Abstract
LLM의 autoregressive decoding에 의해 발생하는 높은 추론 지연 시간 때문에 speculative decoding(추측적 디코딩)이 새로운 디코딩 패러다임으로 등장하였다.
speculative decoding
이 방법은 효율적으로 미래의 토큰들을 초안으로 뽑고(draft), 이를 병렬적으로 확인한다(verify).
단계당 다수의 토큰을 동시에 디코딩을 용이하게 하고, 그로 인해 추론시간이 가속화 된다.
이 논문이 보여주는 것
유망한 디코딩 패러다임에 대한 종합적인 오버뷰 그리고 분석
이 연구가 speculative decoding의 촉매제 역할을 하길 원함. 궁극적으로 보다 효율적인 LLM 추론에 기여하는 것을 목표
Introduction
LLM은 다양한 다운스트림 작업에 놀라운 숙련도를 달성했다. 그러나, autoregressive decoding으로 인한 추론 지연 시간은 LLM이 더 많은 적용이 되는 것을 막았다.
LLM의 추론시간을 가속하기 위해서 Speculative decoding(추측 디코딩)이 소개되었다.
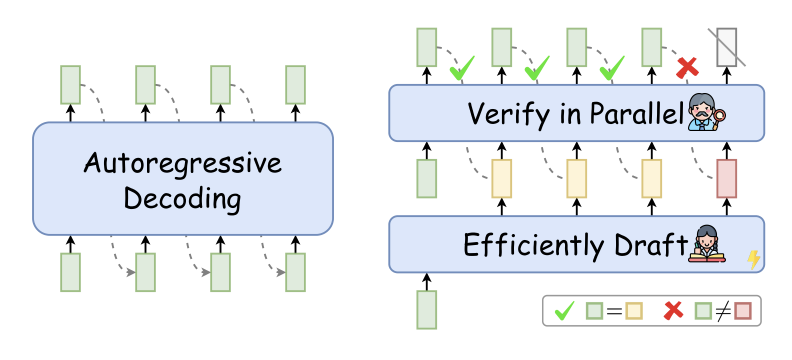
'추측 디코딩'은 우선 초안 모델을 활용하여 향후 디코딩 단계에 대한 추측으로서 여러 토큰을 효율적으로 디코딩한 후(draft), 대상 LLM을 이용하여 초안된 토큰을 병렬적으로 검증한다(verify).
고품질의 출력을 보장하기 위해서는 LLM의 검증 기준에 부합하는 토큰만 허용된다.
SpecDec는 LLM 추론에 대한 두 가지 주요 관찰을 기반으로 한다.
1) 많은 쉬운 토큰은 더 적은 계산으로 예측될 수 있으며(예를 들어, 더 작은 모델을 사용함),
2) LLM 추론은 높은 memory bandwidth bound이며, 주요 레이턴시 병목은 산술 계산보다는 LLM 파라미터의 메모리 읽기/쓰기로부터 발생한다.
추측 디코딩은 가능성을 보여주지만, 추가 조사가 필요한 몇 가지 중요한 질문을 제기한다.
1) 추측의 정확성과 초안의 효율성 사이의 균형을 맞추기 위해 draft 모델을 선택하거나 설계하는 방법
2) 검증 기준은 창조 다양성과 아웃풋 퀄리티를 유지할 수 있는지 검증하는 것은 필수적이다.
Evolution of Speculative Decoding
Motivation
autoregressive decoding은 추론 지연으로 한계를 만든다. 구체적으로, 각 디코딩 단계의 주요 레이턴시 병목 현상은 계산 연산에 의한 것이 아니라, 모든 LLM 파라미터를 고대역폭 메모리(High-Bandwidth Memory: HBM)로부터 GPU와 같은 현대 가속기의 온칩 캐시로 전송할 필요성에 기인한다.
Pioneering Draft-then-verify Efforts
위의 이슈를 완화하기 위해서, 직관적인 방법은 LLM 추론에서 더 많은 병렬을 위해 추가 유휴 계산 자원을 상쇄하는 것이다.
- Blockwise Decoding이라는 접근 방식이 도입되었음, 이는 추가적인 FFN 헤드를 통해 여러 토큰을 동시에 드래프팅하고, 원본 LLM으로 병렬 검증을 하여 추론을 가속화함.
- Xia et al. (2022)이 독립된 drafter를 사용하는 Speculative Decoding (SpecDec)을 소개함, 이는 기존의 엄격한 검증 기준을 완화하는 혁신적인 검증 전략과 함께 정확하고 효율적인 드래프팅을 수행함.
- SpecDec는 기존 자동 회귀 디코딩에 비해 약 5배의 속도 향상을 달성함, 이는 스페큘러티브 디코딩의 잠재력을 강조함.
- Leviathan et al. (2023)과 Chen et al. (2023a)는 Nucleus Sampling의 손실 없는 가속을 포함시키기 위해 Speculative Sampling을 제안함.
이러한 방법은 기존 작은 LMs를 사용하여 더 큰 모델의 추론을 가속화함, 추가적인 훈련 없이 스페큘러티브 디코딩의 빠른 채택을 가능하게 함.
이 진보는 스페큘러티브 디코딩을 LLM 효율성 연구의 최전선으로 이끌었고, NLP 커뮤니티 내에서 널리 관심을 받게 함.
Formulation and Definition
Autoregressive Decoding
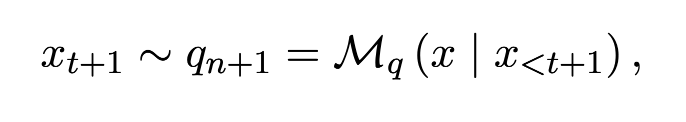
X1~Xt : 인풋 시퀀스
Mq : autoregressive language model
q : conditional probability distribution calculated by Mq
Xt+1은 qn+1을 통해 샘플링된 다음 토큰을 나타낸다.
Autoregressive Decoding은 바람직한 생성 품질을 제공하지만, 메모리 대역폭에 의해 강하게 구속되어 현대 가속기 하드웨어의 활용도가 낮다. 이 과정에서, 메모리-바운드된 LLM 호출(즉, LLM 순방향 단계)은 전체 시퀀스에 대한 하나의 토큰만을 생성하므로, 전체 생성이 비효율적이고 시간 소모적이다.
Speculative Decoding
Speculative Decoding is a Draft-then- Verify decoding paradigm in which, at each decoding step, it first efficiently drafts multiple future tokens and then verifies all these tokens in parallel using the target LLM to speed up inference.
Drafting
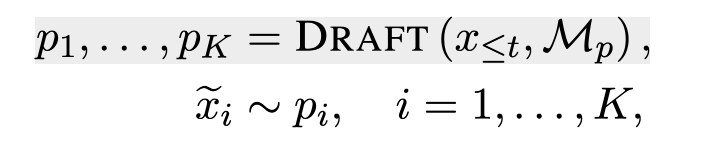
각 디코딩 스텝에서, SpecDec은 효율적으로 여러개의 future token들(타겟 LLM의 아웃풋의 추측)을 초안으로 뽑아낸다.
X1~Xt : 인풋 시퀀스
Mq : 타겟 LLM
Mp : 효율적 초안 모델
p : conditional probability distribution calculated by Mp
ẋi : pi로부터 샘플링된 초안 토큰
Verification
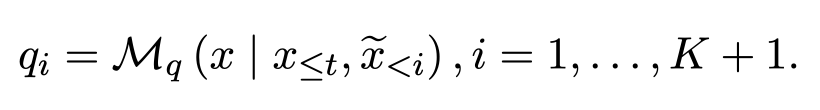
위의 과정에서 나온 초안 토큰들은 타켓 LLM Mq에 의해서 검증(verify)된다.
X1~Xt : 인풋 시퀀스
ẋ1~ẋt : pi로부터 샘플링된 초안 토큰
SpecDec는 K + 1 확률 분포를 동시에 계산하기 위해 Mq를 활용한다.
기준에 부합하는 토큰만을 최종 산출물로 선정하여 대상 LLM의 기준에 부합하는 품질을 보장한다.
만약 ẋc가 verification 기준에 충족되지 못했을 경우, CORRECT(pc, qc)에 의해서 정정될 것이다.
품질 보장을 위해서, c 이후의 모든 초안 토큰들은 버려진다.
drafting and verification은 [EOS] 토큰을 만나거나, 최대 길이를 달성하기 전까지 반복된다.
결과적으로, speculative decoding의 가속효과는 각 스텝에서 허용되는 초안 토큰 수에 따라서 결정된다.
이러한 수용률은 초안 모델의 용량, 검증 기준, 그리고 초안과 대상 LLM 간의 행동 정렬을 포함한 여러 요인에 의해 결정된다.
Drafting
drafting 프로세스는 패러다임의 가속화 영향에 있어 결정적인 요인이 두가지 있다.
추측 정확도와 초안 지연
이 둘을 잘 trade off 하는 것이 이 프로세스의 메인 챌린지이다.
다음 섹션에서는 drafting을 두가지 카테고리로 나눠서 설명할 것이다.
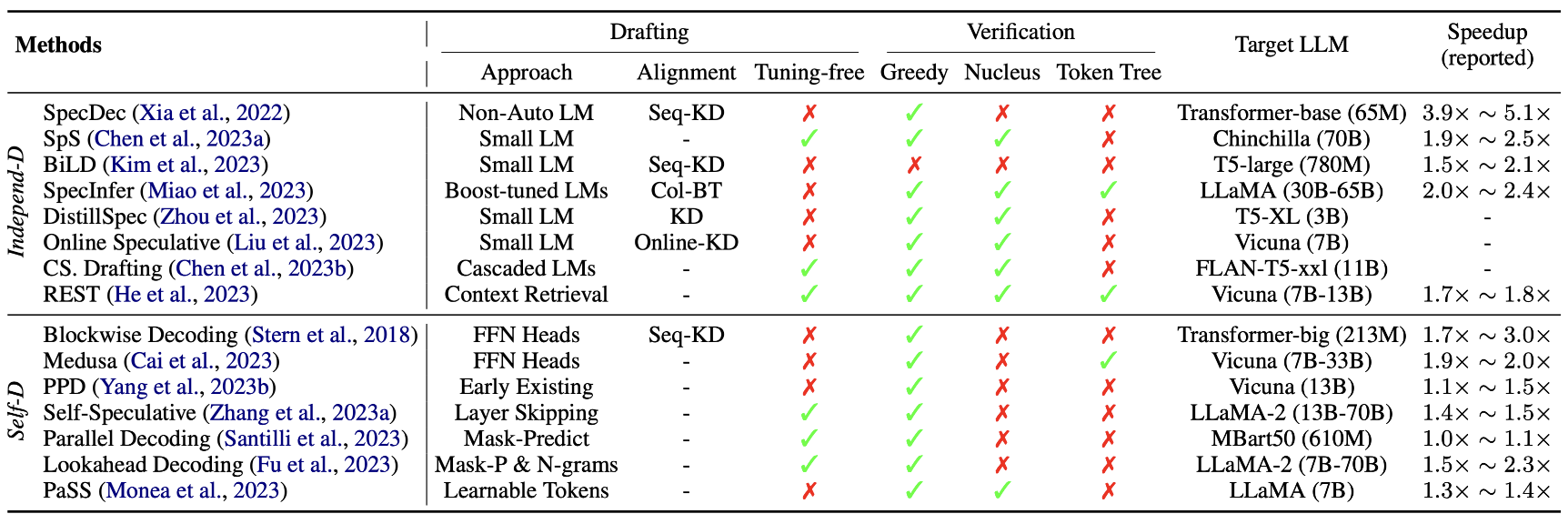
Independent Drafting
SpecDec (Xia et al., 2022)는 추측 정확성과 효율성 사이의 균형을 맞추기 위해 독립적인 모델을 사용하여 드래프팅 작업을 수행하는 것을 제안했음.
특히, 비자동회귀 트랜스포머를 도입하여 한 번에 여러 토큰을 동시에 드래프트하는 새로운 모델을 소개했음.
SpecDec는 sequence-level knowledge distillation를 통합하여 Drafter의 출력을 대상 LLM의 출력과 일치시켜 추측 정확성을 향상시켰음.
이 방법은 특수한 Drafter 모델을 처음부터 훈련시키는 데 더 많은 계산 자원을 요구함.
Leviathan et al. (2023)과 같은 후속 연구에서는 같은 시리즈의 작은 LM을 직접 사용하여 대형 LLM의 추론을 가속화하는 더 직접적이고 효율적인 접근법을 채택함.
Miao et al. (2023)은 다양한 작은 LM들을 대상 LLM과 일치시키기 위해 Collective Boost-tuning을 제안했음.
Liu et al. (2023)은 사용자 쿼리 데이터 스트림에 대한 드래프터를 지속적으로 대상 LLM과 일치시키는 온라인 스페큘러티브 디코딩을 소개함.
Self-Drafting
독립적인 모델을 사용하는 것은 속도를 보장하는 반면,
train이나 검증 시 더 많은 노력이 들어감. 더 나아가 두 모델을 합치는 것은 computational and operational complexities 상승시킨다
- Blockwise Decoding (Stern et al., 2018)과 Medusa (Cai et al., 2023)는 트랜스포머 디코더 위에 추가적인 FFN(feedforward neural network) 헤드를 도입하여 한 번에 여러 토큰을 생성할 수 있게 했음.
- 이러한 FFN 헤드는 추가적인 계산 오버헤드를 줄이고 분산 추론에 유리함.
- 다른 연구들은 대상 LLM 자체의 초기 존재 또는 레이어 스킵을 활용하여 drafting 작업을 수행함 (Yang et al., 2023b; Zhang et al., 2023a; Hooper et al., 2023).
- 예를 들어, Yang et al. (2023b)은 현재 디코딩 단계에서 이른 시점에 존재하는 추가적인 서브프로세스를 도입하여 미래 토큰을 미리 초안을 만들도록 함.
- Self-Speculative (Zhang et al., 2023a)는 추론 중 몇 개의 중간 레이어를 적응적으로 건너뛰어 효율적으로 초안을 만들도록 제안함.
- Santilli et al. (2023)은 모델 구조를 확장하거나 추론 과정을 변경하는 이전 작업과 달리, 입력 프롬프트 끝에 여러 [PAD] 토큰을 직접 추가하는 간단한 드래프팅 전략을 도입함. 이 방법은 LLM이 잡음이 많은 입력을 처리하는 강인함에서 그 효과가 나옴. 하지만 이 접근법은 LLM의 autoregressive pre-training 패턴에서 벗어나, drafting 품질이 최적이 아님.
- 이 문제를 해결하기 위해 Fu et al. (2023)은 저품질의 draft된 토큰을 다수의 n-gram으로 재구성하여 추측 정확성을 효과적으로 향상시킴.
- Monea et al. (2023)은 여러 학습 가능한 [LA] 토큰을 도입하고 이 토큰 임베딩을 작은 훈련 데이터셋에서 미세조정하여 병렬 디코딩 성능을 강화함.
([LA] 토큰이란? Learnable token으로 학습가능한 토큰을 의미한다.)
Verification

Greedy Decoding
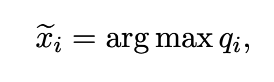
위는 VERIFY 수식이다. qi가 최대일 때의 xi를 뽑는다.
만약 검증에 실패하게 된다면 CORRECT 함수를 통해서 output token을 생성하게 된다.
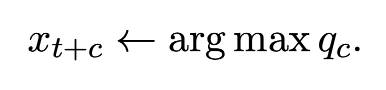
위의 것이 아웃풋 토큰이다.
Nucleus Sampling
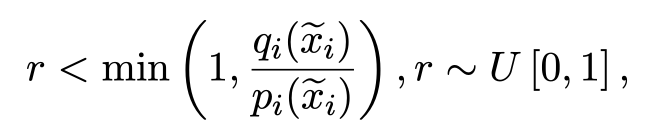
r : 0~1 사이의 랜덤한 숫자
qi(ẋi) & pi(ẋi)는 Mq, Mp에 따른 ẋi의 확률
만약 qi(x̃i) ≧ pi(x̃i)일 때는 accept
아니라면
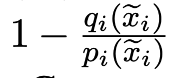
위의 확률로 거부를 한뒤 아래의 CORRECT 함수로 아웃풋 토큰을 정정한다.
더 설명하자면, r보다 qi(x̃i) / pi(x̃i)가 클 확률은 qi(x̃i) / pi(x̃i)이고, r보다 qi(x̃i) / pi(x̃i)가 작을 확률은 1 - qi(x̃i) / pi(x̃i)다.
때문에 거부될 확률이 1 - qi(x̃i) / pi(x̃i)라는 것!
왜 qi(x̃i) ≧ pi(x̃i)일 때, accept이냐?
➡️ 초안 토큰인 x̃i의 확률보다 타겟 모델로 만들어진 확률이 더 크다는 뜻이다. 그러므로, 무조건 이는 수용!
qi(x̃i) < pi(x̃i)이라면? r 값에 따라서 확률적으로 수용한다. r은 균등하게 분포하기 위해서 쓰는 값이다.
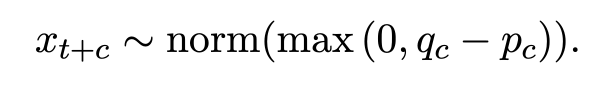

(GPT야 고마워!)
이러한 방식은 대상 LLM의 출력 품질을 유지하면서 추론 속도를 높이는 데 도움이 된다. 특히, qi(ẋi)가 pi(ẋi)보다 작을 때 토큰을 거부하는 확률을 도입함으로써, 단순히 가장 높은 확률의 토큰을 선택하는 것보다 더 유연하고 정확한 추론이 가능해진다.
Token Tree Verification

Figure 4 제시된 이미지는 토큰 트리 시퀀스와 트리 주의(attention) 매트릭스를 나타냅니다. 이 방법론은 언어 모델이 여러 후보 드래프트 시퀀스를 병렬로 검증할 수 있게 하는 전략으로, 기존의 단일 드래프트 시퀀스만 검증하는 방법과 대조됩니다.
토큰 트리 시퀀스(Token Tree Sequences):
왼쪽에 있는 트리 구조는 "Root"에서 시작하여 "It," "I," "like," "am," "be," "will," "very," "the," "a"와 같은 다양한 토큰들이 연결되어 여러 가능한 시퀀스를 형성하고 있습니다. 이 트리는 여러 후보 드래프트 시퀀스를 효율적으로 통합하여 공통된 접두사(prefix)를 공유하면서 각기 다른 경로를 만들어냅니다. 예를 들어, "I am"이라는 접두사는 "I am like"와 "I am very"라는 두 가지 시퀀스로 분기됩니다.
트리 주의 매트릭스(Tree Attention Matrix):
오른쪽에 있는 매트릭스는 트리 구조에서 각 토큰이 어떻게 주의를 받는지를 시각화합니다. 이 매트릭스에서 행은 개별 토큰을 나타내고, 열은 해당 토큰이 다른 토큰들과 어떤 주의 관계를 가지는지를 나타냅니다. 예를 들어, "I" 행은 "I" 토큰이 "am," "like," "very" 토큰들과 주의를 주고받는 것을 보여줍니다. 체크마크는 주의 관계를 가리키며, 특정 토큰이 다른 토큰에 주의를 기울일 때 해당 칸에 표시됩니다.
이러한 방법은 여러 다른 후보 드래프트 시퀀스를 고려함으로써, 언어 모델이 더 정확한 예측을 할 수 있도록 돕습니다. 특히, Miao et al. (2023)은 다양한 부스트 조정된 언어 모델에서 다양한 드래프트 시퀀스를 생성하고, Cai et al. (2023)은 각 FFN 헤드에서 상위 k개의 예측을 고려하여 여러 후보를 도출하는 등의 방법으로 후보 드래프트 시퀀스를 얻었습니다. He et al. (2023)은 검색된 문서에서 입력 프롬프트의 다양한 연속을 사용하여 후보 드래프트 시퀀스를 구성했습니다. 이후 이러한 후보 드래프트 시퀀스들은 토큰 트리로 통합되어 트리 주의 마스크를 사용한 병렬 검증을 위해 대상 언어 모델에 공급됩니다.
내가 이해한 바로는, "I am" 뒤에 like, very라는 두 개의 단어가 올 수 있는데, 다른 방법론의 경우 like와 very 각각을 비교해야 하는 반면에 토큰 트리 검증은 병렬적으로 한번에 검사할 수 있다는 것이다!
Alignment
drafter의 아웃풋을 목표 LLM의 출력과 일치시키기 위해서 다양한 Knowledge distillation(KD) 전략이 사용되었다.
Seq-KD
관련 논문 : https://arxiv.org/pdf/1606.07947.pdf
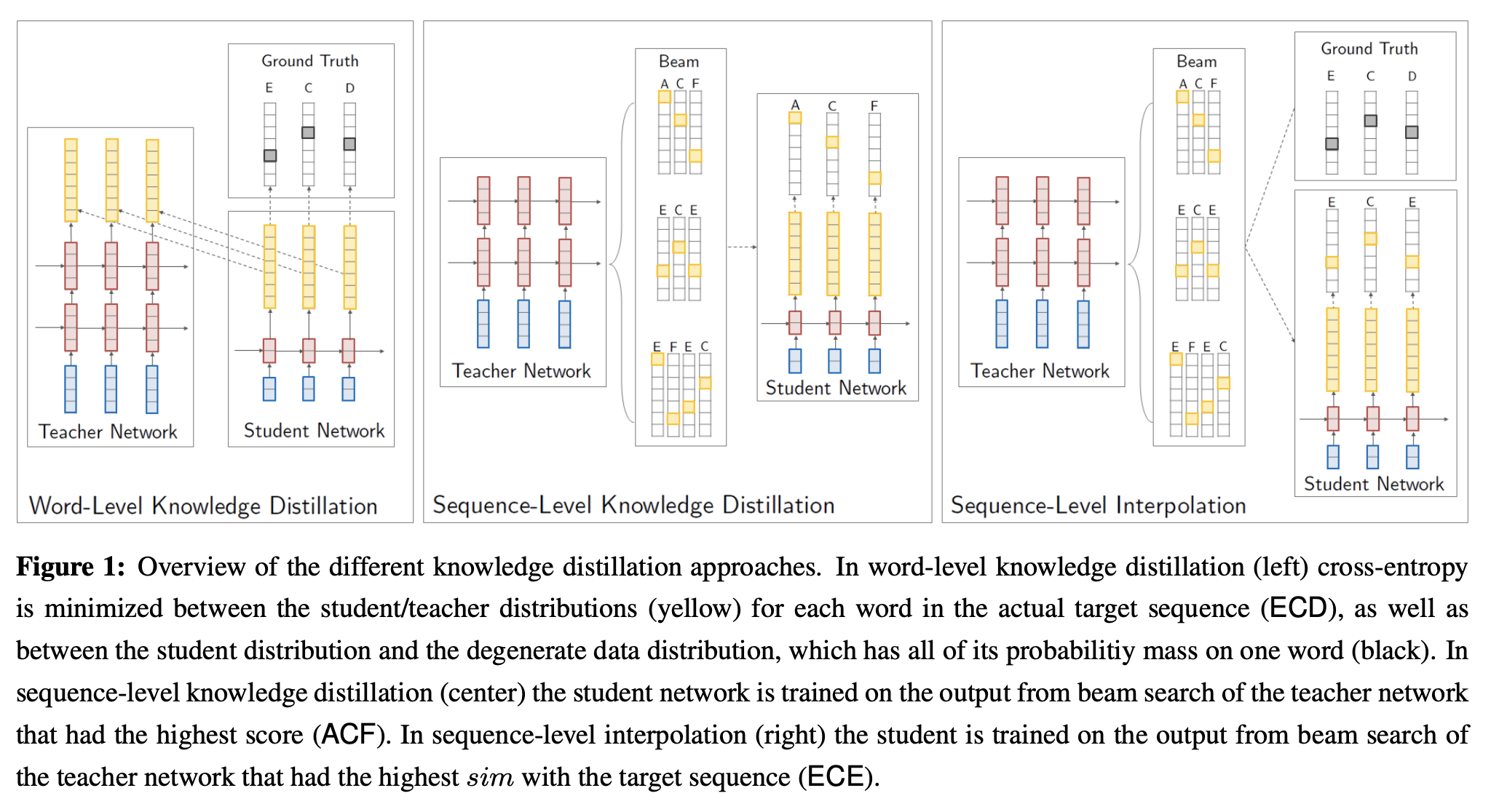
Col-BT
 SSM : small speculative model
SSM : small speculative model
Miao et al.(2023)은 Seq-KD를 채택하여 훈련 데이터에 대한 여러 소형 LM을 미세 조정하고 이들의 집계 출력을 초안으로 활용하여 추측 정확도를 향상시키는 집단 부스트-튜닝(Col-BT) 전략을 제안하였다.
관련 논문: https://arxiv.org/pdf/2305.09781.pdf
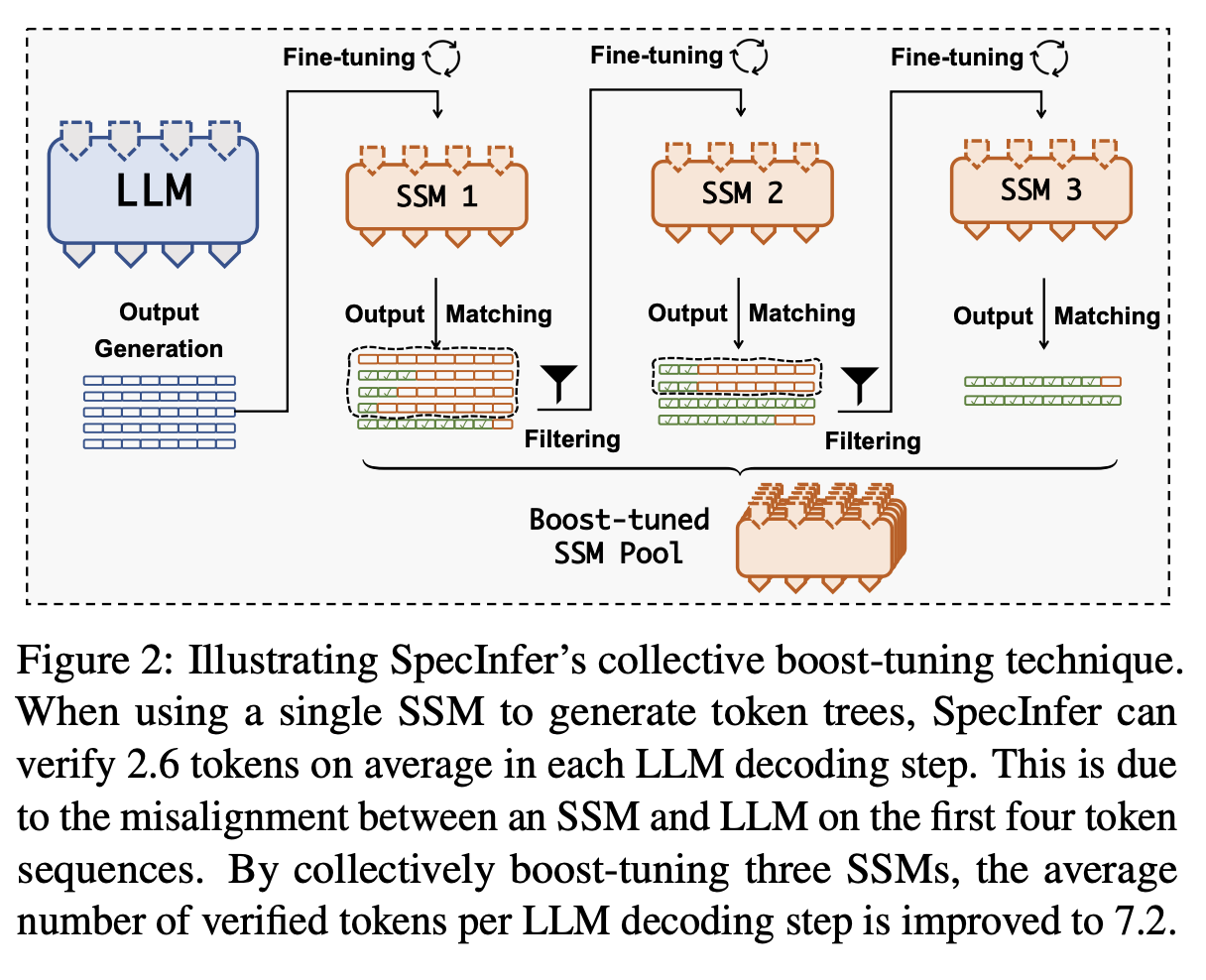
online KD
online KD의 경우, teacher 모델과 student 모델이 동시에 학습이 된다.
Application
일반적인 패러다임의 역할을 할 뿐만 아니라, 최근 연구에서는 특정 작업에서 특정 변형의 탁월한 효과를 보여주는 것으로 밝혀졌다. 또한, 다른 연구에서는 특정 응용 시나리오에 고유한 지연 문제를 해결하기 위해 이 패러다임을 적용하여 추론 가속화를 달성했다. 아래에서는 이러한 유망한 작업에 대한 자세한 소개를 제공할 것이다.
Sun et al.(2021)과 Yang et al.(2023a)의 최근 연구에서는 사변적 디코딩이 문법적 오류 수정(Wang et al., 2021; Bryant et al., 2023) 및 검색-증강 생성(Lewis et al., 2020; Cai et al., 2022)과 같이 모델 입력과 출력이 매우 유사한 작업에 특히 적합하다는 점을 강조했습니다. 이러한 방법은 초기 사용자 입력 또는 검색된 컨텍스트가 초안으로 직접 사용되는 특별한 형태의 사변적 디코딩을 도입했습니다. 예를 들어, 문법적 오류 수정에 대한 사변적 디코딩의 초기 시도인 SAD(Sun et al., 2021)는 문법적 오류 수정에 대한 사변적 디코딩을 초안으로 사용하고 LLM을 활용하여 전체 문장을 병렬로 검증하여 9×~12배 속도 향상을 달성했습니다. 마찬가지로 LLMA(Yang et al., 2023a)는 텍스트 범위를 초안으로 참조에서 선택하여 검색-증강 생성, 캐시-지원 생성 및 멀티턴 대화를 포함한 다양한 실제 응용 시나리오에서 2×~3배 속도 향상을 보여주었습니다.
이러한 작업 외에도 RaLMSpec(Zhang et al., 2023b)는 검색 증강 언어 모델(RaLMs)을 가속화하기 위해 추측 디코딩(Spectulative Decoding)을 채택했다. 반복 RaLMs의 주요 지연 병목 현상은 방대한 지식 기반에서 빈번한 검색이라는 점을 지적했다. 추론을 가속화하기 위해 이 방법은 추측 검색을 위한 로컬 캐시를 유지하여 동일한 모델 출력으로 약 2배 속도 향상을 달성하도록 제안했다. LLMCad(Xu et al., 2023)는 추측 디코딩을 온디바이스 LLM in-ference에 적용했다. 구체적으로 디바이스 메모리에서 호스팅할 수 있는 더 작은 실시간 LM으로 초안을 생성하고 병렬 검증을 위해 대상 LLM만 활용할 것을 제안했다. 이 접근 방식은 모델 가중치의 반복적인 해제 및 로드를 효과적으로 줄여 기존 추론 엔진에 비해 9.3배 속도 향상을 달성한다.
정리
- 스페큘러티브 디코딩은 특정 작업에서 매우 효과적이라는 것이 최근 연구를 통해 밝혀졌음.
- 이 패러다임은 일부 응용 시나리오에서 고유한 지연 문제를 해결하고 추론 가속화를 달성하는 데 적용됨.
- Sun et al. (2021)과 Yang et al. (2023a)의 연구는 문법 오류 수정과 RAG(retrieval augmented generation)과 같이 입력과 출력이 매우 유사한 작업에 스페큘러티브 디코딩이 특히 적합하다고 강조함.
- SAD와 LLMA 같은 방법들은 초기 사용자 입력이나 검색된 컨텍스트를 초안으로 직접 사용하여 2배에서 12배의 속도 향상을 보였음.
- RaLMSpec은 스페큘러티브 디코딩을 이용하여 지식 기반에서의 빈번한 검색이라는 반복적인 RaLMs의 주요 지연 병목 현상을 해결하기 위한 로컬 캐시 유지 방안을 제시함.
- LLMCad는 기기 내 LLM 추론에 스페큘러티브 디코딩을 적용하여 모델 가중치의 반복적인 로딩과 해제를 줄이고, 기존 추론 엔진에 비해 9.3배의 속도 향상을 달성함.
RAG 관련 논문 : https://arxiv.org/abs/2005.11401
Challenges and Future Directions
How to trade off speculation accurancy and drafting efficiency?
drafter를 확장시키는 것은 효과적으로 추측 정확도를 향상시킬 수 있지만, 크게 drafting 효율과 속도를 감소시킨다. 따라서, 추측 정확성과 drafting 지연 사이의 균형을 맞추는 것이 중요합니다. 기존 전략 중에서는 behavior alignment가 이 문제를 해결하는 유망한 접근법으로, 지연 시간을 증가시키지 않으면서 추측 정확성을 향상시킵니다. 하지만 최근의 발전에도 불구하고 drafter를 대상 LLM과 정렬시키는 데에는 여전히 개선의 여지가 있습니다. 예를 들어, 분기점 이후의 초안으로 나온 토큰이 모두 버려지기 때문에, drafter가 초기 위치 토큰의 생성 품질을 우선시하도록 유도하는 방향을 고려할 수 있습니다. 정렬 외에도 drafting의 품질과 추측 길이의 결정 등 다른 요소들도 추측 정확성에 영향을 미치며, 추가적인 탐색이 필요합니다.
How to integrate Speculative Decoding with other leading techniques?
Speculative Decoding은 일반적인 디코딩 패러다임으로서, 다른 고급 기술과 결합할 때 그 잠재력을 이미 입증했습니다. 예를 들어, Yuan et al은 Speculative Decoding과 Contrastive Decoding을 결합하여 추론 속도를 높이는 동시에 생성 품질을 상당히 향상시켰습니다. 텍스트 전용 LLM의 가속화뿐만 아니라, 이미지 합성, 텍스트-음성 변환, 비디오 생성과 같은 멀티모달 추론에서 Speculative Decoding의 적용도 흥미롭고 가치 있는 미래 연구 방향입니다.
Conclusion
LLM의 지속적인 확장에 따른 효율적인 추론의 필요성 증가
최근 몇 년 동안 언어 모델(Large Language Models, LLMs)의 지속적인 확장은 효율적인 LLM 추론에 대한 요구를 크게 증가시켰습니다. 동일한 생성 품질을 유지하면서 LLM 추론을 가속화하는 새로운 디코딩 패러다임인 스페큘러티브 디코딩(Speculative Decoding)이 유망한 해결책으로 부상했습니다.
스페큘러티브 디코딩에 대한 종합적인 조사
이 논문은 스페큘러티브 디코딩에 대한 기존 문헌에 대한 포괄적인 조사를 제시합니다. 여기에는 스페큘러티브 디코딩의 공식적인 정의 및 공식화, 다양한 선도 기술에 대한 심층적인 리뷰뿐만 아니라 향후 연구를 위한 도전과 잠재적인 방향이 포함됩니다. 저희가 알기로, 이는 스페큘러티브 디코딩에 전념하는 첫 번째 조사입니다.
논문의 주요 목적
이 논문의 주요 목적은 현재 연구 환경을 명확히 하고, 이 유망한 패러다임의 미래 방향에 대한 통찰을 제공하는 것입니다.
