An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale 논문
Official github
Code Implementation with pytorch
Abstract
Transformer Architecture는 자연어 처리 작업의 사실상 표준이 되었지만, CV에 대한 적용은 여전히 제한적. Vision에서 Attention은 Convolutional Network와 함께 적용되거나 전체 구조를 유지하면서 Convolutional Network의 특정 구성 요소를 교체하는 데 사용된다. CNN에 대한 의존성이 필요하지 않으며 Sequence of Image Patches에 직접 적용되는 pure Transformer가 Image classification 작업에서 매우 잘 수행될 수 있음을 보여줌. 많은 양의 데이터에 대해 pre-trained하고 다양한 중간 크기 또는 소규모 이미지 인식 결과에서 Vision Transformer는 SOTA Convolutional Network에 비해 우수한 결과를 얻으면서도 교육에 필요한 계산 리소스는 상당히 적다.
Method
모든 설계에서 origianl Transformer (Vaswani et al., 2017)를 가능한 비슷하게 따라간다. 이러한 단순한 설정의 장점은 확장 가능한 NLP Transformer 구조를 효율적으로 구현할 수 있다는 것과 즉시 사용할 수 있다는 점.
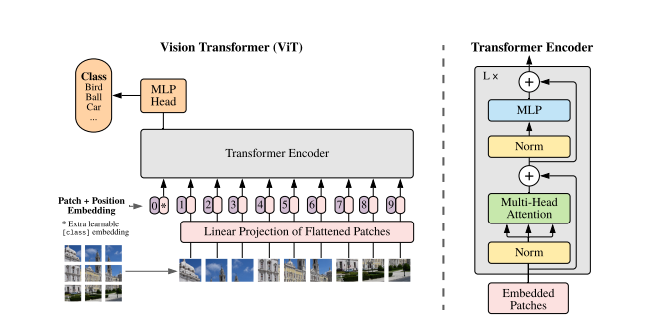
standard Transformer는 1D sequence of token embeddings을 입력으로 받는다. 2D 이미지를 다루기 위해 로 변환시킨다. 이 때, 는 각 image patch이고, 은 patch 개수이다.
BERT의 [class] 토큰과 비슷하게 학습 가능한 embedded patch를 맨 앞에 추가한다.
각 이미지 패치들의 위치 정보를 유지하기 위해 positional embedding이 추가된다. 2D-aware position embeddings를 사용해봤지만 상당한 성능 향상이 이뤄지지 않았기 때문에 학습 가능한 1D position embedding를 사용.
Transformer Encoder는 Multi-Head Self-Attention 블록과 MLP 블록으로 이루어져있음.
우선 Layer Norm은 모든 블록 이전에 적용되고, Residual Connections은 모든 블록 이후에 적용된다.
- Inductive bias.
ViT는 CNN보다 image-specific inductive bias가 적다는 것에 주목. Transformer 모델은 Attention 구조만을 사용. Attnetion은 데이터 전체를 보고 Attention할 위치를 정하는 메커니즘이기 때문에 이 패턴을 익히기 위해서 CNN보다 더 많은 데이터를 필요로 함.
inductive bias (귀납편향)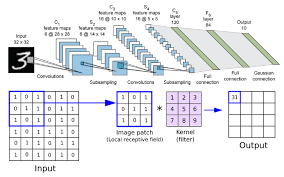
이미지에서 물체는 근처 픽셀에 위치할 것이다. 이렇듯 CNN은 기본적으로 각각의 filter를 통해서 지역적인 정보를 습득하는데 이러한 방식은 이미지를 다룰 때 '지역적인 정보는 중요하다'라는 가정이 깔려 있는 것.
inductive bias란 학습 시에는 만나보지 않았던 상황에 대하여 정확한 예측을 하기 위해 사용하는 추가적인 가정을 의미한다. CNN에서는 Locality가 추가적인 가정이며 이러한 가정이 잘 맞기 때문에 아직까지도 CNN 모델이 잘 쓰이고 있다.
반대로 Transformer에서 self-attention은 한번에 병렬적으로 이루어진다. 따라서 CNN에서 사용되는 filter처럼 Locality의 가정을 잘 활용할 수 없다. 만약, 지역적인 정보를 가지고 예측하는 것이 아닌 Global하게 보고 이미지를 예측하는 것이라면 self-attention 메커니즘을 사용하는 transformer가 더욱 효율적일 것이다.
CNN에 비해서 Inductive Bias가 부족하기 때문에 많은 양의 데이터를 가지고 학습을 해야 효과를 나타낼 수 있다.
Hybrid Architecture.
Image patch의 대안으로 CNN의 feature map의 sequence를 사용할 수 있다.
Conclusion
CV에서 self-attention을 사용하려는 이전 작업과 달리, 초기 Patch 추출 단계를 제외하고 image-specific inductive bias를 아키텍처에 도입하지 않았다. 대신 이미지를 sequence patch로 해석하고 NLP에서 사용되는 표준 Transformer Encoder로 처리한다. 단순하지만 확장 가능한 이 전략은 대규모 데이터에 대해 pre-trained를 한 모델과 결합할 때 잘 작동되는 것을 확인할 수 있다.
하지만 아직까지는 많은 과제가 남아있다. ViT를 Detection이나 Segmentation과 같은 다른 CV 작업에 적용하는 것이다. 다른 과제로는 self-supervised pre-trained 방법을 계속해서 모색하는 것이다.
Experiments
- Dataset
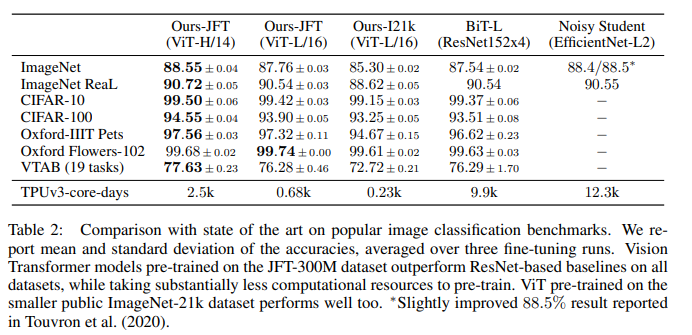
학습 ImageNet-1k(1.3M), ImageNet-21k(14M), JFT-18k(303M)
평가 19-task VTAB(적은 데이터셋을 활용한 transfer learning 성능 평가)
참고 블로그 1
참고 블로그 2
Implementation code 참고 사이트 1
Implementation code 참고 사이트 2

애덤 간바레