리뷰에 앞서...
기존 프로젝트에서 사진에서 정보를 추출하기 위해 글자의 위치를 파악하고, 위치에 따른 카테고리를 분류한 뒤에 글자 위치에 해당하는 이미지만 OCR 엔진을 통해 recognition을 진행했다.
이 프로젝트에서 하나의 모델, End-to-End 모델로 업데이트를 하기 위해 논문을 찾던와중 이 논문을 읽게 되었다.
논문을 읽고 든 생각은 이제는 이미지 전체를 그냥 활용하는 방향으로 발전할 수 있겠다는 생각이 들었다.
프로젝트에 Donut 모델을 적용하기 위해 ONNX 변환하는 과정도 진행했다. 변환은 Github을 참고해주길 바란다.
해당 논문: https://arxiv.org/abs/2111.15664
Official Github: https://github.com/clovaai/donut
Abstract
지금까지 VDU(Visual Document Understanding) 방법들은 OCR 엔진에 많은 의존을 해왔다. OCR-based 접근은 다음과 같은 문제가 있다.
- OCR을 사용하는데 많은 cost 발생.
- 유연성이 없는 OCR 모델
- 뒤에 이어지는 프로세스에 OCR 에러가 영향을 미침.
이러한 문제점들을 다루기 위해 OCR-free 모델을 제안한 것이다.
Introduction
기존 VDU 방법들은 two-stage 방식이었다.
1. 문서 이미지에서 텍스트들을 읽는다.
2. 문서를 전체적으로 이해한다.

위 그림처럼 문서에서 정보를 추출하기 위해 Text detection, Text recognition, Text parsing의 개별적이 세 개의 모듈로 구성되어 있었다.
즉, OCR 엔진으로 문서 정보를 추출하는 것인데, 저런 방식에는 문제점들이 존재한다. 1)고품질의 OCR 결과를 얻기 위해서는 많은 시간과 비용이 발생. 2)다양한 언어에 대해서는 유연함이 없음. 3)OCR 에러가 나면 VDU 시스템에 영향을 미치고 이건 하위 프로세스에 안 좋은 영향을 미친다.
OCR에 의존하지 않고, Raw 입력 이미지로부터 이상적인 결과를 바로 맵핑하는 모델을 소개한다.
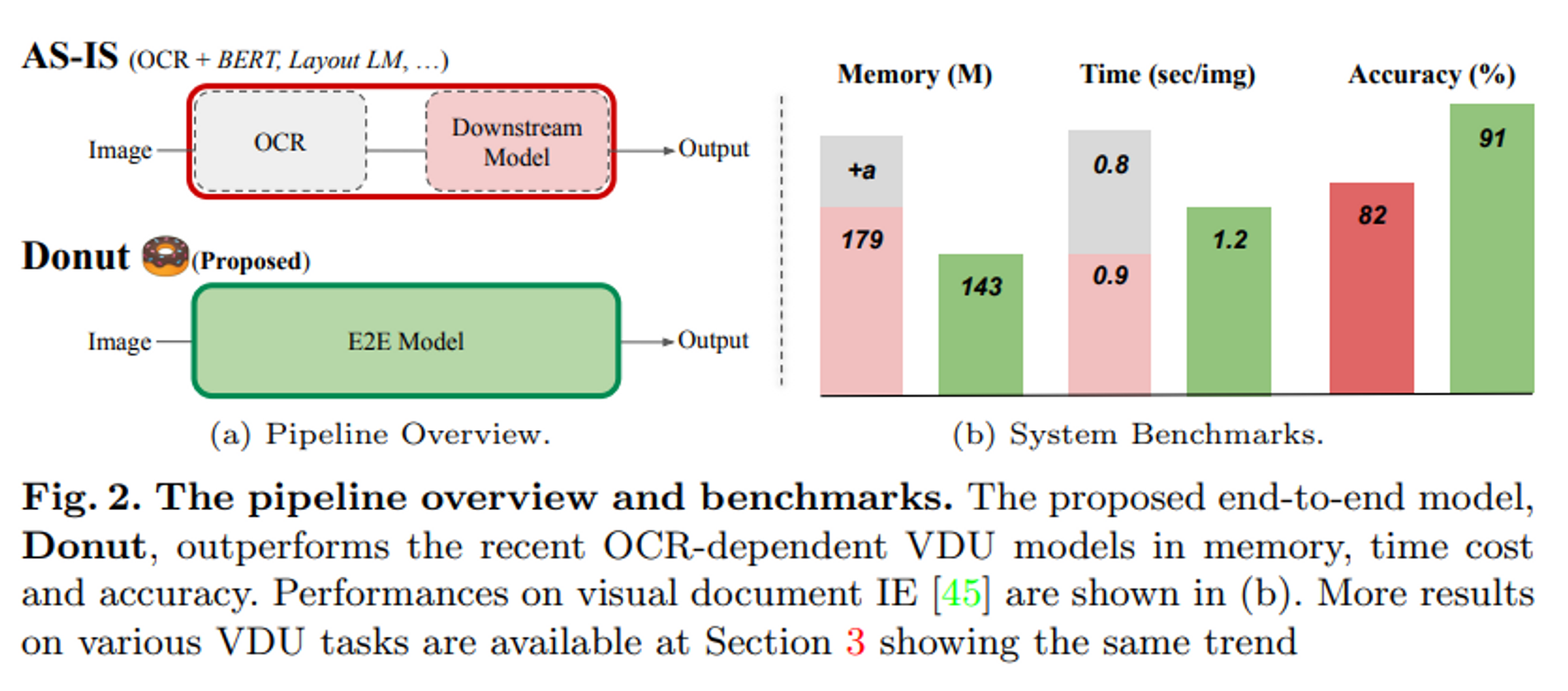
위 표를 보아도 기존 OCR을 이용하는 방법보다 Donut 모델이 정확도, 메모리, 시간 측면에서 더 향상된 것을 알 수 있다.
그리고 SynthDoG를 사용하여 Donut을 다국어 설정으로 쉽게 확장할 수 있음을 보여준다.
Method
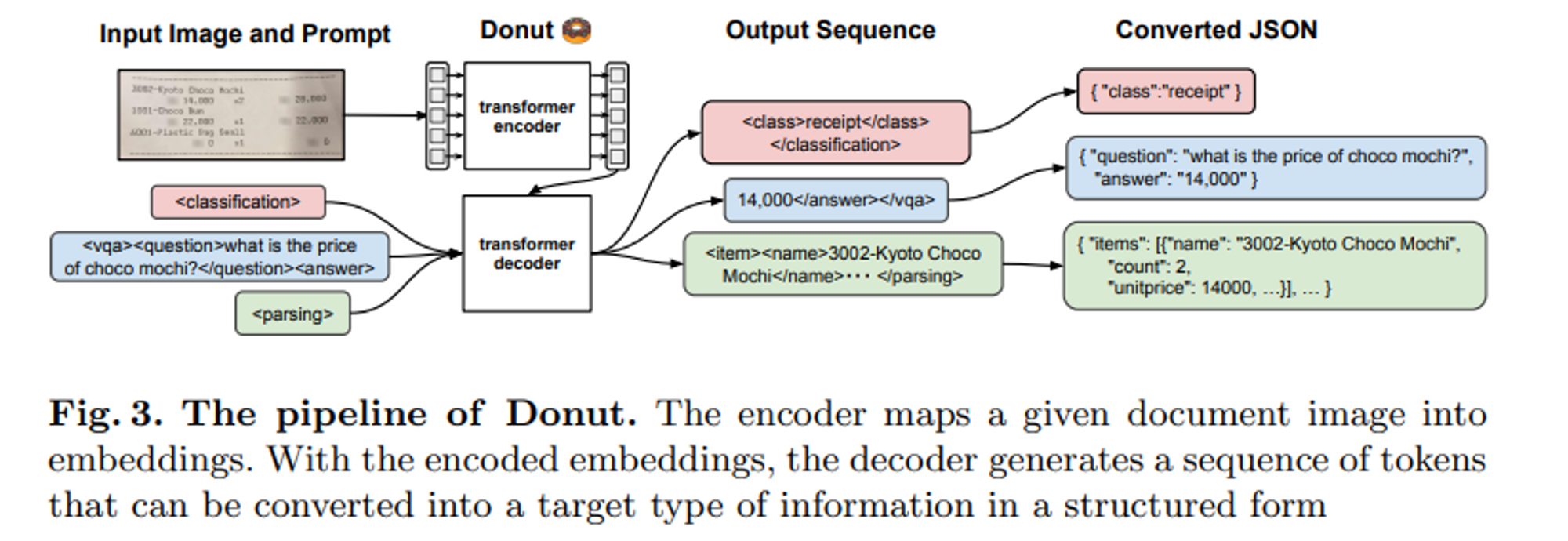
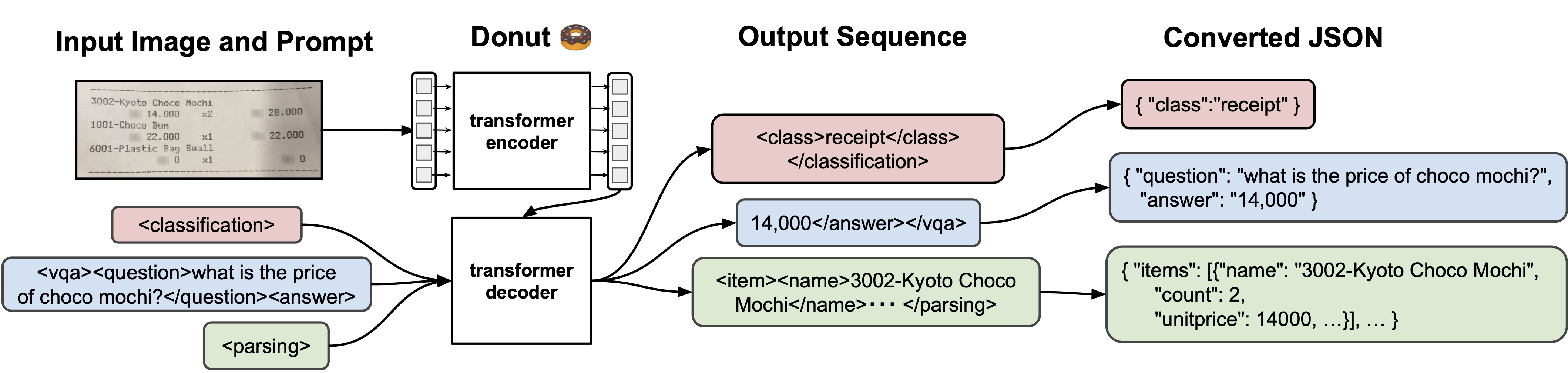
위 이미지는 Donut의 전반적인 프로세스이다.
Donut은 Transformer 기반의 Visual encoder와 Textual decoder 모듈로 구성되어 있다.
문서 이미지로부터 특징을 추출하는 Visual encoder와 파생된 특징들을 일련의 하위 단어 토큰으로 매핑하여 구조화하는 Textual decoder이다.
Encoder
입력하는 이미지 를 로 임베딩한다. 인코더는 CNN기반 모델이나 Transformer기반 모델을 사용할 수 있다. 논문에서는 Swin Transformer를 사용했다. 그 이유는 가장 성능을 보였기 때문에!
최종 Swin Transformer 블록 의 출력은 Textual decoder에 입력된다.
Decoder
가 주어지면, Textual decoder는 토큰 시퀀스 를 생성한다. 는 i 번째 토큰, v 토큰 사이즈에 대한 원핫벡터를 의미한다. 논문에서는 multi-lingual BART 모델을 사용했다.
Model Input
모델은 teacher-forcing 방식으로 학습 되었다.
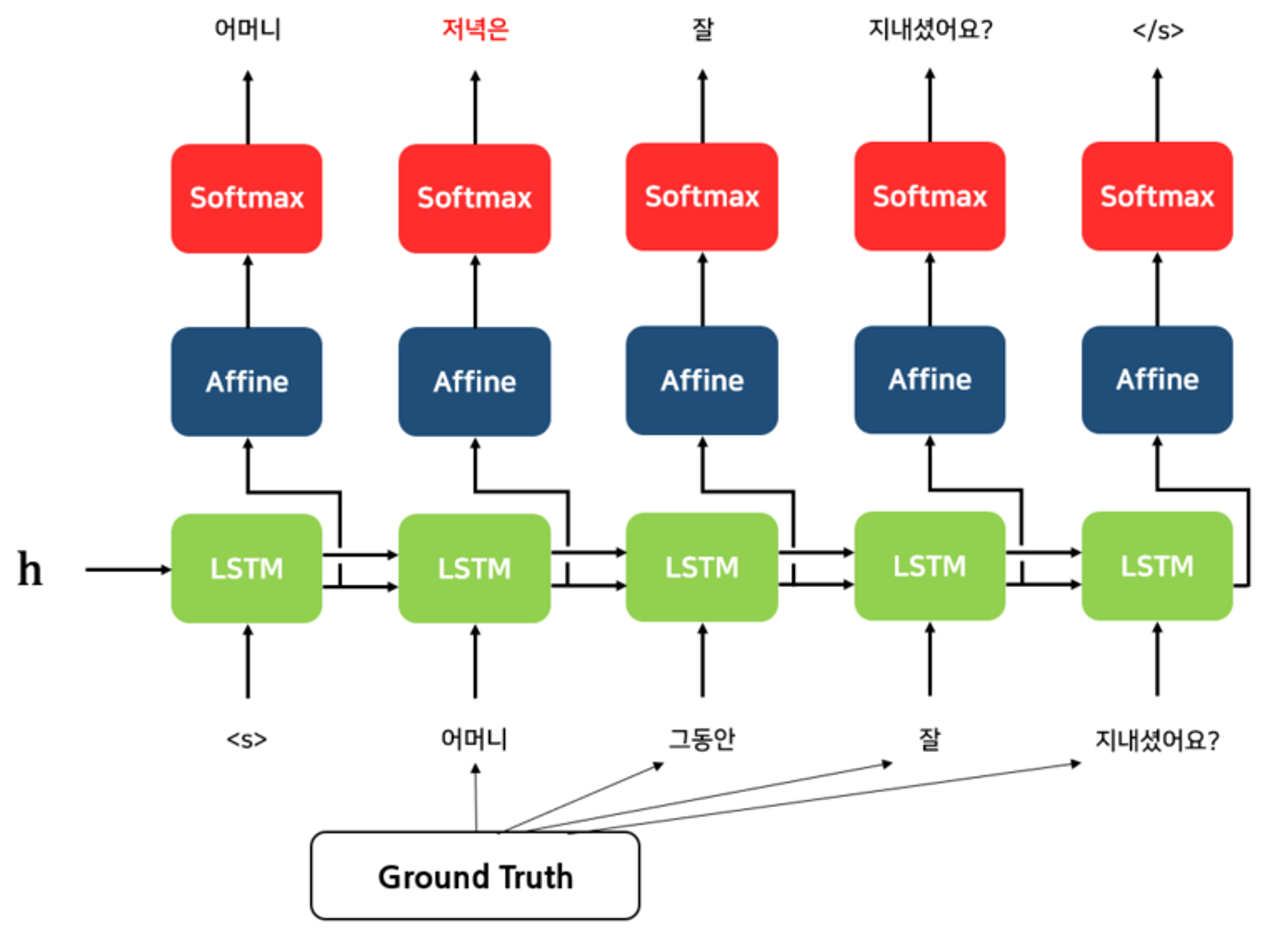
teacher-forcing은 Seq2Seq을 기반으로 한 모델들에서 많이 사용되는 기법이다. Grount Truth를 디코더의 다음 입력으로 넣어주며 학습하는 기법이다.
Donut 모델의 테스트 단계에서는 GPT-3에서 영감을 받아 주어진 prompt에 따라 토큰 시퀀스를 생성한다. 그리고 special 토큰을 제공하여 각각의 downstream task들을 처리하는 식으로 작동한다. (Classification, Parsing, ...)
Pre-training
Donut의 사전 학습은 문서 이미지들을 가지고 학습을 진행한다. cross-entropy loss가 최소가 되도록 학습이 진행되었다.
그런데, 문서 이미지 데이터 자체가 많지가 않다. (영어로 된 문서 이미지는 있지만 다른 언어로 된 문서 이미지 데이터가 별로 없음)
그래서 데이터를 만드는 기법이 탄생했다.
Synthetic Donument Generator (SynthDoG)

위 그림처럼 뒷 배경, 텍스트, 레이아웃의 요소로 구성하여 랜덤하게 이미지를 합성해 데이터셋을 생성한다.

Fine-tuning
pre-training을 통해 모델이 how to read 에 대해 알려줬으면, fine-tuning을 통해 how to understand 에 대해 알려준다.
Experiments and Analyses

Document Classification
문서 분류 작업
보통은 소프트맥스를 통해 클래스 레이블을 예측하는데, Donut은 클래스 정보가 포함된 JSON을 생성한다.
Document Information Extraction
문서 이미지에서 글자를 읽고 레이아웃의 의미를 파악해 이해하는 작업.
Document Visual Question Answering
문서 이미지와 질문이 쌍으로 제공되고 모델은 이미지 내의 시각적 정보와 텍스트 정보를 모두 파악해 질문에 대한 답변을 예측.
Conclusions
OCR에 의존하지 않는 새로운 방식의 End-to-End 모델인 Donut을 제안했다.
모델은 학습 pipeline을 이용해 how to read 를 학습한 뒤, how to understand 를 순차적으로 학습한다.

기울기 손실