이 글에서 다룰 데이터 정보는 다음과 같습니다.
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 3650 entries, 0 to 3649
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Date 3650 non-null object
1 Temp 3650 non-null float64
dtypes: float64(1), object(1)
memory usage: 57.2+ KB날짜 데이터
날짜 데이터는 특정 시점을 표현하거나 저장하는 데 사용되는 데이터 타입입니다. 날짜 데이터를 출력하고 저장하는 방법에 대해 이 글에서 자세히 살펴보겠습니다.
문자형을 날짜형으로 변경
위 데이터를 보면 Date 에 들어온 데이터는 object 형태로 저장되어 있습니다. 여기서 object 는 문자열 데이터입니다. 이 데이터를 날짜형으로 변경하려면 다음과 같은 메소드를 사용하면 됩니다.
pd.to_datetime('column_name', format='날짜 형식')여기서 날짜 형식 포멧은 다음과 같습니다.
| 형식 | 설명 |
|---|---|
| %Y | 0을 채운 4자리 연도 |
| %y | 0을 채운 2자리 연도 |
| %m | 0을 채운 월 |
| %d | 0을 채운 일 |
| %H | 0을 채운 시간 |
| %M | 0을 채운 분 |
| %S | 0을 채운 초 |
위 코드를 사용한 예시는 다음과 같습니다.
df['Date1'] = pd.to_datetime(df['Date'], format='%Y-%m-%d')
df.info()위 코드는 Date 열의 데이터를 %Y-%m-%d 형식으로 변환하여, 변환된 값을 새로운 열인 Date1에 저장합니다.
df['column_name'].dt.strftime("format")
df['column_name'].dt.strftime("format") 은 날짜 데이터 형식을 자신이 원하는 format에 맞게 저장할 수 있는 메서드입니다. 여기서 column_name은 변환할 날짜 데이터를 포함한 열의 이름이며, format은 원하는 날짜 형식을 지정하는 문자열입니다."
df['Date1'].dt.strftime("%Y년 %m월")위 코드의 실행 결과는 다음과 같습니다.
0 1981년 01월
1 1981년 01월
2 1981년 01월
3 1981년 01월
4 1981년 01월
...
3645 1990년 12월
3646 1990년 12월
3647 1990년 12월
3648 1990년 12월
3649 1990년 12월
Name: Date1, Length: 3650, dtype: object날짜 계산
날짜 계산과 관련된 메서드는 다음과 같습니다.
- day 연산:
pd.Timedelta(day=숫자) - month 연산:
DateOffset(months=숫자) - year 연산:
DateOffset(years=숫자)
먼저 pd.Timedelta(day=숫자) 부터 알아보겠습니다.
df['plus day1'] = df['Date1'] + pd.Timedelta(days=1)
df.head()위 코드의 결과는 다음과 같습니다.
다음 DateOffset(months=숫자) 를 사용해보겠습니다.
from pandas.tseries.offsets import DateOffset
df['plus month1'] = df['Date1'] + DateOffset(months=1)
df.head()위 코드의 결과는 다음과 같습니다.
마지막으로 DateOffset(years=숫자)를 사용해보겠습니다.
df['plus year1'] = df['Date1'] + DateOffset(years=1)
df.head()위 코드의 결과는 다음과 같습니다.
날짜 구간 데이터 만들기
pd.date_range(start=시작일자, end=종료일자, periods=기간수, freq=주기)
| 형식 | 설명 |
|---|---|
| D | 일별 |
| W | 주별 |
| M | 월별 말일 |
| MS | 월별 시작일 |
| A | 연도별 말일 |
| AS | 연도별 시작일 |
날짜 구간 데이터는 특정 시작일과 종료일 사이에 일정한 간격으로 날짜를 생성해야 할 때 사용합니다. 아래는 이를 활용한 코드 예시입니다.
pd.date_range(start = '2024-01-01', end = "2035-12-15", freq = "A") 위 코드의 결과는 다음과 같습니다.
DatetimeIndex(['2024-12-31', '2025-12-31', '2026-12-31', '2027-12-31',
'2028-12-31', '2029-12-31', '2030-12-31', '2031-12-31',
'2032-12-31', '2033-12-31', '2034-12-31'],
dtype='datetime64[ns]', freq='A-DEC')rolling()
rolling 함수는 지정한 기간만큼의 데이터를 하나의 컨텍스트로 묶어 계산하거나 분석할 수 있도록 도와줍니다.
df["ma7"] = df['Temp'].rolling(7).mean()
df.head(20)위 코드의 출력 결과는 다음과 같습니다.
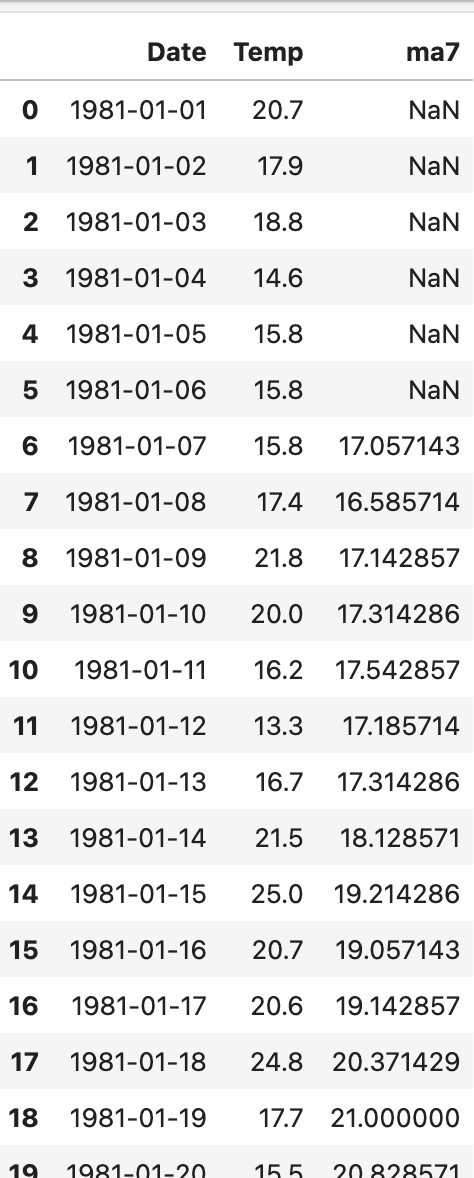
전의 데이터가 부족하면 NaN값을 출력합니다. 위 사진을 보면 0 ~ 5번까지는 데이터가 부족하여 NaN값을 출력하는 것을 볼 수 있습니다.
shift()
shift 함수는 행 데이터를 옮길 때 사용하는 함수입니다.
df['Time Shift1'] = df['Temp'].shift(1)
df.head() 위 코드를 실행한 결과는 다음과 같습니다.
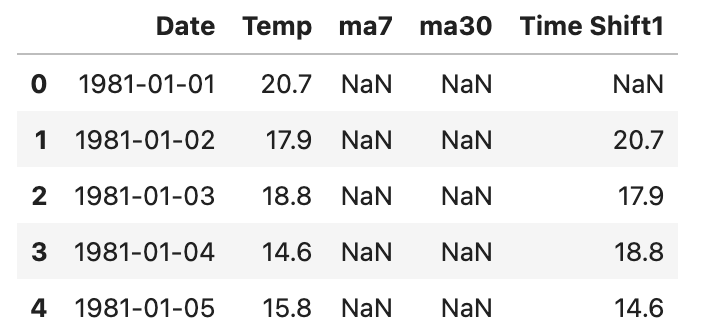
위 사진을 보시면 Temp Shift1은 Temp에서 하나씩 아래의 열로 이동되는 것을 볼 수 있습니다.
