1. Introduction
Tokens & Tokenization
-
Tokenization: The process of representing raw text in smaller units called tokens.
-
Tokens: Basic units created by a tokenizer that compose text
Tokenizers
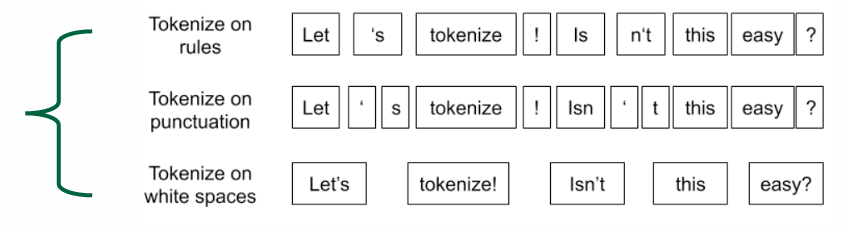
Using Whitespace is most intuitive tokenizing method but not always sufficient.
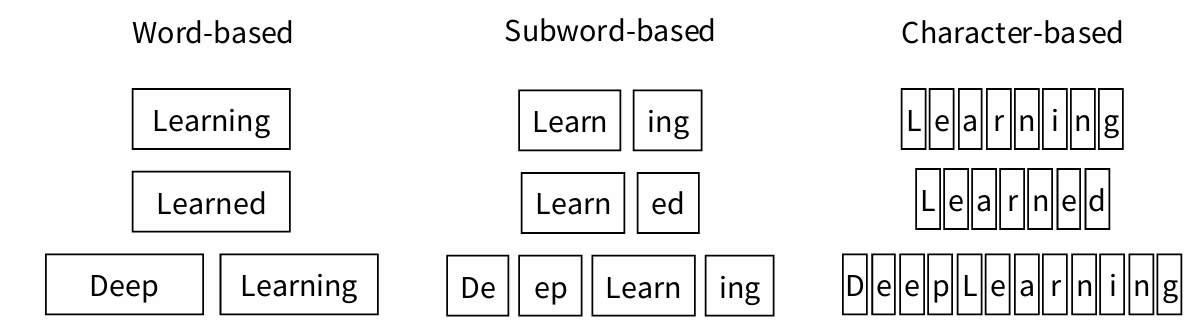
Granuarity in Tokenization
세분성
• Coarse-grained (words): compact, intuitive, vocabulary size ↑, potential change in vocab, the possibility of having unknown ([‘UNK’]) tokens
• Fine-grained (characters, bytes): lengthy, less meaningful, vocabulary size ↓, no change in vocab, almost no unknown tokens
• Subwords:in the middle of the two above, can be arbitrary substrings, or they can be meaning-bearing units like the morphemes -est or –er.
• c.f.) Morphemes are the smallest meaning-bearing units of a language.
Byte Pair Encoding(BPE)
: originally proposed as a data compression algorithm for tokenization, Attempts to find a sweet spot between expression ability and efficiency.
- Procedure
- Start with a vocabulary containing all individual characters.
- Using a corpus of text, find the two symbols that are most commonly adjacent.
- Replace instances of the character pair with the new subword; repeat until desired vocab size. (𝒌 merges create 𝒌 novel tokens)
→The final vocabulary consists of the original characters + 𝑘 new symbols
ex) aaabdaaabac(aa→Z) ZabdZabac (ab→Y) ZYdZYac(ZY→X) (XdXac)
- Pseudocode

Extra Text Preprocessing- Old fashioned
• Normalization
:Putting words/tokens in a standard format.
e.g.) ‘USA’, ‘United States’, ‘United States of America’, ‘States’ →‘USA’
• Case folding
e.g.) ‘NLP’, ‘nlp’, ‘Nlp’ → ‘NLP’
• Lemmatization
:Determining that two words have the same root, despite their surface differences.
e.g.) The words ‘am’, ‘are’, and ‘is’ have the shared lemma ‘be’.
c.f.) Stemming: ‘lower’ →‘low’
• Stopwords (removal)
:Common words that can be filtered out when processing text data.
e.g.) ‘a’, ‘the’, ‘is’, ‘in’, … (which appear frequently in text but are considered to have little meaningful information)
