결측값 확인
결측값이란 데이터가 비어 있거나 누락된 상태를 말합니다. 데이터프레임에서 info()를 통해 결측값을 확인할 수 있습니다.
df.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 714 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KB위 텍스트를 보시면 Age속성에서는 NaN값이 891-714인 177개가 있다는 것을 알 수 있습니다.
아니면 isna()를 통해 결측값을 알 수 있습니다. isna()는 결측값이 있다면 True를 반환하는 함수입니다.
df.isna()위 코드의 결과는 다음과 같습니다.

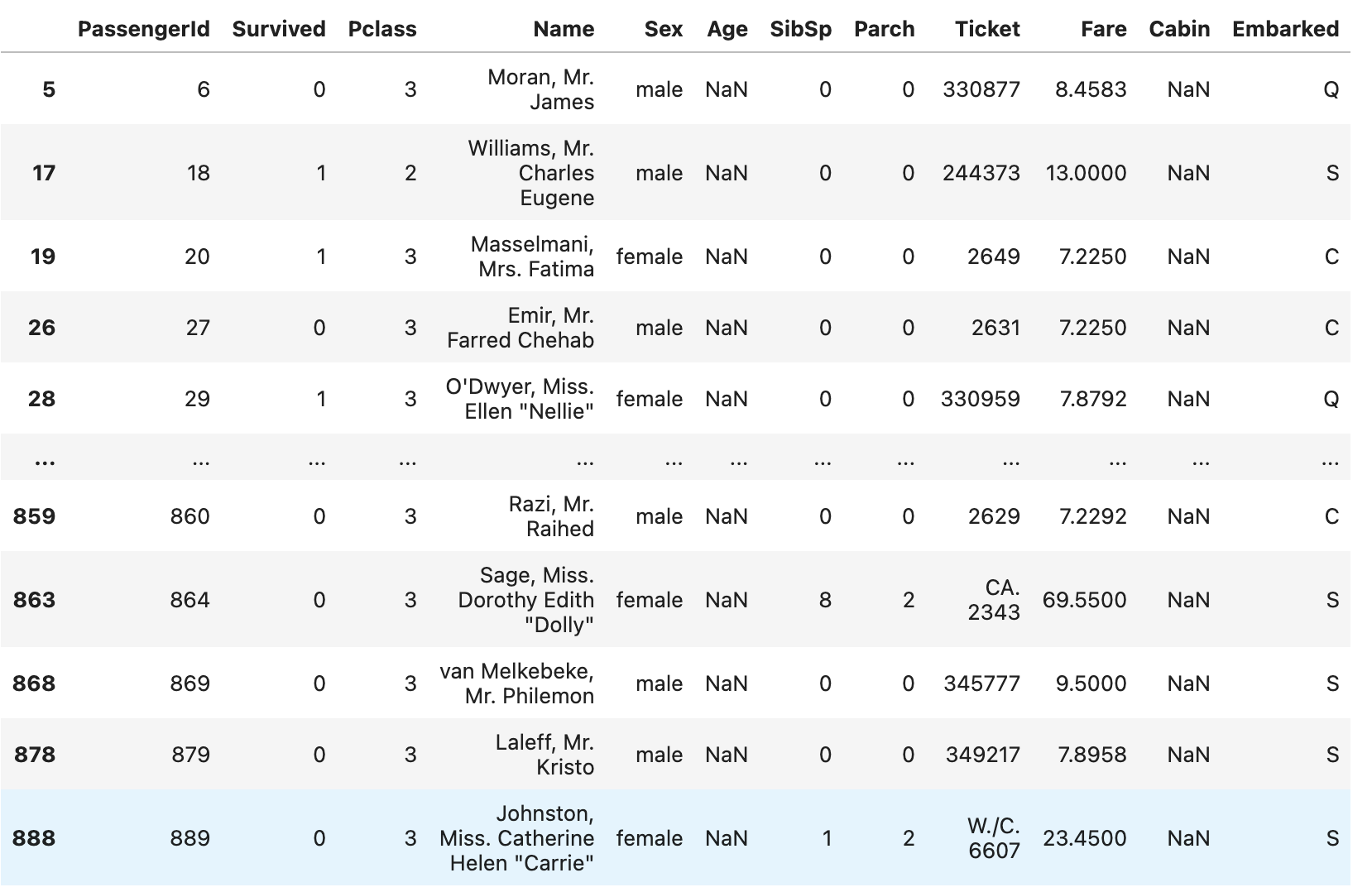
isna()와 loc()를 통해 특정 컬럼에서 NaN인 사람을 출력할 수 있습니다.
df.loc[df["Age"].isna()]위 코드의 결과는 다음과 같습니다.
결측값 제거
dropna()는 결측값(NaN)이 포함된 행 또는 열을 삭제할 때 사용하는 함수입니다. axis 파라미터를 통해 삭제 기준을 설정할 수 있습니다.
- axis = 0: NaN값이 하나라도 있는 row을 삭제합니다.
- axis = 1: NaN값이 하나라도 있는 column을 삭제합니다.
df.dropna().info() 위 결과는 다음과 같습니다.
<class 'pandas.core.frame.DataFrame'>
Index: 183 entries, 1 to 889
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 183 non-null int64
1 Survived 183 non-null int64
2 Pclass 183 non-null int64
3 Name 183 non-null object
4 Sex 183 non-null object
5 Age 183 non-null float64
6 SibSp 183 non-null int64
7 Parch 183 non-null int64
8 Ticket 183 non-null object
9 Fare 183 non-null float64
10 Cabin 183 non-null object
11 Embarked 183 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 18.6+ KB위 텍스트를 보면 데이터 수가 183개로 줄어든 것을 확인할 수 있습니다.
df.dropna(axis = 1).info()위 코드의 결과는 다음과 같습니다.
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 SibSp 891 non-null int64
6 Parch 891 non-null int64
7 Ticket 891 non-null object
8 Fare 891 non-null float64
dtypes: float64(1), int64(5), object(3)
memory usage: 62.8+ KB열이 12개에서 8개로 줄어든 것을 확인할 수 있습니다.
dropna()에 how옵션을 사용하여 좀 더 세밀한 삭제를 할 수 있습니다.
any: 하나라도 NaN 값이 포함되어 있으면 해당 행(row) 또는 열(column)을 삭제합니다.all: 모든 값이 NaN인 경우에만 해당 행(row) 또는 열(column)을 삭제합니다.
df.dropna(how='all').info()위 코드의 결과는 다음과 같습니다.
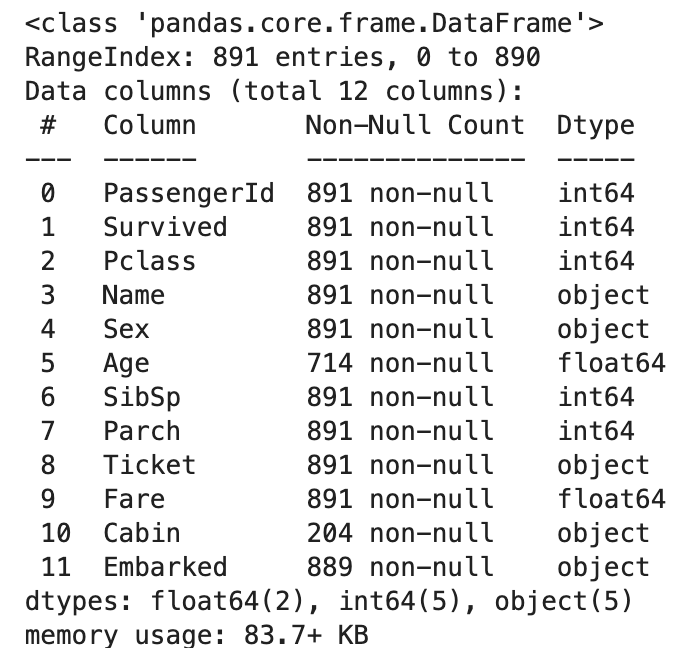
위 사진을 보면 행들 중 모든 column에 대해 결측값이 있는 데이터가 없어서 온전히 모든 데이터가 남아 있는 것을 알 수 있습니다.
선택한 column 중 NaN이 포함되어 있으면 지우게 하기
dropna()의 subset 옵션을 사용하면, 데이터프레임에서 특정 컬럼들만 확인하여 결측값이 있는 행을 삭제할 수 있습니다.
df.dropna(subset=["Cabin", "Age"]).head()위 코드의 결과는 다음과 같습니다.
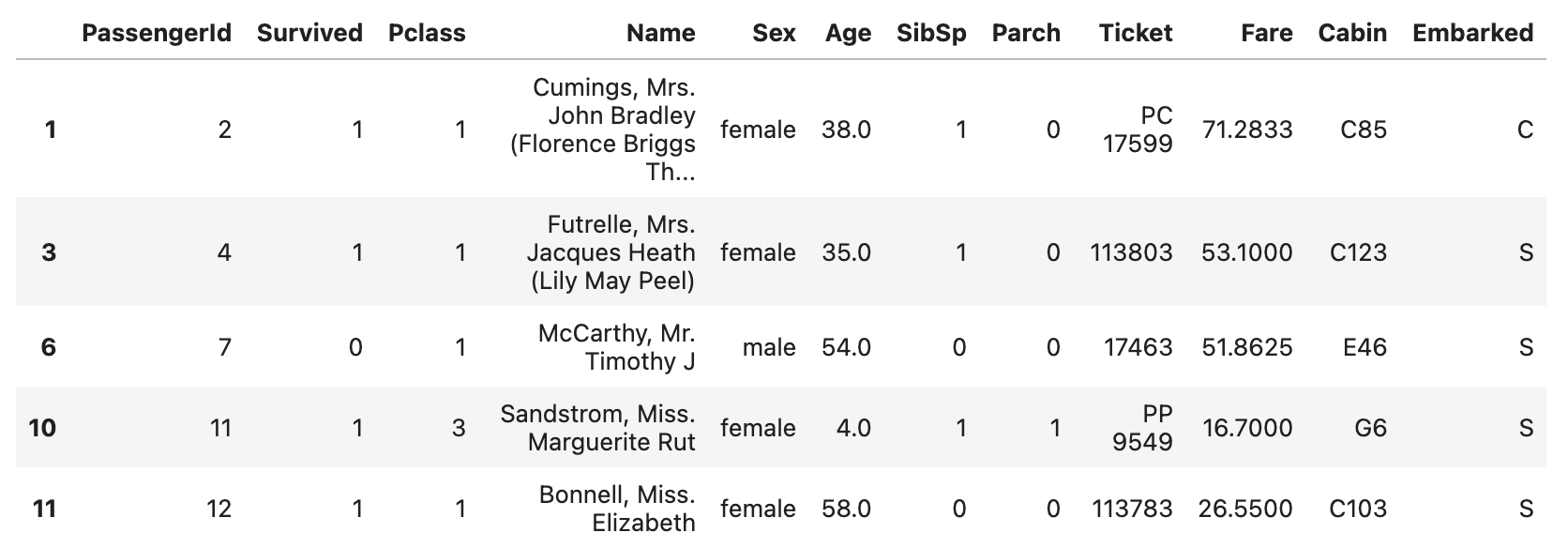
위 결과를 보시면 Cabin과 Age 속성 중 하나라도 NaN이라면 행이 사라진 것을 볼 수 있습니다.
결측값 채우기(대치)
df.fillna()는 결측값을 다른 수로 채우는 함수입니다.
기존의 데이터프레임은 다음과 같습니다.
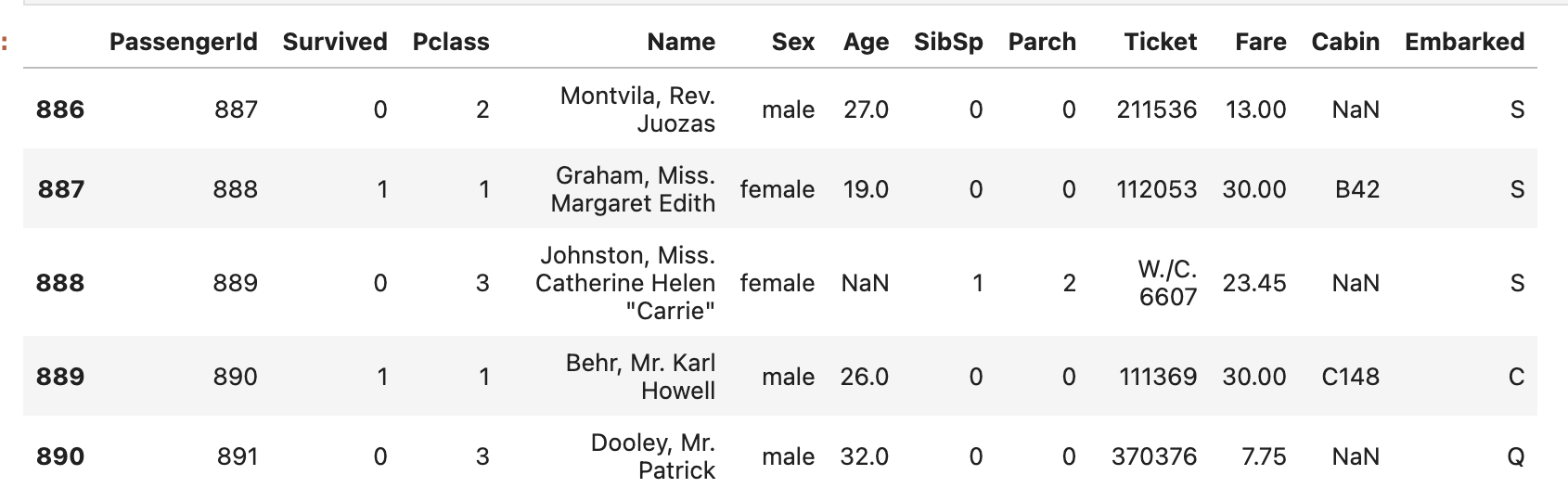
이 데이터프레임에서 다음과 같은 코드를 실행하겠습니다.
df.fillna(-1).tail()위 코드를 실행시키면 다음과 같은 결과가 나옵니다.
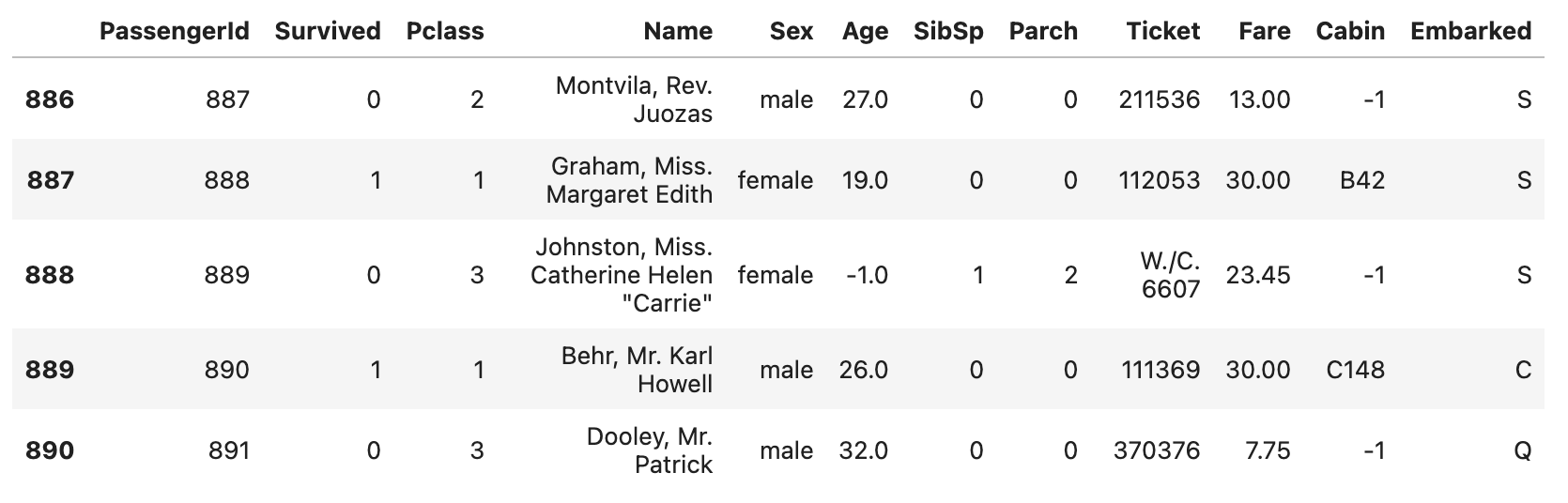
위 사진을 보시면 Cabin 속성에 있던 NaN 값이 -1로 채워진 것을 확인할 수 있습니다.
df.fillna()에는 method옵션을 통해 결측값을 특정 방식으로 채울 수 있습니다. method의 옵션값 종류는 다음과 같습니다.
- ffill: 결측값을 이전 행(row) 또는 열(column)의 값으로 채웁니다.
- bfill: 결측값을 이후 행(row) 또는 열(column)의 값으로 채웁니다.
df.fillna(method='ffill').tail()위 코드의 결과는 다음과 같습니다.
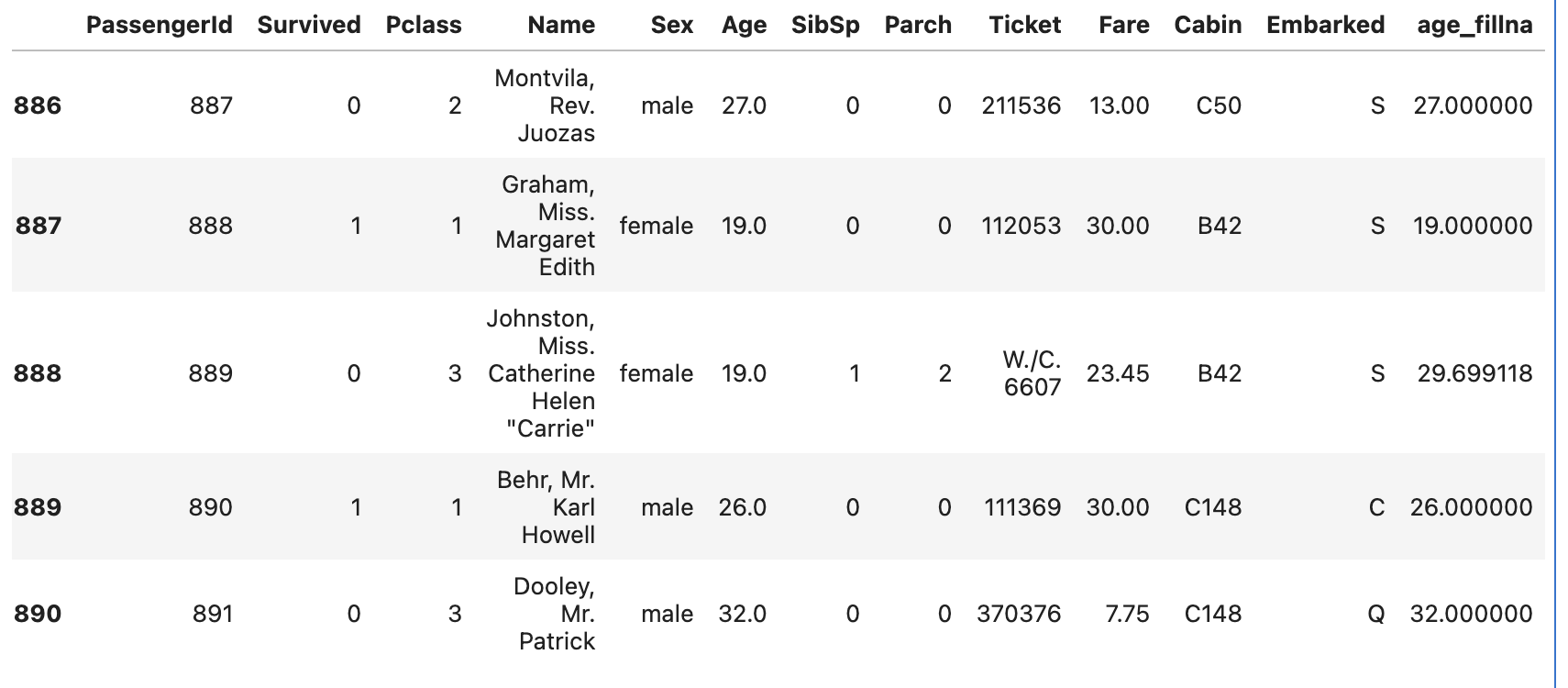
위 사진을 보면 index가 888, 890의 Cabin 값이 이전 행의 Cabin값으로 채워진 것을 확인할 수 있습니다.
