[Paper & Code Review] (2009, UAI) BPR: Bayesian Personalized Ranking from Implicit Feedback
RecSys Paper
먼저 본 논문을 리뷰하기 전에 Loss를 계산하는 방법인 point-wise, pair-wise, list-wise에 대하여 간단하게 설명하려고 한다. 본 개념을 알고 들어가면 좋은 이유는 BPR이 pair-wise 방식으로 loss를 계산하는 방법이기 때문이다.
우선 point-wise는 loss를 계산할 때 한번에 1개의 아이템을 고려하는 방식으로, 간단하게 말하며 user가 item을 사용할 확률 값을 구하는 방식이라고 할 수 있다. 예를 들어 positive item과 negative item이 존재한다고 할 때, 우리는 BCE Loss를 사용하여 positive item을 선택할 확률은 1에 가깝게, negative item을 선택할 확률을 0에 가깝게 독립적으로 loss를 계산하여 각 아이템을 사용할 획률을 최적화 하게 된다. 그 후 전체 아이템에 대한 확률 값을 게산한 후 정렬하여 아이템의 순위를 매기게되는데, 이러한 방식이 point-wise라고 할 수 있다.
pair-wise는 Loss를 계산할 때 한번에 2개의 아이템을 고려하는 방식으로, 간단하게 말하면 positive item과 negative item이 주어졌을 때 positive item과 negative item을 loss 계산할 때 함께 사용하여 item에 대한 순위를 고려하는 것이다. 즉 pair-wise는 아이템의 Rank를 고려하여 모델을 학습시키는 방식이라고 할 수 있다.
list-wise는 Loss를 계산할 때 한번에 3개 이상의 아이템을 고려하는 방식으로, 간단하게 말하면 pair-wise의 확장판이라고 할 수 있다. item list가 주어졌을 때, item list 모두를 가지고 loss를 계산하여 item list 내에서 순위를 매기게 된다. 즉 list-wise는 pair-wise와 똑같이 아이템의 Rank를 고려하여 모델을 학습시키는 방식이지만, 고려하는 item의 수가 더 많다는 측면에서 다르다고 할 수 있다.
01. Introduction
- 본 논문은 개인화된 아이템 추천에 초점이 맞춰져 있음(개인화된 아이템 추천을 위해서는 아이템의 순위를 매기는 것이 중요함)
- 현실에는 Explicit feedback(평점 등) 보다 Implicit feedback(웹 로그, 클릭 등)이 더 수집하기 용이(인터넷에 접속만하면 log가 남기 때문에 자동으로 수집이 가능함)하고 그 양도 훨씬 많기 때문에 본 논문은 Implicit feedback를 활용하는 방법에 중점을 둠
- 그런데 선호가 반영되지 않은 Implicit feedback으로 개인화된 추천을 하는 것은 어려움
- 이에 본 논문에서는 Implicit feedback을 활용하여 개인화된 추천을 할 수 있는 generic optimization criterion BPR-Opt을 제안함
02. Related Work
- point-wise를 사용하는 모델은 오직 1개의 아이템만을 고려하여 모델이 학습하기 때문에 오직 1개의 랭킹만을 고려할 수 있음, 이러한 방식은 비개인화된 방식이라고 말할 수 있음
- 따라서 본 논문에서 제안하는 BPR-Opt을 사용하여 아이템의 랭킹을 고려할 수 있기 때문에, 개인화된 추천이 가능하다고 함
03. Personalized Ranking (본 논문의 핵심)
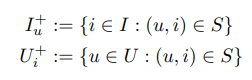
- Implicit feedback에서 관측된 데이터는 positive feedback으로 사용할 수 있고, Implicit feedback에서 비관측된 데이터는 유저가 그 아이템에 대한 흥미가 없는 실제 negative feedback과 유저가 미래에 구매할 가능성이 있는 missing value에 혼합이라고 할 수 있음
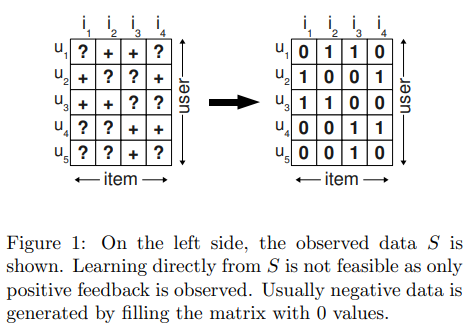
- Implicit feedback을 사용한 일반적인 접근법은 위 그림처럼 관측된 데이터는 1, 비관측된 데이터를 0으로 두고, 이를 유저의 아이템 대한 선호도 점수라고 생각하여 모델을 학습 시킴, 그 후 예측한 스코어 값을 정렬하여 아이템에 대한 랭킹을 매기게 됨
- 그런데 이렇게 모델을 학습시키면 문제가 모델이 0은 0을, 1은 1을 정확히 맞추는 것에 집중한다는 것
- 모델이 표현력이 풍부하다면 모든 데이터는 0과 1을 정확하게 맞추어 아이템의 순위를 제대로 구할 수 없게 됨
- 그럼에도 이러한 방식이 아이템의 순위를 매길 수 있는 이유는regularization과 같은 방법을 통해서 모델의 표현력을 제한하기 때문임
- 즉, 이러한 방식은 아이템의 순위를 구하는 것에 적합한 방식이 아니라고 할 수 있음(구해진 아이템 순위는 올바르지 않기 때문에 개인화된 아이템 추천에 적합하지 않음)
- 따라서 본 논문은 아이템에 대한 순위를 구하는 것에 초점이 맞춰진 모델 최적화 방식을 제안함
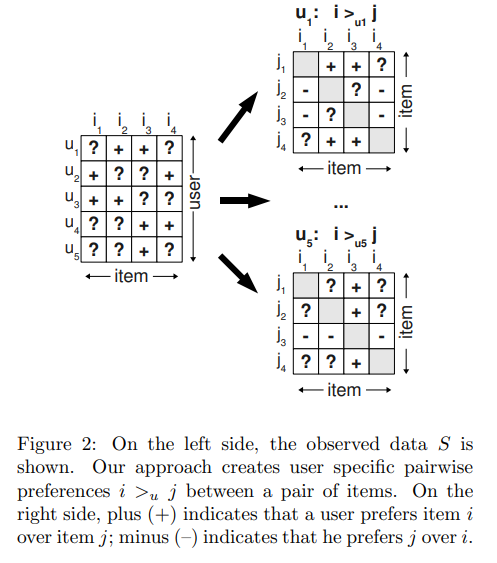
- 본 논문에서 제안하는 방식도 Implicit feedback에 관측된 데이터를 positive로, 비관측된 데이터를 negative로 보는 것은 동일함
- 그러나 활용하는 방식에서 차이가 존재함 (점수 중심이 아니라 순위 중심)
- 본 논문은 point-wise의 일반적인 접근법과 달리 pair-wise의 방식으로 모델을 학습시킴
- 위 그림 처럼 item 쌍을 활용하고 관측된 아이템이 비관측된 아이템 보다 선호한다는 가정으로 모델을 학습시킴
- 예를들어 전체 아이템 i1 ~ i4 중에 u1에 관측된 아이템이 i2와 i3이라고 한다면, i2와 i3은 i1과 i4보다 u1이 더 선호하는 아이템이라고 할 수 있음, 그러나 관측된 아이템인 i2와 i3 사이에는 선호의 우열을 가릴 수 없음, 반대로 i1과 i4에 대해서도 마찬가지임
- 따라서 모델을 학습시킬 때 아이템 쌍은 무조건 관측된 아이템과 비관측된 아이템으로만 구성하여 단순히 관측 아이템과 비관측 아이템 사이에 선호도의 우열, 즉 순위를 매기는 것에 모델이 집중하게 만듬(i2에 대한 순위를 학습 시킬 때는 i1과 i4 아이템만을 고려)
- 이러한 학습 방식은 단순히 아이템에 대한 선호도를 매기는 것에 집중하는 것이 아니라(일반적인 방식의 score 계산) 관측된 아이템은 관측되지 않은 다른 아이템보다 선호한다는 느낌으로 아이템의 순서를 매기는 것에 집중하여 개인화된 추천에 걸맞는 최적화 방법이라고 할 수 있음
- 개인적으로 추천은 아이템에 대한 선호도보디 해당 아이템을 유저에게 보여주는 순위가 더 중요하다고 생각하기 때문에 추천에 적합한 최적화 방법이라고 생각함(보통 아이템 1개를 추천해주는 것이 아닌 여러개의 아이템을 추천해주기 때문에)
04. Bayesian Personalized Ranking (BPR)
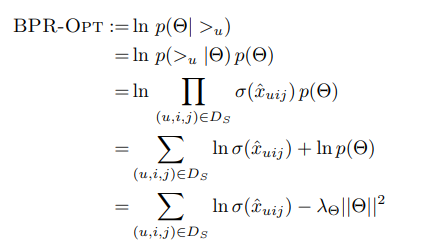
- 본 논문의 핵심은 이미 다루었기 때문에 이부분은 Loss 계산에 대해서만 설명하겠음
- BPR-Opt는 위에 나온 loss 식을 최대화 하는 방향으로 모델을 학습시키는 것임
- 위 loss 식을 간단하게 풀어쓰면 단순히
log(sigmoid(pos - neg)) - 규제로 구성됨 - 식의 앞 부분은 sigmoid 함수는 값을 0 ~ 1 사이로 만들어주고, log 함수는 0 ~ 1 사이의 값을 -무한 ~ 0의 범위의 값으로 만들어주기 때문에 위 식은 -무한 ~ 0 사이의 값을 가지게 됨
- 여기서 우리는 이 값을 최대화 하는 것이 목표이기 때문에 0에 가깝게 식이 구성되어야 할 것임
- 이 식이 0에 가깝게 구성되기 위해서는 sigmoid 값이 1에 가까워야 하고 sigmoid 값이 1에 가깝게 되기 위해서는 pos - neg 의 값이 양수의 값을 가져야함
- pos - neg 의 값이 양수의 값을 가지기 위해서는 pos는 양수로 neg는 음수의 값을 가져야 함, 즉 pos와 neg는 서로 완전히 반대의 방향을 가지도록 모델을 학습시켜야함(이러한 성질이 pos와 neg 사이에 순위를 정하게 됨)
- 그런데 우리는 본 loss를 최적화 시킬 때 Stochastic Gradient Descent, 즉 확률적 경사하강법을 사용하기 때문에 우리의 목적에 맞게 식을 수정하여 최종적으로 양수의 범위를 갖게 loss 식을
-log(sigmoid(pos - neg)) + 규제로 수정하여 모델을 학습시킴(최대화 문제를 풀기 위해 -를 붙여서 최소화 문제로 바꿈) - 여기서 규제는 당연히 SGD 방식을 활용하여 모델의 파라미터를 업데이트 하기 때문에 모든 점에서 미분이 가능한 L2 norm을 사용하여 모델의 표현력을 제한함
- 따라서 본 loss는 pos와 neg는 서로 최대한 멀어지게 학습하면서, 비슷한 latent space를 가지는 item 끼리는 가깝게 하여 아이템의 순위를 매기는데 최적화된 Loss라고 할 수 있음
05. Conclusion
- 본 논문은 개인화된 순위를 매기는 것에 적합한 BPR-Opt를 제안함
- BPR-Opt는 베이지안 분석에 기반한 사후 확률 최대화 문제를 사용함
- 반대로 말하면 BPR-Opt는 개인화된 순위를 매기는 것은 적합하지만 개인의 선호도를 맞추는 문제에는 적합하지 않다고도 말할 수 있음(그런데 직접 실험한 코드의 HR을 보면 더 좋은 성능을 보여주기는 함)
Code
Reference

깔끔한 설명입니다! 감사합니다~