 세트를 선택하고 모델을 통해 실행하는 것여기서 설정할 수 있는 값은 의사 결정 트리의 분기 수
8.ML_모델평가

회귀모델들은 실제 값과의 에러치를 가지고 계산 분류 모델은 평가 항목이 많다 이진 분류 모델의 평가 참/거짓을 찾는 과정에서 답은 2가지지만 예측 결과는 4가지로 나온다 Accuracy 
lm = linear regressisonstatsmodels.formula.api 의 ols(Ordinary Least Squares, 선형회기분석) 기법 사용formula = 'y~x' : y = ax + b라는 의미를 내포하고 있음fit() : 훈련해라Interc
10.ML_cost_function, Gradient Descent, linear_regressin
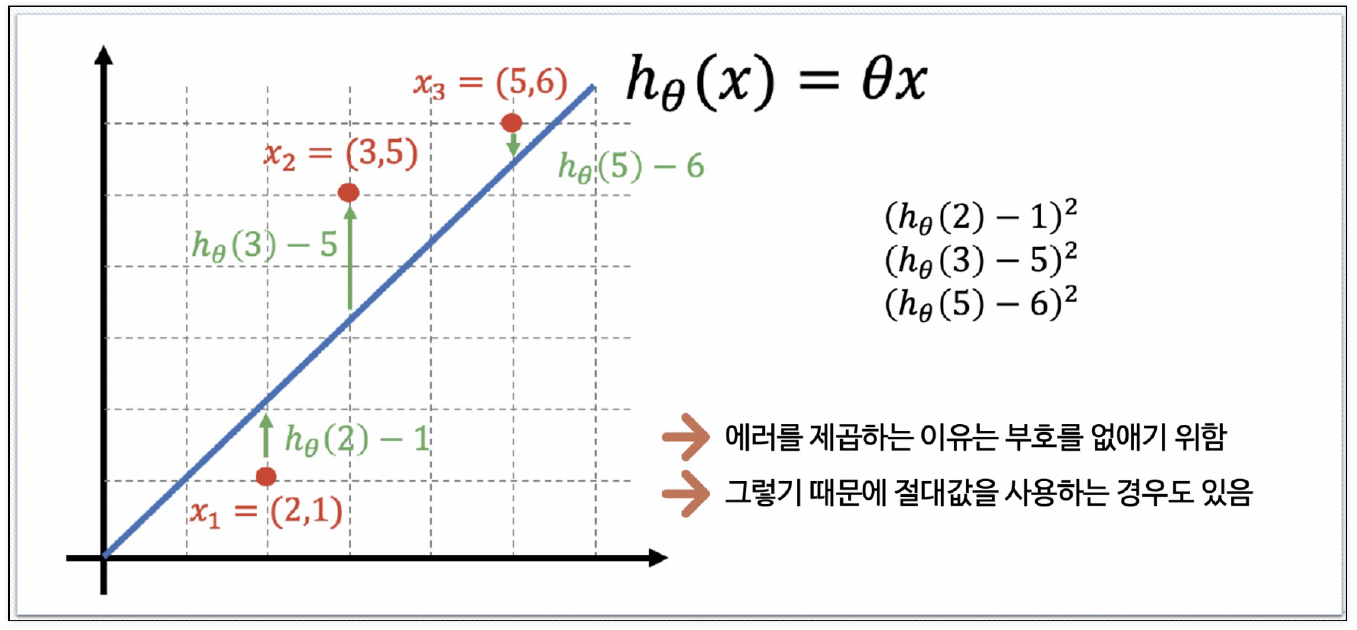
stats_regression : 통계적 회귀
11.ML_logistic_regressin

Linear Regression의 예측을 사용하는 것은 참/거짓과 같은 분류 문제는 해결하기 어렵다분류 문제에 사용되는 모델로 종속 변수가 범주형이고 이진 레이블(0 또는 1, 참/거짓)을 예측하는 데 사용logistic_regressin에서 '시그모이드(Sigmoid
12.ML_Ensemble
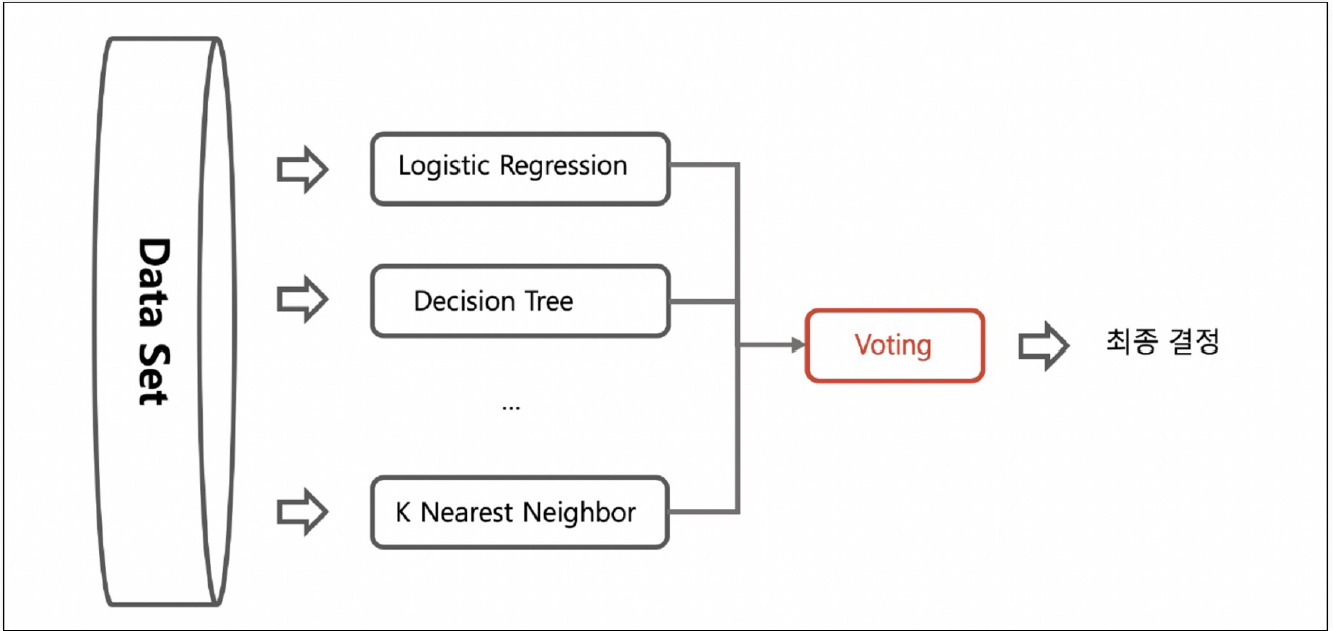
여러 개의 분류기를 생성하고 그 예측을 결합함으로써 보다 정확한 예측을 도출하는 기법강력한 하나의 모델을 사용하는 대신, 보다 약한 모델 여러 개를 조합하여 더 정확한 예측에 도움을 주는 방식여러 개의 동일한 모델을 병렬적으로 학습시켜 결과를 결합하는 방식각 모델은 원
13.ML_Boosting_Algoriyhm
Adaboost는 Decision Tree 기반의 알고리즘step1 : 순차적으로 가중치를 부여해서 최정 결과를 얻음step2 : step1에서 틀린 +에 가중치를 인가하고 경계 재결정step3 : step2에서 틀린 -에 가중치를 인가하고 경계 재결정step4 : 앞
14.ML_GBM, XGBoost, LightGBM
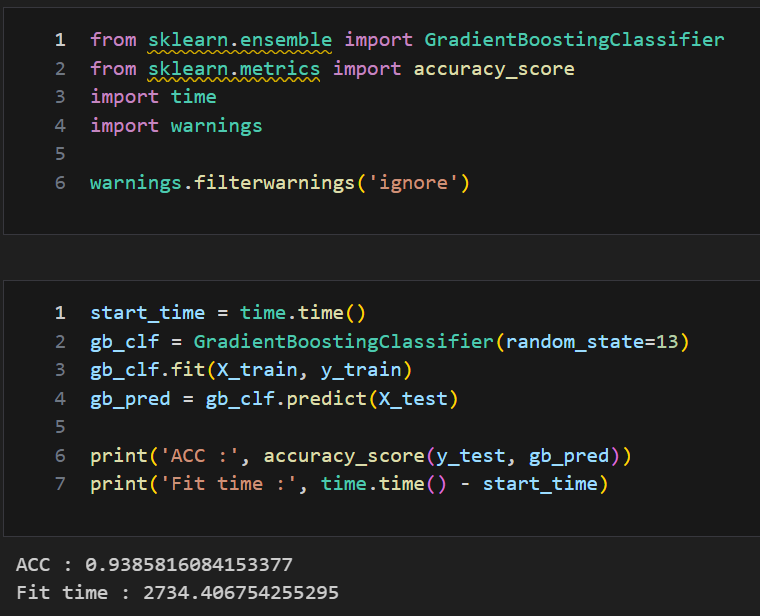
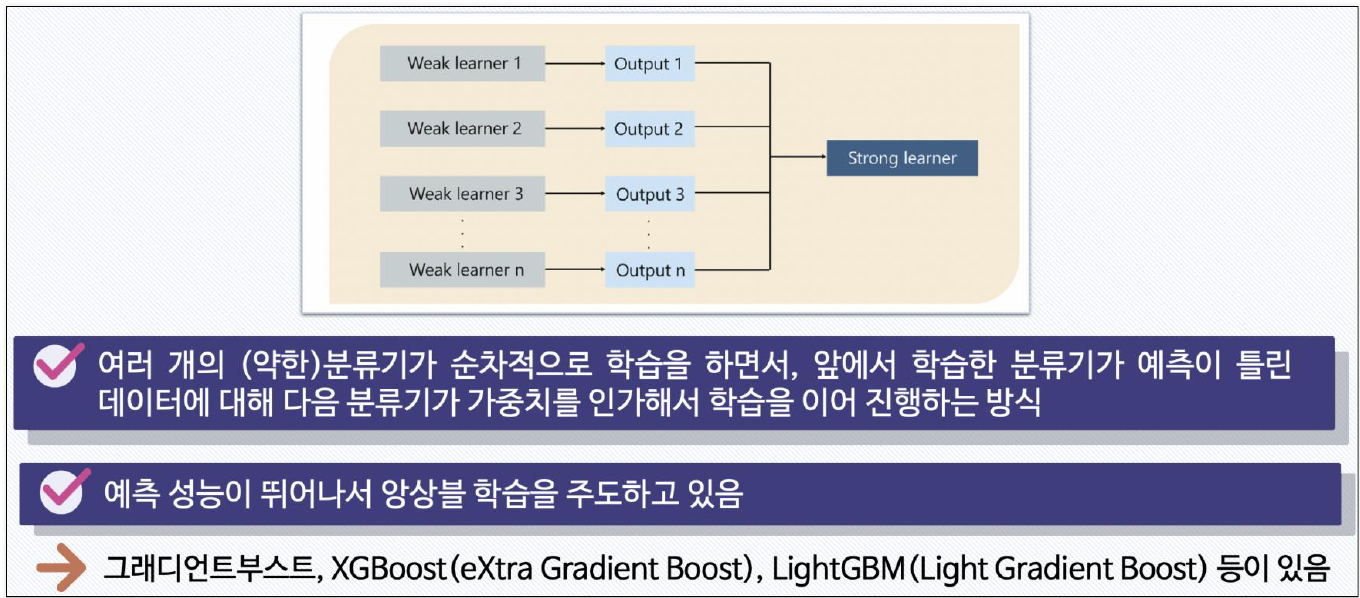
git : https://github.com/bbangcha/ML/blob/main/23.%20ML_GBM%2C%20XGBoost%2C%20LGBM.ipynb부스팅 알고리즘은 여러 개의 약한 학습기(week learner)를 순차적으로 학습-예측하면서잘못 예측