주성분분석의 필요성
주성분분석(Principal Component Analysis, PCA)는 차원
축소의 대표적 기법
- 고차원 자료 분석을 위한 요구가 증가. 예:
• IT: 이미지 자료
• BT: 마이크로어레이 자료 - 대부분의 전통적 통계분석 방법들은 변수 개수(p)가
표본의 개수(n)보다 많은 경우에 적용이 힘들다. - 변수 간에 상관관계가 높은 경우 -> 다중공선성 문제
- 후속 분석을 위해 차원 축소/직교변환 수행 필요
주성분분석: 전체 자료의 변동(variability)을 가장 잘
설명하는, 원변수의 선형결합을 구함으로써, 고차원 자
료의 변동을 저차원으로 설명하는 기법
(1) 원변수의 선형결합으로서,
(2) 전체 자료의 변동을 제일 잘 설명하는 변수이다.
(3) 주성분 변수 간에는 공통 정보가 없다. 즉, 상관계수=0
1.원변수의 선형결합으로 표현
PC1 = a11 X1+ a12 X2 + ∙∙∙ + a1p X
2. 전체 자료의 변동을 제일 잘 설명하는 변수
3 제1주성분과는 수직(상관계수=0)이다.
주성분 분석을 알아보기 위하여 간단한 실습을 실시하겠습니다.
예제 데이터인 default of credit card clients 데이터 사용
import pandas as pd
import openpyxl
df = pd.read_excel('./datasets/default of credit card clients.xls',header=1)
df.corr()
x = df.drop(['ID','default payment next month'],axis=1)
y = df[['default payment next month']]import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import cross_val_score
import numpy as np
plt.figure(figsize=(14,10))
corr = x.corr()
sns.heatmap(corr,vmin=-1,vmax=1,annot=True,fmt='.1g')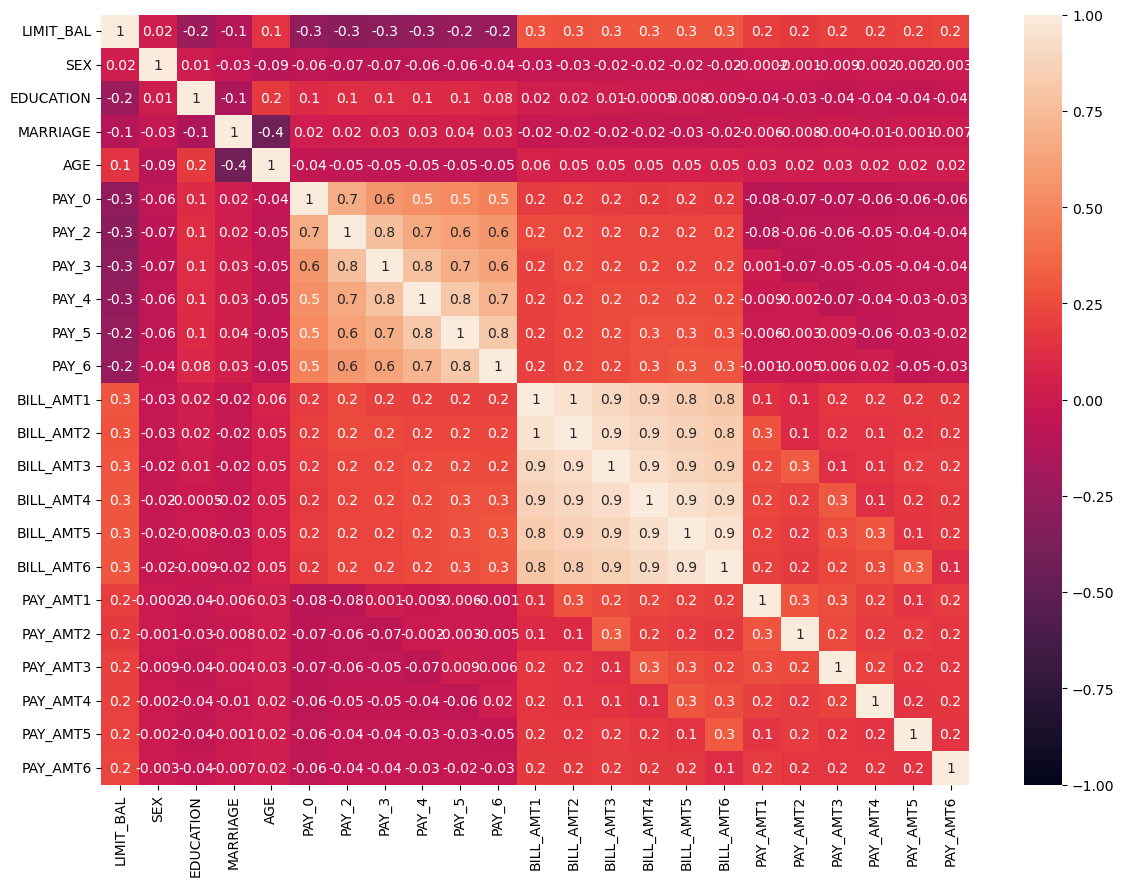
## 1 원본데이터
rcf = RandomForestRegressor(n_estimators=300,random_state=156)
lcf = LogisticRegression()
scores_2 = cross_val_score(lcf,x,y,cv=3,scoring='accuracy')
print(scores_2,scores_2.mean())cv accurcay 평균 accuracy
[0.7783 0.7788 0.7789] 0.7786666666666667
# 2 PCA 변환
scaler = StandardScaler()
x_scale = scaler.fit_transform(x)
pca = PCA(n_components=7)
x_pca = pca.fit_transform(x_scale)
score_pca_1 = cross_val_score(lcf,x_pca,y,scoring='accuracy',cv=3)
print(score_pca_1,score_pca_1.mean())cv accurcay 평균 accuracy
[0.7979 0.7982 0.7987] 0.798266666666666
## pay 변수끼리 bill 변수끼리 일딴 pca 실행후 x데이터 셋을 만들어 예측
pay_name = ['PAY_'+str(i) for i in range(1,7)]
bill_name = ['BILL_AMT'+str(i) for i in range(1,7)]
drop_name = pay_name+bill_name
pay = x.iloc[:,5:11]
bill = x.iloc[:,11:17]
pay_scale = scaler.fit_transform(pay)
bill = scaler.fit_transform(bill)
pca= PCA(n_components=2)
pay_pca = pd.DataFrame(pca.fit_transform(pay),columns=['pay_pca1','pay_pca2'])
bill_pca = pd.DataFrame(pca.fit_transform(bill),columns=['bill_pca1','bill_pca2'])
pca_col = pd.concat([pay_pca,bill_pca],axis=1)score_pca_1 = cross_val_score(lcf,pca_col,y,scoring='accuracy',cv=3)
print(score_pca_1,score_pca_1.mean())cv accurcay 평균 accuracy
[0.8004 0.8021 0.8044] 0.8023000000000001

Just Enjoy Yourself