서포트 벡터 머신(SVM)
- 새로운 데이터가 입력되었을 때 기존 데이터를 활용해 분류하는 방법
- 패턴 인식, 자료 분석 등을 위한 지도 학습 모델로 회귀와 분류 문제 해결에 사용되는 알고리즘
## LinearSVC(서포트 백터 방식으로 분류분석)
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
c=pd.read_csv('./data/classification.csv')
c## 데이터 클래스 분포를 그래프로 확인
sns.pairplot(hue='success', data=c)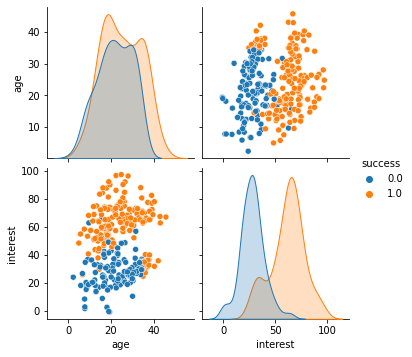
## 데이터의 분할
from sklearn.model_selection import train_test_split
x=c[['age', 'interest']]
y=c['success']
train_x, test_x, train_y, test_y = train_test_split(x,y,stratify=y, train_size=0.7, random_state=1)
print(train_x.shape, test_x.shape, train_y.shape, test_y.shape)## SVM은 특성의 스케일에 민감하기 때문에 StandardScaler를 사용하면 좀 더
# 예측력 높은 결정경계를 생성할 수 있다.
from sklearn.preprocessing import StandardScaler
scaler=StandardScaler()
train_x=scaler.fit_transform(train_x)
sns.pairplot(data=pd.concat([pd.DataFrame(train_x), train_y.reset_index(drop=True)], axis=1),
hue='success')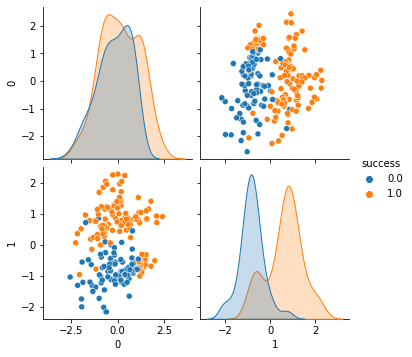
## SVC로 모델을 만들고 데이터 적합
from sklearn.svm import SVC
### 하이퍼파라미터 C, gamma 값은 클수록 오버피팅위험이 있음
clf = SVC(C=0.5)
clf.fit(train_x, train_y)## 테스트데이터로 모델 평가를 수행
from sklearn.metrics import confusion_matrix, accuracy_score, precision_score, recall_score, f1_score
test_x_scal = scaler.transform(test_x)
pred=clf.predict(test_x_scal)
test_cm=confusion_matrix(test_y, pred)
test_acc=accuracy_score(test_y, pred)
test_prc=precision_score(test_y, pred)
test_rcll=recall_score(test_y, pred)
test_f1=f1_score(test_y, pred)
print(test_cm)
print('\n')
print('정확도\t{}%'.format(round(test_acc*100,2)))
print('정밀도\t{}%'.format(round(test_prc*100,2)))
print('재현율\t{}%'.format(round(test_rcll*100,2)))
print('F1\t{}%'.format(round(test_f1*100,2)))[[37 2][ 2 49]]
정확도 95.56%
정밀도 96.08%
재현율 96.08%
F1 96.08%
import numpy as np
import matplotlib.pyplot as plt
from sklearn.svm import LinearSVC
## 하이퍼파라미터 C 에 따라 마진에서 어떠한 변화가 발생하는지 확인
## C의 값이 커지면 마진과 옮지 않은 데이터의 허용치가 증가
plt.figure(figsize=(10, 5))
for i, C in enumerate([1, 500]):
clf = LinearSVC(C=C, loss="hinge", random_state=42).fit(train_x, train_y)
# decision function으로 서포트벡터 얻기
decision_function = clf.decision_function(train_x)
support_vector_indices = np.where(np.abs(decision_function) <= 1 + 1e-15)[0]
support_vectors = train_x[support_vector_indices]
plt.subplot(1, 2, i +1)
plt.scatter(train_x[:, 0], train_x[:, 1], c =train_y, s =30, cmap =plt.cm.Paired)
ax = plt.gca()
xlim = ax.get_xlim()
ylim = ax.get_ylim()
xx, yy = np.meshgrid(
np.linspace(xlim[0], xlim[1], 50), np.linspace(ylim[0], ylim[1], 50)
)
Z = clf.decision_function(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contour(
xx,
yy,
Z,
colors="k",
levels=[-1, 0, 1],
alpha=0.5,
linestyles=["--", "-", "--"],
)
plt.scatter(
support_vectors[:, 0],
support_vectors[:, 1],
s=100,
linewidth=1,
facecolors="none",
edgecolors="k",
)
plt.title("C="+str(C))
plt.tight_layout()
plt.show()
## C가 1일때 보다 C가 500일 때 마진과 반대 방향인 데이터가 더 많이 허용된다. 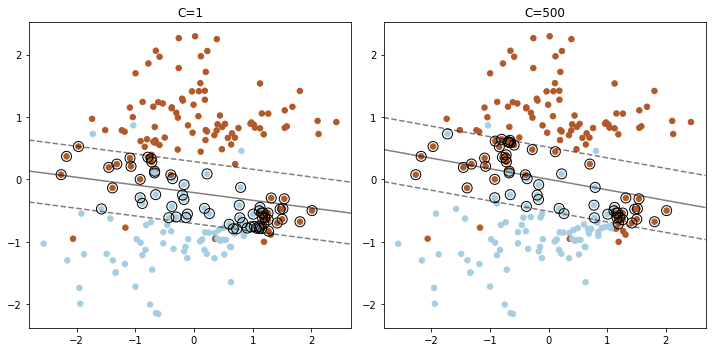
### 서포트 벡터 방식으로 회귀분석
import numpy as np
# 샘플데이터 생성하기
X = np.sort(5 * np.random.rand(40, 1), axis=0)
#1차원 배열로 변경
y = np.sin(X).ravel()
# 타깃데이터에 노이즈 추가하기
y[::5] += 3 * (0.5 - np.random.rand(8))
from sklearn.svm import SVR
# 회귀 모델 적합시키기 (가우시안, 선형회귀, 다항회귀)
svr_rbf = SVR(kernel='rbf', C=100, gamma=0.1, epsilon=0.1)
svr_lin = SVR(kernel='linear', C=100, gamma='auto')
svr_poly = SVR(kernel='poly', C=100, gamma='auto', degree=3, epsilon=0.1, coef0=1)
svr_rbf.fit(X, y)
svr_lin.fit(X, y)
svr_poly.fit(X, y)## 예측값 생성
rbf_pred=svr_rbf.predict(X)
lin_pred=svr_lin.predict(X)
poly_pred=svr_poly.predict(X)
from sklearn.metrics import mean_squared_error, mean_absolute_error, mean_squared_error
import pandas as pd
import numpy as np
## 성능평가지표 확인
preds = [rbf_pred, lin_pred, poly_pred]
kernel = ['rbf', 'Linear', 'Polynomial']
evls = ['mse', 'rmse', 'mae']
results=pd.DataFrame(index =kernel,columns =evls)
for pred, nm in zip(preds, kernel):
mse = mean_squared_error(y, pred)
mae = mean_absolute_error(y, pred)
rmse = np.sqrt(mse)
results.loc[nm]['mse']=round(mse,2)
results.loc[nm]['rmse']=round(rmse,2)
results.loc[nm]['mae']=round(mae,2)
results mse rmse mae
rbf 0.09 0.29 0.15
Linear 0.23 0.48 0.4
Polynomial 0.09 0.3 0.15## 세 가지 종류의 SVR 모형이 실제 데이터에 어떠한 형태로 적합되었는지 시각화
import matplotlib.pyplot as plt
lw =2
svrs = [svr_rbf, svr_lin, svr_poly]
kernel_label = ["RBF", "Linear", "Polynomial"]
model_color = ["m", "c", "g"]
fig, axes = plt.subplots(nrows=1, ncols=3, figsize=(15, 10), sharey=True)
for ix, svr in enumerate(svrs):
axes[ix].plot(
X,
svr.fit(X, y).predict(X),
color=model_color[ix],
lw=lw,
label="{} model".format(kernel_label[ix]),
)
axes[ix].scatter(
X[svr.support_],
y[svr.support_],
facecolor="none",
edgecolor=model_color[ix],
s=50,
label="{} support vectors".format(kernel_label[ix]),
)
axes[ix].scatter(
X[np.setdiff1d(np.arange(len(X)), svr.support_)],
y[np.setdiff1d(np.arange(len(X)), svr.support_)],
facecolor="none",
edgecolor="k",
s=50,
label="other training data",
)
axes[ix].legend(
loc="upper center",
bbox_to_anchor=(0.5, 1.1),
ncol=1,
fancybox=True,
shadow=True,
)
fig.text(0.5, 0.04, "data", ha="center", va="center")
fig.text(0.06, 0.5, "target", ha="center", va="center", rotation="vertical")
fig.suptitle("Support Vector Regression", fontsize=14)
plt.show()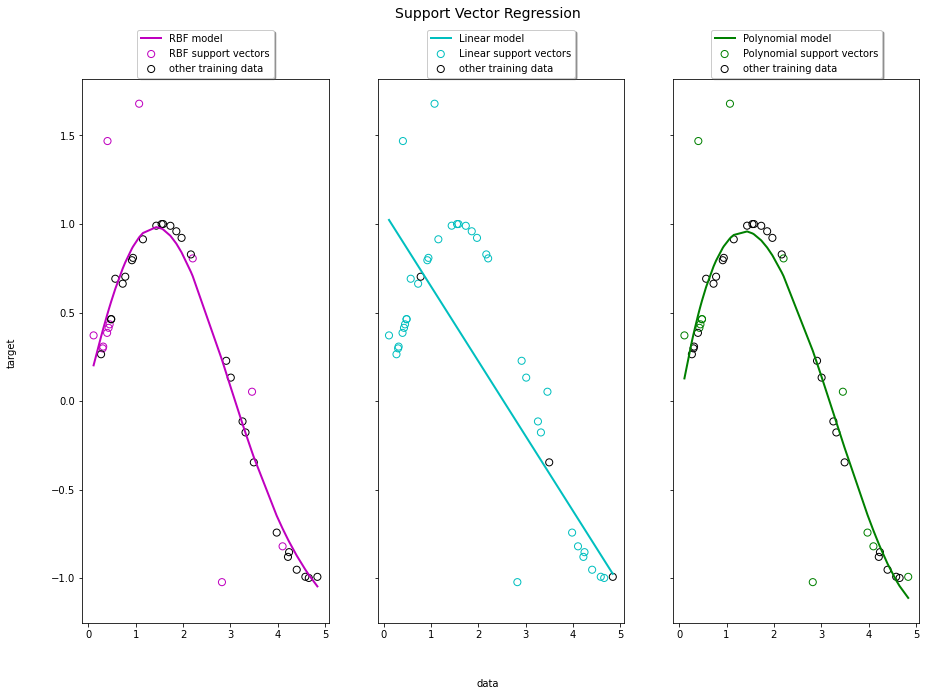

Just Enjoy Yourself