Week11. Unsupervised Learning: Principal Component Analysis (PCA)
dimension reduction
to understand key features, the most variance in data set (high variance high importance)
visualization, data analysis
create new dimensional components that are combinations of proportions of the existing featrues; transformation
Theory and Intuition
-
Dimension Reduction
help visualize and understand complex data sets
act as a simpler data set for training data
reduce N features to a desired smaller set of components through a transformation, not simply select a subset of features -
Variance explained
Certain features are more important than other features
unlabeled data, determine feature importance?
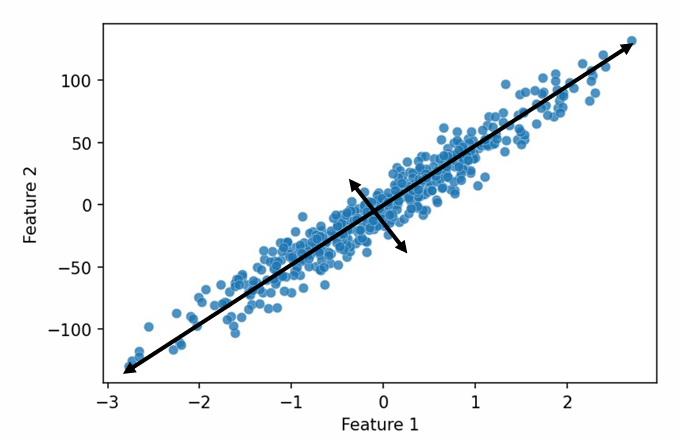

- Principal Component: a linear combination of original features
The more variance the original features accounts for, the more influence it has over the principal components
This single principal component can explain some percentage of the original data like 90%.
trade off some of the explained variance for less dimensions (low explained variance, low dimenstion)
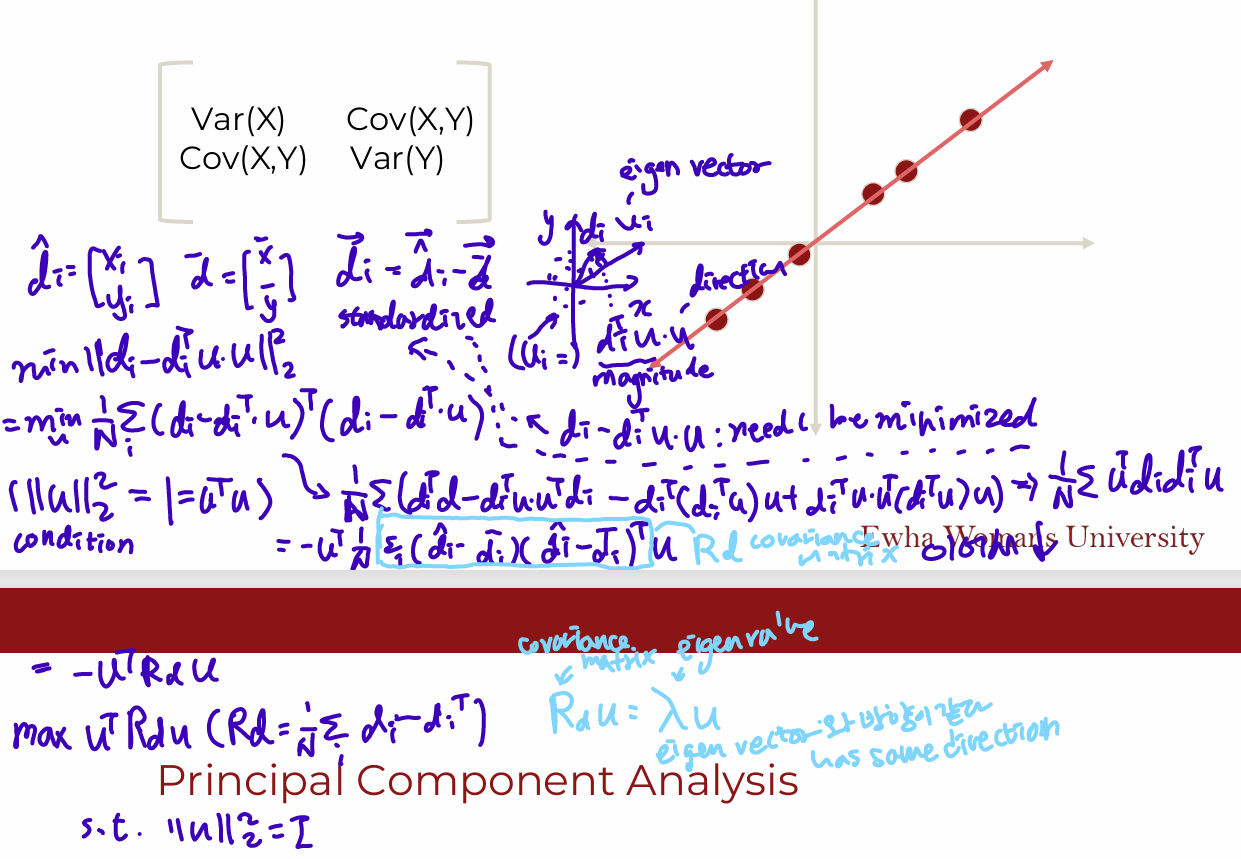
Math
creating a new set of dimensions (the principal components) that are normalized linear combinations of the original features
- standardize the data
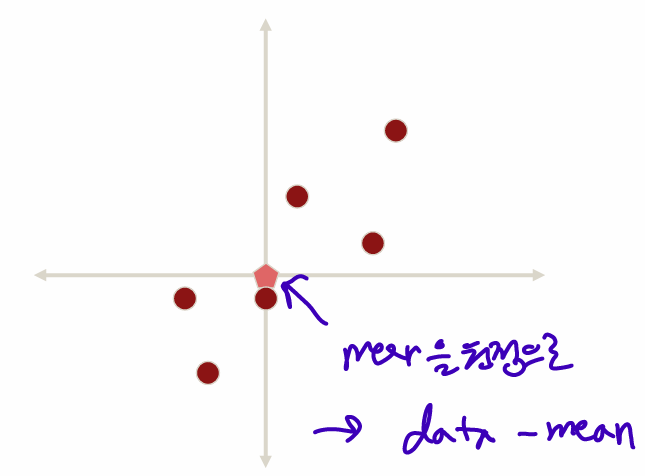
- Linear transformation of data
- EigenVector: Directional information
- EigenValue: Magnitude information
- Orthogonal Eigenvector
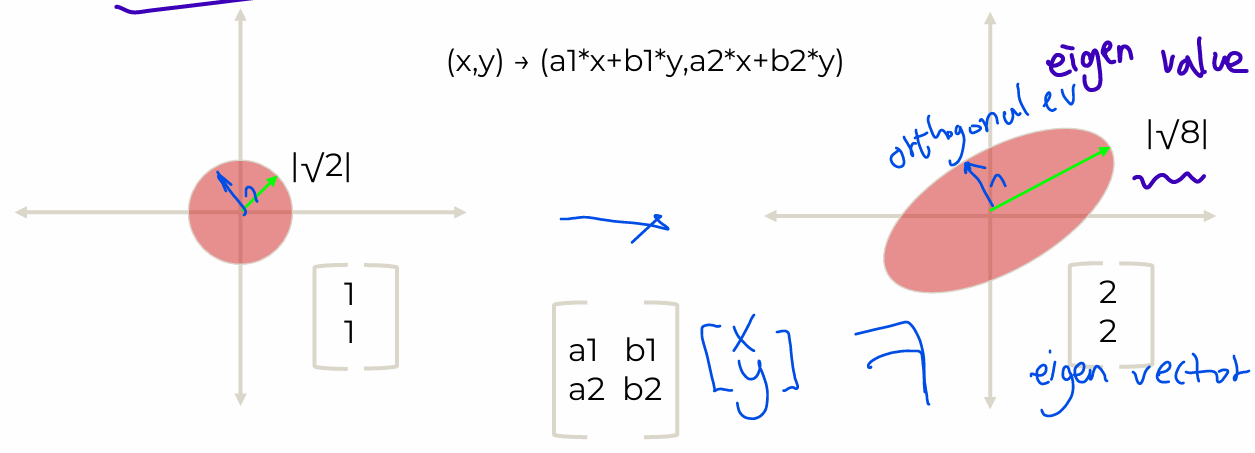
- Apply Linear Transformation
- EigenValue measures variance explained
PCA STEPS
○ Get original data
○ Calculate Covariance Matrix
○ Calculate EigenVectors
○ Sort EigenVectors by EigenValues
○ Choose N largest EigenValues
○ Project original data onto EigenVectors
Recap: PCA Steps
- Data preprcessing
replace - Ader normalization and optionally feature scaling,
- Compute "covariance matrix":
Sigma = - Compute "eignevectors" of matrix Sigma:
[U,S,V] = svd(Sigma);
Ureduce = (:, 1:k);
z = Ureduce'*x;
Background: Covariance
Measure of the “spread” of a set of points around their center of mass(mean)
- Variance: Measure of the deviation from the mean for points in one dimension
- Covariance: Measure of how much each of the dimensions vary from the mean with respect to each other
measured, relation between two dimensions
covariance between one dimension is the variance
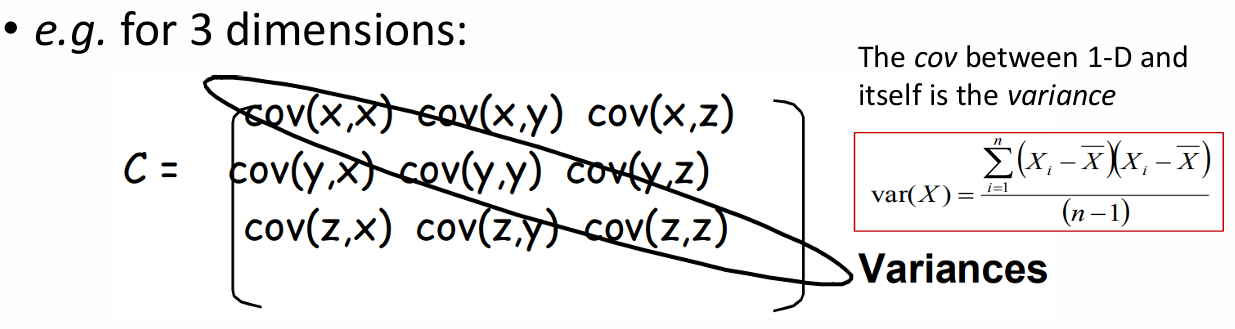
cov(x,y) = cov(y,x) symmetrical about the diagonal
N-dimensional data; NxN covariance matrix
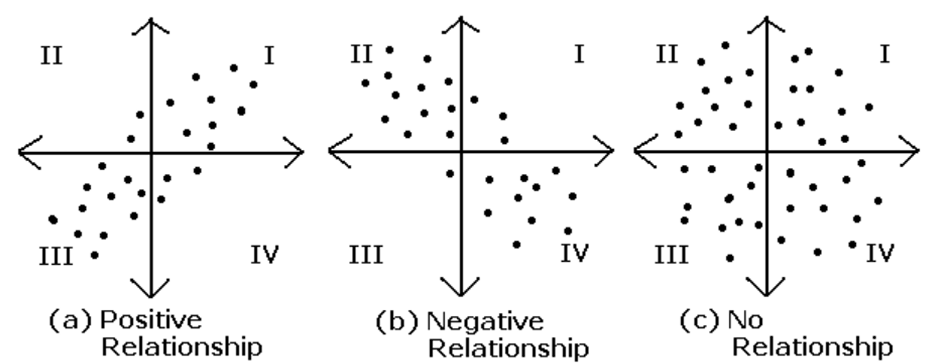
- value
positive value; both dimensions increase or decrease together
negative value; while one increases the other decreases
zero; two dimensions are independent of each other
PCA
PCA is used to simplify a dataset, reduce dimensionality by eliminating the later principal components.
It is a linear transformation that greatest variance comes to the first axis, the first principal component, the scond greatest variance on the second axis, and so on.
-
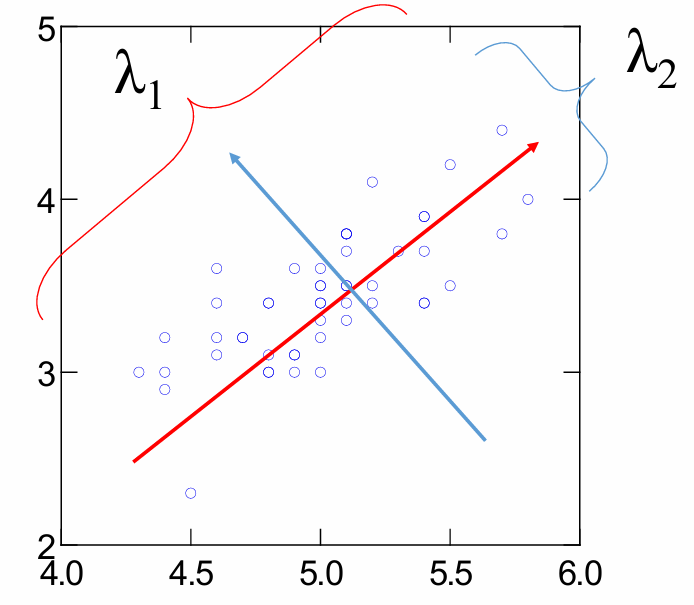
Principal components
First PC is direction of maximum variance from origin
Subsequent PCs are orthogonal to first PC and describe maximum residual variance -
Eigenvalues of the covariance matrix = Variances of each principal component
find largest eigenvalues
-
Application: face recognition and image compression, finding patterns in data of high dimension
PCA Theorem
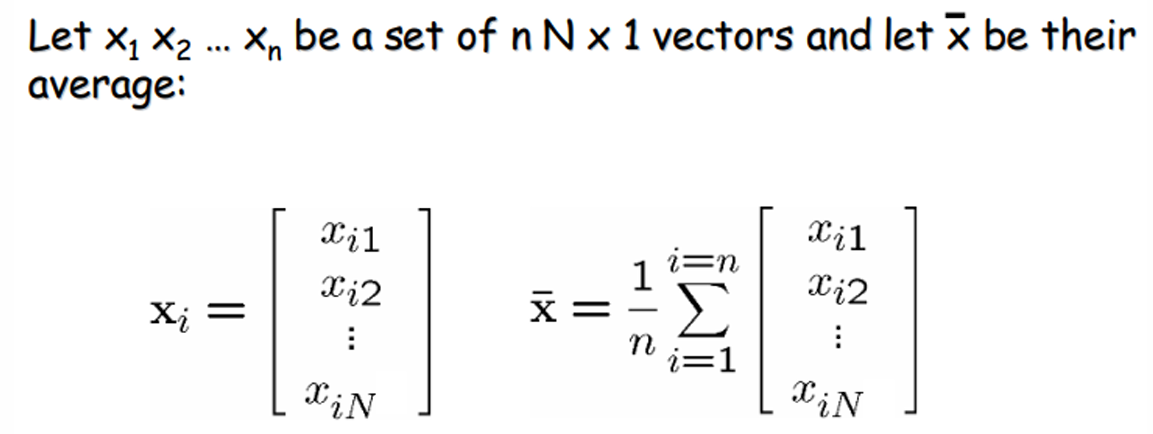
- Let X be the N x n matrix with columns:
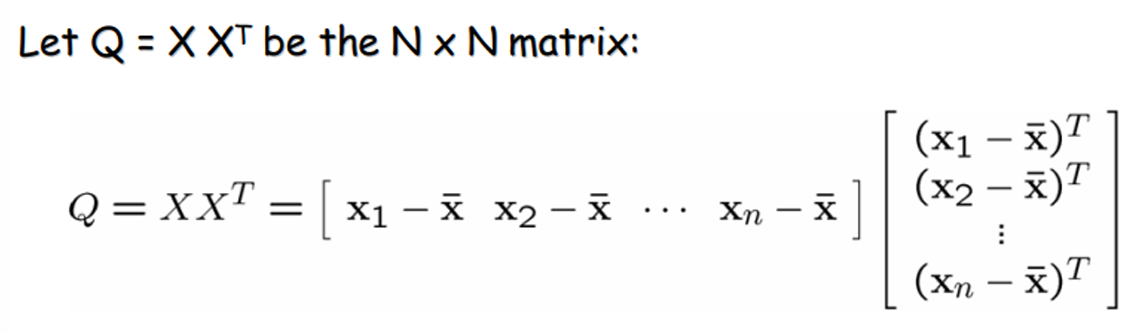
Q is square, symmetric, the covariance matrix(scatter matrix), can be very large


- Expressing x in terms of e1...en has not changed the size of data
However, if the points are highly correlated, x will be close to zero; they lie in a lower-dimensional linear subspace
PCA Example
-
Substract the mean
, mean으로 원점이동 -
Calculate the covariance matrix
cov =
Non-diagonal elements are positive; variable increases together -
Calculate the eigenvectors and eigenvalues of the covariance matrix
eigenvalues =
eigenvectors =
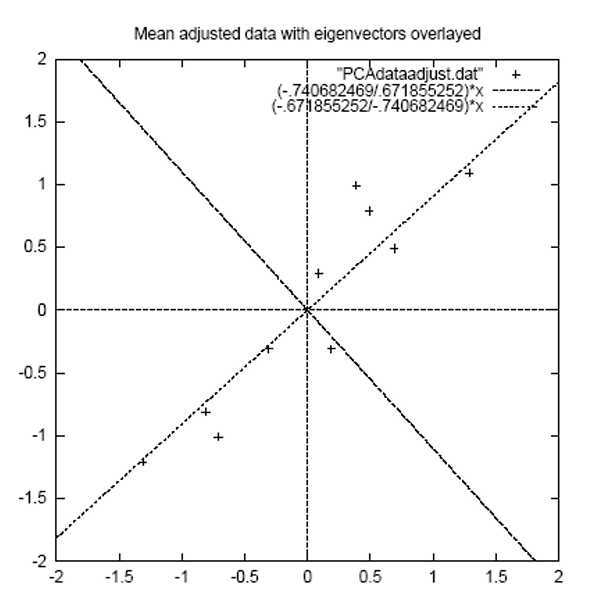
perpendicular to each other, first line is of best fit
- Reduce dimensionality and form feature vector
The eigenvector with the highest eigenvalue is the principal component of the data set.
Order eigenvectors by eigen value, highest to lowest, in order of significance.
Ignore the components of lesser significance, lose some information
choose only the first p eigenvectors; final data set has only p dimension
- Feature Vector = (eig1 eig2 eig3 ... eign)
leave out less significant component and only have a single column
to
- Deriving the new data
FinalData = RowFeatureVector x RowZeroMeanData
RowZeroMeanData = RowFeatureVector x Final Data
RowOriginalData = (RowFeatureVector x FinalData) + Original mean
RowFeatrueVector: eigen vectors in the columns transposed, eigenvecors in rows with the most significant eigenvector at the top
RowZeroMeanData: the mean-adjusted data transposed, data items in column, each row holding a seperate dimension
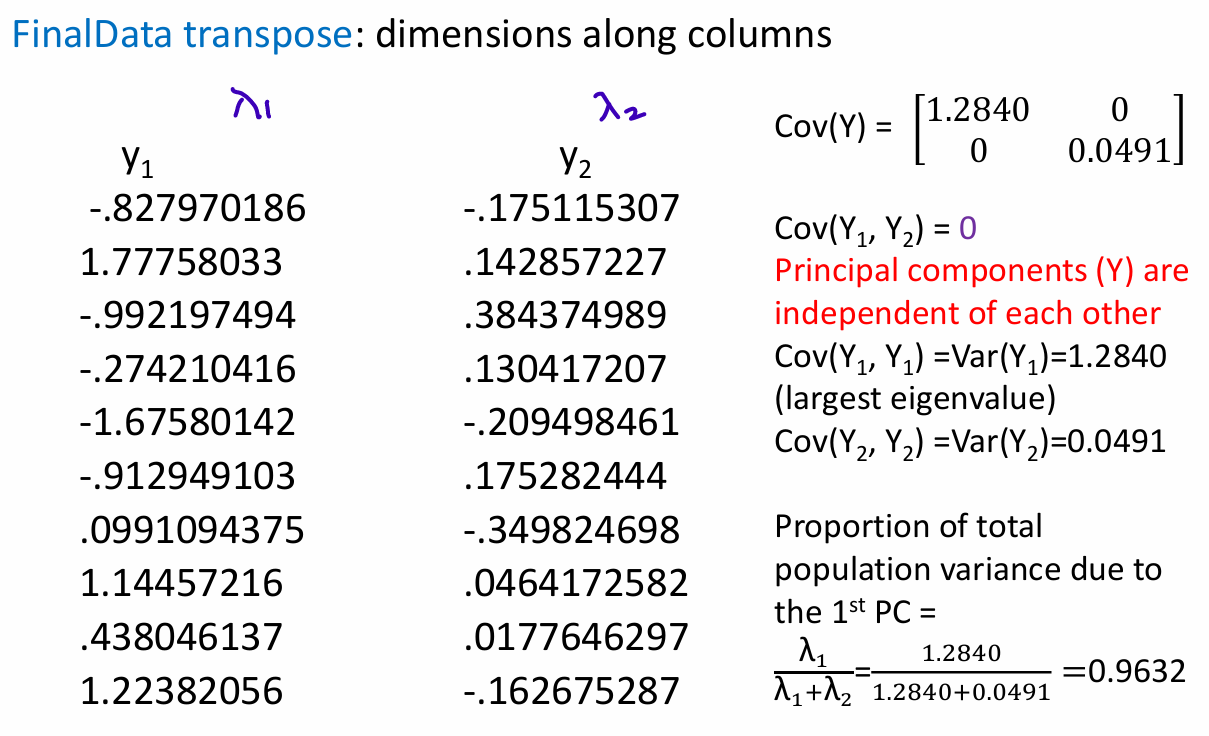
- FinalData transpose