앙상블
- 단일 결정 트리의 단점을 극복하기 위해 여러 머신 러닝 모델을 연결하여 더 강력한 모델을 만드는 방법
- 주어진 자료로부터 여러 개의 예측 모형들을 만든 후 예측 모형들을 조합하여 하나의 최종 예측 도형으로 만드는 것
- 대표적인 기법은 배깅, 부스팅, 랜덤포레스트
import pandas as pd
## 유방암 데이터 로드하여 종양 예측하는 분류분석
breast = pd.read_csv('./data/breast-cancer.csv')import seaborn as sns
import matplotlib.pyplot as plt
plt.figure()
## 진단 데이터가 타깃데이터
## M이 악성 B는 양성
sns.countplot(x='diagnosis', data =breast)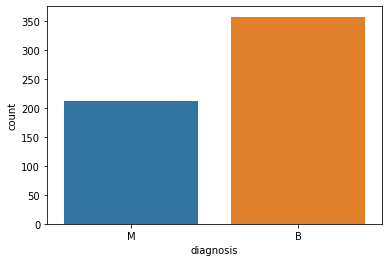
## 설명변수를 area_mean, texture_mean으로 설정 타깃변수를 diagnosis로 설정하여 산점도 그래프
sns.relplot(x='area_mean', y='texture_mean', hue='diagnosis', data=breast)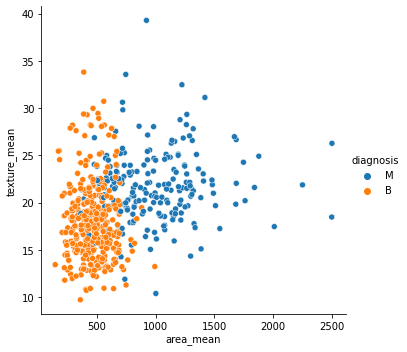
### 진단 데이터를 이산형으로 변경 M이면 1 아니면 0
### 데이터 분할
import numpy as np
from sklearn.model_selection import train_test_split
breast["diagnosis"] = np.where(breast["diagnosis"]=="M", 1, 0)
features = ["area_mean", "area_worst"]
X = breast[features]
y = breast["diagnosis"]
x_train, x_test, y_train, y_test = train_test_split(X, y, test_size =0.3, stratify =y, random_state =1)
print(x_train.shape, x_test.shape)
print(y_train.shape, y_test.shape)배깅
- 주어진 자료를 모집단으로 간주하여 주어진 자료에서 여러 개의 붓스트랩 자료를 생성하고 각각의 붓스트랩 자료에 예측 모형을 만든 후 결합하여 최종 예측 모형은 만드는 것
- 통계분류와 회귀분석에서 사용하는 머신러닝 알고리즘의 안정성과 정확도를 향상시키기 위해 고안한 학습법
## BaggingClassifier를 이용하여 분류기를 생성해 예측 수행
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import BaggingClassifier
clf = BaggingClassifier(base_estimator =DecisionTreeClassifier())
pred = clf.fit(x_train, y_train).predict(x_test)
print("Accuracy Score : ", clf.score(x_test, pred))Accuracy Score : 1.0
## 혼동행렬을 반환하여 예측결과를 자세히 확인
from sklearn.metrics import confusion_matrix
pd.DataFrame(confusion_matrix(y_test, pred),
index=['True[0]', 'True[1]'],
columns=['Pred[0]','Pred[1]']) Pred[0] Pred[1]
True[0] 101 6
True[1] 9 55## oob_score를 이용하여 모델 평가
## oob_score를 true로 설정하면 기능을 사용 가능
## 검증세트나 교차검증을 하지 않아도 되는 장점
clf_oob=BaggingClassifier(base_estimator =DecisionTreeClassifier(),
oob_score=True)
oob=clf_oob.fit(X, y).oob_score_
print(oob)0.9138840070298769
부스팅
- 예측력이 약한 모형들을 결합해 강한 예측 모형으로 만드는 방법
## 부스팅 방식회귀분석
## 차량 데이터 로드
car = pd.read_csv("./data/CarPrice_Assignment.csv")
car_num = car.select_dtypes(['number'])
features = list(car_num.columns.difference(['car_ID', 'symboling', 'price']))
X=car_num[features]
y=car_num['price']
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(X, y, test_size =0.3, random_state =1)## 모델의 예측력 확인
from sklearn.ensemble import AdaBoostRegressor
reg = AdaBoostRegressor(base_estimator =None)
pred=reg.fit(x_train, y_train).predict(x_test)
from sklearn.metrics import mean_squared_error, mean_absolute_error, mean_squared_error
mse = mean_squared_error(y_test, pred)
mae = mean_absolute_error(y_test, pred)
rmse = np.sqrt(mse)
r2 = reg.score(x_test, y_test)
print('MSE\t{}'.format(round(mse,3)))
print('MAE\t{}'.format(round(mae,3)))
print('RMSE\t{}'.format(round(rmse,3)))
print('r2\t{}%'.format(round(r2 *100,3)))MSE 6221211.287
MAE 1825.094
RMSE 2494.236
r2 89.695%
## 변수의 중요도 확인
importances = reg.feature_importances_
column_nm = pd.DataFrame(features)
feature_importances = pd.concat([column_nm,
pd.DataFrame(importances)],
axis=1)
feature_importances.columns = ['feature_nm', 'importances']
print(feature_importances) feature_nm importances
0 boreratio 0.019181
1 carheight 0.003101
2 carlength 0.010996
3 carwidth 0.074639
4 citympg 0.019009
5 compressionratio 0.002970
6 curbweight 0.062739
7 enginesize 0.631786
8 highwaympg 0.065671
9 horsepower 0.061642
10 peakrpm 0.011266
11 stroke 0.011511
12 wheelbase 0.025489

Just Enjoy Yourself