단순이동평활화
▪ 이동평균법(moving average method)
• 시계열을 평활화하는 가장 단순한 방법은 이동평균(moving average)을 사용하는
방법이다.
• 시계열 자료의 특정시점(a time point) 관측치와 이 관측치의 이전과 이후 관측치의
평균으로 대체하는 방법을 '중심이동평균'(centered moving average)라고 한다. 쉽
게 말해, 한 시점 앞 뒤 관측치를 평균내는 방법이다. 따라서 이동평균법을 하면 전
체 관측치의 개수가 줄어 든다.
• 예를 들어 n=3이면 3기간 단순이동평균(M3), n=5이면 5기간 단순이동평균(M5),
n=10이면 10기간 단순이동 평균(M10)이다
Simple Moving Average (SMA)
• 단순 이동 평균은 가장 일반적인 평균 유형이다.
• SMA에서는 최근 데이터 포인트의 합계를 수행하고 기간별로 나눈다.
• 슬라이딩 너비의 값이 클수록 데이터가 더 평활해지지만, 값이 크면 정확도가 떨
어질 수 있다.
• SMA를 계산하기 위해 pandas의 Series.rolling() 메서드를 사용한다.
import FinanceDataReader as fdr
df_apple = fdr.DataReader('AAPL',start = '2010')
# 가장 마지막의 10일치 주가 출력
df_apple.tail(10)
df_apple[['Close']].plot(figsize=(20,10))
last_day = datetime(2022,1,2)
df_apple.loc[last_day,"Close"] = np.nan
df_apple['Close_7Days_Mean'] = df_apple['Close'].rolling(7).mean().shift(1)
df_apple[['Close_7Days_Mean']].plot()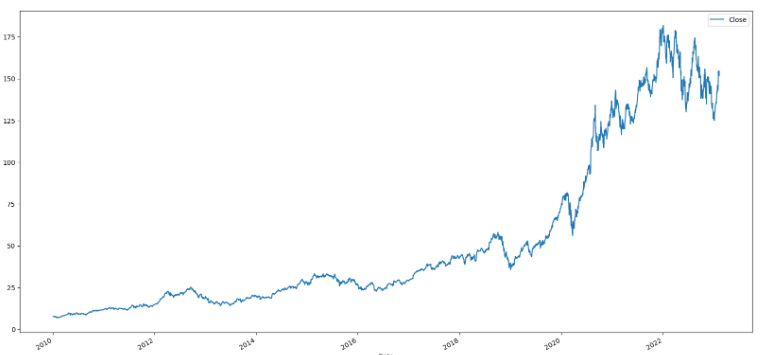
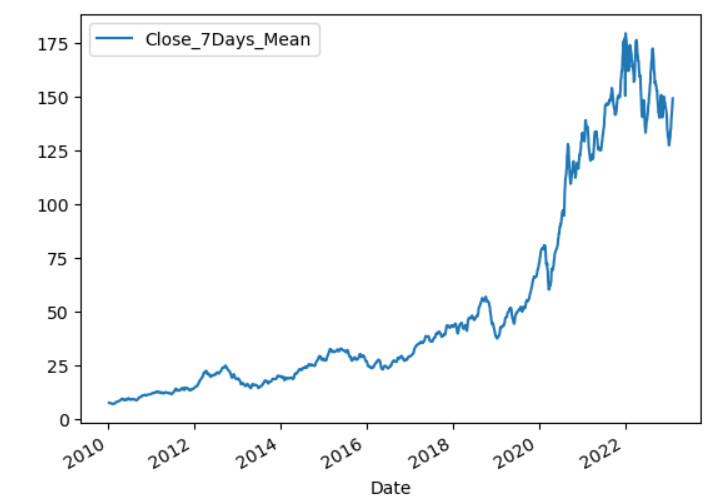
# pandas dataframe에는 resample이라는 데이터프레임의 시계열 인덱스 기준으로 샘플링을 편하게 해주는 메
# 소드가 있다. 아래와 같이 하면 월단위로 시계열 데이터를 다시 만들어 준다
# 월단위로 주식 가격의 평균을 샘플링
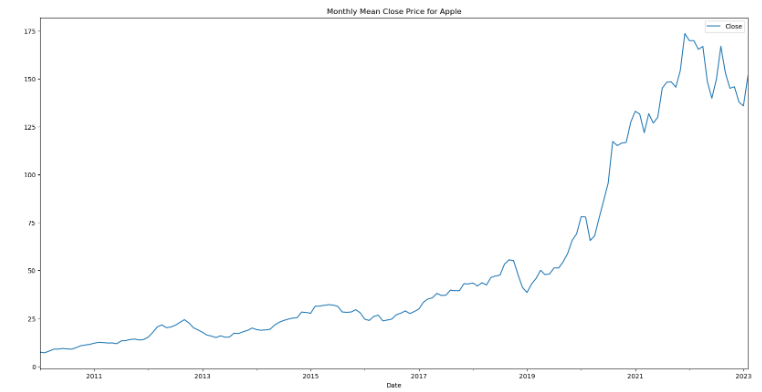
df_apple_monthly = df_apple.resample(rule='M').mean()
# 마지막 컬럼(Close_7Days_Mean) 제외
df_apple_monthly = df_apple_monthly.iloc[:,:-1]
# 월별 주가(종가)를 시각화
df_apple_monthly[['Close']].plot(figsize=(20,10))
plt.title('Monthly Mean Close Price for Apple')
df_apple_monthly[['Close_3Month_Mean']] = df_apple_monthly[['Close']].rolling(3).mean().shift(1)
df_apple_monthly[['Close', 'Close_3Month_Mean']].plot(figsize=(15,20))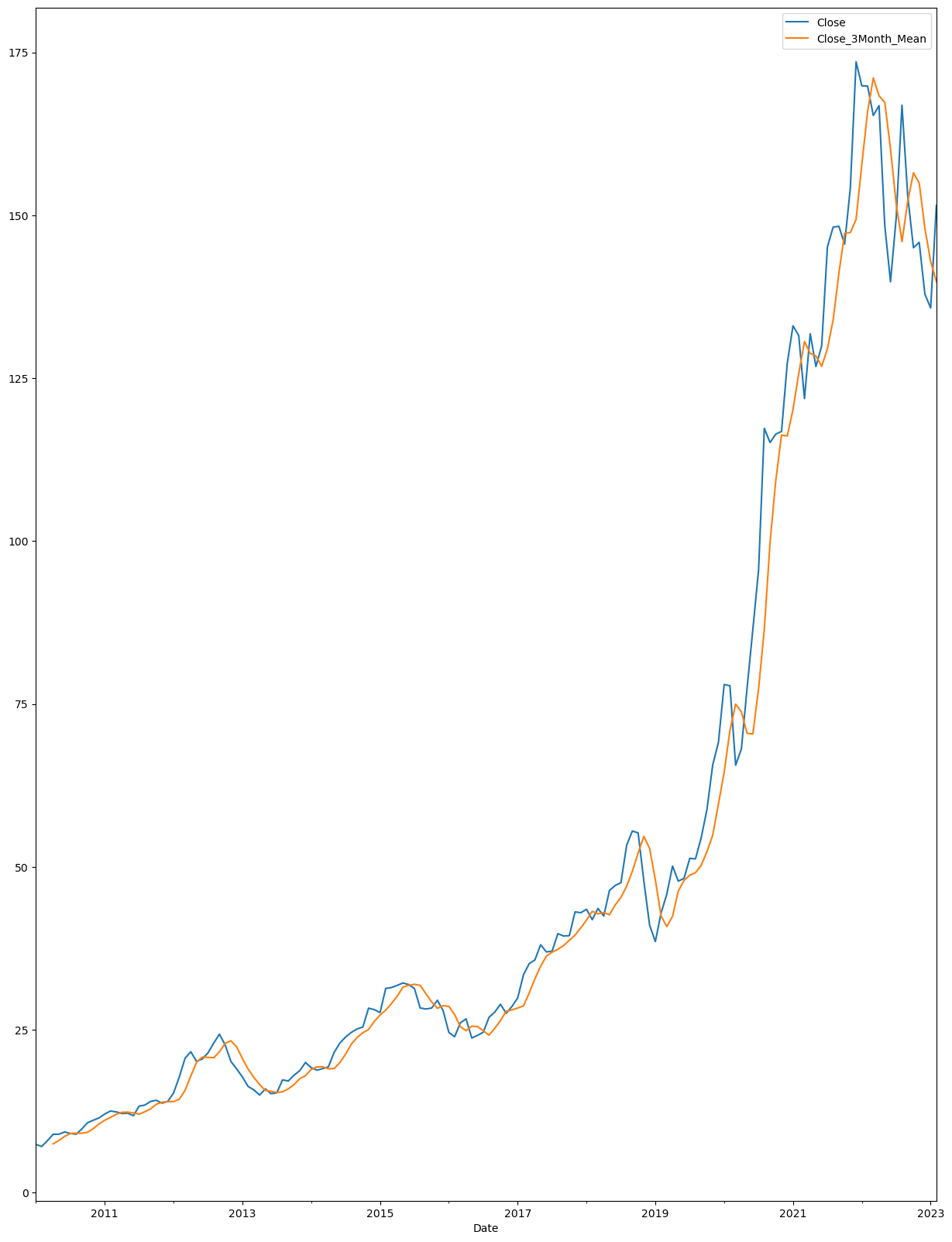
Exponential Moving Average (EMA)
• EMA는 새로운 데이터에 더 많은 가중치를 부여하여 최근 데이터에 더욱 초점을 맞
춘다.
• EMA의 주요 아이디어는 이전 데이터보다 최근 데이터를 더 선호하는 것이다.
• 데이터가 오래될수록 데이터에 할당된 가중치가 줄어듭니다. 이 때문에 EMA는 모
든 값에 동일한 가중치가 주어지는 SMA에 비해 추세 변화에 더 민감하다.
• SMA를 계산하기 위해 pandas의 pandas.Series.ewm() 메서드를 사용한다
import pandas as pd
data = {'val':[1,4,2,3,2,5,13,10,12,14,np.NaN,16,12,20,22]}
df = pd.DataFrame(data).reset_index()
# df['val'].plot.bar(rot=0, subplots=True)
df.plot(kind='bar',x='index',y='val')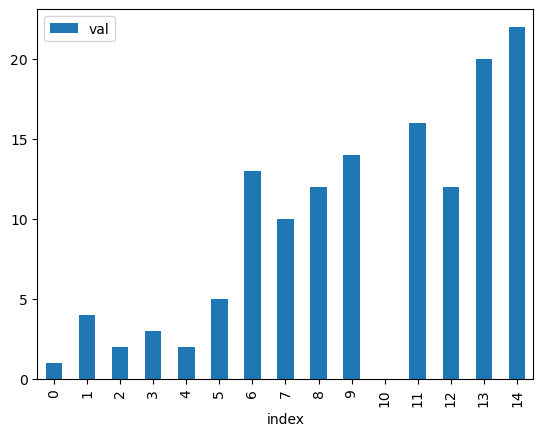
import matplotlib.pyplot as plt
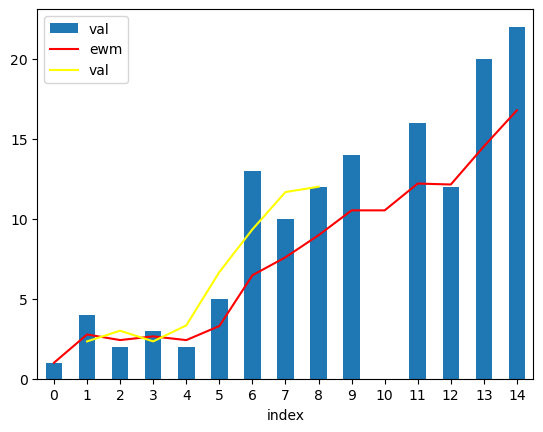
df2 = df.assign(ewm=df['val'].ewm(alpha=0.3,ignore_na=True).mean())
df3 = df.rolling(3).mean().shift(1).reset_index(drop=True)
# val열에 ewm 메서드적용 후 df에 추가
ax = df.plot(kind='bar',x='index',y='val') # ax에 df의 bar chart 생성
ax2= df2.plot(kind='line',x='index', y='ewm', color='red', ax=ax)
ax3= df3.plot(kind='line',x='index',y='val',color='yellow',ax=ax)
# ax2에 df2의 line chart 생성후 ax에 추가
plt.show() # 그래프 출력
Cumulative Moving Average (CMA)
• 누적 이동 평균은 SMA와 같이 현재 시간 't'까지의 모든 데이터의 평균이며 가중치
가 없는 평균이다.
• 모든 값에 동일한 가중치가 할당된다.
• 창 크기가 일정한 SMA와 달리 CMA에서는 창 폭이 지속 시간이 길수록 커진다.
• CMA를 계산하기 위해 pandas의 Series.expanding() 메서드를 사용한다
