sklearn.metrics.silhouette_score¶
sklearn.metrics.silhouettescore(_X, labels, *, metric='euclidean', sample_size=None, random_state=None, **kwds)[source]
실루엣 분석 metirc 값을 구하기 위해 iris데이터를 통하여 실습해 보겠습니다.
이때 군집화는 kmeans 방법으로 클러스터개수를 3개로 수행 하였습니다.
from sklearn.preprocessing import scale
from sklearn.datasets import load_iris
from sklearn.cluster import KMeans
# 실루엣 분석 metric 값을 구하기 위한 API 추가
from sklearn.metrics import silhouette_samples,silhouette_score
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
iris = load_iris()
feature_names = ['sepal_lenght','sepal_width','petal_length','petal_width']
iris_df = pd.DataFrame(iris.data,columns=feature_names)
## kmeans 군집화 수행
kmeans = KMeans(n_clusters=3,init='k-means++',max_iter=100,random_state=0).fit(iris_df)
iris_df['cluster'] = kmeans.labels_
iris_df.head()sepal_lenght sepal_width petal_length petal_width cluster
0 5.1 3.5 1.4 0.2 1
1 4.9 3.0 1.4 0.2 1
2 4.7 3.2 1.3 0.2 1
3 4.6 3.1 1.5 0.2 1
4 5.0 3.6 1.4 0.2 1# iris 의 모든 개별 데이터에 실루엣 계수값을 구함
score_samples = silhouette_samples(iris.data,iris_df['cluster'])
print('silhouette_sample() return 값의 shape',score_samples.shape)
# 실루엣 계수 컬럼 추가
iris_df['silhouette_coeff'] = score_samples
# 모든 데이터의 평군 실루엣 계수값을 구함
average_score = silhouette_score(iris.data,iris_df['cluster'])
print('평균 실루엣 값',average_score)
iris_df.groupby('cluster')['silhouette_coeff'].mean()silhouette_sample() return 값의 shape (150,)
평균 실루엣 값 0.5528190123564095
cluster
0 0.417320
1 0.798140
2 0.451105
데이터 별 실루엣 계수
클러스터가 1인 데이터들은 0.8 정도의 실루엣 계수를 가지므로
군집화가 어느정도 잘 된 듯하다.
하지만 실루엣 계수 평균 값이 0.553인 이유는
다른 클러스터에 할당된 데이터들의 실루엣 계수값이 작아서이다
## 실루엣 계수 시각화를 통하여 최적의 클러스터수 찾기
# 실루엣 기법
def visualize_silhouette(cluster_lists, X_features):
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_samples, silhouette_score
import matplotlib.pyplot as plt
import matplotlib.cm as cm
import math
# 입력값으로 클러스터링 갯수들을 리스트로 받아서, 각 갯수별로 클러스터링을 적용하고 실루엣 개수를 구함
n_cols = len(cluster_lists)
# plt.subplots()으로 리스트에 기재된 클러스터링 수만큼의 sub figures를 가지는 axs 생성
fig, axs = plt.subplots(figsize=(4*n_cols, 4), nrows=1, ncols=n_cols)
# 리스트에 기재된 클러스터링 갯수들을 차례로 iteration 수행하면서 실루엣 개수 시각화
for ind, n_cluster in enumerate(cluster_lists):
# KMeans 클러스터링 수행하고, 실루엣 스코어와 개별 데이터의 실루엣 값 계산.
clusterer = KMeans(n_clusters = n_cluster, max_iter=500, random_state=0)
cluster_labels = clusterer.fit_predict(X_features)
sil_avg = silhouette_score(X_features, cluster_labels)
sil_values = silhouette_samples(X_features, cluster_labels)
y_lower = 10
axs[ind].set_title('Number of Cluster : '+ str(n_cluster)+'\n' \
'Silhouette Score :' + str(round(sil_avg,3)) )
axs[ind].set_xlabel("The silhouette coefficient values")
axs[ind].set_ylabel("Cluster label")
axs[ind].set_xlim([-0.1, 1])
axs[ind].set_ylim([0, len(X_features) + (n_cluster + 1) * 10])
axs[ind].set_yticks([]) # Clear the yaxis labels / ticks
axs[ind].set_xticks([0, 0.2, 0.4, 0.6, 0.8, 1])
# 클러스터링 갯수별로 fill_betweenx( )형태의 막대 그래프 표현.
for i in range(n_cluster):
ith_cluster_sil_values = sil_values[cluster_labels==i]
ith_cluster_sil_values.sort()
size_cluster_i = ith_cluster_sil_values.shape[0]
y_upper = y_lower + size_cluster_i
color = cm.nipy_spectral(float(i) / n_cluster)
axs[ind].fill_betweenx(np.arange(y_lower, y_upper), 0, ith_cluster_sil_values, \
facecolor=color, edgecolor=color, alpha=0.7)
axs[ind].text(-0.05, y_lower + 0.5 * size_cluster_i, str(i))
y_lower = y_upper + 10
axs[ind].axvline(x=sil_avg, color="red", linestyle="--")
from sklearn.datasets import make_blobs
x,y = make_blobs(n_samples=500,n_features=2,centers=4,cluster_std=1,
center_box=(-10,10),shuffle=True,random_state=1)
visualize_silhouette([2,3,4,5],x)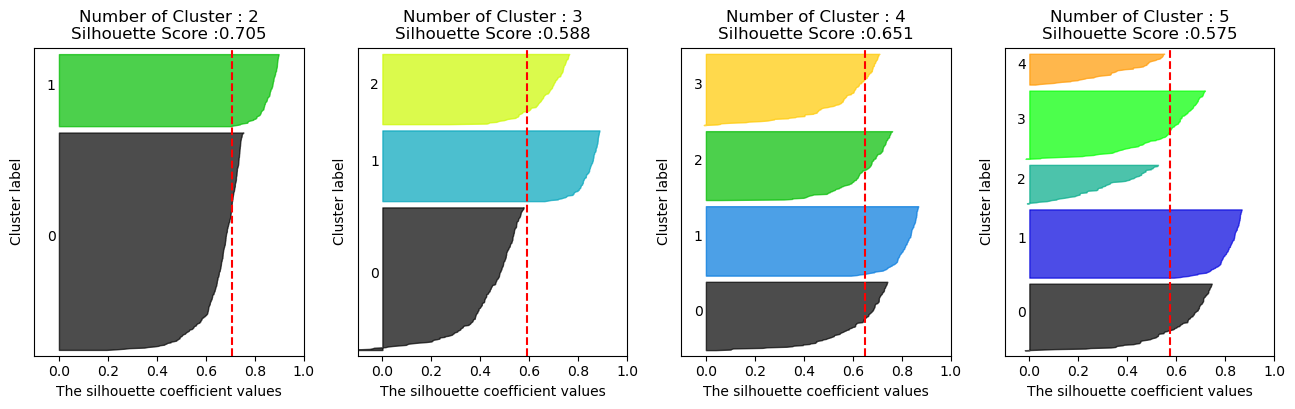
실루엣 계수는 클러스터 2일때 좋은 값이 나왓지만
데이터의 분포가 고르지 않기 때문에
클러스터 4로 했을때 데이터의 분포가 고르고 실루엣 계수값도 좋게 나왓다

Just Enjoy Yourself