이번 글에서는 인구 데이터프레임과 CCTV 데이터프레임을 가지고 외국인과 고령자의 수가 많으면 구별 CCTV가 많은지 보는 실습을 해보겠습니다. 여기서 적절하다의 기준은 인구를 기준으로 하겠습니다.
cctv_file = "./data/01. CCTV_in_Seoul.csv"
pop_file = "./data/01. population_in_Seoul.xls"
df_cctv = pd.read_csv(cctv_file)위 코드를 실행하여 CCTV 데이터프레임을 갖고 옵니다. 그 후 데이터의 정보를 확인하기 위해 다음과 같은 코드를 실행합니다.
df_cctv.info()위 코드의 결과는 다음과 같습니다.
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 25 entries, 0 to 24
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 기관명 25 non-null object
1 소계 25 non-null int64
2 2013년도 이전 25 non-null int64
3 2014년 25 non-null int64
4 2015년 25 non-null int64
5 2016년 25 non-null int64
dtypes: int64(5), object(1)
memory usage: 1.3+ KB컬럼의 이름의 기관명을 구별로 바꿔줍니다. 나중에 두 데이터프레임을 합칠 때 구별이라는 컬럼을 통해 merge()를 사용하기 때문입니다.
df_cctv = df_cctv.rename(
columns = {
"기관명" : "구별"
}
)
df_cctv.info()위 코드의 결과는 다음과 같습니다.
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 25 entries, 0 to 24
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 구별 25 non-null object
1 소계 25 non-null int64
2 2013년도 이전 25 non-null int64
3 2014년 25 non-null int64
4 2015년 25 non-null int64
5 2016년 25 non-null int64
dtypes: int64(5), object(1)
memory usage: 1.3+ KB다음으로 인구 데이터프레임을 불러오겠습니다.
df_pop_seoul = pd.read_excel(pop_file)
df_pop_seoul.head()여기서 필요한 부분만 추출하고, 컬럼의 이름도 변경하겠습니다.
df_pop_seoul = pd.read_excel(
pop_file,
header = 2,
usecols = 'B, D, G, J, N'
)
df_pop_seoul.columns = ["구별", "인구수", "한국인", "외국인", "고령자"]
df_pop_seoul = df_pop_seoul.drop([0])
df_pop_seoul.info()위 코드에서 header=2는 엑셀 파일에서 컬럼 이름이 위치한 행(0부터 시작하는 기준으로 세 번째 행)을 지정하는 옵션이며, usecols='B, D, G, J, N'는 특정 열만 선택하여 불러오는 매개변수입니다.
해당 코드는 서울시 인구 데이터를 불러온 후, 선택한 열에 대해 새로운 컬럼명을 ["구별", "인구수", "한국인", "외국인", "고령자"]로 변경하고, 첫 번째 행(인덱스 0)을 제거합니다.
위 코드의 결과는 다음과 같습니다.
<class 'pandas.core.frame.DataFrame'>
Index: 25 entries, 1 to 25
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 구별 25 non-null object
1 인구수 25 non-null float64
2 한국인 25 non-null float64
3 외국인 25 non-null float64
4 고령자 25 non-null float64
dtypes: float64(4), object(1)
memory usage: 1.2+ KB데이터들의 상세 정보를 하나하나 확인해보겠습니다.
먼저 CCTV 데이터프레임을 먼저 확인해보겠습니다.
df_cctv.sort_values(by = "소계", ascending = False).head()위 코드는 CCTV 데이터프레임 중 소계라는 컬럼을 내림차순으로 정렬하여 상위 5개 데이터를 출력하라는 뜻입니다.
위 코드의 실행 결과는 다음과 같습니다.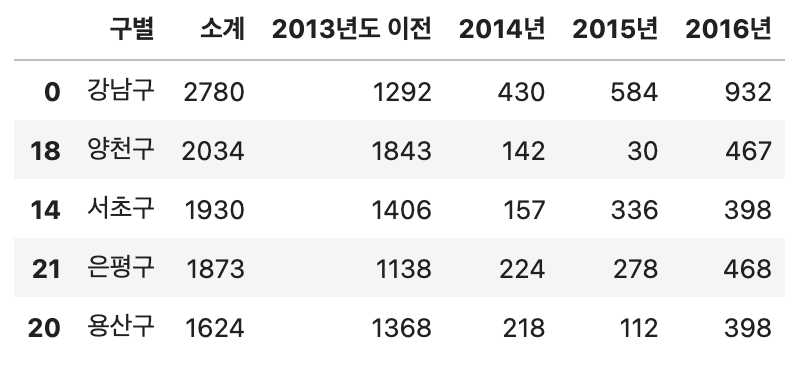
위 코드를 통해 강남구에 CCTV가 2780개로 가장 많이 설치된 것을 확인할 수 있습니다. 하지만 절대적인 숫자를 통해서는 CCTV가 많은지 적은지 알 수 없기 때문에 최근 증가율이라는 새로운 컬럼을 통해 얼마나 증가했는지를 알 수 있게 컬럼을 추가하겠습니다.
df_cctv["최근증가율"] = (df_cctv["2014년"] + df_cctv["2015년"] + df_cctv["2016년"]) / df_cctv["2013년도 이전"] * 100
df_cctv.sort_values(by = "최근증가율", ascending = False).head()위 코드를 통해 2014년, 2015년, 2016년의 합을 더하여 2013년도 이전으로 나누어 2013년도 대비 얼마나 CCTV가 늘었는지 알 수 있습니다.
코드의 실행 결과는 다음과 같습니다.
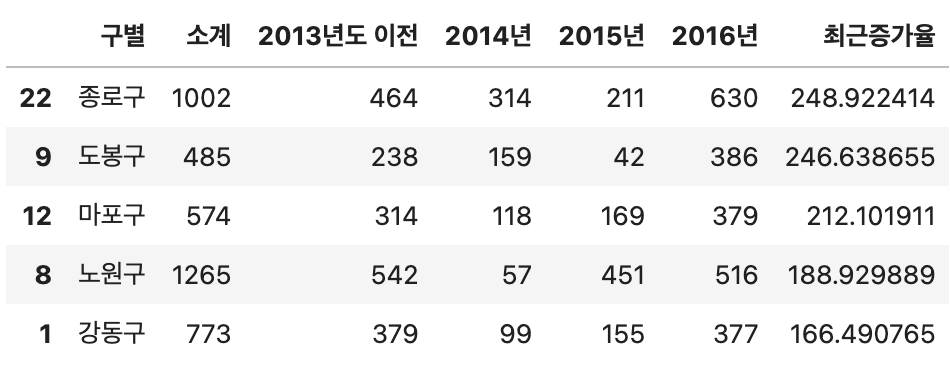
그리고 인구 데이터프레임도 절대적인 숫자가 얼마나 많은지 적은지를 알 수 없기 때문에 비율로 특정 컬럼을 표현하겠습니다.
df_pop_seoul["외국인비율"] = df_pop_seoul["외국인"] / df_pop_seoul["인구수"] * 100
df_pop_seoul["고령자비율"] = df_pop_seoul["고령자"] / df_pop_seoul["인구수"] * 100
df_pop_seoul.sort_values(by = "외국인비율", ascending = False).head()위 코드의 결과는 다음과 같습니다.
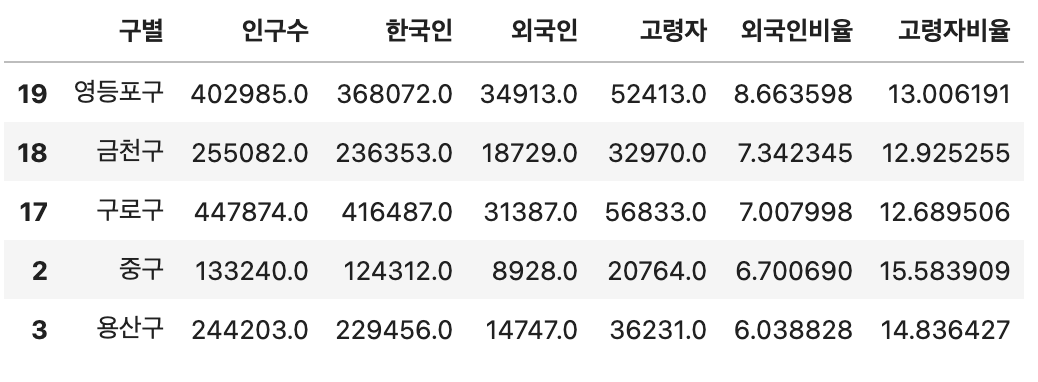
위 표를 보면 외국인의 절대적인 숫자는 구로구가 금천구보다 많지만 비율은 금천구가 구로구보다 많다는 것을 알 수 있습니다.
CCTV, 인구수 데이터 합쳐서 분석하기
저희는 CCTV와 인구수에 대한 데이터분석을 하고 있기 때문에 두 데이터프레임을 합칠 필요가 있습니다. 따라서 다음과 같은 코드를 작성합니다.
data_result = pd.merge(df_cctv, df_pop_seoul, on='구별')
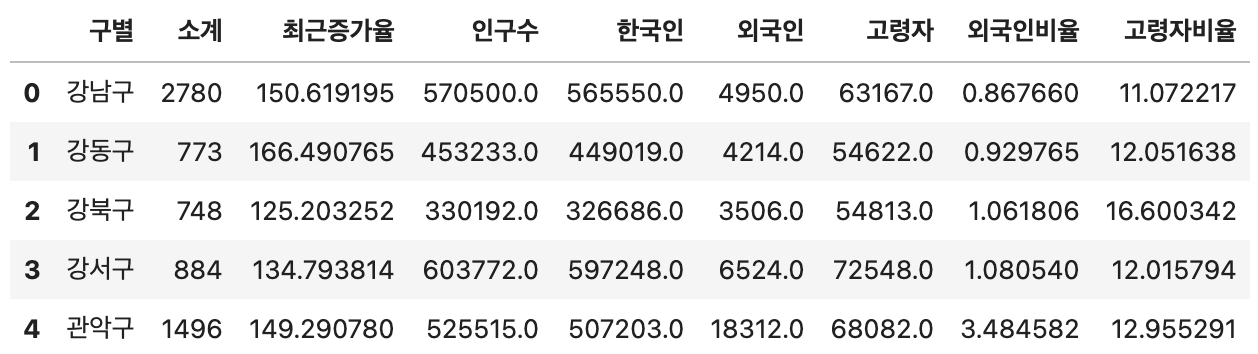
data_result.head()두 데이터프레임 모두 구별 컬럼을 공통으로 가지고 있기 때문에 이를 기준으로 데이터를 결합할 수 있습니다. 위 코드의 결과는 다음과 같습니다.
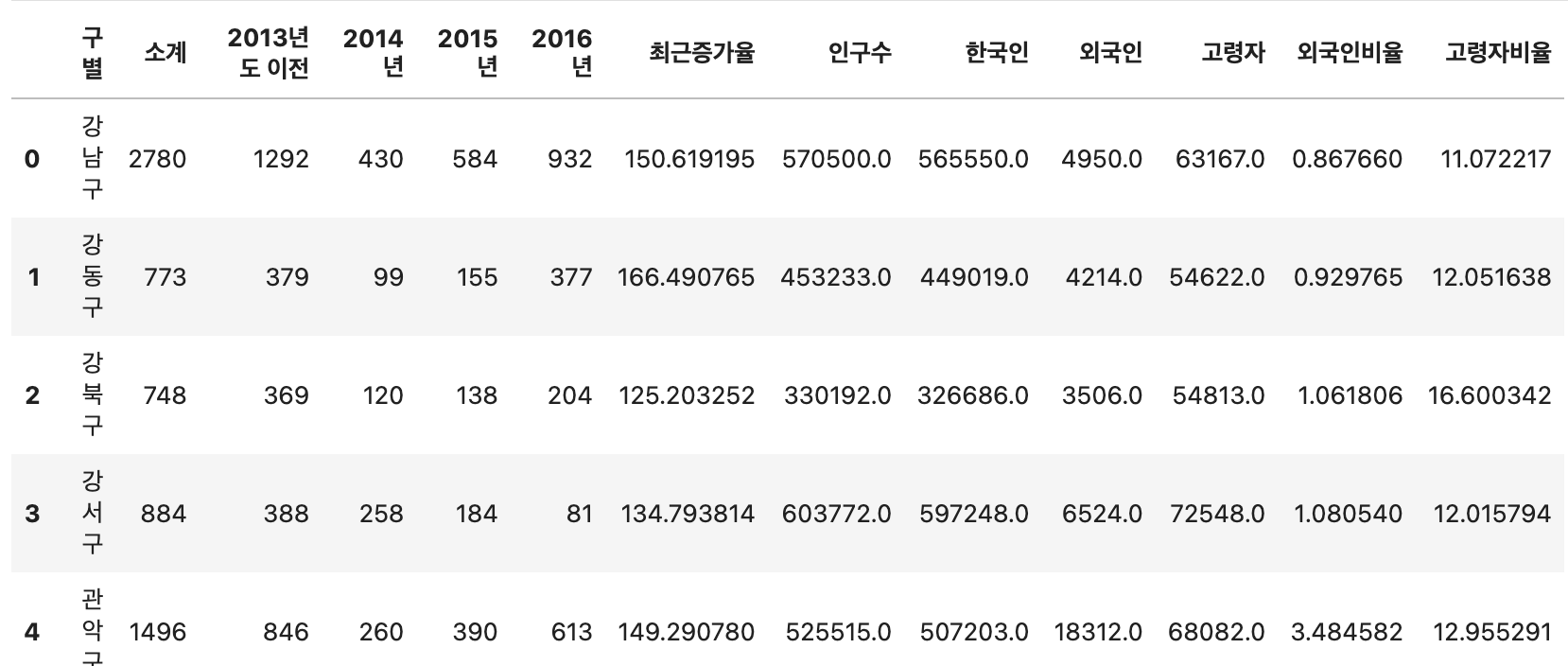
필요 없는 컬럼 삭제하기
합친 데이터프레임에서는 각 연도별 설치 대수는 분석의 핵심 요소가 아닙니다. 우리가 필요한 정보는 각 구별 CCTV의 총합(소계)이므로, 불필요한 연도별 데이터를 제거합니다.
또한, 2013년부터 2016년까지의 CCTV 설치 대수를 활용하여 최근 증가율을 이미 계산하였기 때문에, 해당 연도별 컬럼을 더 이상 유지할 필요가 없습니다.
따라서 다음과 같은 코드를 실행합니다.
data_result = data_result.drop(["2013년도 이전", "2014년", "2015년", "2016년"], axis = 1)
data_result.head()위 코드의 결과는 다음과 같습니다.
CCTV와 소계의 상관관계
CCTV의 총 개수(소계)가 어떤 요인에 의해 결정되는지를 확인하기 위해 다양한 데이터를 비교해 볼 필요가 있습니다. 이를 통해 특정 요인과 CCTV 설치 수 간의 관계를 파악하고, 의미 있는 패턴을 도출할 수 있습니다.
이러한 데이터 간의 관계를 분석할 때 상관관계를 활용하며, 상관관계는 두 변수 간의 연관성을 나타내는 중요한 지표입니다.
상관관계의 정도를 측정하는 상관계수를 통해 변수들 간의 관계를 보다 구체적으로 평가할 수 있습니다. 상관계수는 다음과 같이 해석될 수 있습니다.
- 0.1 이하: 무시할 정도의 상관관계
- 0.1 ~ 0.3: 약한 상관관계
- 0.3 ~ 0.7: 뚜렷한 상관관계
- 0.7 ~ 1.0: 강한 상관관계
여러 요인 중 저희는 고령자 비율과 외국인 비율에 대한 소계의 상관 관계를 확인하고자 합니다. 왜냐하면 저희의 실습 목표 중 하나가 "고령자와 외국인이 많으면 CCTV가 많이 설치 되었는지"이기 때문입니다.
상관계수는 다음과 같이 구할 수 있습니다.
import numpy as np
np.corrcoef(data_result["고령자비율"], data_result["소계"])corrcoef()는 두 변수 간의 피어슨 상관계수(Pearson correlation coefficient) 를 계산하는 함수입니다. 여기서는 고령자비율과 소계의 상관계수를 구합니다. 위 코드의 결과는 다음과 같습니다.
array([[ 1. , -0.28078554],
[-0.28078554, 1. ]])이번에는 외국인비율과 소계의 상관계수를 확인해보겠습니다.
np.corrcoef(data_result["외국인비율"], data_result["소계"])위 코드의 결과는 다음과 같습니다.
array([[ 1. , -0.13607433],
[-0.13607433, 1. ]])위 코드의 결과들을 보면 외국인비율과 고령자비율은 CCTV의 소계와 음의 상관관계를 갖는 것을 확인할 수 있습니다. 즉 각 구에서 외국인과 고령자가 많으면 CCTV는 적다는 것을 의미합니다.
