이 글은 다음과 같은 데이터를 사용합니다.
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 714 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KB행의 추가
concat()함수는 데이터프레임이나 시리즈를 하나로 합치는 함수입니다.
sample_rows = df.loc[[3, 7, 100]]
sample_rows.index = ['추가1', '추가2', '추가3']
sample_rows
df1 = df.copy()
df2 = pd.concat((df1, sample_rows))
df2.tail()위 코드의 실행 결과는 다음과 같습니다.
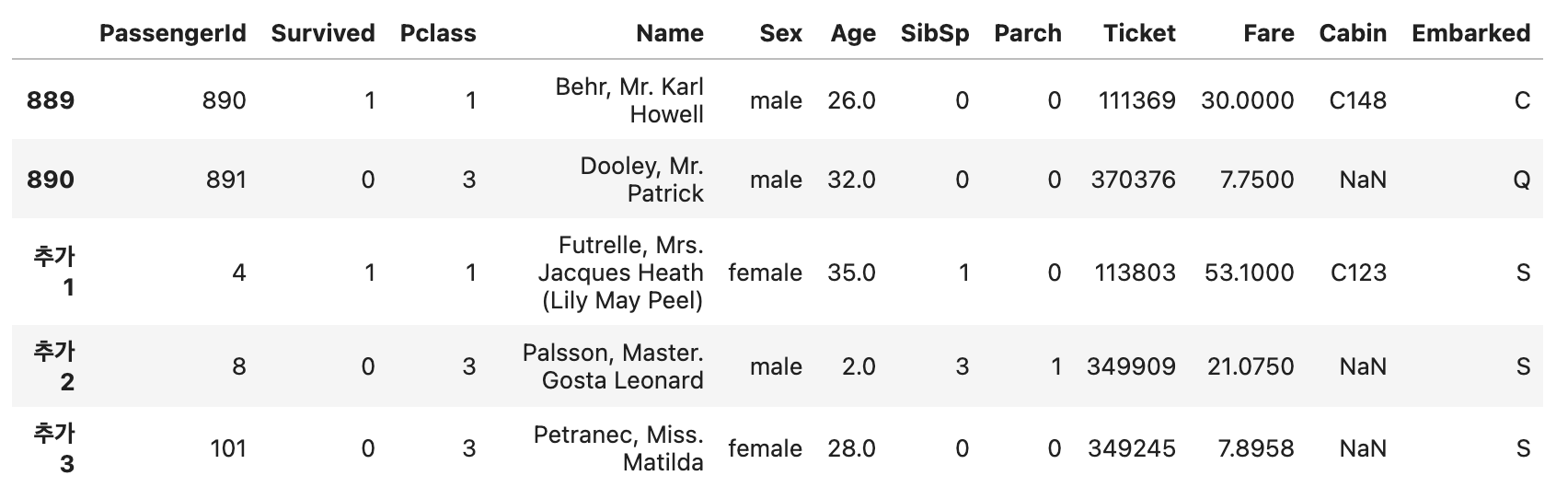
단 concat()을 사용할 땐 두 데이터프레임의 column 이름이 같아야 합니다. 만약 column 이름이 다르다면 새로운 column이 추가됩니다. 그리고 그 column의 값에는 NaN값이 채워집니다.
행 삭제
drop()은 데이터프레임에서 행이나 열 데이터를 지울 때 사용하는 함수입니다. 함수의 인수로는 제거할 행이나 열을 받습니다.
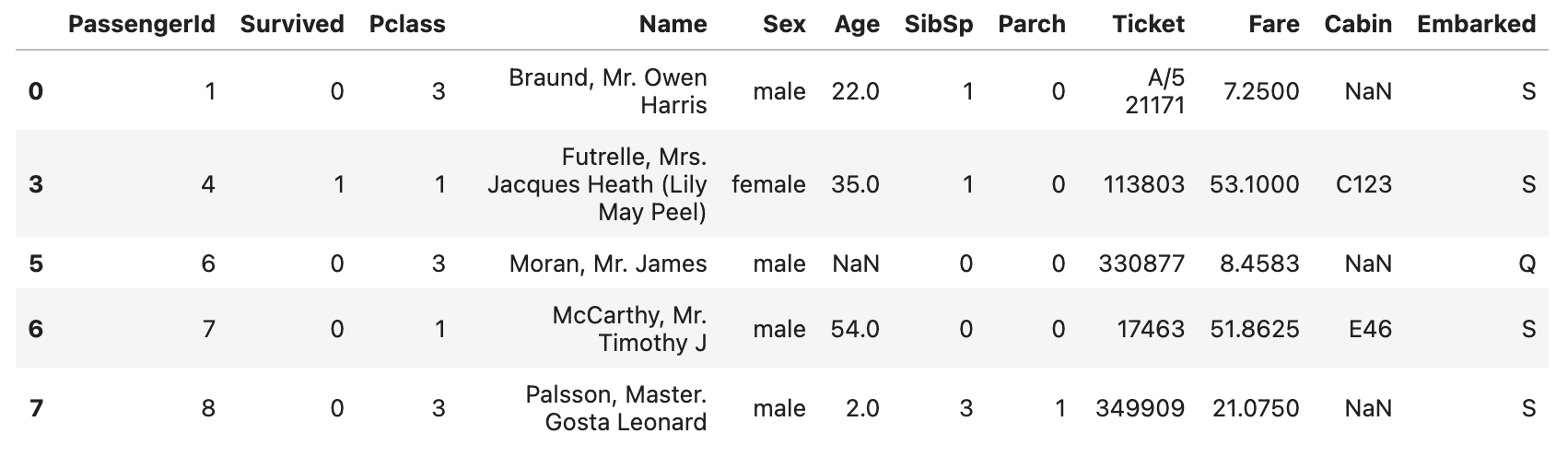
df2.drop([1, 2, 4]).head()위 코드의 결과는 다음과 같습니다.
열 추가
열을 추가하는 방법은 딕셔너리와 똑같이 생성하면 됩니다.
df1['나이대'] = df1['Age'] // 10 * 10 위 코드의 결과는 다음과 같습니다.
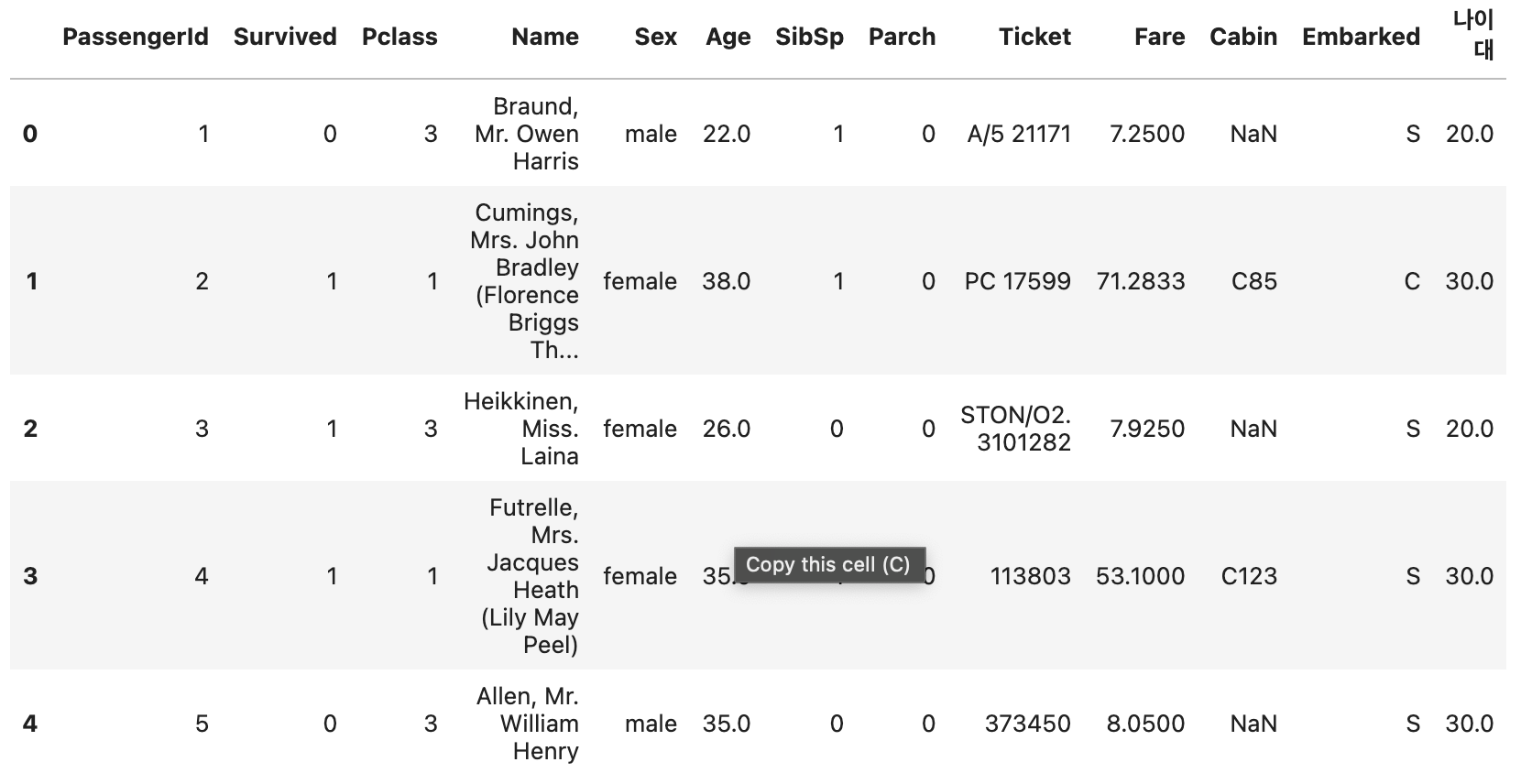
열 삭제
열을 삭제하는 방법은 drop()함수를 사용하면 됩니다.
df1 = df.copy()
df1.drop("Embarked", axis=1).info()위 함수의 결과는 다음과 같습니다.
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 11 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 714 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
dtypes: float64(2), int64(5), object(4)
memory usage: 76.7+ KB위 결과를 보시면 속성 Embarked가 삭제된 것을 확인할 수 있습니다.

꼬박꼬박