데이터 분석
1.데이터 전처리

이상치를 확인하는 방법은 여러가지가 존재한다. 일반적인 수치형 변수의 경우에는 IQR 방식을 이상치 판단 기준으로 사용할 수 있다. IQR(Inter Quantile Range)방식은 시각화에서 사용한 Boxplot의 이상치 결정 방법을 그대로 사용한 것이다. IQR의
2.데이터 전처리_2
범주형 변수는 값이 수학적 연산으로 모델을 생성하는 대부분의 분석 도구에서 직접 사용할 수 없기 때문에 특별한 처리 필요방법 중 하나로 더미변수화를 사용더미변수는 범주형 변수에 있는 범주 각각을 컬럼으로 변경하여 해당 범주에 속하는지 여부에 따라 0과 1로 채운 변수분
3.데이터의불균형
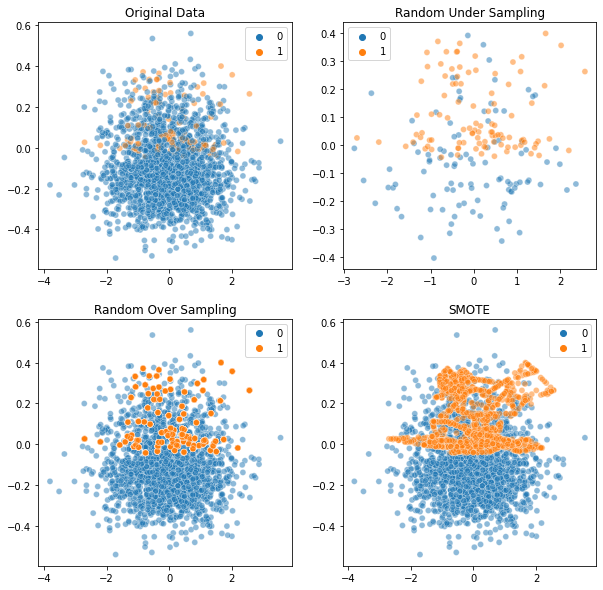
정상을 정확하게 분류하는 것과 이상을 정확하게 분류하는 것 중 일반적으로 이상을 정확히 분류하는것이 중요보통 이상 데이터가 target값이 되는 경우가 많다. 데이터가 불균형할 때는 분류의 성능과 Target 데이터를 정확히 분류해내는 목표가 일치하지 않게 되는 문제
4.회귀분석
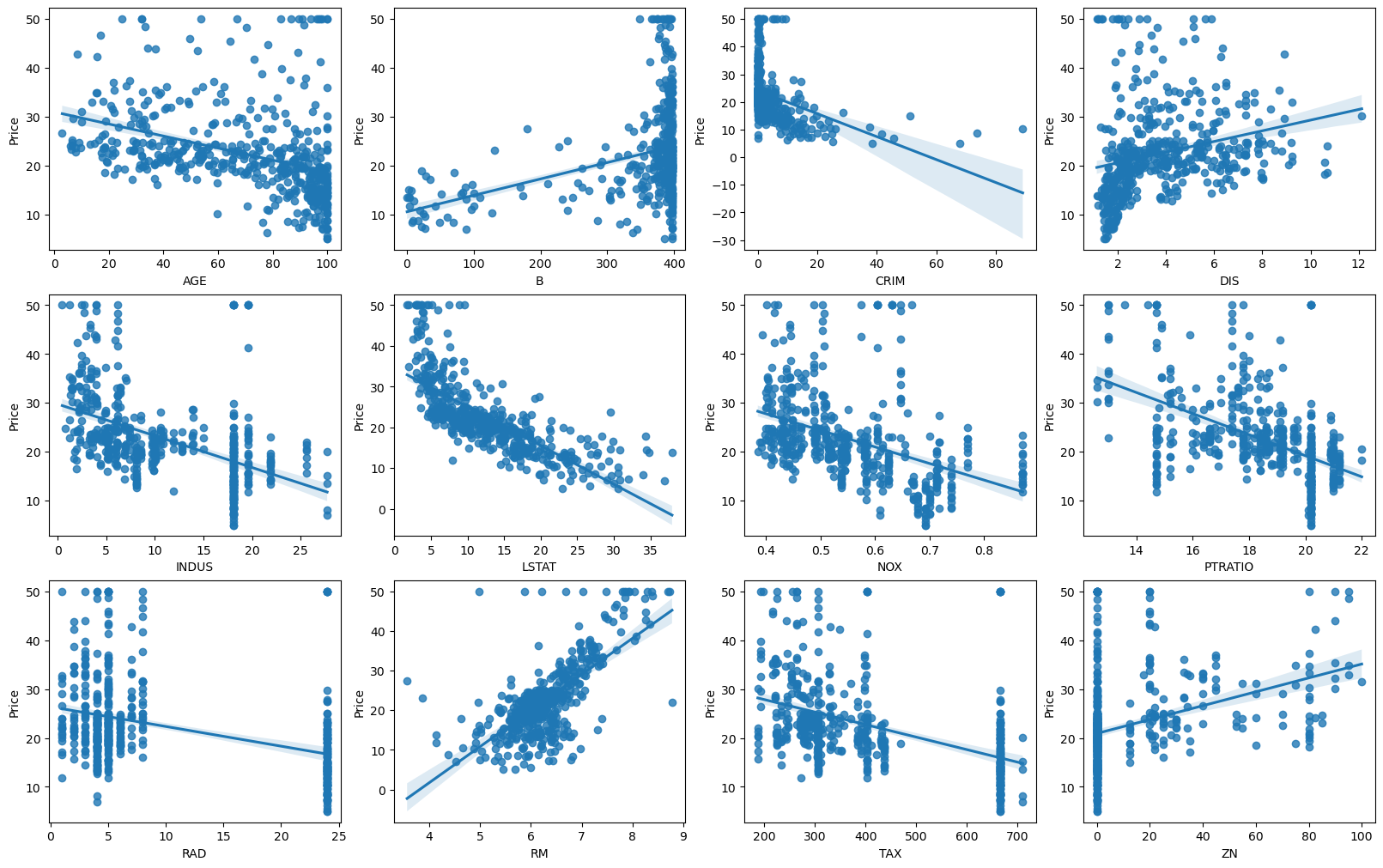
회귀 분석은 실젯값과 예측값의 차이를 기반으로 한 지표들을 중심으로 성능평가지표가 발전실젯값과 예측값의 차이를 구해서 이것들을 단순히 합하게 되면 +와 -가 섞여 오류를 상쇄할 수 있다. 실젯값과 예측값의 차이를 절댓값으로 변환해 평균한 것에러의 크기가 그대로 반영이
5.분류분석
실제분류와 예측분류가 얼마나 일치했는가를 기반으로 알고리즘 성능을 평가실제 데이터에서 예측 데이터가 얼마나 같은지 판단하는 지표데이터 구성에 따라 머신러닝 모델의 성능을 왜곡할 가능성이 존재이진 분류의 예측오류가 얼마이고 어떠한 유형의 예측 오류가 발생하고 있는지 나타
6.단순선형회귀
입력 특성에 대한 선형 함수를 만들어 예측을 하는 알고리즘독립변수가 하나인 경우 특정 직선을 학습하는 것선형 회귀 모델을 잘 한습시키려면 MSE(평균 제곱 오차)값을 최소화 하는 파라미터 선택통계적 방식의 회귀 분석은 정규방정식을 사용하여 문제를 해결머신러닝 모델에서는
7.다항 회귀
다항 회귀 데이터가 단순한 직선 형태가 아닌 비선형의 형태를 갖고 있을 때, 각 변수의 거듭제곱을 새로운 변수로 추가하면 선형 모델을 사용 가능 이렇게 확장된 특성을 데이터세트에 선형 모델로 훈련시키는 기법이 다항회귀 평가지표 값이 더 나아진것을 확인 할 수 있다.
8.다중회귀
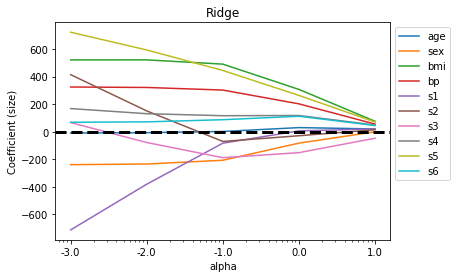
다중의 독립변수가 있는 회귀 분석여러 개의 독립 변수가 복합적으로 종속 변수에 영향을 미치는 경우 다중 회귀 모형으로 데이터를 표현 할 수 있다. 다중 회귀에서 최적 모델을 결정하기 위해 다양한 방법으로 변수를 선택모델이 복잡해지면 과대적합이 발생할 가능성이 있어 이를
9.로지스틱 회귀
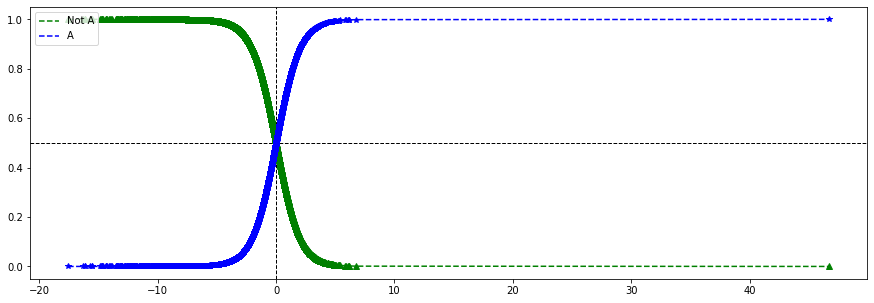
반응 변수가 범주형인 경우에 적용하는 회귀 분석을 로지스틱 회귀 분석이라 한다. 반응변수 Y를 직접 모델링 하지 않고 Y가 특정 범주에 속하는 확률을 모델링 한다.\[2768 246]정확도 85.19%정밀도 72.7%재현율 65.24%F1 68.77%2개 이상의 클래
10.서포트벡터머신
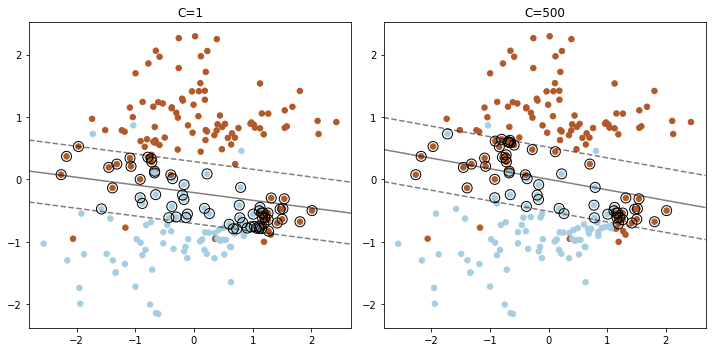
서포트 벡터 머신(SVM) 새로운 데이터가 입력되었을 때 기존 데이터를 활용해 분류하는 방법 패턴 인식, 자료 분석 등을 위한 지도 학습 모델로 회귀와 분류 문제 해결에 사용되는 알고리즘
11.배깅 부스팅
단일 결정 트리의 단점을 극복하기 위해 여러 머신 러닝 모델을 연결하여 더 강력한 모델을 만드는 방법주어진 자료로부터 여러 개의 예측 모형들을 만든 후 예측 모형들을 조합하여 하나의 최종 예측 도형으로 만드는 것대표적인 기법은 배깅, 부스팅, 랜덤포레스트주어진 자료를
12.랜덤포레스트
배깅과 부스팅보다 더 많은 무작위성을 주어 약한 학습기들을 생성한 후 이를 선형결합하여 최종 학습기를 만드는 방법정확도 : 0.8947368421052632\[102 5]정확도 89.47%정밀도 91.07%재현율 79.69%
13.데이터 인코딩
컴퓨터에서 인코딩이란 컴퓨터에서 연산이 가능하도록 범주형자료,명목형자료와 같은 변수를 0또는 1 로 인코딩하여 머신러닝 알고리즘에서 사용가능하도록 데이터를 변환하는 것사이킷런 머신러닝 알고리즘은 문자열 값을 입력 값으로 허용하지 않습니다. 그러므로 문자열 값들을 숫자
14.kfold,stratifiedKFold
iris data 를 통하여 간단한 실습해보겠습니다.kfold 114 115 116 117 118 119]평균 검증 정확도: 0.9416599999999999각 교차검증에서 사용된 index번호와 그때 accuray값을 통하여 평가최종 평균accuracy를 통하여 모
15.GridSearchCV
sklearn.model_selection.GridSearchCVclass sklearn.model_selection.GridSearchCV(estimator, param_grid, , scoring=None, n_jobs=None, refit=True, cv=None
16.Confusion_Matrics, precision, recall, precision_recall_curve
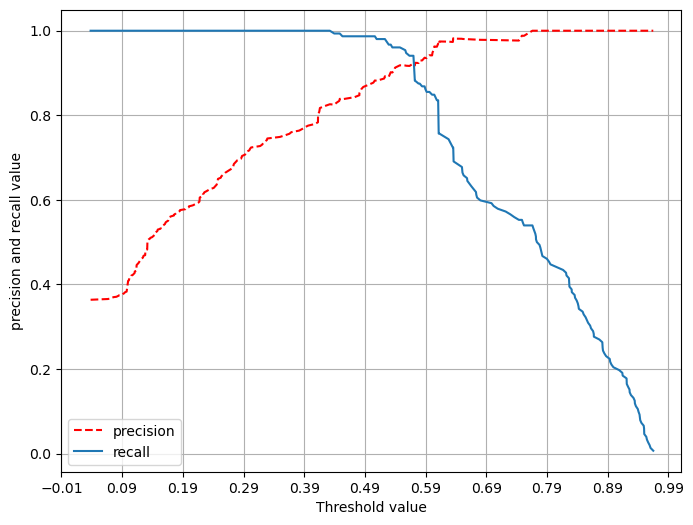
분류분석의 평가지표로 실제값과 예측값을 통하여 얼마나 잘 예측했는가를 평가할 수 있는 지표이다.실습을 통하여 확인해 보겠습니다.\[405 0]정확도: 0.9666666666666667정밀도: 1.0재현율: 0.6666666666666666분류알고리즘은 바로 labe
17.ROC_curve,AUC
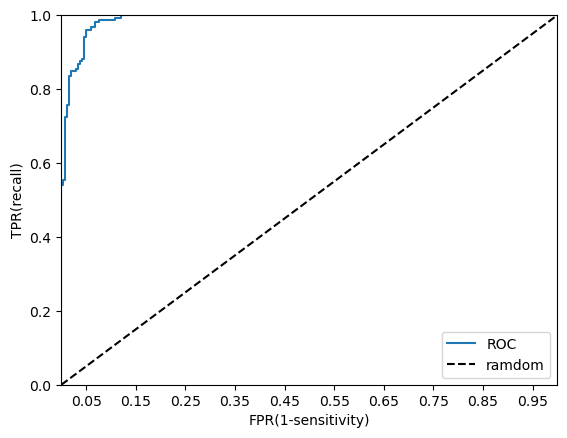
roc_curve 는 임계값을 변화함에 따라 fpr과 tpr의 변화를 나타낸 plot으로 y=x를 기준으로 위에그려지는 포물선을 보고 평가할 수있다이때 roc_curve밑에 값을 auc라고 하는데 이 auc값은 0.5보다 크고 1보다 작은 값으로 1에 가까울수록 좋다고