2. Word Embedding
: Embedding -> Vector, Feature, Representation
the representation of words in the form of a real-valued number
Good word embedding encodes the meaning of the word such that the words that are closer in the vector space are expected to be similar in meaning
One-hot Encoding(Simple Indexing)
:Map tokens into a sequence of natural numbers.
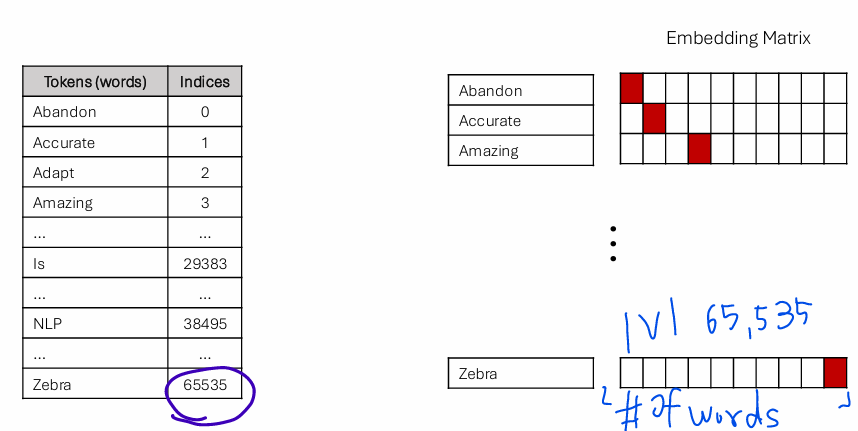
[UNK]: unknown token
Problems of One-hot Encoding
- Sparsity, Scalability, Curse of Dimensionality: most zero, vector dimension is linear to vocabulary size, high-dimension leads to overfitting, computational complexity
- Fixed Vocabulary: It cannot handle new words
- Limited Information: No notion of similarity between word vectors
Word2Vec: Skip gram & CBoW
Word 2 Vectors
: build a dense vector for each word- confined and restricted small vector space and encapsulates the semantic meaning of the word
- Intuition: Distributional semantics- A word w's context is the set of words nearby.
Overview
:Word2vec is a framework for learning word vectors.
Word2vec learns semantically meaningful, dense vector representations of target words based on the context provided by words in an internet corpus.
Every word in a fixed vocabulary is represented by a dense vector.
-
Strategy
• Go through each position 𝑡 in the text, which has a center word 𝑐 and context (“outside”) words 𝑜.
• Use the similarity of the word vectors for 𝑐 and 𝑜 to calculate the probability of 𝑜 given 𝑐 (or vice versa). - Skip-gram / Continuous Bag-of-Words (CBoW)
• Keep adjusting the word vectors to maximize this probability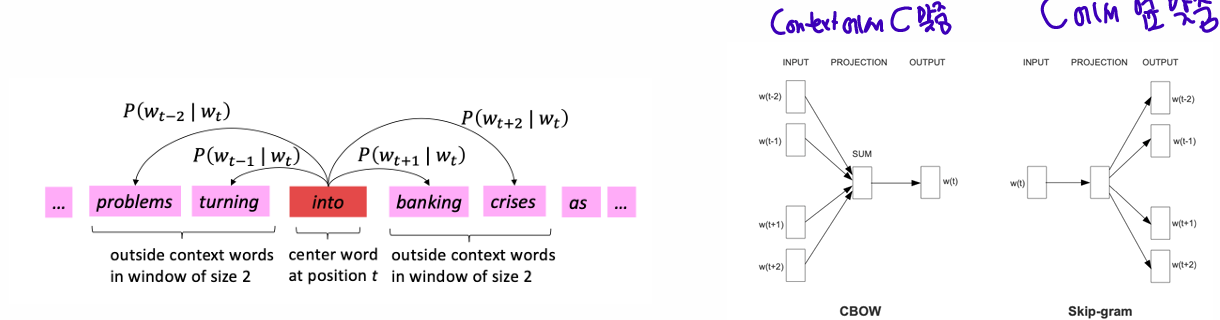
-
Terms:
• Window size (Context size): 𝑚 (2 in this case)
• Target word: (1 ≤ 𝑡 ≤ 𝑇) or 𝑐 for short (center)
• Context words: (𝑚 ≠ 0), or 𝑜 for short (outside)
• Parameters:
Objective Function
Objective of Skip-gram: Maximizing the likelihood of accurately predicting surrounding words given a specific target wor in a text corpus
-
Converting likelihood to objective function (loss,cost function):
The (average) negative log-likelihood:
-
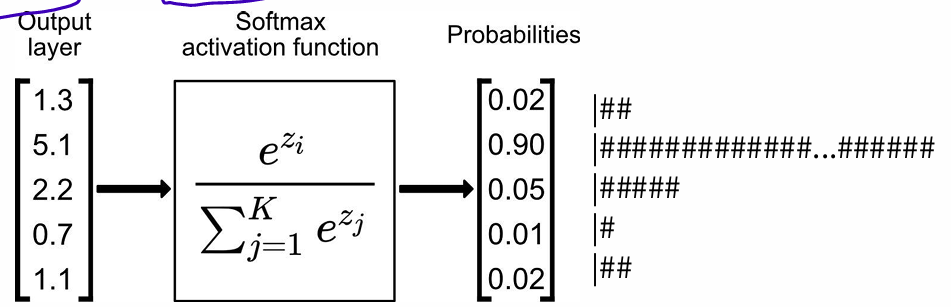
conditional probability: use two seperate word vectors per word w + Softmax function
for each word w: when w is a center word, when w is a context word
c: a center word c, o: a context word
softmax function:
or
: dot product compares similarity of o and c,
exponentiation makes anything positive
Normalize over entire vocabulary to give probability distribution
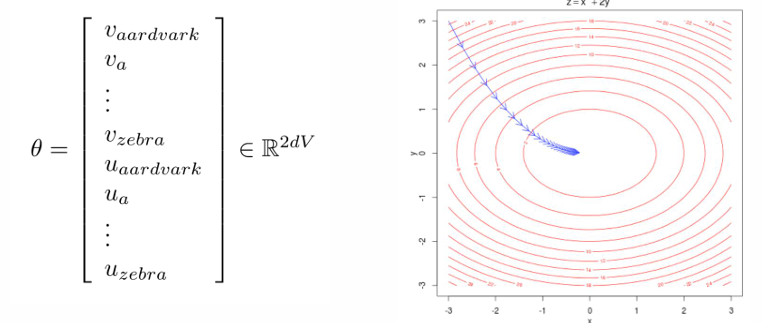
Optimization
Optimaize parameters to minimize loss by walking down the gradient
d-dimensional vectors and V-many words (every word has two vectors u, v)
Gradient Descent
: minimize ,
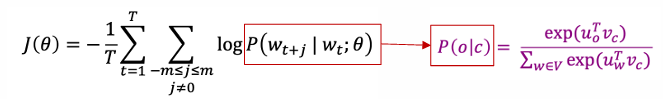
(for single parameter)
(in matrix notation)
repeat until converge
while True:
theta_grad = evaluate_gradient(J, corpus, theta)
theta = theta - alpha * theta_grad- Stochastic Gradient Descent
: Repeatedly sample windows and update after each one
while True:
window = sample_window(corpus)
theta_grad = evaluate_gradient(J, window, theta)
theta = theta - alpha * theta_grad- Derivation of Gradients (for center word parameters )
observed - expected
Word2Vec Algorithm Family: More detail
two vector (u, v): easier optimization, average both at the end (possible with one vector)
dimensionality d is usually set as 100 or 300
In the beginning, we initialize parameter randomly
Skip-Gram (SG)
Predict context (outside) words (position independent) given center word
• Its name comes from the fact that we predict a context word skipping over intermediate words.
Negative Sampling
: train binary logistic regressions to differentiate a true pair (center word and a word in its context window) versus several “noise” pairs (the center word paired with a random word).
- Objective function
: We maximize the probability of two words co-occurring in first log and minimize probability of noise words in second part.
-> the unigram distribution U(w) raised to the 3/4 power
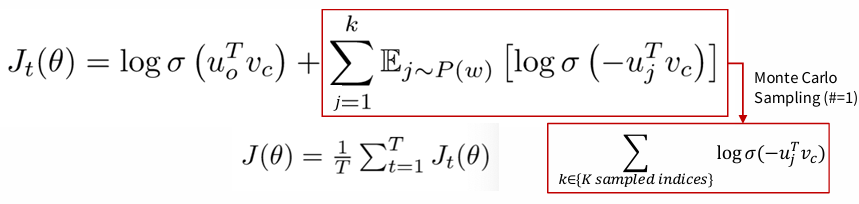
+) Word2Vec with Gensim: implementation of Word2Vec, p37
