with chatGPT 제정신일때 예쁘게 정리해서 다시 올려야지.;;
Introduction
이 연구는 대규모 언어 모델(Large Language Models, LLMs)의 서빙 지연 시간을 줄이기 위한 새로운 솔루션을 제안합니다. 대규모 언어 모델은 실시간 반응이 필요한 다양한 응용 프로그램에서 사용되고 있지만, 자동 회귀 변환기(autoregressive transformer) 아키텍처에 기반을 두고 있어, 출력 토큰을 단계별로 생성하는 과정에서 특히 더 큰 모델 크기로 인해 높은 지연 시간을 겪습니다. 이를 해결하기 위해, 추측적 디코딩(Speculative Decoding, SD)이 유망한 해결책으로 제시되었습니다. SD의 핵심 아이디어는 더 작고 효율적인 초안 모델(draft model)을 사용하여 출력 시퀀스에서 다음 γ 토큰을 예측하고, 이를 원래 LLM(목표 모델)이 병렬로 검증하게 하는 것입니다.
연구는 SD 가속화를 위해 두 가지 방향에서 새로운 솔루션을 제안합니다. 첫 번째 방향은 초안 모델의 예측이 목표 모델의 예측과 더 밀접하게 일치할수록 제안된 토큰이 수용될 가능성이 높다는 직관에 기반합니다. 이를 위해, 초안 모델을 목표 모델과 정렬시키기 위한 증류 훈련(distillation training)을 제안합니다. 두 번째 방향은 초안 모델이 목표 모델이 검증할 수 있는 여러 후보 시퀀스를 제안하도록 함으로써 수용 가능성을 높이는 것입니다. 이를 위해, 다중 초안 모델을 사용하거나 다중 예측 헤드를 사용하여 비자동 회귀 방식으로 여러 후보 토큰 시퀀스를 제안하는 방법이 탐색되었습니다.
이 연구에서는 GLIDE라는 새로운 모델을 소개합니다. GLIDE는 초안 모델이 목표 모델의 KV(key-value) 캐시를 활용하여 목표 모델이 더 쉽게 수용할 수 있는 토큰을 제안할 수 있게 합니다. 또한, Confidence-aware Proposal Expansion(CAPE) 방법을 도입하여 제안된 후보 시퀀스를 추가 후보 토큰으로 확장합니다. 이 방법은 제안된 토큰의 예측 신뢰도가 그 토큰이 목표 모델에 의해 수용될 가능성과 긍정적인 상관관계가 있다는 관찰에 기반합니다.
GLIDE와 CAPE의 효과는 Vicuna와 Mistral 목표 모델을 사용한 네 가지 데이터셋에서의 실험을 통해 입증되었습니다. GLIDE는 목표 모델의 KV 캐시에 주의를 기울임으로써 최대 23.5%까지 수용률을 향상시켰고, 기존 초안 모델들에 비해 평균 19.9%의 수용률 향상을 달성했습니다. CAPE를 GLIDE에 통합한 추가 실험은 Vicuna 모델에서 2.50배에서 2.61배까지의 속도 향상을 달성했다고 보고합니다.
Our Method
SD를 가속화하는 우리의 방법은 두 부분으로 구성된다.
(1) 우리는 draft 모델의 현재 제안 생성을 지원하기 위해 target 모델의 마지막 verification 과정에서 계산된 KV 캐시를 "엿보기(catches a glimpse of)"하는 GLIDE라는 draft 모델을 설계한다.
(2) 우리는 draft 모델의 confidence score를 사용하여 제안 시퀀스의 각 위치에 포함할 상위 순위 토큰의 수를 동적으로 결정하는 CAPE라는 제안 확장 메커니즘을 제안한다.
GLIDE: Glimpse Draft Model
draft 모델과 target 모델이 모두 standard draft-only 아키텍처를 따른다고 가정
draft 모델이 target 모델에 의해 계산되고 캐시된 접두사 토큰의 숨겨진 표현을 활용할 수 있도록 하기 위해, 저희는 GLIDE(glimpse draft 모델)라는 draft 모델을 위한 새로운 아키텍처를 제안합니다.
GLIDE를 사용하면 초안 모델 MD가 대상 모델 MT에서 캐시된 Key-Value 쌍을 재사용할 수 있으며, 아마도 많은 추가 계산 비용을 들이지 않고 MD의 distribution를 MT의 distribution와 더 일관되게 만들 수 있습니다. MD는 MT가 동결된 상태에서 GLIDE 아키텍처를 기반으로 처음부터 훈련될 것입니다.
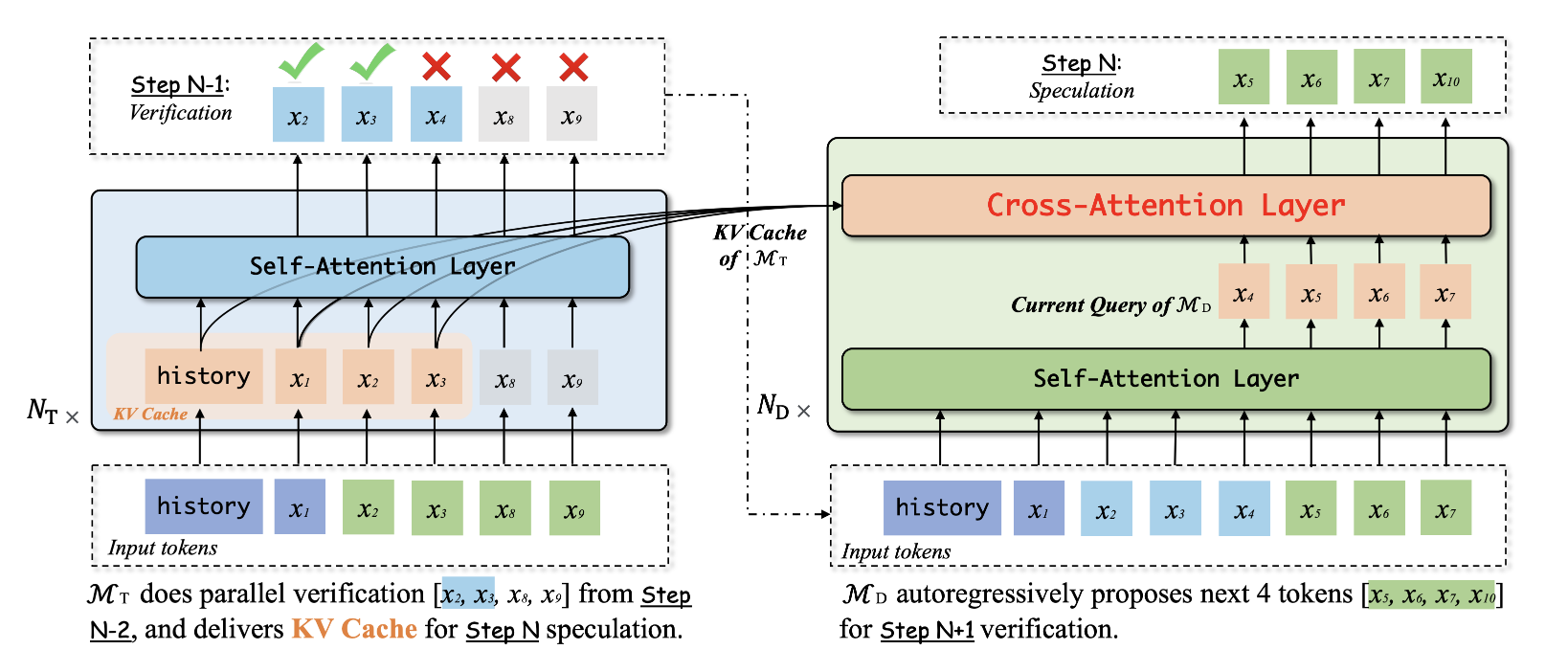
구체적으로, 마지막 speculation round에서 MD가 검증을 위해 MT로 전달되는 토큰 시퀀스를 제안했다고 가정한다.
그 다음 후속 검증 단계에서 MT가 xt-1까지의 시퀀스를 수락하고 추가 토큰 xt를 생성한다고 가정한다. 이 검증 단계 이후, 토큰에 대한 KV 캐시만 위치(t - 1)까지 유지하고 MT에 의해 거부된 토큰에 대한 KV 캐시를 폐기할 것이다. 그림 2의 왼쪽은 검증 과정을 보여주는데, 여기서 회색 큐브는 폐기된 KV 캐시를 나타낸다.
이제 접두사 x≤t가 주어졌을 때, 현재 speculation round의 초안 모델 MD가 x t+1에서 x t+i-1로 토큰화할 것을 제안했다고 가정한다.
바닐라 추측 디코딩에서, MD는 MT와 독립적으로 작동한다. 그러나, 우리가 제안한 GLIDE 아키텍처에서, 우리는 xt-1까지 MT의 캐시된 키와 접두사 토큰과 연관된 값을 재사용하기를 원한다. 그렇게 하기 위해, 우리는 그림 2의 오른쪽에 표시된 것과 같이, MD의 각 트랜스포머 계층의 self-attention sub-layer와 feed-forward sub-layer 사이에 cross- attention sub-layer를 삽입한다.
이 추가 계층은 먼저 아래 self-attention sub-layer에서 t와 (t + i - 1) 사이의 출력을 MT의 Key-Value와 호환되는 차원의 쿼리 벡터로 투영한다. 그런 다음, 이 cross-attention sub-layer은 MD의 이러한 쿼리와 MT의 KV 캐시 사이의 standard cross-attention을 수행한다. 결과적인 벡터는 위의 feed-forward sub-layer으로 전달될 것이다.
h : MT self attention layer의 헤드 개수
(Klj, Vlj) : MT에서 l번째 레이어의 j번째 헤드
Hm : MD의 m번째 self-attention sub-layer에서 마지막 i 출력 벡터. 이 i 벡터는 t ~ (t+i-1)에 대응함.
MD에서의 숨겨진 벡터의 차원 d_D는 일반적으로 MT의 키의 차원 d_k와 다르며, MT에는 h개의 attention heads가 있기 때문에, 우리는 먼저 h개의 선형 투영을 수행하여 H^m을 MT의 각 head마다 하나씩 h개의 다른 쿼리 행렬로 투영합니다. 여기서 Q^m_j = H^m W_j는 각각 j에 대해 학습 가능한 매개변수 W_j를 가지고 있습니다. 교차 주의를 수행하기 위해서는, MD의 각 레이어가 MT의 상응하는 레이어에 주의를 기울이며, 이는 상위 레이어에서 시작합니다. 이 방식을 통해, 우리는 상위 레이어의 MT KV 캐시를 사용하려고 합니다. 왜냐하면 상위 레이어가 더 맥락화되어 있고 따라서 더 나은 표현을 제공한다고 가정하기 때문입니다.
Qmj = HmWj
예를 들어서 h=8이라고 하고, Hm이 512 차원이고 MT의 key, value vector dimension이 64라고 하자.
그럼 Wj는 512*64차원의 행렬이고, 이를 통해서 8개의 Q1, ... Q8을 만들어낸다.
cross attention을 수행하기 위해, MD의 각 레이어는 상위 레이어부터 시작하여 MT의 해당 레이어에 주의를 기울입니다. 이 방식을 통해, 우리는 MT의 상위 레이어에서 KV 캐시를 사용하려고 합니다. 이는 상위 레이어가 보통 더 맥락화되어 있고 따라서 더 나은 표현을 제공한다고 가정하기 때문입니다.
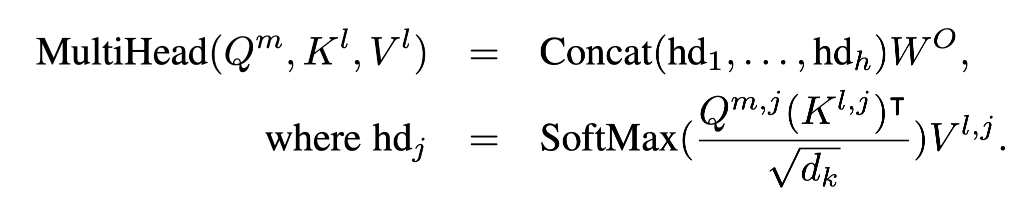
여기서 l = NT - ND + m인데, MT에서 더 상위의 KV cache에 대응하기 위해서 이렇게 설정되었다.
blockwise attention mask
마스크를 사용함으로써, 훈련 중인 MD가 실제 추론 시점에서 경험하게 될 지연된 KV 캐시 상황을 모방하여, 지연된 상황에서도 정확한 예측을 할 수 있도록 준비됩니다.
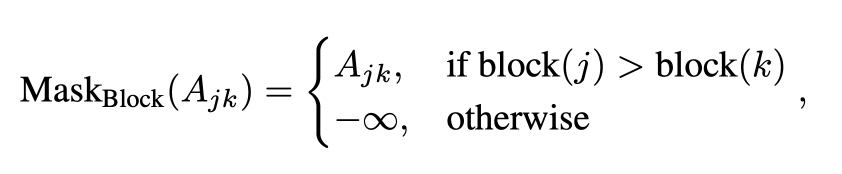
블록 단위 주의 마스크(block-wise attention mask) 개념을 예를 들어 설명해보겠습니다. 가정해 봅시다. 시퀀스가 다음과 같이 15개의 토큰으로 구성되어 있고, 각 블록의 길이 L이 5라고 합니다.
시퀀스: [A, B, C, D, E, F, G, H, I, J, K, L, M, N, O]
이 시퀀스를 길이가 5인 블록으로 나누면 다음과 같이 세 블록이 됩니다:
- 1번째 블록: [A, B, C, D, E]
- 2번째 블록: [F, G, H, I, J]
- 3번째 블록: [K, L, M, N, O]
이제 초안 모델 MD가 'H'라는 토큰을 예측하려고 한다고 가정해 보겠습니다. 'H'는 2번째 블록에 속합니다. 교차 주의를 할 때 MD는 2번째 블록의 왼쪽에 있는 토큰들, 즉 [F, G]의 표현만을 사용합니다. 또한 MD는 1번째 블록에 속한 토큰들, 즉 [A, B, C, D, E]의 KV 캐시에는 주의를 기울일 수 있지만, 'H'를 포함하여 2번째 블록의 KV 캐시에는 주의를 기울이지 않습니다.
블록 단위 주의 마스크를 사용하여 이를 구현하려면, 주의 행렬 A에서 'H'에 해당하는 행의 원소들이 마스크 처리됩니다. 'H'가 2번째 블록에 속하므로, block(H) = 2입니다. 이제 'F'와 'G'에 해당하는 열의 원소는 그대로 유지되지만, 'H'에 해당하는 열의 원소는 마스크 처리되어 \( -\infty \)로 설정됩니다. 이는 소프트맥스 함수를 적용할 때 이 원소들이 사실상 0으로 만들어져서 'H'의 KV 캐시를 고려하지 않도록 하는 것입니다.
이렇게 마스크를 적용함으로써, MD는 훈련 중에 실제 추론 단계에서 경험하게 될 지연된 KV 캐시를 모방할 수 있습니다. 이 방식으로 훈련된 MD는 실제 운영 환경에서도 지연된 KV 캐시가 있을 때 효과적으로 작동할 수 있습니다.CAPE: Confidence-Aware Proposal Expansion
CAPE는 2가지 구성요소로 되어있다. 1) proposal expansion mechanism, 2) crresponding verification mechanism
proposal expansion
pD(·|x<t+i) : the next token distribution computed by the draft model MD
pi = maxpD(·|x<t+i)
이때 pi의 범위에 따라서 S(p) 함수에 따라 Ki(expansion set Xi의 크기)를 결정한다.
S(p) to be 7, 5, 3, and 1 for p in the ranges of (0, 0.3], (0.3, 0.6], (0.6, 0.8], and (0.8, 1], respectively. --> confidence가 낮을 수록 K값이 올라감. 즉, 후보를 많이 만들어둔다는 뜻!
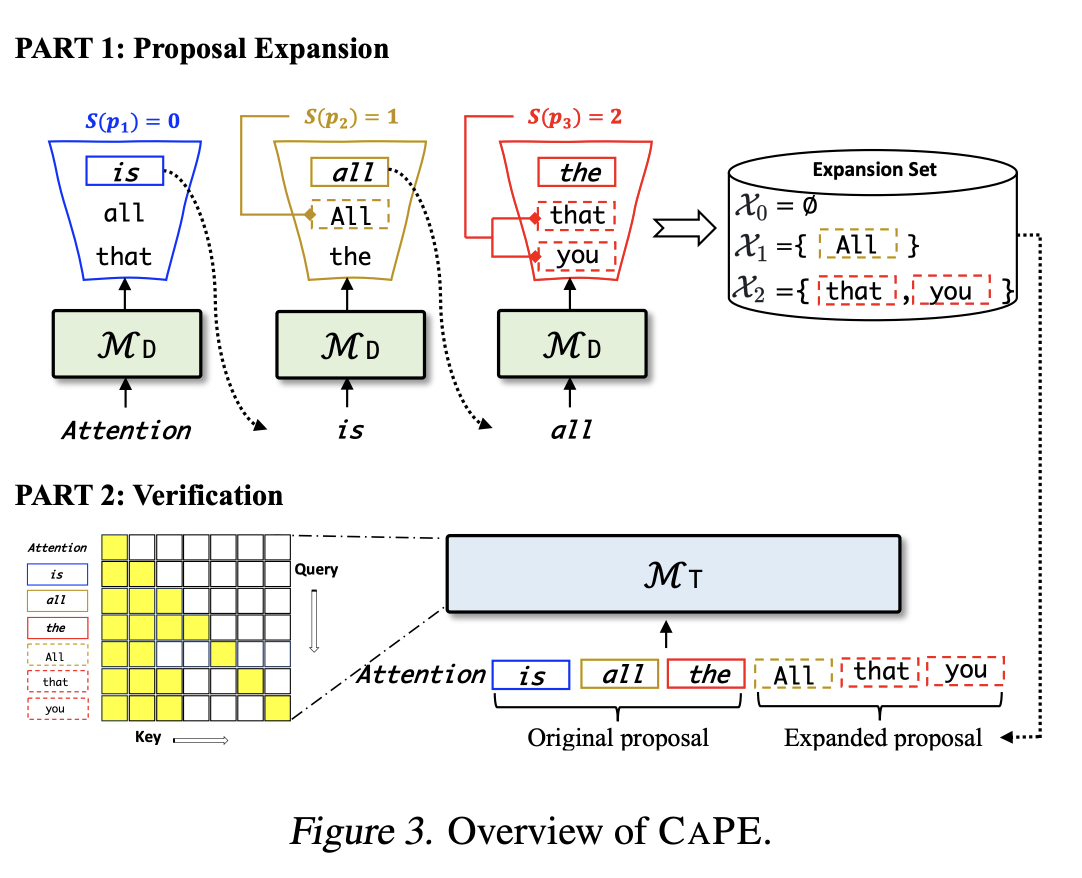
Fig3을 통해서 설명하자면, S(p2) = 1이라는 것은, X1의 expansion set의 크기가 1이라는 것을 의미한다.
중요한 점은 확장 세트의 구성이 초안 모델의 추론을 느리게 하지 않으며, 확장 세트에 있는 토큰들은 미래 토큰들을 예측하는 데 사용되지 않는다는 것입니다. 이는 빔 탐색(beam search)을 사용한 제안 확장과는 주요한 차이점입니다. 빔 탐색에서는 각 위치에서 상위-k 토큰 각각을 사용하여 후속 토큰들을 생성하는데, 이는 많은 가지(branch)를 가진 트리 구조의 확장 제안을 만들어내며, 계산 비용이 많이 들고 효율성이 떨어집니다.
Verification of Expanded Proposals
추가적인 후보 토큰을 각 위치에서 갖기 때문에 verification mechanism의 수정이 필요하다.
토큰 트리 verifier에서 아이디어를 착안함.
먼저, linearizean expanded proposal into a single sequence by simply appending the tokens in the expansion sets to the end of the proposal.
--> 위의 Figure3로 설명을 하자면, 후보로 뽑은 애들을 그냥 Linear하게 늘어놓아라.
Attention is all the / all that you
그다음 special causal mask를 사용해서 MT에서 병렬적으로 검사하게 패스한다.
이 마스크는 다음을 따른다.
That means, for i > γ, pos(i) = j where xt+i ∈ Xj .
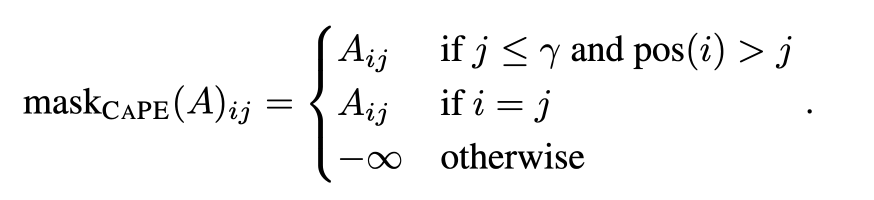
| Attention | is | all | the | All | that | you |
|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 |
| 1 → X1 | 2 → X2 | 2 → X3 |
설명을 하자면, All이 X1이라는 expansion set에서 나왔다. Xj의 j를 pos(i)의 값으로 쓰자니까 pos(index of 'All') = 1인 것이다.
이를 토대로 마스크를 적용해보면
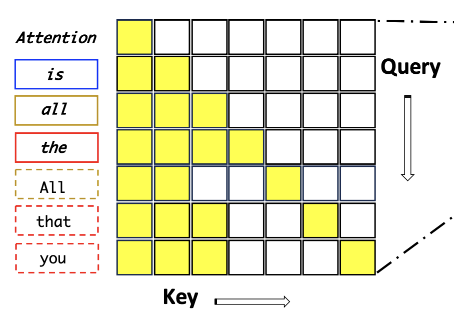
이런 그림이 나온다.
이 마스크는 훈련 중에 모델이 미래의 토큰들에 대한 정보를 사용하지 못하게 하여, 모델이 실제 추론 시점에서 겪을 상황을 잘 반영하도록 합니다. 결과적으로, 모델은 각 토큰이 실제 사용될 문맥에서 얼마나 타당한지를 더 정확히 평가할 수 있게 됩니다.
Experiment
Experiment desing
GLIDE와 CAPE의 효율성을 따로 판단하기 위해서 2 세트의 실험을 디자인함.
1) GLIDE w/o CAPE -> 수용률(acceptance rate)과 예상 속도 향상(expected speedup)을 평가 지표로 채택. draft model이 생성할 토큰의 개수 γ는 5로 설정, acceptance strategy : speculative sampling
2) we compare GLIDE+CAPE with Medusa and GLIDE+BeamSearch.
Evaluation of GLIDE
Effectiveness of attending to target model’s KV cache
1) GLIDE는 target 모델의 KV 캐시를 재사용하기 위해 cross attention를 사용
2) Vanilla Draft는 KV 캐시 미사용 외에는 동일
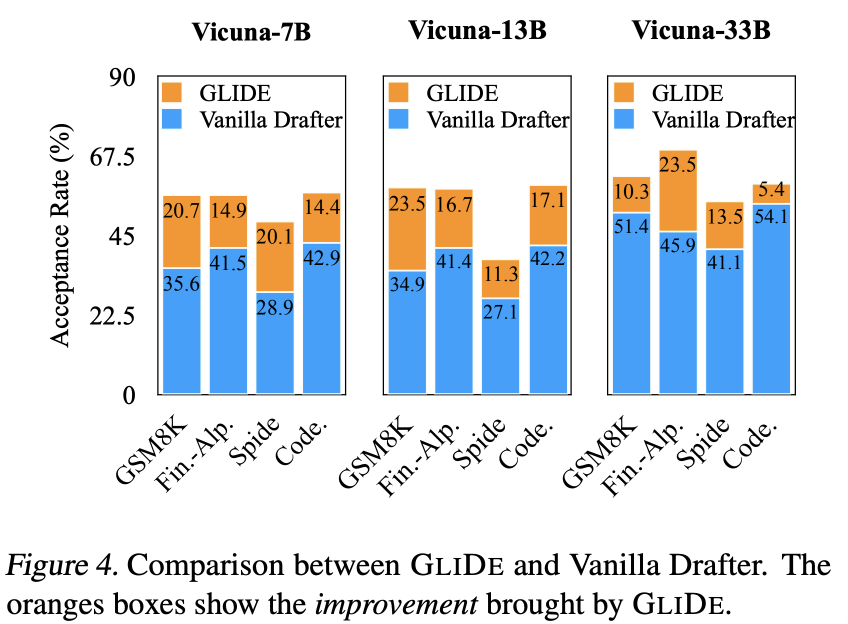
실험 비용을 줄이기 위해 SlimPajama-6B 데이터의 절반을 무작위로 추출하여 GLIDE와 Vanilla Drafter 모두를 훈련시킵니다. 두 모델을 ShareGPT에서 추가로 미세 조정합니다. GSM8K, Fin.-Alp., Spider 및 Code 데이터셋에서 실험을 진행합니다. GLIDE가 Vanilla Drafter보다 항상 현저하게 높은 수용률을 보인다는 것을 발견했습니다.
그림 4에서는 네 데이터셋에서 Vanilla Drafter에 비해 GLIDE가 수용률을 얼마나 향상시켰는지 보여줍니다. 수용률의 향상은 5.4에서 23.5 퍼센트 포인트 사이에 있으며, 대부분의 설정에서는 10 퍼센트 포인트가 넘는 향상을 보입니다. 이렇게 큰 향상을 고려할 때, 초안 모델이 제안된 시퀀스의 품질을 개선하고 따라서 수용률을 향상시키기 위해 목표 모델의 KV 캐시를 재사용하는 것이 매우 효과적임을 결론지을 수 있습니다.
Comparison between GLIDE and other draft models

GLIDE는 SlimPajma-6B 전체 데이터셋으로 학습한 후 ShareGPT로 파인튜닝한 모델로, LLAMA-68m, LLAMA-160m 및 LLAMA-45m과 비교되었습니다. 비교는 비용 계수(Cost, 비용 계수), 수락률(Acc., 수락률), 예상 속도 향상(E(Spd.), 예상 속도 향상) 세 가지 메트릭으로 이루어졌습니다. 표에서 발견된 결과는 다음과 같습니다. (1) GLIDE의 비용 계수는 LLAMA-68m 또는 LLAMA-45m와 비교할 만큼 매우 낮습니다. 비용 계수는 대상 모델과 대조하여 초당 시간 비용을 측정하며, 5% ~ 6%의 비용 계수는 GLIDE 초안 모델의 시간 비용이 대상 모델의 것과 무시할 정도라는 것을 의미합니다. (2) 수락률 및 예상 속도 향상 측면에서, GLIDE 초안 모델은 모든 설정에서 기준 초안 모델보다 우월하며, 개선은 모두 통계적으로 유의합니다. (3) GLIDE의 수락률은 일반적으로 55%에서 70% 사이로, 제안된 토큰의 절반 이상이 수락됨을 의미합니다. 비교적 기준 초안 모델은 때로 약 30%의 수락률만 갖고 있습니다. 비슷하게, GLIDE의 예상 속도 향상은 1.67에서 2.24 사이로, 기준 초안 모델의 경우 LLAMA-68m 및 LLAMA-45m에서는 항상 1.5 미만이고 LLAMA-160m에서는 항상 1.0 미만입니다. 요약하면, 표 1의 결과는 다시 한번 GLIDE의 효과적임을 입증합니다.
비용 계수(cost coefficient)는 드래프트 모델 MD과 타겟 모델 MT 간의 상대적 실행 시간(walltime) 비용을 측정하는 지표입니다. 구체적으로, 드래프트 모델 한 번의 실행 시간과 타겟 모델 한 번의 실행 시간 사이의 비율로 정의됩니다. 이 계수는 드래프트 모델의 계산 비용을 타겟 모델의 그것과 비교하여 표현한 것으로, 이 값이 낮을수록 드래프트 모델의 실행 시간 비용이 타겟 모델에 비해 상대적으로 낮음을 의미합니다.
예를 들어, 비용 계수가 0.05(5%)라면, 이는 드래프트 모델의 실행 시간이 타겟 모델의 실행 시간의 5%에 해당함을 나타냅니다. 즉, 타겟 모델을 실행하는 데 걸리는 시간이 100초라면, 드래프트 모델을 실행하는 데는 5초만 걸린다는 뜻입니다.
비용 계수는 모델의 효율성을 평가할 때 중요한 지표로 사용됩니다. 낮은 비용 계수는 드래프트 모델이 빠르게 실행될 수 있음을 의미하며, 특히 대규모 모델에서는 실행 시간을 줄이고, 자원을 절약하며, 전체적인 실행 비용을 낮출 수 있어 중요합니다.
Comparison of actual decoding speed
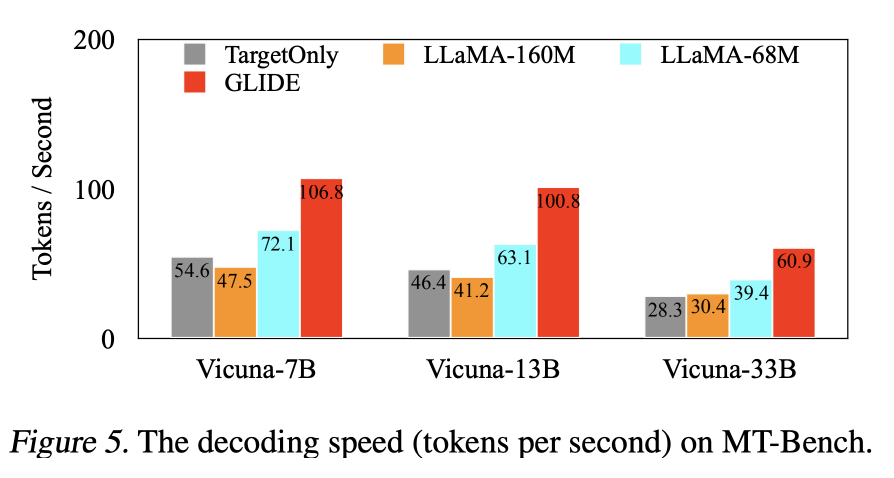
GLIDE의 속도와 기준선의 속도의 비교는 그림 5에 나와 있다. 우리는 GLIDE가 모델의 디코딩 속도를 상당히 가속화한다는 것을 발견했다. 결과는 예상되는 속도 향상과 일치한다. GLIDE를 사용할 때 우리의 가속된 Vicuna-33b 모델이 추측 디코딩이 없는 Vicuna-7b보다 디코딩 속도가 빠르다는 것은 흥미롭다.
Evaluation of CAPE
GLIDE+CAPE를 다음과 같은 베이스라인들과 비교합니다:
(1) 여러 제안을 병렬로 생성하는 비자동 회귀 드래프트 모델을 사용하는 Medusa (Cai et al., 2023), (2) CAPE를 사용하지 않는 GLIDE
(3) 빔 크기를 4로 설정한 GLIDE+BeamSearch.
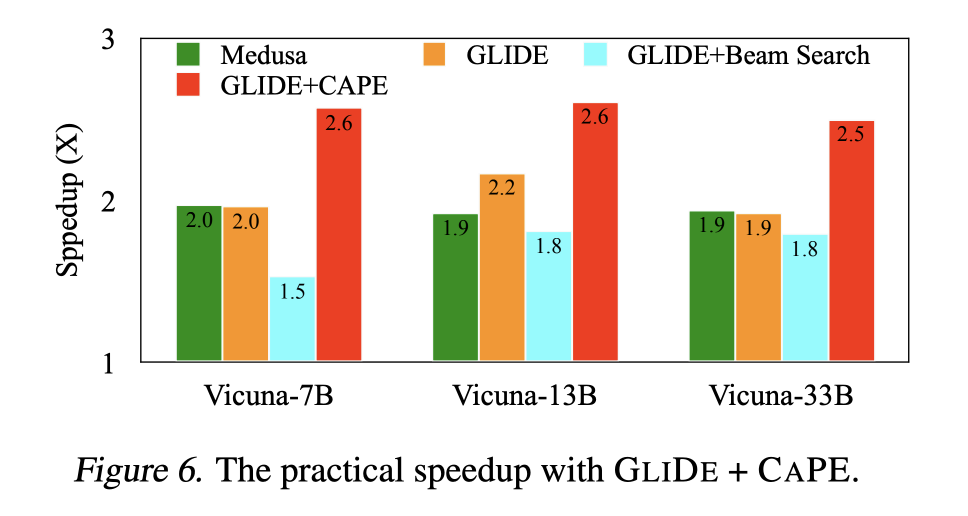
이러한 결과로부터 다음과 같은 발견을 했습니다:
(1) GLIDE+CAPE는 상당한 차이로 모든 베이스라인을 명확하게 능가했습니다.
(2) GLIDE 위에 CAPE를 추가하면 실행 시간 속도 향상이 명확하게 개선됩니다.
(3) CAPE 없이 GLIDE만 사용해도 Medusa보다 더 나은 성능을 보이는 것이 흥미롭습니다.
이는 GLIDE 자체의 효과를 다시 한번 보여줍니다.
Medusa가 타겟 모델의 숨겨진 상태를 드래프트 모델의 제안 생성에 사용하지만, 우리가 사용하는 이전 KV 캐시 전체 대신 마지막으로 검증된 토큰의 숨겨진 상태만을 사용하며, 이는 드래프트 모델의 예측 품질에 영향을 미칠 수 있습니다.
또한, Medusa는 비자동 회귀 방식으로 제안 시퀀스를 생성합니다. 비자동 회귀 언어 모델은 일반적으로 유창성이 낮은 출력 시퀀스를 생성하는 경향이 있습니다. 반면, 우리의 GLIDE 모델은 자동 회귀 모델입니다.
따라서 Medusa의 제안 품질은 우리 것보다 낮을 가능성이 높습니다. 이는 Medusa가 실행 시간 속도 향상 측면에서 우리 방법보다 성능이 떨어지는 또 다른 중요한 요인일 수 있습니다.
(4) GLIDE+BeamSearch가 GLIDE보다 느린 것은, 빔 검색을 사용하여 여러 제안 시퀀스를 생성하는 것이 반드시 유리한 것은 아님을 보여줍니다. 추가 제안 시퀀스는 수용 가능성을 높일 수 있지만, 추측과 검증 동안 이러한 제안을 생성하고 검증하는 것은 추가 비용을 발생시키며, 우리 실험에서는 이러한 이점을 상쇄하는 것으로 보입니다.
우리의 GLIDE+CAPE 방식은 메두사보다 빠를 뿐만 아니라 각 배치에서 제안된 토큰의 수를 메두사보다 적게 검증한다는 점에 주목할 필요가 있다. 우리의 CAPE는 각 단계에서 검증을 위한 토큰의 최대 수를 32개로 설정한 반면, 메두사는 64개로 설정한다. 따라서 우리의 CAPE는 더 큰 배치 크기 추론을 지원할 수 있다.
GLIDE+CAPE 방식이 메두사보다 각 배치에서 검증하는 토큰의 수를 더 적게 하는 점과 이것이 더 큰 배치 크기 추론을 지원할 수 있다는 점 사이의 관계를 설명하겠습니다.
1. 검증을 위한 토큰의 수: 이는 모델이 한 번에 검증 과정을 거칠 토큰의 최대 개수를 의미합니다. CAPE를 사용하면, 이 과정에서 모델이 처리해야 하는 토큰의 수가 최대 32개로 제한됩니다. 반면, 메두사는 최대 64개의 토큰을 한 번에 처리할 수 있도록 설정됩니다.
2. 배치 크기 추론: 배치 크기는 모델이 한 번에 처리할 수 있는 데이터의 양을 의미합니다. 배치 크기가 크면 모델은 한 번에 더 많은 데이터를 처리할 수 있으므로, 일반적으로 처리 효율성이 증가합니다. 그러나, 이는 모델이 충분한 계산 리소스를 가지고 있고, 각 배치의 데이터를 효율적으로 처리할 수 있을 때만 가능합니다.
여기서 중요한 점은, 검증을 위해 처리해야 하는 토큰의 수가 적다는 것이 모델이 한 번에 더 많은 데이터(즉, 더 큰 배치)를 처리할 수 있음을 의미할 수 있다는 것입니다. CAPE가 검증 단계에서 처리하는 토큰의 수를 32개로 제한함으로써, 각 검증 과정이 더 가벼워지고 더 빨리 완료될 수 있습니다. 이는 모델이 더 큰 배치를 더 효율적으로 처리할 수 있게 해, 전체적인 추론 속도를 향상시킬 수 있습니다.
즉, 각 검증 과정에서 처리해야 하는 데이터의 양을 줄이면, 그만큼 모델이 처리할 수 있는 전체 데이터의 양을 증가시킬 수 있고, 이로 인해 더 큰 배치 크기로 추론을 수행할 수 있게 됩니다. 이는 특히 대규모 모델이나 복잡한 데이터 세트를 다룰 때 중요할 수 있으며, 전체적인 시스템의 효율성과 처리 속도를 향상시키는 데 도움이 됩니다.
Further Analysis
Impact of KV cache at different layers
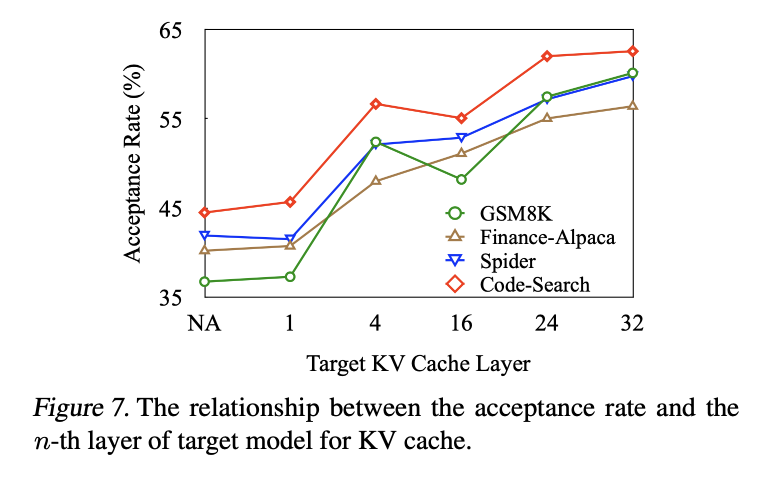
기본 설정에서 초안 모델은 § 4에 설명된 바와 같이 대상 모델의 최상위 계층에서 KV 캐시에 주의한다. 하위 계층의 KV 캐시에 주의하는 것도 가능하다. 실제로 상위 계층의 KV 캐시가 더 효과적인지 확인하기 위해 4개의 데이터 세트에서 미스트랄-7b를 대상 모델로 사용하여 GLIDE를 사용할 때의 수용률을 비교한다. 결과는 그림 7에 나와 있다. 대상 모델의 상위 계층에서 KV 캐시를 명확하게 사용하면 더 높은 수용률이 생성된다는 것을 알 수 있으며, 이는 상위 계층에서 KV 캐시를 사용하는 것이 더 효과적이라는 우리의 가정을 확인시켜준다. 반면 하위 계층에서 KV 캐시를 사용하는 것은 KV 캐시를 전혀 사용하지 않는 것에 비해 여전히 유용하다. 따라서 GLIDE는 잠재적으로 early exit speculative decoding methods(Schuster et al., 2022)과 결합하여 전체 디코딩 시간을 더욱 줄일 수 있다.
Conclusion
본 연구에서는 제안 생성을 개선하기 위해 대상 모델의 KV 캐시를 활용하는 GLIDE라는 모델 아키텍처 초안을 제안한다. 또한 검증을 위한 추가 후보 토큰을 생성하는 CAPE라는 신뢰 인식 제안 확장 메커니즘을 제안한다. 실험은 GLIDE와 CAPE가 모두 추측 디코딩을 가속화하는 매우 효과적인 방법임을 보여준다. 또한 당사의 방법은 월타임 기준으로 강력한 기준 메두사를 크게 능가한다. 전반적으로 GLIDE와 CAPE를 통합하면 Vicuna 모델에서 2.5배의 속도가 향상된다. 향후 작업으로 GLIDE의 배치 서빙과 매우 긴 컨텍스트 처리에서의 효과를 살펴볼 것이다.
