[Paper & Code Review] (2018, WSDM) Personalized Top-N Sequential Recommendation via Convolutional Sequence Embedding
RecSys Paper
목록 보기
4/9
1. INTRODUCTION
- 이 논문이 나오기 전에 대부분의 top-N recommendation은 user’s general preferences에 기초하여 추천이 이루어짐
- user’s general preferences란, 간단하게 말하면 삼성 제품을 좋아하는 사람에게는 삼성 제품을, 애플 제품을 좋아하는 사람에게는 애플 제품만을 추천하는 것으로, 유저의 정적인 행동 정보만이 반영된 선호라고 할 수 있음
- 그런데 단순히 user’s general preferences에만 집중하게 되면 우리는 iPhone을 산 유저에게 핸드폰 악세사리를 추천해줄 기회를 잃게 됨(유저에게 단순히 iPhone과 관련된 아이템만 추천해줄 것임)
- 따라서 유저의 행동 정보인 sequential pattern을 모델링 하여, 유저에 최신 행동 정보에 기반한 추천을 함으로써 우리는 이러한 기회를 잃지 않을 수 있도록 해야함
- 본 논문은 sequential pattern을 모델링 하여 가까운 미래에 유저가 살만한 아이템을 추천해주는 방법에 대하여 다룸
1) Top-N Sequential Recommendation
- 본 논문에서 다루는 Top-N Sequential Recommendation은 아이템의 집합을 사용하는 것이 아닌, 유저의 행동에 기반한 아이템의 sequence를 가지고 모델링하는 것을 말함(ex, 만약 유저가 1, 2, 3, 4, 5 라는 구매 기록이 있다면 아이템 집합을 1, 2 ,3 / 2, 3, 4 / 3, 4, 5등 으로 sequence하게 만들 수 있음)
2) Limitations of Previous Work
- Markov chain based model은 top-N sequential recommendation을 위한 빠른 접근법이지만, 2가지 한계를 가지기 때문에 본 논문에서 제안하는 Caser 보다 성능이 좋지 않다고 본 논문에서는 말함
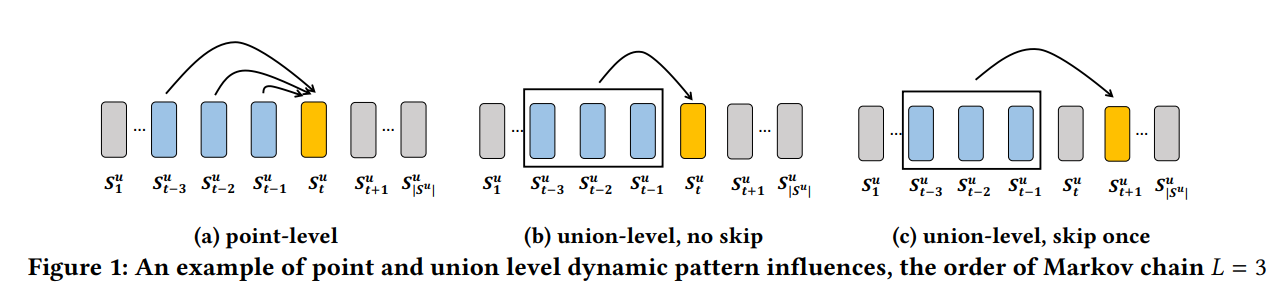
- 1) Markov chain based model은 오직 point-level sequential pattern만을 모델링 할 수 있다고 함 (Fail to model union-Level sequential patterns)
- 예를 들어서 우리가 밀가루를 산다고 가정할 때, 우유와 버터를 각각으로 모델링하여(point-level) 밀가루를 예측하는 것보다, 우유와 버터를 같이 모델링하여(union-Level) 밀가루를 예측하는 것이 확률적으로 더 높은 값을 가질 것임
- 2) Markov chain based model은 유저 행동을 건너뛸 수 없다고 함(Fail to allow skip behaviors)
- 예를 들어서 유저가 공항, 호텔, 레스토랑, 바, 명소 순으로 체크인을 한다고 할 때 명소는 레스토랑과 바와는 강한 연관성을 가지지는 않지만(명소 체크인 전에 무조건적으로 발생하는 행동이 아닐 수 있음), 공항과 호텔은 명소와 강한 연관성을 가질 수 있음
- 따라서 중간에 필요 없는 행동들은 skip 함으로써 조금 더 유저의 sequential pattern을 더욱더 잘 모델링 할 수 있다고 함
- 그리고 sequential pattern을 구성할 때 연관 규칙 분석의 support, confidence를 사용한다면 더 좋은 성능을 보일 수 있다고 함
3) Contributions
- 본 논문에서 제안하는 ConvolutionAl Sequence Embedding Recommendation Model, Caser은 다음과 같은 장점을 가진다고 함
- 1) 수평, 수직의 convolutional filter를 사용하여 point-level, union-level, skip behavior의 sequential pattern을 capture 할 수 있음
- 2) users’ general preferences, sequential patterns을 모두 모델링 할 수 있다고 함
- 3) top-N sequential recommendation에서 SOTA의 성능을 보였다고 함
2. FURTHER RELATED WORK
- 이 부분은 그냥 CF, MF 모델 등과 Caser의 차이를 이야기하는 부분이기 때문에 생략함
3. PROPOSED METHODOLOGY
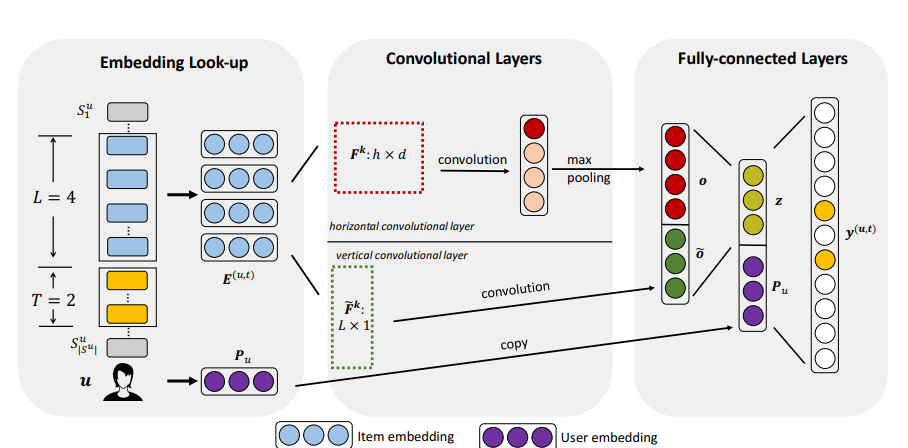
- Caser은 CNN을 사용하여 sequential feature을 학습하는 모델
- Caser은 Embedding을 학습하는 Latent Factor Model
- Caser은 그림과 같이 Embedding Look-up, Convolutional Layers, Fully-connected Layers로 이루어짐
- Caser의 train Data의 구조는 (u, L item, T item)이고, 유저 u가 과거 행동 정보인 L item을 이용해 미래의 행동 정보인 T item을 예측하는 방식으로 모델 학습이 이루어짐
1) Embedding Look-up
- latent factor와 비슷한 개념으로 우선 d 차원의(latent factor) Q(item), P(User) Embedding Table 을 만듬
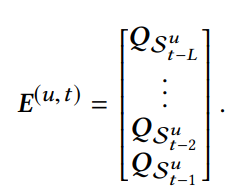
- 그리고 유저 u의 과거 행동 정보인 L sequence에 존재하는 item들의 임베딩을 stack하여 학습에 사용할 최종 Embedding matrix E를 만듬(유저의 과거에 구매한 아이템들의 정보가 담겨진 Embedding이라고 할 수 있음)
2) Convolutional Layers
- 앞에서 만들어진 Embedding matrix E를 image로 생각하여 Convolutional Layers을 이용해 sequential patterns에 대한 정보를 cature함
- 사용된 Convolutional Layer로는 Horizontal Convolutional Layer와 Vertical Convolutional Layer가 있음
(1) Horizontal Convolutional Layer

- Horizontal Convolutional Layer은 union-level patterns에 대한 정보를 capture하는데 사용됨

- h x d 크기의(d는 Embedding size) 필터를 k개 만들어 1개의 Horizontal Convolutional Layer가 만들어짐 (즉 1개의 Layer는 K의 차원으로 변형됨)
- h의 경우는 {1....L}로 이루어져있기 때문에 Horizontal Convolutional Layer 총 개수는 L개라고 할 수 있음(L은 과거의 유저의 행동 정보의 sequence의 길이임)

- 위 처럼 하나의 레이어는 convolutional 연산을 거쳐서 k개의 c 벡터가 만들어짐
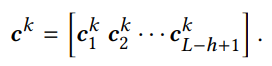
- 만들어진 c 벡터는 L - h + 1 개의 row를 가지게 됨(합성곱 연산에 따른 아웃풋 이미지 크기 계산임)

- 이 c벡터에 max pooling을 적용하면 1개의 value만 남고 이를 각 필터마다 적용을 하게 되면, 최종적으로 하나의 Layer의 output 차원은 필터의 크기인 k(위 그림은 n으로 표시됨)가 됨
- 그런데 여기서 중요한 것은 각각의 Horizontal Convolutional Layer는 연속적인 것이 아닌 독립적으로 이루어져 있음, 따라서 각 Horizontal Convolutional Layer에 k 값인 n은 다 다를 수 있음
- 따라서 최종 Horizontal Convolutional Layer의 output 차원은 n * L 이됨(모든 Horizontal Convolutional Layer의 k 값이 같다는 전제)
(2) Vertical Convolutional Layer
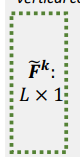
- Vertical Convolutional Layer은 point-level sequential patterns에 대한 정보를 capture하는데 사용됨(수직 필터가 Fossil과 비슷하게 weighted sum에 역할을 하기 때문에)
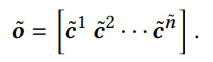
- Vertical Convolutional Layer은 L x 1 크기의 k개의 필터로 이루어져 있어, 필터 1개의 아웃풋의 크기는 d 차원임
- 따라서 Vertical Convolutional Layer의 아웃풋은 d x k의 크기를 가짐
3) Fully-connected Layers
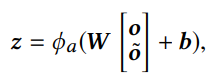
- 우선 2개의 Convolutional Layer에 나온 아웃풋을 concat하여 hidden layer에 통과시켜서 convolutional sequence embedding을 얻음(z의 사이즈는 d임)
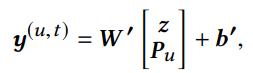
- user’s general preferences를 capture하는데 사용하는 유저 임베딩 Pu와 z를 concat하고, 그 값을 taget item의 embedding(d x 2)과 서로 내적하고 taget item의 bias(1)를 더하여 최종적으로 y를 얻음
- y는 유저의 sequential patterns에 대한 정보를 가지고 target에 대한 선호도의 확률 값이라고 할 수 있음
4) Network Training
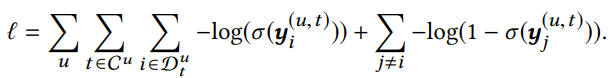
- 본 모델은 위와 같이 y 값을 sigmoid function을 통과시켜서 binary cross-entropy loss를 목적함수로 하여 모델을 학습시킴
- 그리고 target인 i(pos sample)에 대한 sequential patterns에 랜덤하게 negative samplling한 j(neg sample)를 구하여 모델을 학습시킴(본 논문에서는 3개의 negative sample을 사용했다고 함)
- optimizer는 Adam으로, batch size는 100으로, 정규화를 위해 모든 학습 파라미터에 L2 Norm을 적용하고, FC layer에 0.5의 Dropout을 사용하여 모델을 학습시켰다고 함
5) Recommendation
- 유저에 마지막 L item의 embedding을 가지고 모든 item에 대한 y 값을 구하여 높은 값을 가지는 Top-N개의 아이템을 추천에 사용함
6) Connection to Existing Models
- Caser의 학습 방법은 MF, FPMC, Fossil가 학습하는 방법과 유사하게 만들 수 있다고 함
4. EXPERIMENTS
- 이 부분의 내용은 본 모델이 다른 모델 보다 성능이 좋다는 이야기라서 생략함
5. CONCLUSION
- Caser은 top-N sequential recommendation에 새로운 접근법임
- Caser은 point-level, union-level sequential patterns, skip behaviors, long term user preferences 등에 정보를 모두 캡쳐할 수 있다고 함
Code
Reference

Machine Learning Engineer at Konan Technology