[Paper & Code Review] (2017, WWW) Pixie: A System for Recommending 3+ Billion Items to 200+ Million Users in Real-Time
RecSys Paper
목록 보기
7/9
INTRODUCTION
- Pinterest는 2억 명이 넘는 유저에게 30억 개가 넘는 아이템을 실시간으로 개인화된 추천을 해주는 것이 주요 목표이다.
- 많은 아이템을 실시간으로 추천해줄때 1초 이상의 시간이 걸릴 수 있는데, 사용자들에게 1초는 매우 오랜 시간 일 수 있다.(모델의 인퍼런스 타임을 단축시키는 것이 중요하다는 것)
- 그래서 기다리는 시간을 단축 시키기 위해서 Pinterest는 배치 서빙을 하려 했지만, 이 방법은 시간과 리소스의 낭비가 발생할 수 있기 때문에 사용하지 않았다.(실제 사용자보다 사용하지 않는 사용자의 수가 많기 때문에 의미 없는 계산이 일어남)
- 이런 문제를 해결하기 위해서 Pinterest가 제안한 모델이 바로 a scalable real-time graph-based recommendation system인 Pixie이다.
- Pinterest는 pin(개인이 저장한 이미지, 하나의 board에 속할 수 있음)과 board(pin의 집합체로 여러개의 보드에 동일한 pin이 존재할 수도 있고, 동일한 pin이 존재하는 board가 서로 다른 이름으로 존재할 수도 있음)를 인간이 만든 하나의 bipartite graph로 보았고, 이를 이용해 graph-based recommendation을 함
- Pinterest는 유저가 상호작용한 pin의 집합인 Q(최근 + 과거에 상호 작용한 pin들을 사용)를 input으로 하여 Pixie Random Walk algorithm을 사용해 추천을 생성함
- Pixie Random Walk algorithm은 사용자의 언어(사용 언어), 관심사 등에 편향되어 Random Walk를 수행함 (개인화된 추천을 위해)
- Pixie Random Walk algorithm은 Q의 pin들에 weight를 서로 다르게 하여 좀더 유저의 행동을 잘 캡쳐할 수 있도록 함(weight가 높은 pin이 더 많은 pin을 방문할 수 있도록 하는 것)
- Pixie Random Walk algorithm은 Q가 모두 독립적으로 Random Walk을 수행한 후 그 결과가 조합됨
- Pixie Random Walk algorithm은 real-time performance를 증가시키고자 early stopping을 사용함 (속도 향상 측면)
- cold-start problem을 해결하기 위해서 새로운 pin이 생성되면, 처음에는 board를 추천하고, 그 새로운 pin을 그 board에 추가되어 추후에 제공된다고 함
- 그리고 a graph curation strategy을 발전시키고 있다고 함
- Pixie algorithm은 flexibility와 dynamically bias가 적용된 Walk 덕분에 유저는 자신의 언어와 지역에 걸맞는 컨텐츠를 추천받을 수 있고, walk length를 조절함으로써 신선함(넓은)과 적합함(좁은)의 추천을 조절할 수 있다고 함
PROPOSED METHOD
- 우선 Random Walk를 수행하기 위한 Graph로 G를 정의함
- G는 bipartite graph로 G = (P, B, E)로 정의됨
- P는 pin의 모음, B는 board의 모음, E는 P와 B가 서로 연결되었는지의 유무
- 추천을 생성하기 위해서 input으로 유저가 상호작용했던 pin의 집합인 Q를 정의함
- Q는 {()}로 정의되고, 최근에 상호작용한 pin일수록 가중치를 크게, 과거에 상호작용한 pin일수록 가중치를 작게 설정함
1) Pixie Random Walk
(1) Basic Random Walk
def BasicRandomWalk(q: Query pin, E: Set of edges, α: Real, N: Int):
totSteps = 0
V = array(len(total_pin)) : pin visit counts
while True:
currPin = q
crrSteps = SampleWalkLength(α)
for i in range(crrSteps):
currBoard = E[currPin].currPin_connection_board_random_sampling
currPin = E[currBoard].currBoard_connection_pin_random_sampling
V[currPin]++
totSteps += currSteps
if totSteps >= N: break
return V- Pixie Random Walk의 기본 베이스는 위와 같은 수도 코드를 이루어졌고, Random Walk를 이용하여 방문한 pin들의 count가 저장되어 있는 visit counts vector를 구하는 것이 핵심이라고 생각함
- Pixie Random Walk는 위 알고리즘을 수정하여 사용함
(2) Biasing the Pixie Random Walk
- 개인화된 추천을 위해서는 유저의 선호가 반영된 pin 또는 board를 선택하는 것이 중요함
- 이를 위해서 편향된 Random Walk를 수행함
- user features에 기반하여 random edge selection(pinterest의 경우 유저의 language or topic 정보를 활용하여, 유저의 취향에 맞는 pin과 board의 방문 확률을 높임)
(3) Multiple Query Pins with Weights
- 최근에 상호작용한 pin일수록 가중치를 크게, 과거에 상호작용한 pin일수록 가중치를 작게 설정함
- query pin의 degree에 따라서 visit counts의 수렴이 달라질 수 있기 때문에, degree에 맞게 random walk의 size를 조정
(4) Multi-hit Booster
- Q에서 여러개의 pin이 방문한 pin일수록 그 영향력을 더 강하게 함
(5) Early Stopping
- 속도를 개선시키기 위해서 특정 node에 nv 이상의 방문이 일어나면, nv 이상의 방문이 일어난 횟수를 체크하고, 그 수가 np 이상이면 탐색을 종료함
- 왜냐하면 많은 방문이 일어났으면 이미 많은 방문이 일어난 노드에 수렴했다고 볼 수 있기 때문임
(6) Pixie Random Walk
def PixieRandomWalk(q: Query pin, E: Set of edges, U : User personalization features, α: Real, N: Int, np : Int, nv : Int):
totSteps = 0
V = array(len(total_pin)) : pin visit counts
nHighVisited = 0
while True:
currPin = q
currSteps = SampleWalkLength(α)
for i in range(currSteps):
currBoard = E[currPin].currPin_connection_board_personalization_random_sampling(U)
currPin = E[currBoard].currBoard_connection_pin_personalization_random_sampling(U)
V[currPin]++
if V[currPin] == nv:
nHighVisited++
totSteps += currSteps
if totSteps >= N or nHighVisited > np: break
return V- 위에서 말한 내용을 기반으로 Basic Random Walk 수정하여 위와 같은 형태의 조금 더 개인화되고 속도가 빠른 Pixie Random Walk를 만듬
- 핵심은 개인화된 board와 pin을 sampling 하는 것이고, 특정 이상의 방문이 발생하면 탐색을 멈춰서 속도를 개선시키는 것이라고 생각함
(6) Pixie Random Walk Multiple
def PixieRandomWalkMultiple(Q: Query pins, W : Set of weights for query pins, E: Set of edges, U : User personalization features, α:
Real, N: Int):
for q in Q:
Nq = Eq.2
Vq = PixieRandomWalk(q, E, U, α, Nq)
for p in G:
V[p] = Eq.3
return V- 위와 같은 형태로 Pixie Random Walk를 Q의 개수 만큼 수행할 수 있음
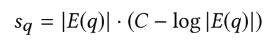
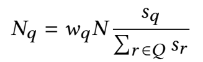
- Eq.2의 경우 위와 같은 식으로 구성되어 있음(Multiple Query Pins with Weights를 위하여)
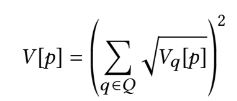
- Eq.3의 경우 위과 같은 식으로 구성되어 있음(Multi-hit Booster를 위하여)
2) Graph Pruning
- Pinteres의 그래프의 경우 매우 거대하기 때문에, 이를 한번 전처리해줄 필요가 있음
- 단순하게 생각햇을 때 많은 pin들이 제대로된 board에 들어간다고 가정할 수 없기 때문에, 이런 잘못 분류된 pin들을 모두 제거 해줌
- 여기서 pin들의 description(text)을 사용하여 LDA topic modelling을 함
- pin의 경우에는 board 와의 Similarity를 계산하여 낮은 Similarity를 갖는 pin을 제거
- board의 경우에는 pin들의 Topic distribution을 구한 뒤, 엔트로피가 높은 board를 제거
USE CASES AT PINTEREST
- PINTEREST는 Pixie를 Homefeed에 사용하여, 사용자가 실시간으로 pin을 설정하면 바로 Q를 생성하여 실시간 추천을 한다고 함
- PINTEREST는 Pixie를 연관 pin 생성, 연관 board 생성, board 추천 등에 사용한다고 함
Code
- https://github.com/SeongBeomLEE/RecsysTutorial/tree/main/Pixie
- 개인적으로 내가 구현했을 때 속도가 느림(실제로는 C로 구현 + 병렬 처리를 했을 것 이라고 생각됨, 그리고 내가 제대로 구현했다는 보장이 없음, 그리고 numpy를 이용하여 구현했는데 dict로 이분 그래프를 나타냈다면 더욱더 속도 빠를 것이라고 생각됨)
- 다른 DNN 기반의 모델 보다 성능이 좋지 않은 편(본 모델의 경우 A/B Test를 바탕으로 모델의 성능을 평가했다고 함. 따라서 나 처럼 영화 데이터 셋으로 모델의 성능을 평가하지는 않았을 것임, 그리고 본 모델은 실시간 추천을 위한 빠른 neighborhood-based model의 일종이라고 생각됨, 그래서 성능 보다는 속도가 우선이 아닐까 생각됨)
Reference

Machine Learning Engineer at Konan Technology