데이터 분석에서 집계(Aggregation)는 다수의 데이터를 하나로 요약하는 과정입니다. 이를 통해 데이터의 전반적인 특징을 빠르게 파악하거나, 의사결정을 위한 핵심 지표를 확인할 수 있습니다. 이 글에서는 데이터 집계에 사용되는 다양한 함수와 그 의미를 정리합니다.
groupby()
groupby() 는 데이터를 하나로 묶는 기능을 가진 함수입니다. 함수의 인수로는 column의 이름이 들어갑니다.
df.groupby("Pclass")위 코드를 실행하면 다음과 같은 결과가 나옵니다.
<pandas.core.groupby.generic.DataFrameGroupBy object at 0x7fffba080910>위 결과의 의미는 DataFrameGroupBy라는 객체가 생성되었다는 의미입니다.
집계 함수
| 함수 | 설명 |
|---|---|
| count() | 행의 갯수 |
| nunique() | 행의 유니크한 갯수 |
| sum() | 합 |
| mean() | 평균 |
| min() | 최솟값 |
| max() | 최댓값 |
| std() | 표준편차 |
| var() | 분산 |
위 함수는 그룹에 대해 계산을 할 수 있는 집계함수입니다. NaN값은 계산에서 제외됩니다.
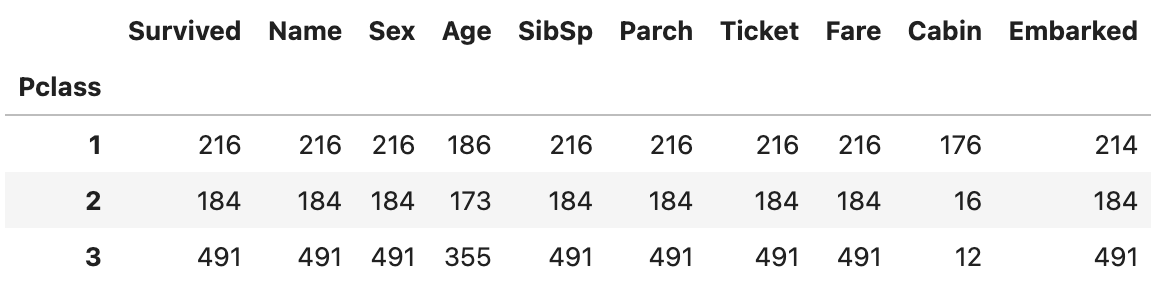
df.groupby("Pclass").count()위 코드의 실행 결과는 다음과 같습니다.
다중 그룹
다중 그룹은 둘 이상의 column 이름을 groupby()의 인수로 사용하여 만들 수 있습니다.
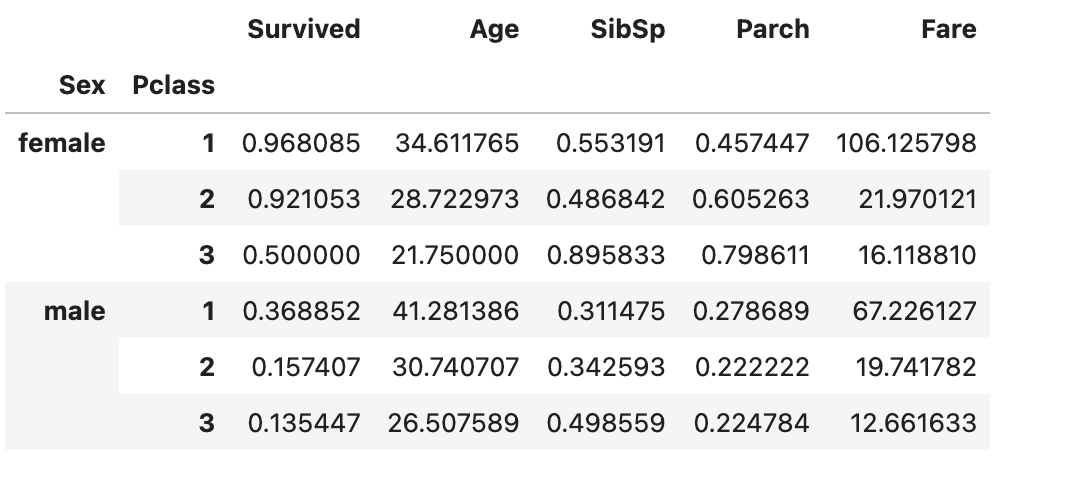
df.groupby(["Sex", "Pclass"]).mean(numeric_only=True)코드에서 numeric_only = True 를 사용한 이유는 문자열 데이터도 계산하기 때문입니다. 위 코드의 결과는 다음과 같습니다.
crosstab
crosstab()은 범주형 데이터를 비교 분석하는 데 유용한 도구로, 데이터 간 관계를 이해하거나 특정 기준에 따라 데이터를 요약할 때 사용됩니다. 행에는 그룹핑할 데이터, 열에는 계산을 할 데이터를 지정합니다.
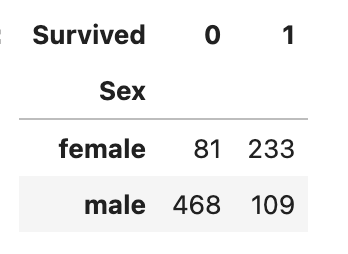
pd.crosstab(df['Sex'], df['Survived'])위 코드의 결과는 다음과 같습니다.
범주별 비율 구하기
normalize은 crosstab()으로 생성된 데이터를 비율로 변환해주는 옵션입니다. 이를 통해 데이터의 상대적인 분포를 파악할 수 있습니다.
여기서 사용할 수 있는 옵션은 다음과 같습니다.
- normalize='all': 전체 데이터를 기준으로 비율 계산 (전체 합이 100%).
- normalize='index': 각 행별 데이터를 기준으로 비율 계산 (행별 합이 100%).
- normalize='columns': 각 열별 데이터를 기준으로 비율 계산 (열별 합이 100%).
그리고 margins은 행과 열의 합계를 포함한 총계(row/column-wise total) 추가됩니다.
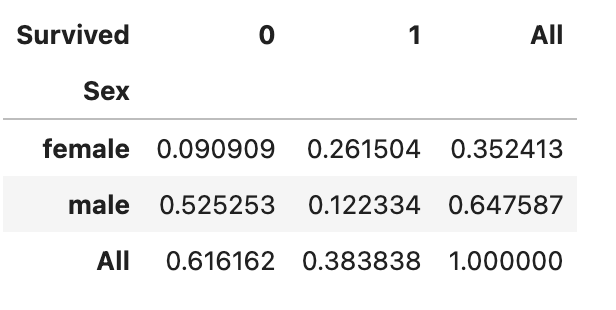
pd.crosstab(df['Sex'], df['Survived'], normalize='all', margins = True)위 코드의 결과는 다음과 같습니다.
다중 인덱스, 다중 컬럼의 범주표
crosstab()로 다중 인덱스, 다중 컬럼을 출력하는 방법은 인수에 리스트형으로 출력하고자 하는 index와 column을 기입하면 됩니다.
pd.crosstab(index=[df['Sex'], df['Pclass']], columns=[df['Survived'], df['Embarked']])위 결과는 다음과 같습니다.
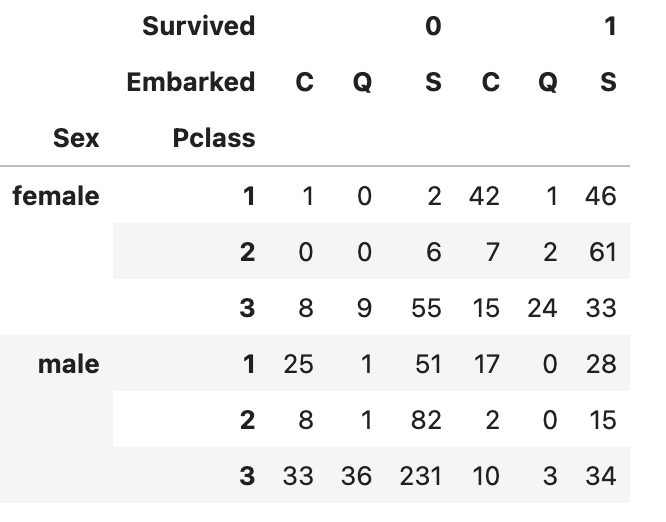
위 결과를 통해 데이터에서 sex속성이 'female'이며 Pclass속성이 1인 사람이 Survived속성이 0이며 Embarked속성이 'C'인 사람은 1명이다는 정보를 알 수 있습니다.
pivot table()
pivot_table() 는 데이터를 특정 기준으로 그룹화하고, 계산하여 표 형태로 변환하는 함수입니다. 인수로 받는 값은 다음과 같습니다.
- data: 사용할 데이터프레임
- index: 테이블의 행으로 들어갈 기존 데이터프레임의 열
- columns: 테이블의 열로 들어갈 기존 데이터프레임의 열
- values: 집계할 데이터를 포함하는 열.
- aggfunc: 각 그룹 별로 값들을 조회할 함수
- fillvalue: NaN값을 대체할 값.
pd.pivot_table(
df,
index='Sex',
columns='Pclass',
values='Fare',
aggfunc='mean',
margins = True
)위 코드의 결과는 다음과 같다.
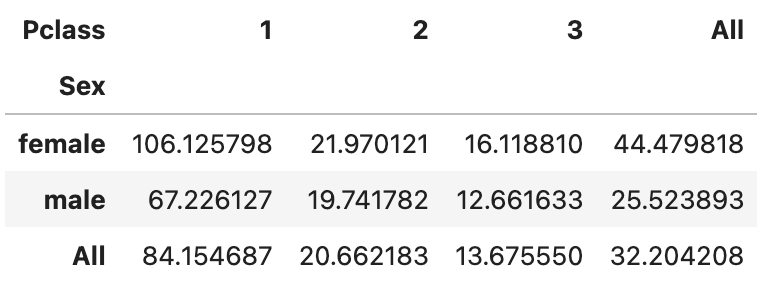
위 결과를 통해 데이터에서 sex 속성이 'female'인 사람중 Pclass 속성이 1인 사람들의 Fare 의 평균은 106.125798이다라는 정보를 알 수 있습니다.
pivot_table()도 마찬가지로 다중 인덱스와 다중 컬럼을 사용할 수 있습니다.
pd.pivot_table(
df,
index=['Sex','Pclass'],
columns=['Survived', 'Embarked'],
values = 'Fare',
aggfunc = 'mean'
)위 코드의 결과는 다음과 같습니다.
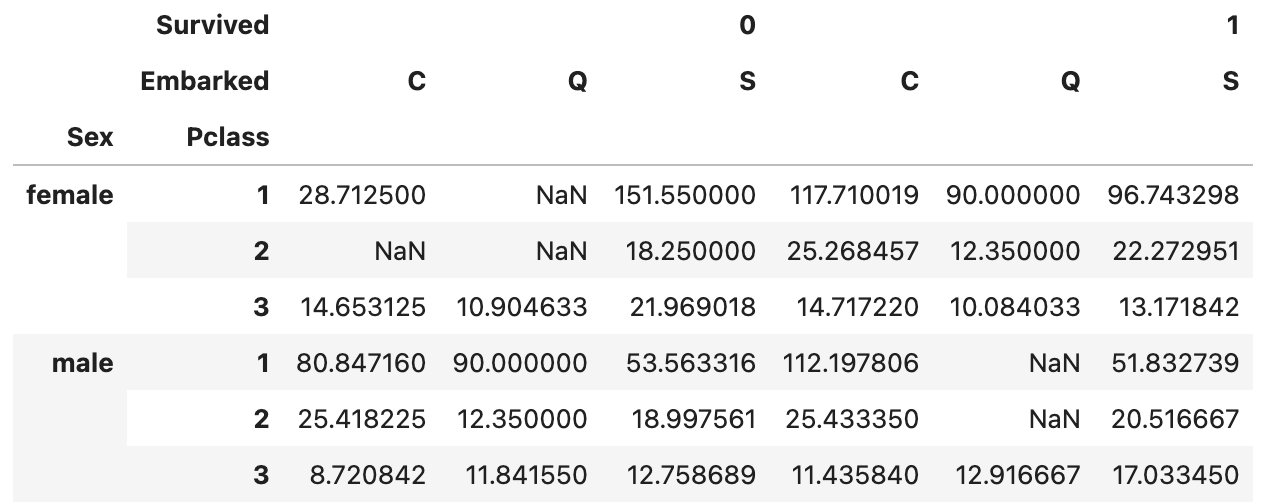
stack(), unstack()
stack()은 column 레벨에서 index 레벨로 데이터프레임을 변경하는 함수입니다.
unstack()은 unstack()과 반대로 index 레벨에서 column 레벨로 데이터프레임을 변경하는 함수입니다.
두 함수 인수로 변경할 레벨을 입력 받습니다.
pivot = pd.pivot_table(
df,
index = ['Sex', 'Pclass'],
values=['Survived', "Fare"],
aggfunc=['mean', 'median', 'sum']
)
pivot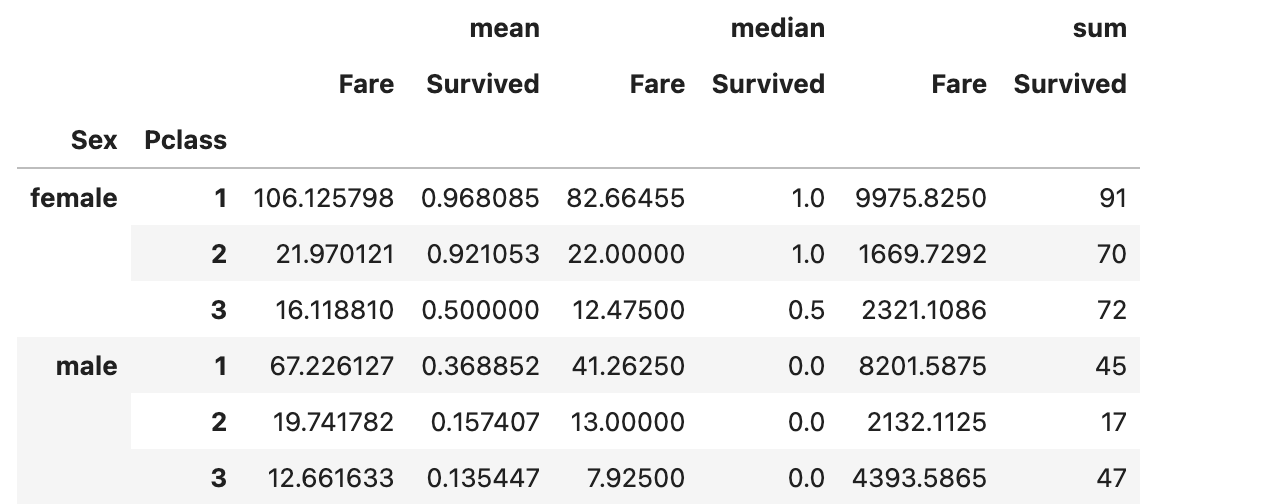
pivot.stack(0) 위 코드를 실행하면 다음과 같은 결과가 나옵니다.
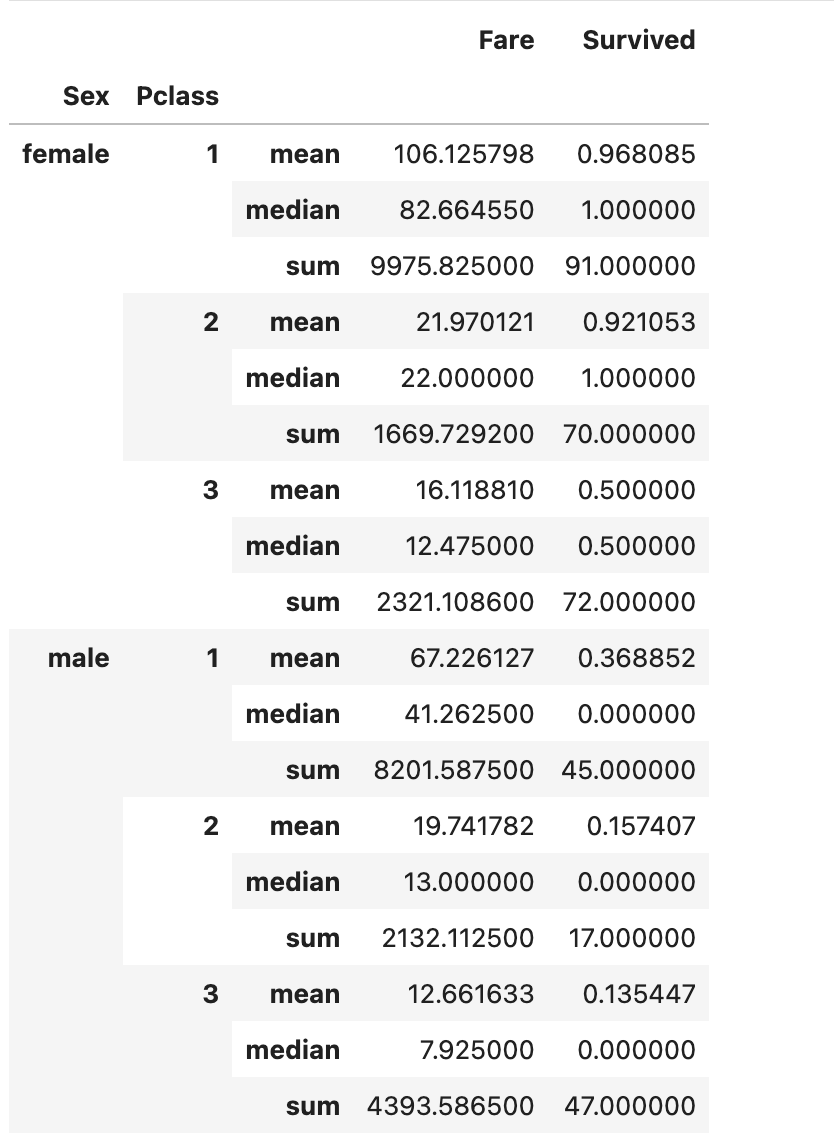
위 표를 보시면 column의 첫 번째 레벨인 mean, median, sum가 row로 내려간 것을 확인할 수 있습니다.
pivot.unstack(0) # 행 index의 첫 번째 레벨을 column으로 올린다.위 코드를 실행하면 다음과 같습니다.

위 표를 보시면 row의 첫번째 레벨인 sex가 column으로 올라간 것을 확인할 수 있습니다.
melt()
melt()는 데이터프레임의 column 값을 행으로 변환하는 함수입니다.
data = {
'이름': ['Alice', 'Bob', 'Charlie'],
'국어': [85, 90, 95],
'수학': [88, 92, 96],
'영어': [87, 91, 93]
}
df = pd.DataFrame(data)
df위 코드의 결과는 다음과 같습니다.
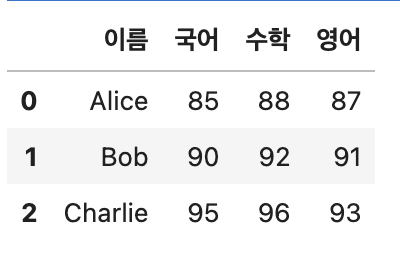
여기서 melt()를 사용하면 다음과 같습니다.
melted_df = pd.melt(
df,
id_vars=['이름'],
value_vars=['국어', '수학', '영어'],
var_name='과목',
value_name='점수'
)
melted_df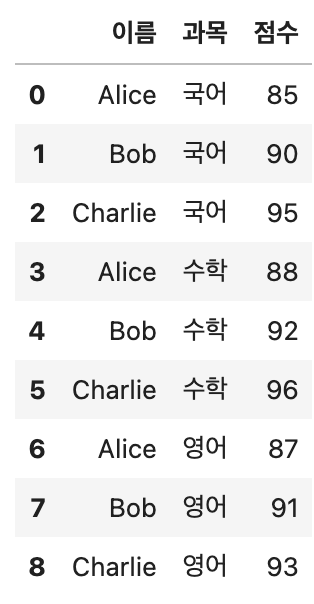
위 사진을 보면 이름이라는 속성을 기준으로 다른 column이 index로 들어온 것을 확인할 수 있다.
column -> record: melt
column -> index : stack
