[논문 정리] Visual Instruction Tuning
Abstract
Instruction-following 데이터를 사용하여 LLM을 instruction tuning하는 것은 새로운 작업에 대한 zero-shot 성능을 향상.
텍스트 전용인 GPT-4를 사용하여 멀티모달 언어-이미지 struction-following 데이터를 생성하여 instruction tuning을 진행.
범용 비전 및 언어 이해를 위해 비전 인코더와 LLM을 연결하는,
종단간 학습된 대규모 멀티모달 모델인 LLaVA: Large Language and Vision Assistant.
두 가지 평가 벤치마크 구축.
실험 결과, LLaVA는 멀티모달 채팅 능력이 획기적, 때로는 처음 보는 이미지나 지시에 대해 멀티모달 GPT-4와 행동이 유사.
또한, 합성된 멀티모달 instruction-following 데이터셋에서 GPT-4 대비 85.1%의 상대적 점수를 기록.
Science QA 데이터셋에서 fine-tuning했을 때, LLaVA와 GPT-4의 시너지는 92.53%라는 SOTA 정확도를 달성.
Instruction-following: 명령어를 그대로 따르는 특성
Instruction Tuning: Instruction 데이터셋을 통해 LLM 모델 fine-tuning을 진행하고 이를 통해 zero-shot 성능을 높이는 방법
Introduction
인공지능의 목표 중 하나는 다양한 실제 작업을 제약 없는 환경에서 수행하기 위해 인간의 의도에 맞춰진 멀티모달 비전-언어 지시를 효과적으로 따를 수 있는 범용 어시스턴트를 개발하는 것.
따라서 분류, 탐지, 분할, 캡셔닝과 같은 개방형 비전 이해에 강력한 기능을 가진 언어 증강 기반 비전 모델, 비전 생성 및 편집 기술 개발에 대한 관심이 급증.
하지만 각 작업은 하나의 단일 대규모 비전 모델에 의해 독립적으로 해결되며, 작업 지시는 모델 설계에 암시적으로 포함.
더불어, 언어는 이미지 내용을 설명하는 데만 사용.
-> 일반 의사소통처럼 언어가 시각 신호를 언어 의미론(language semantics)으로 매핑하는 데 중요한 역할을 할 수 있게 하지만
일반적으로 고정된 인터페이스를 가지며 사용자의 지시(instruction)에 대한 상호작용성과 적응성이 제한적.
<-> 반면, LLM은 범용 어시스턴트를 위한 보편적 인터페이스.
다양한 태스크 지시가 명시적인 언어로 표현, 종단간 학습된 신경망 어시스턴트가 사용자가 원하는 특정 작업으로 전환하여 문제를 해결하도록 유도.
LLaMA는 GPT-3의 성능에 필적.
본 논문에서는 범용 비전 어시스턴트 구축을 위해
instruction-tuning을 언어-이미지 멀티모달 공간으로 확장하려는 첫 번째 시도인
시각 지시 조정(Visual Instruction-tuning)을 제시.
- 멀티모달 명령어 수행 데이터
비전-언어 명령어 수행 데이터의 부족을 해결하기 위해,
ChatGPT/GPT-4를 사용하여 이미지-텍스트 쌍을 적절한 명령어 수행 형식으로 변환하기 위한 데이터 재형성 관점과 파이프라인을 제시 - 대규모 멀티모달 모델
CLIP의 개방형 시각 인코더와 Vicuna의 언어 디코더를 연결, LMM(Large Multimodal models)을 개발하고 생성된 지시적(instructional) 비전-언어 데이터에 대해 종단간 미세 조정.
LMM 명령어 튜닝에 생성된 데이터의 효과를 검증하고 범용 명령어 수행 시각 에이전트 구축.
GPT-4와 앙상블될 때, Science QA 멀티모달 추론 데이터셋에서 SoTA. - 멀티모달 명령어 수행 벤치마크
다양한 이미지, 명령어 및 상세 주석이 포함된 두 벤치마크를 갖춘 LLaVA-Bench. - 오픈 소스
생성된 멀티모달 명령어 데이터, 코드베이스, 모델 체크포인트 및 시각 채팅 데모를 공개.
의미론: 의미론은 요소가 특정 위치에 있거나 특정 구조를 띌 때 어떤 의미를 갖냐를 의미.
GPT-assisted Visual Instruction Data Generation
멀티모달 instruction-follwing 데이터에서 인간이 직접 분류한 데이터를 사용하려면 데이터 생성 과정이 시간이 많이 소요되고 덜 명확.
따라서 데이터 수집을 위해 ChatGPT/GPT-4를 활용.
이미지-텍스트 쌍을 instruction-follwing에 적용하기 위해
Human : Xq Xv<스톱> Assistant : Xc<스톱> 활용.
-> 비용 저렴, 하지만 지시와 응답 모두에서 다양성과 심층적 추론 부족.
-> 시각적 콘텐츠를 포함하는 instruction-follwing 데이터를 생성하기 위해
언어 전용 GPT-4 또는 ChatGPT를 교사로 활용
텍스트 전용 GPT에 프롬프트를 제공하기 위해 이미지를 시각적 특징으로 인코딩하기 위해 두 가지 유형의 기호 표현을 사용, 기호 표현을 통해 이미지를 LLM이 인식할 수 있는 시퀀스로 인코딩.
-> 세 가지 유형의 지시 따르기 데이터를 생성
프롬프트 작성법:
- 대화
사진에 대해 질문하는 사람과 어시스턴트 간의 대화를 설계.
답변은 어시스턴트가 이미지를 보고 질문에 답하는 것처럼 톤을 유지. - 상세 설명
이미지에 풍부하고 포괄적인 설명을 내포하기 위해 의도가 설정된 질문 목록을 제작.
각 이미지에 대해 목록에서 질문 하나를 무작위로 샘플링하여 GPT-4가 상세 설명을 생성하도록 요청. - 복잡한 추론
앞서 언급된 두 가지 유형을 기반으로 심층 추론 질문을 추가로 생성.
답변은 엄격한 논리를 따르는 단계별 추론 과정을 요구.
대화 58K개 + 상세 설명 23K개 +복잡한 추론 77K개 => 총 158K개의 언어-이미지 instruction-follwing 샘플 수집.
GPT-4가 더 높은 품질의 instruction-follwing 데이터를 일관되게 제공.
Visual Instruction Tuning
4.1 Architecture
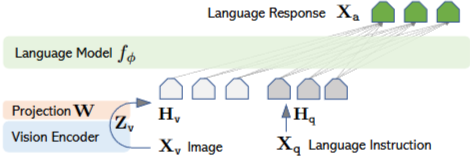
입력 이미지 에 대해, pre-trained CLIP 비전 인코더인 ViT-L/14를 사용하여 시각적 특징 를 얻음.
실험에서는 마지막 트랜스포머 레이어 이전과 이후의 그리드 특징을 모두 고려.
이미지 특징을 단어 임베딩 공간으로 연결하기 위해 단순한 선형 레이어를 사용.
구체적으로, 학습 가능한 프로젝션 행렬 를 적용하여 를 언어 모델의 단어 임베딩 공간과 동일한 차원을 갖는 언어 임베딩 토큰 로 변환.
시각적 토큰 의 시퀀스를 가짐.
경량화되어 있어 실험을 빠르게 반복 가능.
4.2 Training
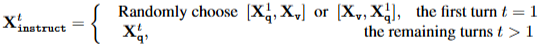
모델은 이미지() 하나에 대해 여러 번의 질문()과 답변()이 오가는 시퀀스를 학습.
첫 번째 턴 (): 질문()과 이미지()의 순서를 무작위로 배치하여 또는 형태로 입력.
이는 모델이 이미지와 텍스트의 선후 관계에 상관없이 정보를 처리.
이후 턴 (): 추가 질문()만 입력값으로.
오토레그레시브(Auto-regressive) 방식으로 다음 토큰을 예측하며, 오직 어시스턴트의 답변() 부분에서만 손실(Loss)을 계산.
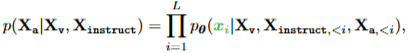
1단계: 특징 정렬을 위한 사전 학습
- 데이터: CC3M을 595K개의 이미지-텍스트 쌍으로 필터링. naive expansion 방법을 사용하여 instruction-following 데이터로 변환.
- 전략: 를 구성하기 위해 이미지 에 대해 질문 가 무작위로 샘플링 -> 이미지를 짧게 설명하도록 요청하는 언어 지시어로 만듦.
정답 예측 답변 는 원본 캡션. - 전략: 학습 시 시각 인코더와 LLM 가중치를 모두 고정(frozen).
학습 가능한 파라미터 (프로젝션 행렬)만을 사용하여 위 식의 likelihood를 극대화. - 이러한 방식으로 이미지 특징 를 사전 학습된 LLM 단어 임베딩과 정렬 -> 단어 토큰으로 보임.
동결된 LLM을 위한 호환 가능한 시각 토크나이저를 훈련하는 것으로 이해.
2단계: 종단 간 미세 조정
각 인코더 가중치는 항상 고정, LLaVA 내에서 프로젝션 레이어와 LLM의 사전 학습된 가중치를 모두 계속 업데이트.
즉, 학습 가능한 파라미터는 위 식에서 .
방법:
- 멀티모달 챗봇: 158K 언어-이미지 instruction-following 데이터에 대해 미세 조정을 수행하여 챗봇을 개발
- 과학 QA: ScienceQA 벤치마크.
각 질문에는 자연어 또는 이미지 형태의 맥락 제공.
어시스턴트는 자연어로 추론 과정을 제공하고 여러 선택지 중에서 답을 선택.
Experiments
멀티모달 챗봇과 ScienceQA 데이터셋을 사용하여 LLaVA의 instruction-following 및 시각적 추론 능력을 평가.
5.1 Multimodal Chatbot
LLaVA는 적은 수의 멀티모달 instruction-following 데이터셋(약 80K)으로 학습되었음에도 GPT-4와 상당히 유사.
LLaVA에게는 도메인 외이지만, 장면을 이해하고 질문 지시에 따라 합리적인 응답을 제공 가능.

Text-only GPT-4와 LLaVa로부터 응답을 얻고, 질문, 시각 정보(텍스트 설명 형식), 그리고 생성된 응답을 판정자(Text-only GPT-4)에게 전달한 결과.
벤치마크 1: LLaVA-Bench (COCO).
OCO-Val-2014에서 30개의 이미지를 무작위로 선택
각 이미지에 대해 Sec. 3에 제안된 데이터 생성 파이프라인을 사용하여 대화/상세 설명/복잡한 추론 세 유형의 질문 총 90개의 생성.
- Instruction-tuning을 통해 instruction-following 모델의 능력이 50점 이상 향상.
- 소량의 상세 설명 및 복잡한 추론 질문을 추가하면 모델의 전반적인 기능이 7점 향상. 추론 능력의 향상이 대화 능력을 보완.
- 세 가지 유형의 데이터를 모두 사용하는 것이 85.1%로 최고 성능
벤치마크 2: LLaVA-Bench (In-the-Wild).
어려운 작업과 새로운 도메인에 대한 일반화 가능성을 평가.
- LLaVA는 BLIP-2 (+29%) 및 OpenFlamingo (+48%)에 비해 훨씬 더 나은 성능
- 텍스트 전용 GPT-4와 비교했을 때, LLaVA는 복잡한 추론 질문에서 인상적인 81.7%의 성능을 달성, 전반적인 점수는 67.3%
한계:

- 왼쪽의 경우,
식당 이름을 정확히 답하려면 모델이 광범위한 지식 범위와 다국어 이해 능력 필요,
반찬을 정확히 설명하려면 인터넷에서 관련 멀티모달 정보를 검색 - 오른쪽의 경우,
요구르트의 정확한 브랜드를 인식하려면 모델이 고해상도 이미지를 처리하고 광범위한 지식 범위를 보유 - 이미지 내의 복잡한 의미론을 파악하지 못함
5.2 ScienceQA
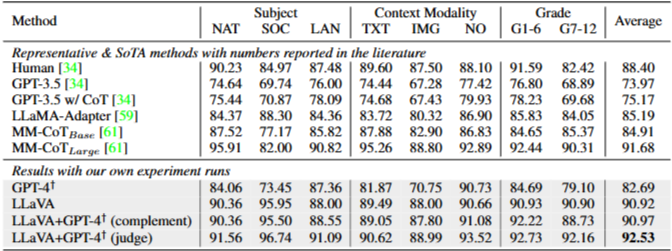
LLaVA의 경우, 마지막 레이어 이전의 시각적 특징을 사용, 모델이 먼저 이유를 예측한 다음 답변을 예측, 12 에포크 동안 훈련 -> 성능 SOTA와 근접.
shot in-context-learning을 사용하여 GPT-4에 프롬프트를 제공 -> 성능 향상.
앙상블:
(i) GPT-4 보완.
GPT-4가 답변을 제공하지 못할 때마다, 우리 방법론의 예측을 사용-> 우리 방법론만을 적용했을 때와 동일한 정확도
(ii) GPT-4를 판사로
GPT-4와 LLaVA가 다른 답변을 생성할 때마다
질문과 두 가지 결과를 바탕으로 GPT-4에게 자체 최종 답변을 제공하도록 프롬프트 제공 -> 높은 SoTA 정확도 갱신
Conclusion
본 논문은 시각 instruction tuning의 효과를 입증.
언어-이미지 instruction-following 데이터를 생성하기 위한 자동화된 파이프라인을 제시, 이를 기반으로 인간의 의도를 따라 시각적 작업을 완료하는 다중 모달 모델인 LLaVA를 훈련.
이 모델은 ScienceQA에서 미세 조정될 때 새로운 SoTA 정확도를 달성, 다중 모달 채팅 데이터에서 미세 조정될 때 뛰어난 시각적 채팅 기능을 제공.
또한, 다중 모달 struction-following 능력을 연구하기 위한 최초의 벤치마크를 제시.
본 논문은 시각 instruction tuning의 초기 단계이며 주로 실용적 태스크에 초점.
Related Work
멀티모달 instruction-following 에이전트:
i) 각 특정 연구 주제에 대해 개별적으로 탐색되는 종단간(end-to-end) 학습 모델
ii) 다양한 모델이 협업하게끔 조정하는 시스템
Instruction Tuning:
기존 모델들은 이미지-텍스트 쌍으로 학습되었을 뿐, 시각-언어 instruction data로 명시적 튜닝을 거치지 않음.
이 때문에 텍스트 전용 모델들에 비해 멀티모달 작업에서의 상호작용 능력이나 복잡한 지시 이행 능력이 상대적으로 떨어짐.
-> 시각 instruction tuning을 연구.
종단간 학습으로 여러 태스크를 처리할 수 있는 멀티모달 모델을 추구.
REFERENCES
Instruction-following:
https://co-no.tistory.com/entry/%EA%B0%9C%EB%85%90-%ED%94%84%EB%A1%AC%ED%94%84%ED%8A%B8-%EC%97%94%EC%A7%80%EB%8B%88%EC%96%B4%EB%A7%81%EC%9D%98-%EA%B0%9C%EB%85%90%EA%B3%BC-LLM-%ED%99%9C%EC%9A%A9-%EC%8B%9C-%EA%BF%80%ED%8C%81
Instruction Tuning:
https://velog.io/@nellcome/Instruction-Tuning%EC%9D%B4%EB%9E%80
