논문 리뷰
1.YOLOv5 아키텍쳐 분석
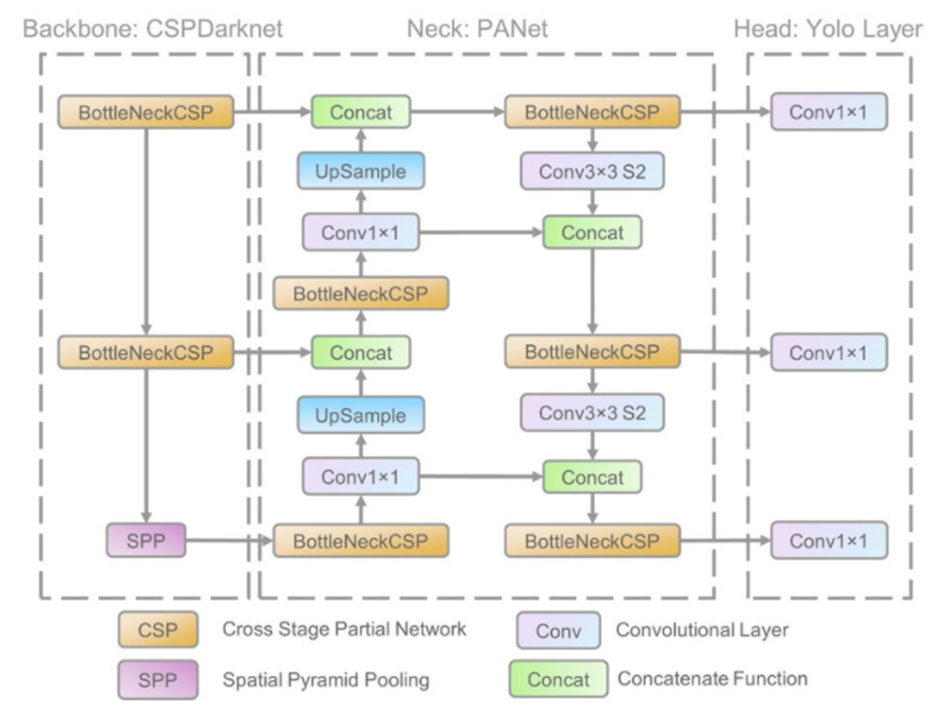
일단 완전 초보인점.. 사전지식이 학부생 그 이상 이하도 아니라는 점 감안하고, 모르는 단어가 있다면 찾아가면서 분석해보겠다.벌써부터 난관이다! backbone, neck, head? 이게 다 뭐람. input layer를 feature map으로 변환한다. 즉, Ba
2.[paper review] Accelerating Transformer Inference for Translation via Parallel Decoding
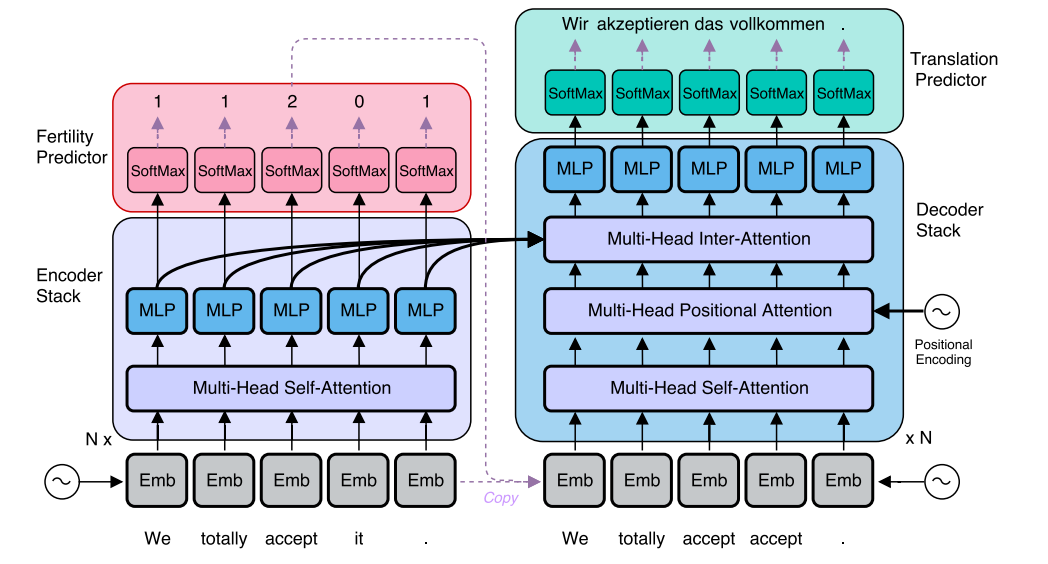
저자는 transformer의 inference time에 많은 시간이 들어간다고 지적하고 있다. 왜냐하면 기존의 autoregressive MT(MT: machine translation)는 이전의 시퀀스를 받아서 현 시퀀스를 생성하는 꼴이다. 이렇게 한번에 하나의
3.self attention 이해하기
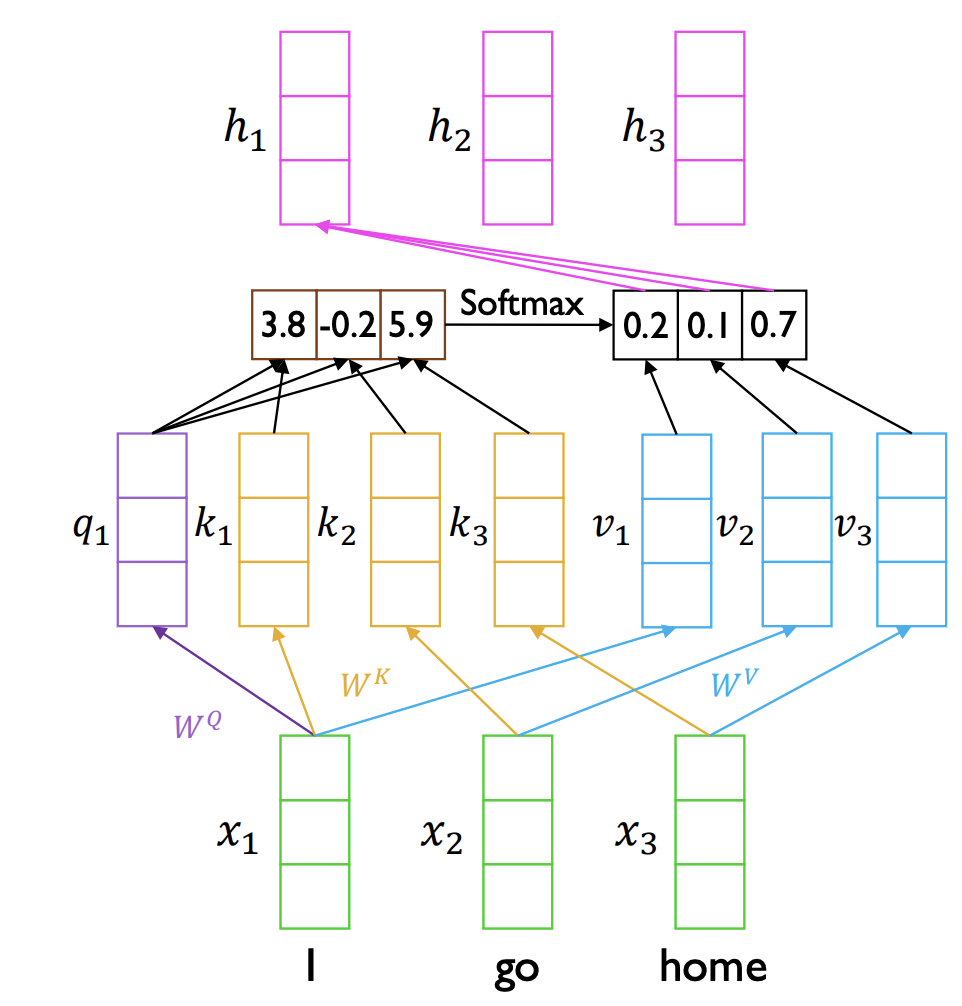
self attention의 Key, Query, Value 간의 이해가 잘 안돼서따로 포스팅을 해보겠다.hidden state: 각 token을 처리할 때마다 생성됨. 이는 해당 시점에서의 토큰이 문장 내에서 어떤 의미를 가지며, 다른 토큰들과 어떤 관계를 맺고 있는
4.[paper review] Improving Language Understanding by Generative Pre-Training

해당 논문은 GPT-1의 구조를 설명하고 있다. Introduction NLP 분야에서 supervised learning은 많은 도메인에서의 적응성을 제한한다. 왜냐면 unlabeled corpora가 labeled corpora보다 훨씬 많기 때문! 라벨링 되
5.[paper review] Unlocking Efficiency in Large Language Model Inference : A Comprehensive Survey of Speculative Decoding
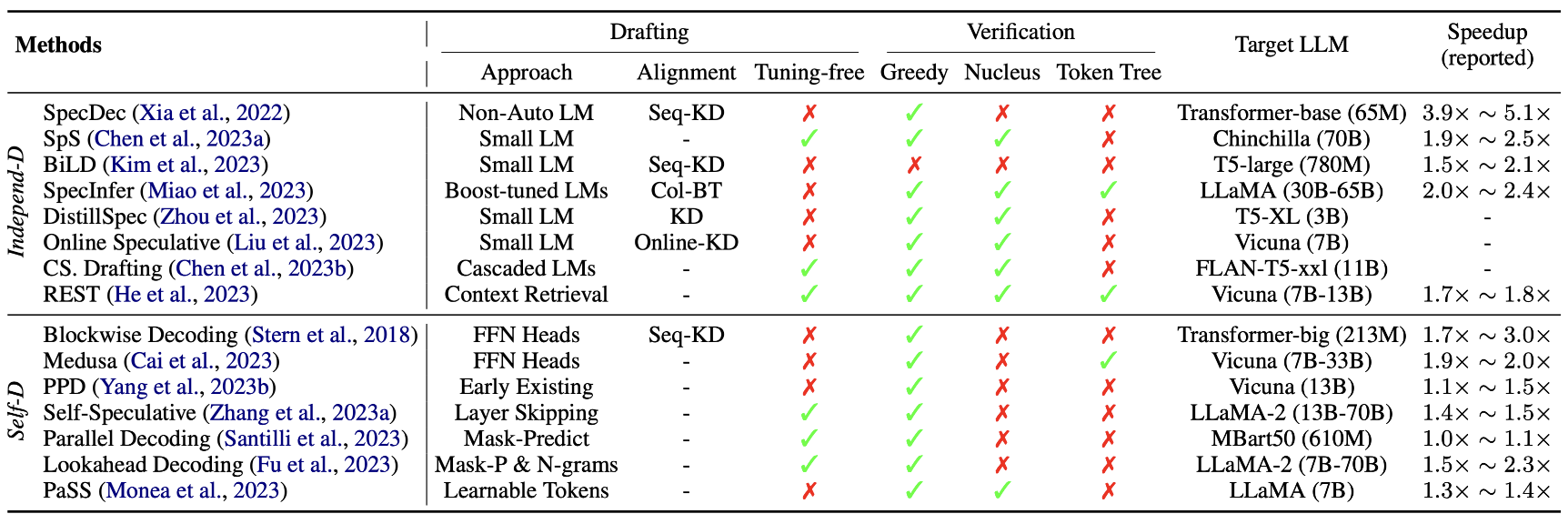
Abstract LLM의 autoregressive decoding에 의해 발생하는 높은 추론 지연 시간 때문에 speculative decoding(추측적 디코딩)이 새로운 디코딩 패러다임으로 등장하였다. speculative decoding 이 방법은 효율적으
6.[paper review] GPTQ: ACCURATE POST-TRAINING QUANTIZATION FOR GENERATIVE PRE-TRAINED TRANSFORMERS
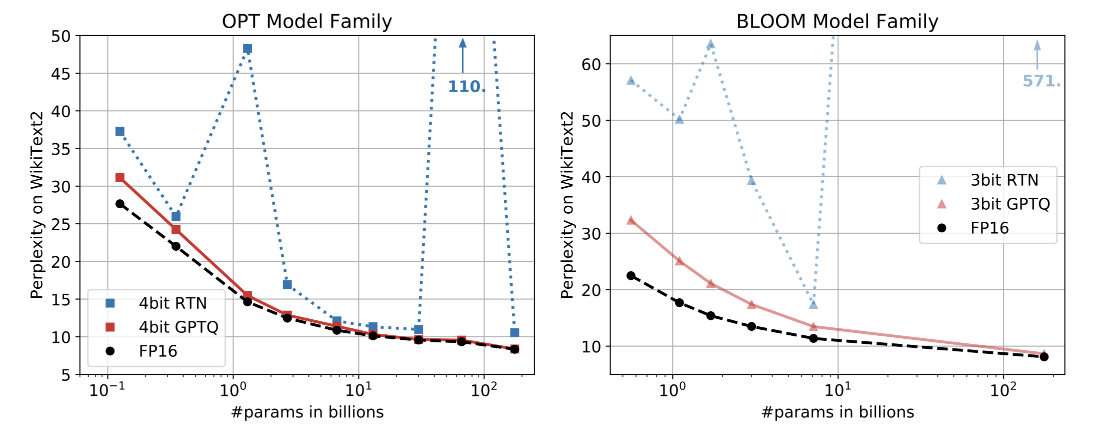
정말 정말 힘들었다..사실 아직도 이해 못했는데최대한 이해한 부분이라도 써보겠다 (기억상실을 방지하기 위함)low bitwidth quantization or model pruning은 억만개의 파라미터에 대해 비용이 많이 드는 retraining을 요구한다.때문에!
7.[paper review] MEDUSA: Simple LLM Inference Acceleration Framework with Multiple Decoding Heads
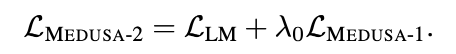
paper: https://arxiv.org/abs/2401.10774 implementation: https://github.com/FasterDecoding/Medusa 1. Intro 2. Relative work 3. MEDUSA 메두사는 각 디코딩 스텝이 3
8.[paper review] GLIDE with a CAPE
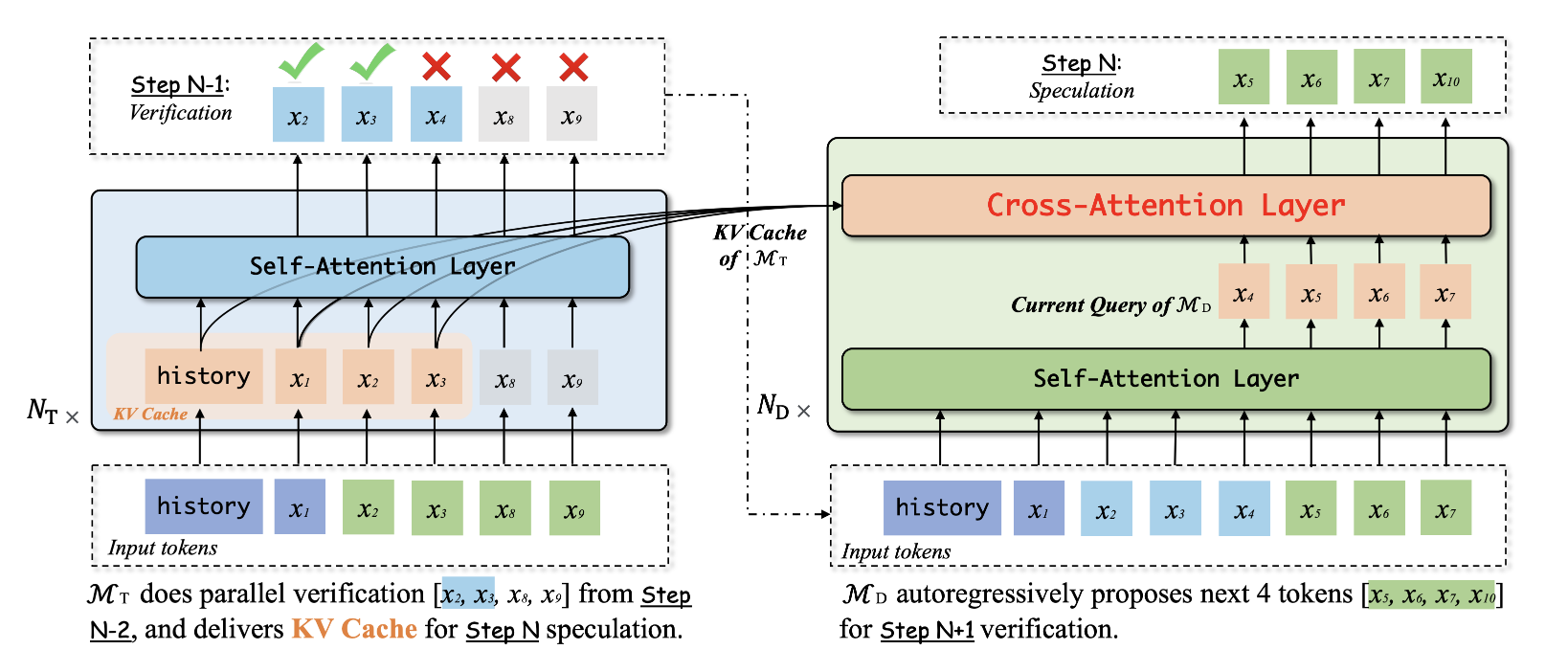
with chatGPT이 연구는 대규모 언어 모델(Large Language Models, LLMs)의 서빙 지연 시간을 줄이기 위한 새로운 솔루션을 제안합니다. 대규모 언어 모델은 실시간 반응이 필요한 다양한 응용 프로그램에서 사용되고 있지만, 자동 회귀 변환기(au
9.[paper review] Hydra: Sequentially-Dependent Draft Heads for Medusa Decoding
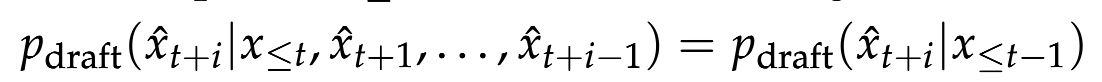
transformer-based LLM이 널리 사용되기 시작하면서, 이러한 모델들의 추론 효율성을 향상시키기 위한 연구가 점점 더 중요해지고 있습니다. 대규모 언어 모델의 사전 훈련은 전체 입력 시퀀스를 병렬로 처리함으로써 높은 하드웨어 활용도를 달성할 수 있지만, 전