[Paper & Code Review] (2018, WWW) Variational Autoencoders for Collaborative Filtering
RecSys Paper
목록 보기
6/9
1. INTRODUCTION
- 좋은 추천 시스템은 엄청난 양의 content와 유저 사이에 효과적인 상호작용을 만들어 준다(유저가 모르고 있던, 유저에게 적합한 content를 추천해주는 것). 따라서 좋은 추천 시스템은 소비자에게는 펀리함을, 기업에게는 새로운 기회를 제공해줄 수 있다.
- Collaborative filtering은 유저와 아이템간의 유사한 패턴을 찾아내서 이를 활용하여 유저가 선호할만한 아이템을 추천해주는 것이다.
- 대부분의 사람들은 주로 추천 시스템을 big-data problem로 생각하지만(많은 양의 유저와 데이터가 존재하기 때문에), 논문의 저자는 유저는 아주 적은 양의 아이템만 상호 작용하기 때문에 small-data problem이라고 주장한다.(유저-아이템 상호 작용 데이터는 매우 sparse함)
- 본 논문에서는 a probabilistic latent-variable model을 만듦으로써 sparse한 데이터를 사용하고 모델의 과적합을 피했다.
- 본 논문에서 제안하는 a probabilistic latent-variable model은 variational autoencoders를 변형한 모델이다.
- 본 모델은 전통적인 Bayesian approach를 따르기 때문에 데이터의 크기에 매우 강건하다고 함
- 본 모델은 multinomial likelihood를 사용하기 때문에 implicit feedback data를 더 잘 모델링 할 수 있다고 함(그래서 Multi-VAE 라고 부르는 것)
- 본 모델은 annealing 기법을 사용하여 파라미터를 업데이트함으로써 모델의 과적합을 해소함
2. METHOD
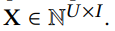
- 본 모델은 implicit feedback인 위와 같은 user-item interaction matrix를 input으로 사용함(0과 1로 이루어진 데이터)
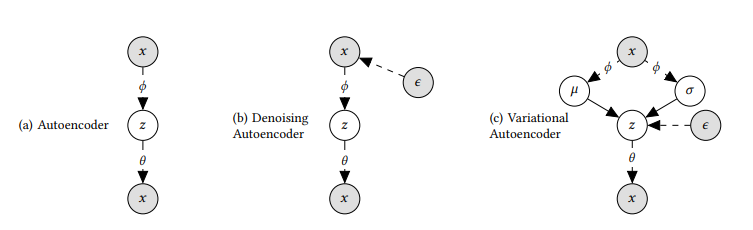
- 본 논문에서 제안한 모델은 variational autoencoder를 변형한 형태 모델이며, autoencoder 계열의 모델은 위와 같이 3종류로 나뉨(VAE는 원래 생성 모델의 일종이기 때문에 autoencoder 계열이라고 말하기는 좀 그렇지만, 모델 구조 자체가 autoencoder 계열과 비슷하여 autoencoder라고 불림)
- 단순히 x를 encoder를 이용하여 latent representation z로 축소 후에 decoder로 복원하는 형태가 기본적인 Autoencoder
- x에 noise를 넣은 후 encoder를 이용하여 latent representation z로 축소 후에 decoder로 복원하는 형태가 Denoising Autoencoder
- x를 encoder를 이용하여 평균과 분산을 구한 후, 구해진 평균과 분산으로 K-dimensional latent representation z 샘플링하고, 해당 샘플링된 z를 다시 decoder로 복원하는 형태가 Variational Autoencoder
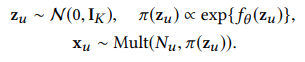
- 본 논문에서 제안하는 VAE는 user-item interaction matrix x가 multinomial distribution이라고 가정하고 모델을 학습시킴, 따라서 본 모델을 Multi-VAE 라고 칭함
- 모델의 output인 reconstuct x를 어떠한 loss를 사용하여 최적화 하느냐에 따라서 Gaussian, Logistic, Multinomial로 나뉘어짐
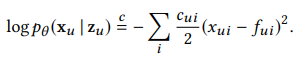
- 위와 같이 단순히 MSE Loss를 사용하면 Gaussian-VAE라고 부름
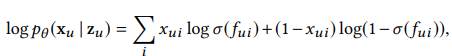
- 위와 같이 단순히 BCE Loss를 사용하면 Logistic-VAE라고 부름(output인 reconstuct x를 sigmoid 함수에 통과 시킨 후에 계산해야함)
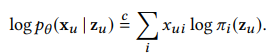
- 위와 같은 Loss를 사용하면 Multi-VAE라고 부름
- 위 Loss는 단순히 multi-class classification을 위한 cross-entropy loss로 볼 수 있음
- 는 output인 reconstuct x를 softmax 함수에 통과시킨 probability vector임
- 해당 probability vector를 reconstuct x vector와 곱함으로써 1에 해당하는 위치의 값을 최대화 시킬 수 있음
- 위와 같이 probability vector를 사용하는 방식은 추천 시스템의 top-N ranking에 적합하다고 할 수 있음
- 왜냐하면 probability vector를 이용한 Loss 계산 방식은 list-wise 방식 + 관측된 행렬에 대해서만 backpropagation을 진행하는 것 이라고 할 수 있기 때문임 (top-N에 해당하는 클래스의 확률 값은 매우 높아지게 되고 이 차이가 앞에 두 Loss와의 차이점이라고 생각됨)

- Multi-VAE는 위와 같은 방식으로 모델의 파라미터를 최적화 시키는데, 중간에 z를 샘플링하는 reparametrization trick이 존재함
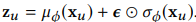
- reparametrization trick은 단순히 정규 분포에서 샘플링된 입실론을 모델을 통해서 구한 분산과 평균을 곱하는 것임
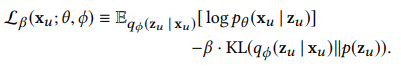
- Multi-VAE의 목적함수는 기존 VAE와 달리 KL term에 베타라는 annealing 기법이 사용됨(과적합을 방지하기 위한 하나의 규제 방법이라고 볼 수 있음)
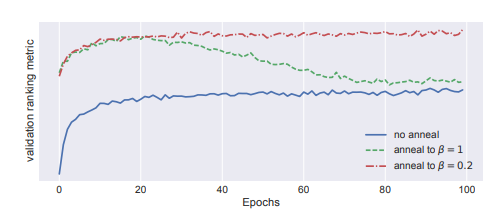
- annealing 기법을 사용함으로써 모델의 성능을 높임
- 모델이 학습을 할 때 KL term에 너무 집중하게 되면 모델이 과적합되는 경향을 보임(베타가 1일 때)
- 베타는 하나의 파라미터로 0 ~ 1 사이의 값으로 튜닝을 할 수 있음
- 모델의 에폭이 늘어남에 따라서 베타의 값을 조금 씩 증가시키면서 loss에서 KL term의 비중을 높이는 것임
- 따라서 annealing 기법은 초반에는 모델이 probability vector를 제대로 만드는 것에 집중하게 만들고 점차 KL term의 비중을 높여가는 것이라고 할 수 있음
- 베타는 논문에서 0.2까지 올렸을 때 최적의 성능을 보여줬다고 함
- 추가적으로 본 모델의 input에 dropput layer를 추가하여 noise 효과를 줌으로써 과적합을 해소함(DAE의 방법)
- DAE에 multinomial likelihood를 사용하면 Multi-DAE라고 부름
3. EMPIRICAL STUDY
- Multi-VAE와 Multi-DAE의 경우 I -> 600 -> 200 -> 600 -> I와 같이 단순히 0 or 1개의 적은 수의 hidden layer를 사용했을 때 좋은 성능을 보여줬다함
- 중간 layer에 activation function으로는 tanh를 사용함
- dropout 확률은 0.5로 설정함
- Multi-VAE와 Multi-DAE 모두 Adam을 사용함
- Multi-DAE의 경우에는 0.01의 weight decay를 주었지만, Multi-VAE의 경우에는 주지 않음
- batch size는 500으로 설정하고, ML-20M의 경우 200 epochs으로 모델을 학습 시킴
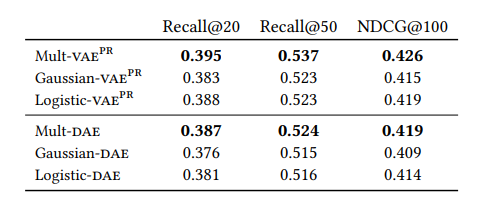
- Multi-VAE와 Multi-DAE 간의 엄청난 성능 차이를 보이지는 않지만, variational Bayesian inference approach을 사용하는 Multi-VAE가 point estimate인 Multi-DAE 보다 더 좋은 성능을 보여준다고 함(그냥 둘다 써보고 제일 좋은 모델 쓰는 것이 제일 좋을 듯 함)
Code
Reference

Machine Learning Engineer at Konan Technology