Introduction
transformer-based LLM이 널리 사용되기 시작하면서, 이러한 모델들의 추론 효율성을 향상시키기 위한 연구가 점점 더 중요해지고 있습니다. 대규모 언어 모델의 사전 훈련은 전체 입력 시퀀스를 병렬로 처리함으로써 높은 하드웨어 활용도를 달성할 수 있지만, 전통적으로 LLM 추론의 효율성은 시퀀스에 따라 토큰을 하나씩 순차적으로 생성해야 한다는 필요성에 의해 제한되었습니다. 현재 GPU 하드웨어에서, LLM 디코딩의 순차적인 특성은 메모리 대역폭 문제로 이어지고, 처리량은 GPU 주 메모리로부터 로컬 레지스터로의 대규모 가중치 행렬의 이동에 의해 제한됩니다. 각 생성 단계는 모델 가중치 전체에 대한 접근을 요구하지만, 비교적 적은 수의 FLOPs만을 포함합니다(배치의 각 시퀀스에 대해 단 하나의 토큰만 처리), LLM 디코딩은 GPU의 풍부한 부동 소수점 계산 능력을 충분히 활용하지 못하는 경향이 있습니다.
sequential LLM 디코딩에서의 메모리 대역폭 병목 현상을 완화하기 위해, 최근 연구에서는 추측적 디코딩을 통한 LLM 추론 가속화를 탐구하고 있습니다. 추측적 디코딩은 더 작은 초안 모델을 사용하여 각 생성 단계에서 현재 시퀀스의 다중 토큰 후보 연속을 제안합니다. 원래 LLM은 후보 연속의 모든 토큰을 병렬로 검증하여, 일부를 시퀀스에 추가하고 나머지는 버립니다. 각 검증 단계는 원래 LLM을 통한 단일 전방 통과만을 요구하지만, 시퀀스에 여러 토큰을 추가할 수 있으므로, 추측적 디코딩은 생성된 토큰 당 필요한 가중치 데이터 이동의 양을 줄임으로써 디코딩을 가속화할 수 있습니다.
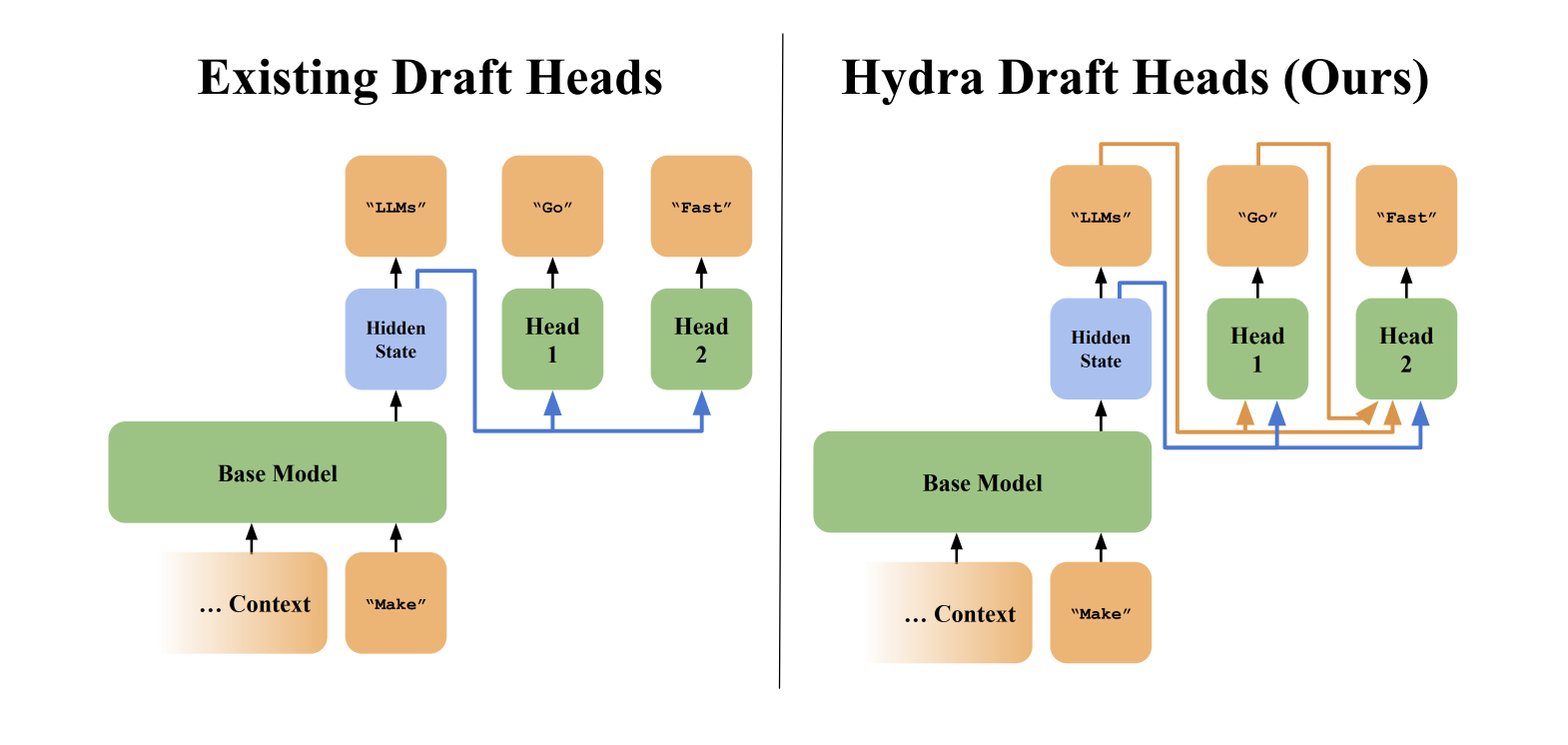
speculative decoding에서 중요한 것은 draft model입니다. 이것은 충분히 가벼워야 하며 acceptance rate는 높아야 합니다. 해당 논문에선 독립적으로 학습된 언어 모델을 draft model 대신 base 모델의 의미론적으로 풍부한 숨겨진 상태에서 작동하는 lightweight head의 모음으로 초안 모델을 구조화하는 것을 조사한다.
초안 헤드 패러다임에서 각 초안 헤드는 미래로 향하는 고정된 수의 단계에서 토큰의 정체를 예측하는 역할을 한다.
현재까지의 draft head는 이전의 내용들을 인식하지 못하고, 독립적으로 hidden state로만 생성한다. 이러한 sequential dependence는 예측 정확성을 제한한다. 해당 논문에서는 이를 해결하기 위해서 hydra head를 제안하였다. 또한, base 모델의 hidden state에 노이즈를 추가하고(Jain et al., 2024), teacher loss objective를 사용하고 hydra 헤드에 extra tranformer decoder layer을 추가하는 것을 조사합니다.
Hydra Heads
standard draft head에 sequential dependence를 추가하는 hydra head 구성을 자세하게 소개하도록 하겠습니다.
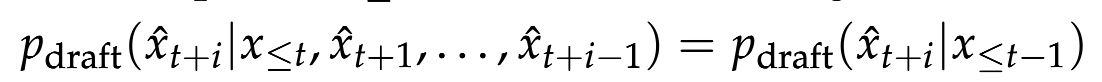
위의 수식은 existing dragt heads의 token's distribution을 나타낸 것입니다.
이전 토큰값을 고려하여 계산했을 때와 마지막 hidden state를 통해서 생성한 값이 동일한 것을 확인할 수 있습니다. 이는 i번째 토큰을 추측할 때 1~(i-1)번째 토큰을 인식하지 않기 때문입니다.
시퀀스 의존도를 가지는 draft head인 hydra head의 경우는 다음과 같습니다.
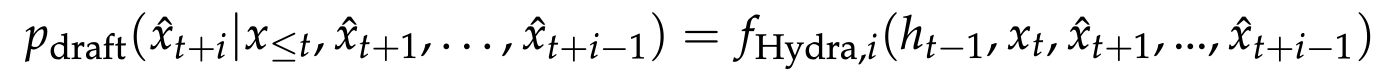
hydra head는 base 모델의 시간 t까지의 hidden state(h t-1)와 이전 히드라 헤드가 샘플링한 토큰의 입력 임베딩의 함수이기 때문에 sequentially dependent하다.
Shared Training and Evaluation Details
models : Vicuna 7B, 13B, and 33B.
Training : draft model을 base model과 같이 훈련 시킬 수 있으나, base 모델은 동결한 채 draft model만 학습시킴.
Evaluation : MT-Bench, a multi-turn conversation benchmark
Head to Head Comparison of Medusa and Hydra
hydra head를 도입하게 된 가설: sequential dependence를 더하는 것은 draft head가 생성하는 토큰의 퀄리티를 높이게 되고, 이는 더 큰 처리량을 가능하게 한다.
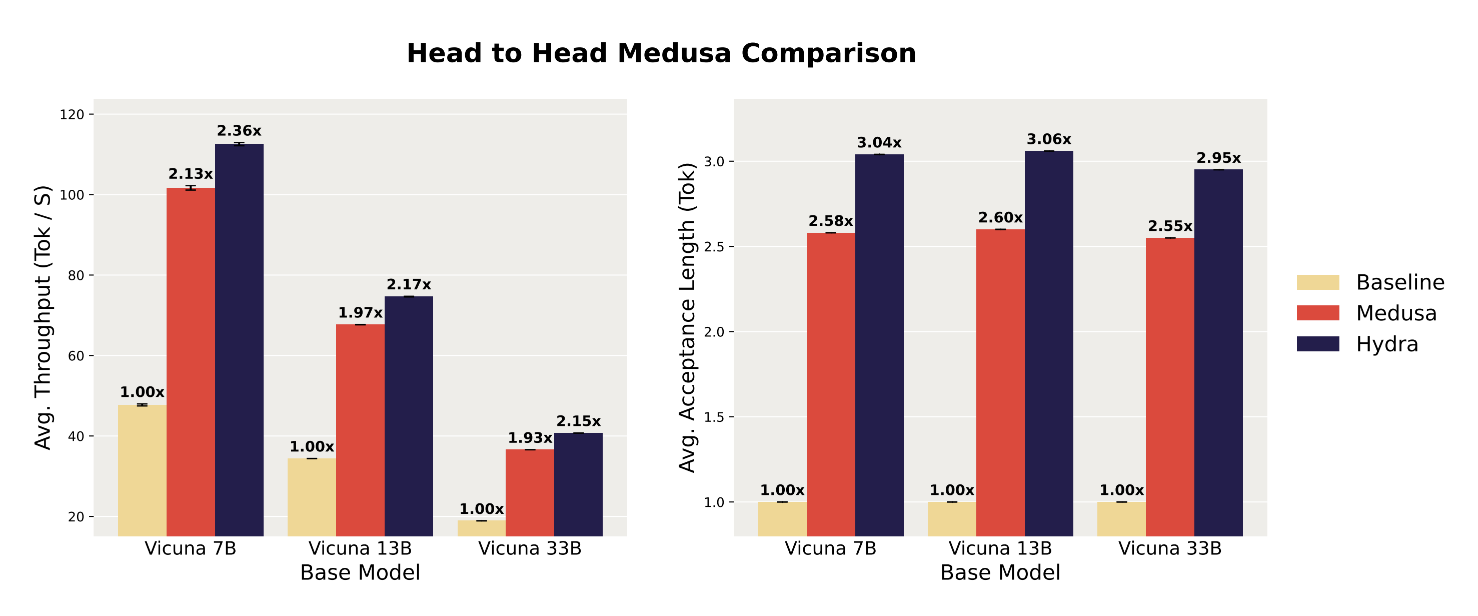
➡️ 이러한 결과는 draft 헤드를 sequential dependence이 해당 헤드의 예측 품질을 크게 향상시켜 디코딩 속도를 향상시킨다는 것을 보여줍니다.
Exploring the Design Space of Hydra Heads
이 섹션에서는 hydra head의 훈련 절차 및 아키텍처에 대한 수정 사항을 살펴봅니다.
Exploring the Training Procedure of Hydra Heads
Adding noise to the input sequence.
Jain et al. (2024)는 fine-tuning 중에 LLM의 input embedding에 노이즈를 추가하면 결과 모델의 성능을 향상시킬 수 있음을 보여줍니다.
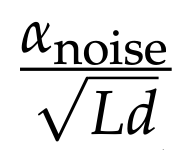
위의 수식은 sample noise인 입실론을 scaling하는데에 사용됩니다.
αnoise: 잡음의 강도를 조절하는 파라미터
배치 크기(B), 시퀀스 길이(L), 모델 차원(d)을 가진 데이터에 균일 분포(Uniform(-1, 1))로부터 샘플링한 잡음(ϵ)
Distilling the base LLM
기본 medusa decoding은 text를 예측하기 위해서 fine-tuning dataset으로 hydra head를 학습합니다. 추론하는 동안 draft head의 목표는 base LLM이 autoregressive하게 예측했을 토큰만 예측하는 것이기 때문에 이것이 최적의 훈련 목표인지 의문이다.
여기서 의문이 생기는 부분은 훈련 목표와 추론 목표 사이의 불일치입니다. 훈련에서는 전체 텍스트의 내용을 예측하도록 모델을 학습시키지만, 실제 사용(추론)에서는 다음에 올 하나의 토큰만을 예측하는 것이 목표입니다. 이는 훈련된 모델이 추론 시점에 필요한 작업보다 더 많은 정보를 예측하도록 학습됨을 의미합니다.
이러한 불일치가 최적의 학습 목표가 아닐 수 있다는 의문을 제기하는 이유는, 모델이 실제로 수행해야 하는 작업에 더 집중할 수 있는 학습 목표가 더 효과적일 수 있기 때문입니다. 즉, 모델이 실제 사용 시 단지 다음 토큰을 예측하는 데 필요한 정보만을 학습하도록 목표를 조정하는 것이 더 효율적일 수 있습니다. 이는 학습 과정을 더 효율적으로 만들고, 모델이 실제 추론 과정에서 더 좋은 성능을 발휘하도록 할 수 있습니다.
fine-tuning dataset으로 학습하는 대신 각 hydra head의 학습 손실인 hydra가 예측한 분포와 base model 사이의 크로스 엔트로피인 teacher loss를 사용한다.
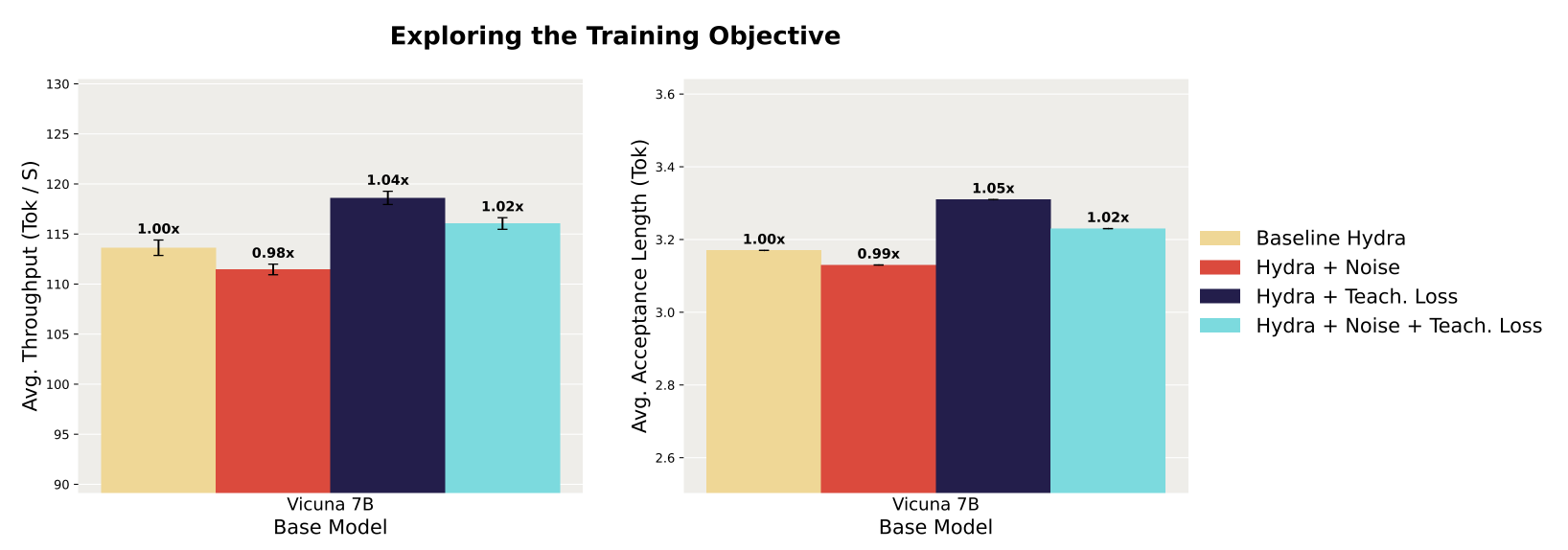
hydra head quality에 대한 각각의 훈련 개입 방법이 어떤 영향을 미치는지 평가하기 위해, 제안된 개입 방법들을 각각 별도로 그리고 함께 적용해본 후 이를 표준 방식으로 훈련된 하이드라 헤드와 비교합니다. 평가 결과는 디코딩 처리량과 각 개입 방법에 대한 평균 수용 길이(acceptance length)로 나타냅니다. 연구 결과, 추가 임베딩 잡음 없이 단지 teacher loss에만 기반한 훈련이 가장 성능이 뛰어난 개입 방법임을 발견했습니다. 구체적으로, teacher loss만을 사용하여 훈련된 헤드를 사용한 디코딩은 표준 하이드라 헤드를 사용한 디코딩에 비해 Vicuna 7B에서 처리량이 1.04배 향상됩니다. 흥미롭게도, 입력 시퀀스에 어떤 형태의 잡음을 추가하는 것은 수용 길이와 디코딩 속도를 저하시키는 것으로 나타났습니다. 이러한 결과를 바탕으로, 연구팀은 향후 실험에서 다음 토큰 예측 손실(next token prediction loss) 대신 teacher loss을 사용하기로 결정했습니다.
다음 토큰 예측 손실(Next Token Prediction Loss)
다음 토큰 예측 손실은 자연어 처리 분야의 언어 모델 훈련에서 사용되는 손실 함수입니다. 이는 모델이 현재까지의 입력 시퀀스를 바탕으로 다음에 올 토큰을 정확하게 예측하는 데 초점을 맞춥니다. 모델이 예측한 다음 토큰과 실제 다음 토큰 사이의 차이를 최소화하는 것이 목표입니다. 이 손실 함수는 주로 순차적 데이터를 다루는 언어 모델이나 시퀀스 생성 모델에서 사용됩니다.
교사 손실(Teacher Loss)
교사 손실은 "교사 강요(teacher forcing)" 기법과 관련이 있으며, 모델 훈련 시 실제 데이터 대신 교사 모델(또는 이전 단계에서의 정답 토큰)의 출력을 다음 입력으로 사용하는 방식입니다. 이 손실 함수는 모델이 주어진 입력에 대해 정확한 출력을 생성하도록 돕습니다. 특히, 시퀀스 생성 작업에서 모델의 빠른 수렴을 도모하고, 생성된 시퀀스의 질을 향상시키는 데 유용합니다.
차이점
- 목표의 차이: 다음 토큰 예측 손실은 모델이 다음 토큰을 정확히 예측하도록 하는 데 중점을 둡니다. 반면, 교사 손실은 모델이 전체 시퀀스 또는 복잡한 구조를 더 효과적으로 학습할 수 있도록 지도하는 데 초점을 맞춥니다.
- 훈련 방식의 차이: 다음 토큰 예측 손실은 모델이 스스로 생성한 출력을 다음 입력으로 사용하는 자기 회귀(self-regressive) 방식을 따릅니다. 반면, 교사 손실은 교사 모델의 출력이나 실제 정답 데이터를 다음 입력으로 사용하여 모델을 강제로 올바른 방향으로 유도합니다.
- 사용 목적의 차이: 다음 토큰 예측 손실은 주로 모델이 시퀀스의 다음 토큰을 예측하는 능력을 향상시키기 위해 사용됩니다. 교사 손실은 모델이 전체 시퀀스 구조를 더 잘 이해하고, 특히 초기 학습 단계에서 빠른 수렴을 도모하기 위해 사용됩니다.
교사 손실은 모델이 실제 데이터의 구조를 더 잘 학습하도록 돕는 반면, 다음 토큰 예측 손실은 모델이 독립적으로 다음 토큰을 예측하는 능력에 중점을 둡니다. 이 두 손실 함수는 모델의 학습 목적과 구조에 따라 선택적으로 사용될 수 있습니다.
Exploring Alternative Hydra Head Architectures
Hydra-specific prefix attention
MLP 기반 하이드라 헤드는 이미 생성된 시퀀스의 표현을 입력으로 받아들일 때, 기본 모델의 가장 최근 처리된 토큰에 해당하는 hidden state만을 사용합니다. 그러나 기본 모델이 하이드라 헤드와 독립적으로 훈련되기 때문에, 마지막 토큰의 숨겨진 상태에 컨텍스트에 대한 충분한 정보가 인코딩되어 있는지 명확하지 않습니다.
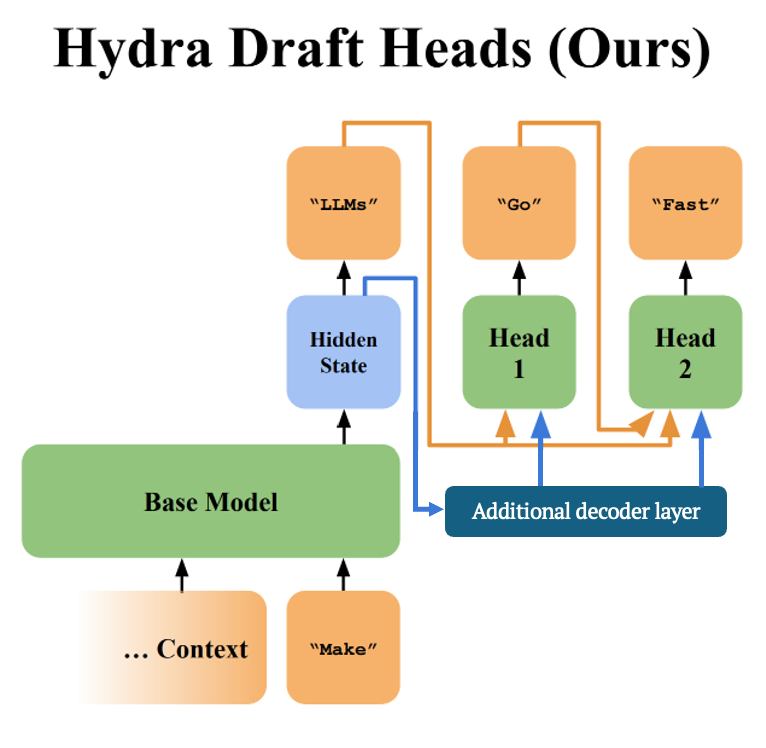
하이드라 헤드가 전체 컨텍스트에 대한 관련 정보를 더 잘 집계하여 사용할 수 있도록, 기본 LLM에 추가적인 디코더 계층을 확장하여 초안 모델을 위한 더 나은 입력 표현을 생성하도록 제안합니다. 각 하이드라 헤드는 여전히 single layer MLP이지만, 이제 이미 생성된 시퀀스의 최종 토큰의 표현을 추가적인 디코더 계층의 입력으로 받습니다. 추가적인 디코더 계층은 하이드라 헤드와 함께 훈련되므로, 이미 생성된 시퀀스에서 하이드라 헤드에 유용한 정보가 무엇인지 학습할 수 있습니다. 모든 하이드라 헤드가 같은 추가 디코더 계층의 숨겨진 상태를 공유한다는 점을 주목하며, 이는 추가 디코더 계층이 하이드라 디코딩 단계마다 한 번만 조회된다는 것을 의미합니다. 이렇게 추가 디코더 계층과 표준 MLP를 결합한 하이드라 헤드 아키텍처를 PrefixMLP 하이드라 헤드 아키텍처라고 합니다.
이해한대로 그림을 그려봤습니다. (이해한게 틀릴 수도 있음..)
results
Hydra-specific decoder layer을 추가하는 것이 모델링 성능을 향상시키는지 테스트하기 위해, 제안한 PrefixMLP 아키텍처를 사용한 디코딩과 표준 MLP만을 사용한 하이드라 헤드를 사용한 디코딩을 비교했습니다. PrefixMLP 헤드를 사용한 디코딩이 평균 수용 길이를 1.12배 향상시켜 평균 디코딩 처리량을 1.08배 개선하는 결과를 얻었습니다.
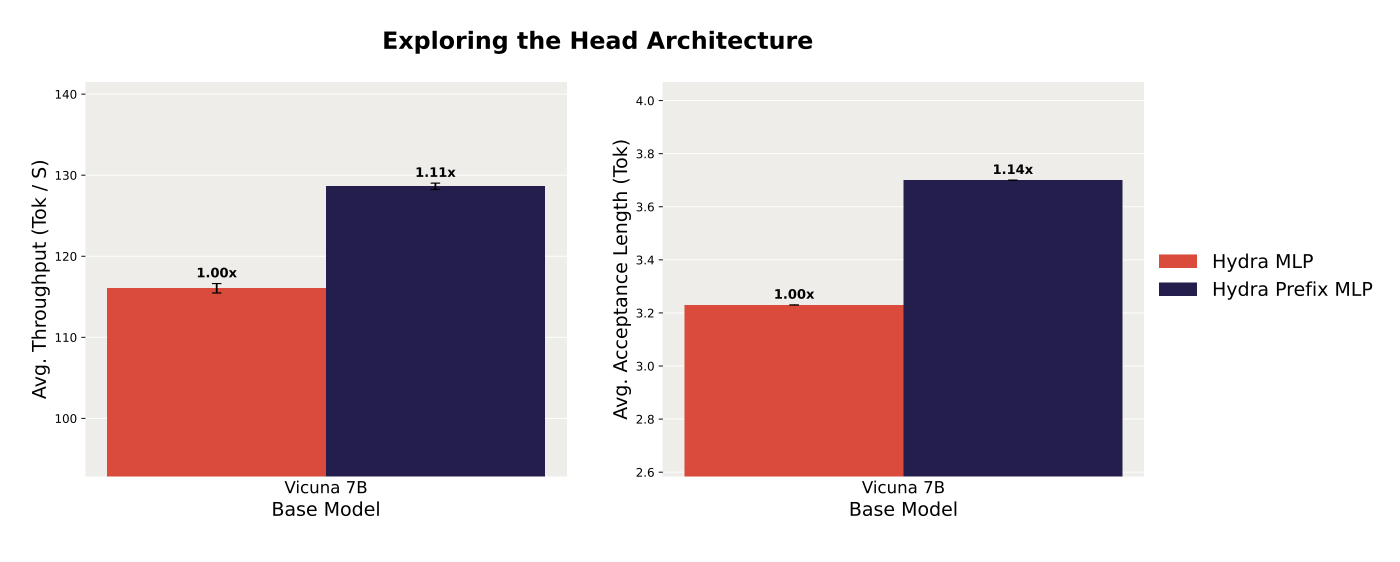
이 결과는 생성된 시퀀스에서 컨텍스트를 하이드라 헤드가 인지하는 방식으로 집계하는 것이 하이드라 디코딩 성능을 향상시킨다는 것을 시사합니다.
Hydra++: The Most Performant Hydra Model
이번 섹션에서 가장 뛰어난 hydra head 조합인 hydra++를 제안한다.
hydra++는 teacher loss와 prefixMLP head architecture를 사용해서 학습된다.
히드라 헤드에 대한 개입이 히드라 디코딩에 미치는 누적 영향을 이해하기 위해 표준 자기회귀 디코딩, 메두사 디코딩 및 히드라 디코딩의 원래 공식화에 대해 히드라++를 평가한다.
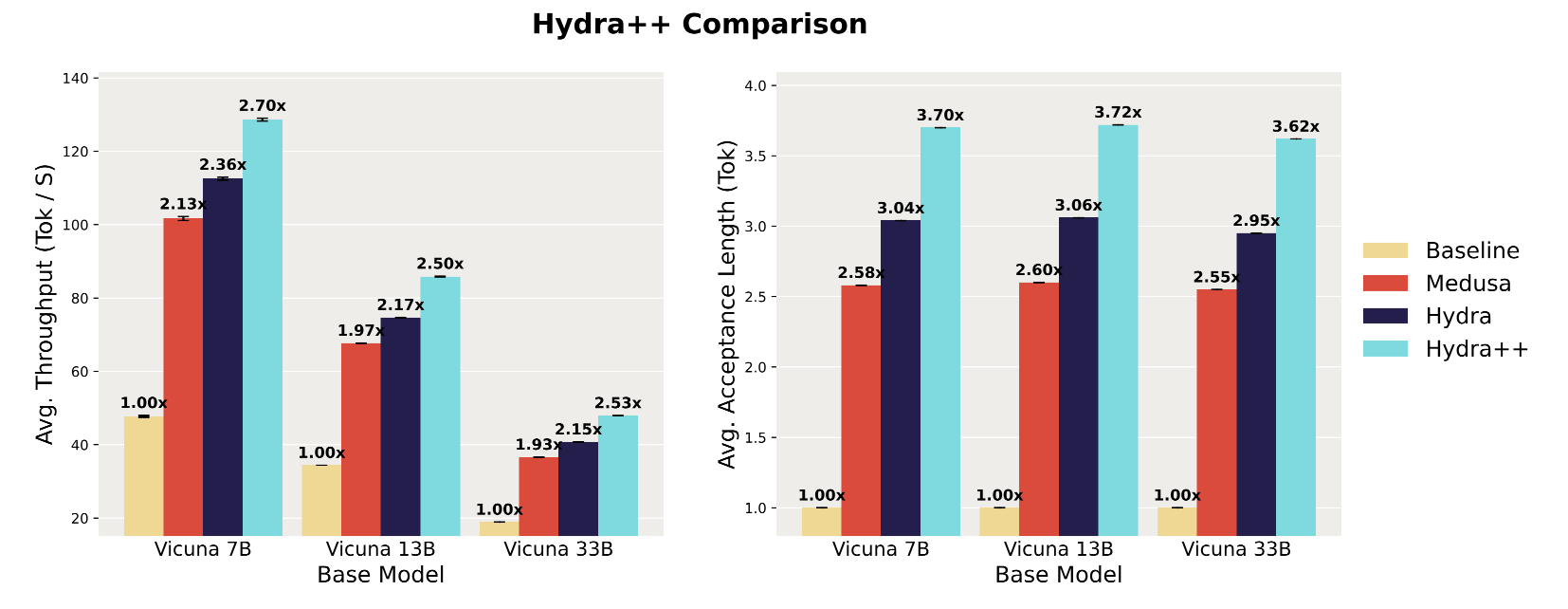
results
figure 5의 다른 기본 라인들과 비교하여 Hydra++의 디코딩 성능을 비교한다. Hydra++는 상당한 속도 향상을 생성하여 Vicuna 7B, 13B 및 33B에 대한 자기 회귀 디코딩에 비해 디코딩 처리량을 각각 2.7배, 2.5배 및 2.53배 향상시킨다. Medusa 디코딩에 비해 Hydra+는 Vicuna 7B, 13B 및 33B에 대해 처리량을 각각 1.27배, 1.27배 및 1.31배 향상시킨다. 마지막으로, 원래 Hydra 헤드 공식을 사용한 디코딩에 비해 Hydra+는 Vicuna 7B, 13B 및 33B에 대해 각각 1.14배, 1.15배 및 1.18배 향상시킨다. 이러한 결과는 다른 훈련 및 아키텍처 개입과 함께 sequentailly dependent draft head가 표준 드래프트 헤드에 비해 상당히 개선되었음을 시사한다.
Typical Acceptance Sampling
지금까지 제시된 모든 결과들은 그리디(greedy) 수용 기준을 사용하여, 토큰들이 기본 LLM의 그리디 다음 토큰 예측과 일치할 때만 검증되었습니다. 이 섹션에서는 Cai et al. (2024)에 의해 제안된 전형적인 수용 검증 기준을 통한 비그리디(non-greedy) 샘플링을 고려합니다.
Typical acceptance criterion의 목적은 그리디 수용보다 더 다양하고 창의적인 시퀀스를 샘플링하는 것이며, 추측적 디코딩의 효율성 이점을 보존하는 것입니다.
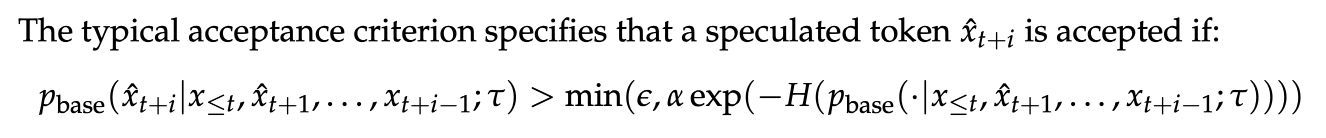
where ϵ is known as the posterior threshold, α is known as the posterior alpha, τ is the sampling temperature, and H(·) is the entropy.
설명해보자면, H(·) 엔트로피가 높다는 것은 분포가 고르다는 것이고, 확실한 토큰이 없다는 것이다. 엔트로피가 크면 αexp(-H(·))가 작아지고, 더 많은 후보군을 만드는 것을 허용하게 된다.
반대로 엔트로피가 작다는 것은 확실한 후보, 즉 easy token이 존재한다는 것이고 후보군을 적게 만들게 된다.
results
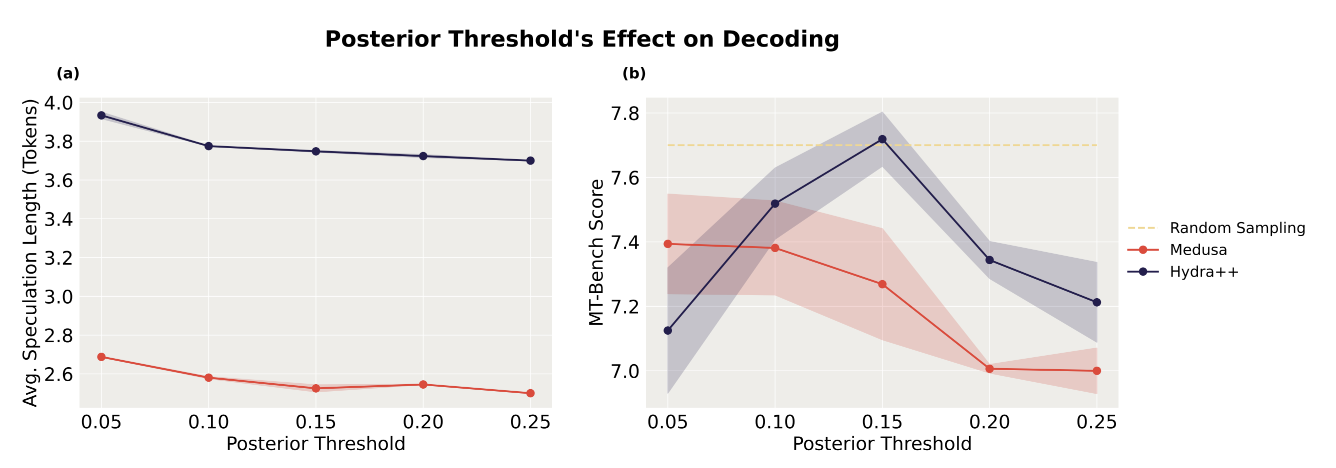
그림 6에서는 posterior threshold을 변화시킬 때 average speculation length와 생성물의 품질이 어떻게 영향을 받는지를 나타냈습니다. Medusa와 Hydra++ 모두에서 후방 임계값을 증가시키면 평균 추측 길이는 약간 감소하지만, 검토된 모든 posterior threshold에 대해 hydra++는 메두사보다 훨씬 더 높은 average acceptance length를 나타냈습니다. Hydra++의 posterior threshold과 MT-Bench 점수 사이에는 monotonic relation가 발견되지 않았습니다. 그러나 posterior threshold 값의 최적 설정(ϵ=0.15)에서 하이드라 플러스는 메두사보다 MT-Bench에서 더 좋은 점수를 달성하며, 기본 모델에서의 랜덤 샘플링과 필적할 수 있는 성능을 달성했습니다.
이러한 결과는 하이드라 디코딩에서 typical acceptance을 검증 체계로 사용하면 높은 평균 추측 길이를 유지하면서 기본 모델을 샘플링하는 것과 유사한 성능을 가질 수 있음을 보여준다.
Conclusion
이 연구에서는 초안 헤드 기반의 추측적 디코딩을 체계적으로 검토하고 초안 헤드의 추측 품질을 향상시키는 방법을 제안합니다. 기존에 제안된 초안 헤드들이 시퀀셜하게 독립적이라는 점, 즉 미래의 i개 토큰에 대해 추측할 때, 초안 헤드의 예측이 1번째, 2번째, ... (i-1)번째 추측된 토큰들에 의존하지 않는다는 문제점을 관찰했습니다. 이 문제를 해결하기 위해, 표준 초안 헤드를 대체할 수 있는 sequential dependent한 하이드라 헤드를 제안합니다. 하이드라 헤드는 후보 연속에 있는 토큰들의 기본 모델 입력 임베딩을 입력으로 취함으로써 시퀀셜하게 의존적이 됩니다. 이 간단한 변화는 디코딩 속도의 상당한 개선을 이끌어내며, 하이드라 디코딩은 메두사 디코딩에 비해 최대 1.11배의 종단 간 처리량 향상을 달성합니다. 또한, 하이드라 헤드의 다양한 훈련 목표와 아키텍처를 조사합니다. teacher loss에 기반한 훈련이 헤드 품질과 종단 간 디코딩 속도를 향상시키는 것을 발견했습니다. 우리는 기본 모델의 숨겨진 상태를 더 잘 인코딩하기 위해 추가적인 디코더 계층을 도입하는 PrefixMLP라고 부르는 하이드라 헤드 아키텍처를 실험합니다. PrefixMLP 하이드라 헤드 사용은 디코딩 속도를 더욱 증가시킵니다. 모든 하이드라 헤드 개선사항을 하이드라++라고 부르는 하이드라 헤드 레시피로 결합함으로써, 메두사와 자동 회귀 디코딩에 비해 각각 최대 1.31배 및 2.7배의 디코딩 처리량 증가를 달성합니다. 초안 헤드 기반의 추측적 디코딩은 표준 추측적 디코딩 패러다임에 대한 효율적이고 간단한 대안이며, 우리의 작업은 시퀀셜하게 의존적인 초안 헤드의 구축을 통해 초안 헤드를 사용한 디코딩의 성능을 극대화하는 중요한 단계를 밟습니다.
내 생각
결국 non autoregressive하게 생성한 것이다. 그치만 품질 향상을 시킴..
그럼 glide and cape랑 비교했을때 뭐가 더 품질이 좋을까? 그리고 누가 더 빠를까? 이런 생각..
