비지도학습
1.DBSCAN
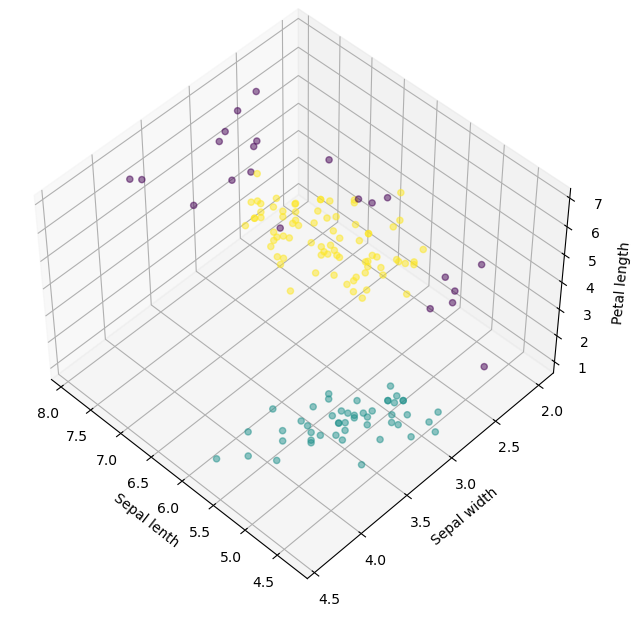
이번에는 클러스터링 알고리즘중 밀도 방식의 클러스터링을 사용하는 DBSCAN(Density-based spatial clustering of applications with noise) 에 대해서 알아보도록 한다.밀도 기반의 클러스터링은 점이 세밀하게 몰려 있어서 밀도
2.PCA 주성분분석
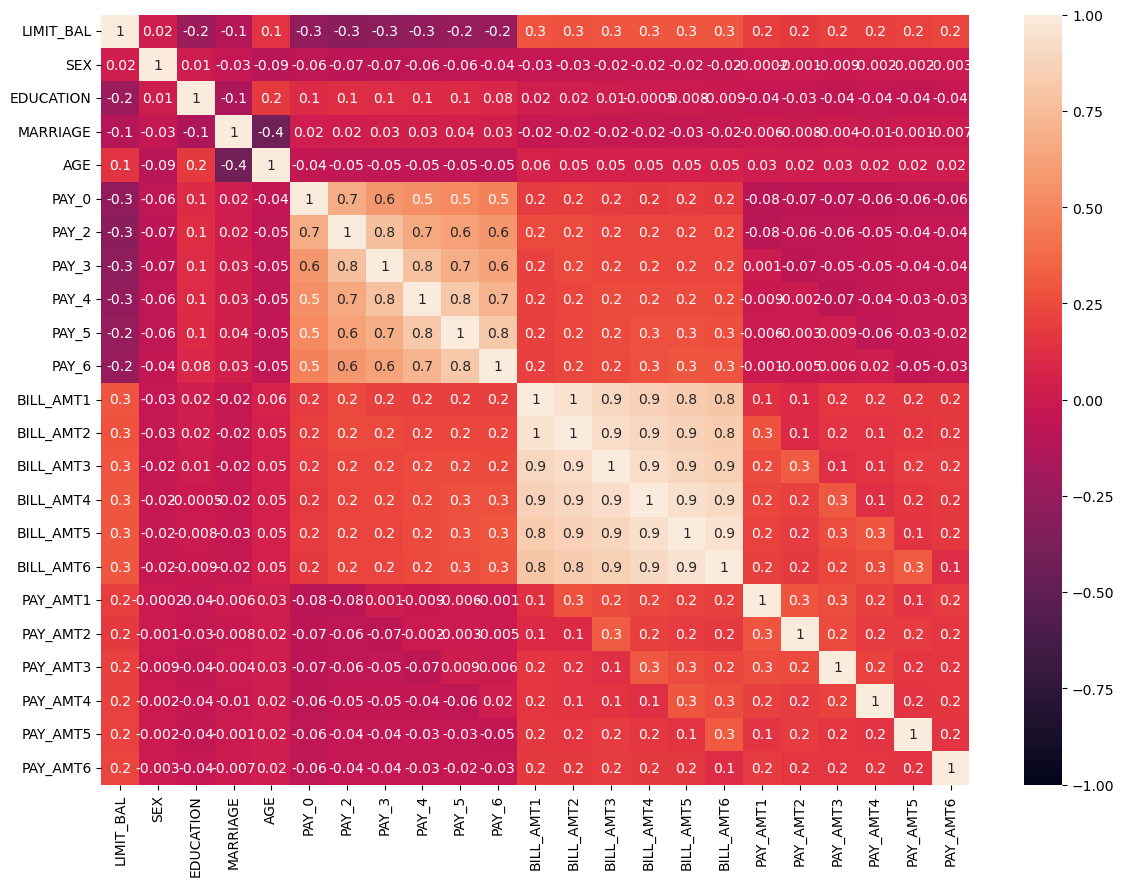
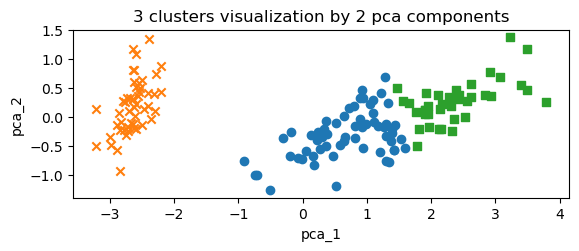
주성분분석의 필요성주성분분석(Principal Component Analysis, PCA)는 차원축소의 대표적 기법고차원 자료 분석을 위한 요구가 증가. 예: • IT: 이미지 자료• BT: 마이크로어레이 자료대부분의 전통적 통계분석 방법들은 변수 개수(p)가표본의 개
3.GMM(GaussianMixture)

머신러닝에서 자주 사용되는 Gaussian Mixture Model(GMM)을 알아보겠습니다. GMM은 머신러닝에서 Unsupervised Learning(클러스터링)에 많이 활용이 됩니다. 하지만 다른 K-means와 같은 클러스터링 알고리즘과는 다르게 통계적인 용어
4.K-means clustering
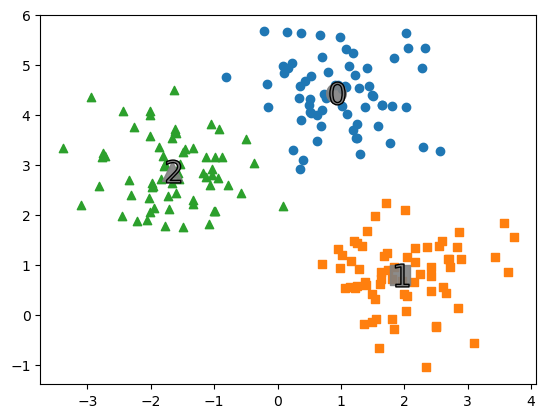
KMeans 클러스터링 알고리즘은 n개의 중심점을 찍은 후에, 이 중심점에서 각 점간의 거리의 합이 가장 최소화가 되는 중심점 n의 위치를 찾고, 이 중심점에서 가까운 점들을 중심점을 기준으로 묶는 클러스터링 알고리즘이다.아래 그림을 보면 3개의 군집이 존재하는 것을
5.Mean Shift cluster
Mean Shift Clustering 개요K-Means랑 유사한데 차이점은K-means는 중심에 소속된 데이터의 평균 거리 중심으로 이동하는 데 반해,Mean Shift는 중심을 데이터가 모여있는 밀도가 가장 높은 곳으로 이동 시킴특징KDE (Kernel Densit
6.silhouette_score
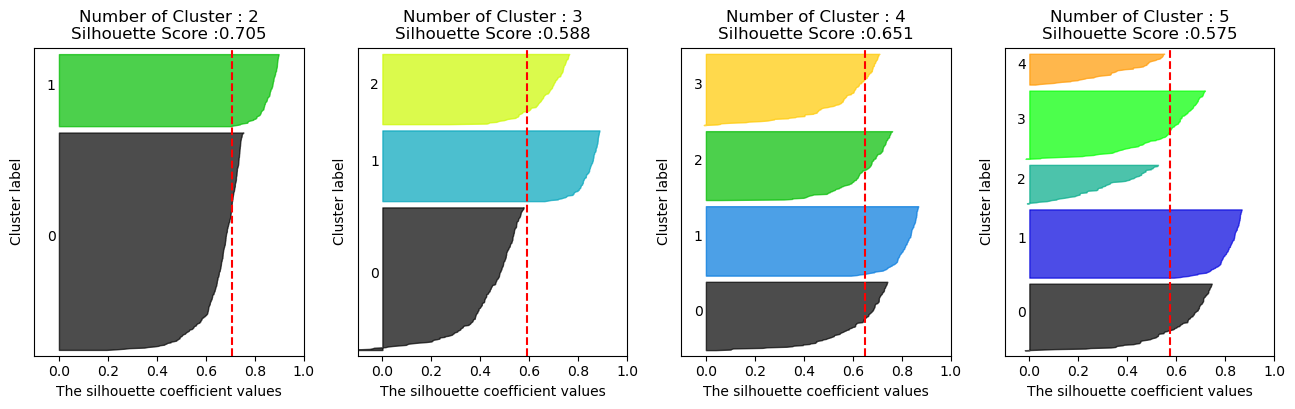
sklearn.metrics.silhouettescore(\_X, labels, \*, metric='euclidean', sample_size=None, random_state=None, \*\*kwds)\[source](https://github