Paper Review #7 - A Dual-Path Cross-Modal Network for Video-Music Retrieval
MultimodalKnowledgeGraph
Gu, X., Shen, Y., & Lv, C.,"A Dual-Path Cross-Modal Network for Video-Music Retrieval", Sensors, 23(2), pp.805, 2023
본 논문에서는 감정적인 정보와 컨텐츠 정보를 통합해 dual path cross modal retrieval network를 구축한다.
content 기반 retrieval은 비디오와 음악 모두 semantic content(비디오의 이벤트나 음악의 주제같은)관련 정보를 가지고 있다고 간주한다. 따라서 추가적인 레이블 정보 없이 비디오와 음악 쌍만을 사용하여 self-supervising이 가능하다. 하지만 비디오 데이터와 음악 데이터 간 이질성이 크기 때문에 이러한 이질성을 바탕으로 감정 정보를 활용하는 것이 효과적이다.
VER과 MER에서 감정을 추출하고 인식하는데 사용되는 딥 러닝 네트워크는 크게 단일 네트워크와 결합 네트워크로 구분된다.단일 네트워크는 주로 CNN을 사용해 video feature 추출 및 emotion space에 mapping한다. 비디오 감정 인식의 대표적인 모델로는 3DResNET, 음악 감정 인식의 대표적인 모델로는 2DResNet과 Vggish가 있다.
또한 자연어에서 트랜스포머가 좋은 두각을 나타냈기 때문에 트랜스포머를 비디오 인식에 적용 시킨 ViViT와 Video Swin Transformer가 있다.
Content path에선 미세 네트워크 구조를 갖는 content common space를 설계하고, 비디오와 음악 사이 content sharing representation을 얻기 위한 constraint를 추가하였다.
Emotional path에서는 emotional feature를 얻기 위해 emotional feature 추출 스키마를 디자인한다. 비디오와 음악의 감정 공유 표현(representation of emotional sharing)은 단순화된 emotional common space가 있는 네트워크 구조로부터 얻어진다.
이렇게 컨텐츠와 감성이 결합된 common fusion space가 설계되면 비디오와 음악 간 최종 representation feature들을 얻을 수 있다. 이 feature 간의 유사성을 계산함으로써 video-music retrieval task가 완료된다. 이를 위해 비디오와 음악 간 dual-path retrieval network인 DPVM(Dual Path Video Music Retrieval Network)을 제안한다.
DPVM의 구조는 밑의 그림과 같다.
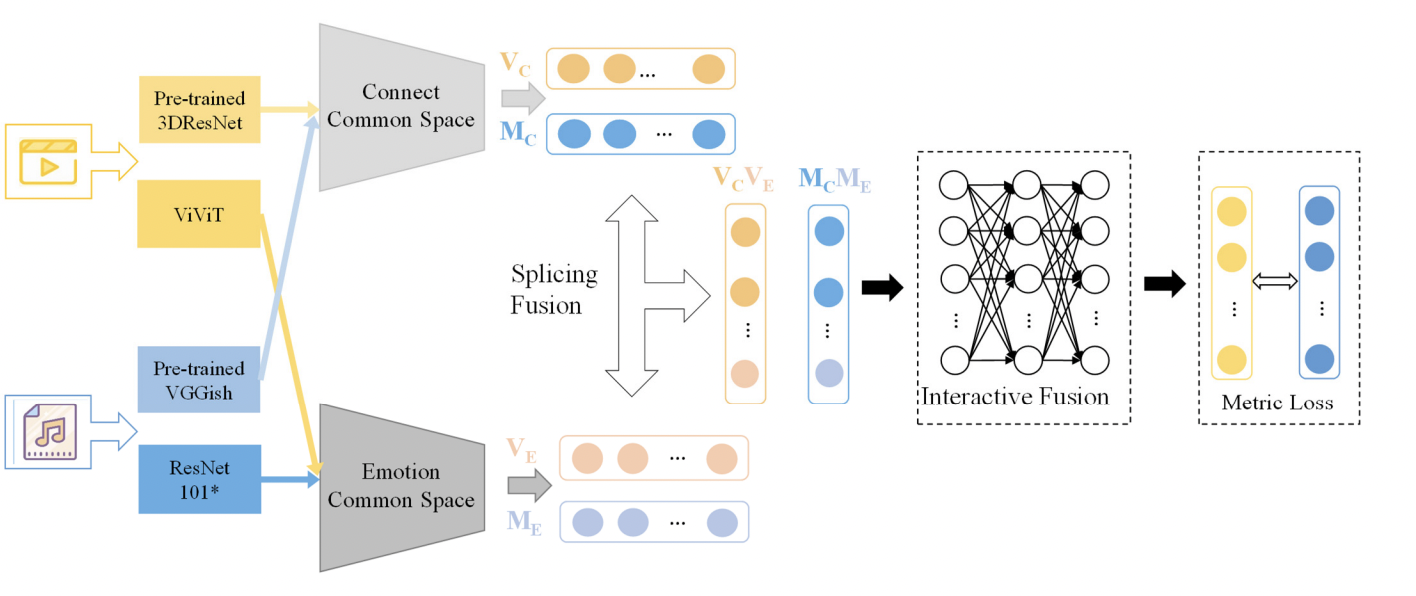
Overview & Architecture
음악은 서정적인 감정을 주요 내용으로 삼고 있는 경향이 크기 때문에 cross-modal retrieval에 단순한 의미론적인 컨텐츠 정보만을 사용하는 데에 한계가 있다. 따라서 비디오-음악 검색 작업에서 감정적 컨텐츠 정보와 의미적 컨텐츠 정보가 모두 필요하다. DPVM은 common network, emotion common network, fusion network로 구성되어 있다.
- : 비디오의 content feature vector
- : 비디오의 emotional feature vectore
- : 음악의 emotional feature vectore
- : 음악의 emotional feature vectore
- Content common space: 컨텐츠 정보의 경우 대규모데이터셋에서 사전 훈련된 일반적인 네트워크 모델을 사용해 content feature를 추출한다. content feature는 혼합된 정보나 중복성이 있을 수 있기 때문에 encoding-decoding 구조를 사용해 세분화시켜 content feature 사이의 shared representation을 얻는다.
- Emotion common space: 비디오와 음악의 감정 정보에 대한 feature를 추출하는데, emotion feature extraction network를 최적화 시키기 위해 emotional discriminatory loss(감정 차별적 손실)을 적용한다. 일반적인 네트워크 모델에 의해 추출된 content feature에 비해 emotional feature는 더 구체적이고 중복성이 낮다는 특징이 있기 때문에 Multi-Layered Perceptron(MLP)으로 이루어져 fully connected layer 구조를 가진 emotion common space는 두 modality 사이의 이질성을 제거하고 emotion shared representation을 얻도록 설계되었다.
- Fusion network:Fusion shared space는 콘텐츠 정보와 감정 정보를 결합하는데, 이는 비디오와 음악의 최종 representation feature를 얻기 위해 설계되었으며 representation feature간의 유사성을 계산해 비디오와 음악 간 retrieval 작업을 완료한다.
- Splicing Fusion: 동일한 modal 의 content feature과 emotional feature을 splicing함.
- Interactive Fusion: content information, emotional information과 상호작용함 이러한
Networks
Content Common Network
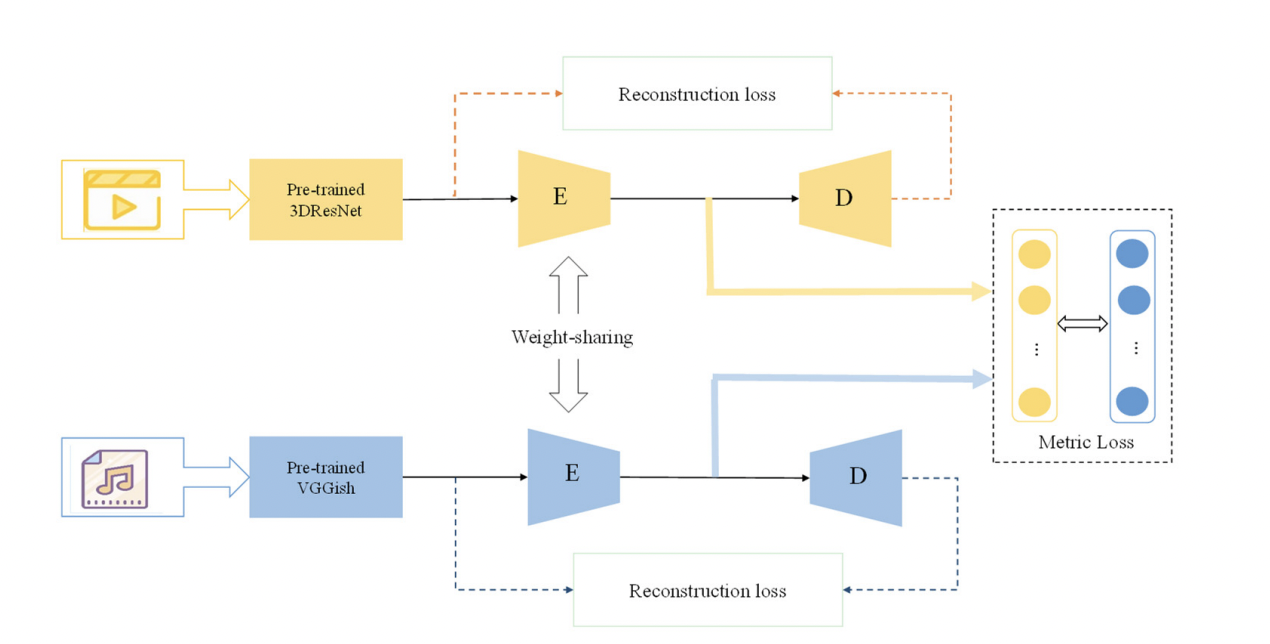
- Video: Kinetics-600 데이터셋에서 사전훈련된 3DResNet을 사용해 content feature 추출
- Music: AudioSet에서 사전훈련된 Vggish를 사용해 content feature 추출
- Content common space: Encoder-Decoder 구조를 사용하는데 encoder는 차원을 축소하고 비디오와 음악 feature 간의 weight를 공유하면서 차원을 통합함. Decoder는 차원을 재구축함. 이런 방법을 통해 차원 축소 과정에서 중요한 정보가 손실되지 않는 것을 보장함. 이때 Reconstruction loss와 metric loss의 두가지 손실 함수를 적용하는데 Reconstruction loss의 경우 인코더의 차원 축소를 처리하고 Metric loss는 생성된 비디오와 음악 컨텐츠에 대한 common feature information의 일관성을 최적화함.
- Content loss
- Implementation
- 각 비디오 데이터는 고정된 프레임의 샘플링 스키마를 사용해 시간 순서에 따라 6개의 세그먼트로 분리도미
- 각 세그먼트에서 16개의 연속적인 프레임이 선택됨
- 음악의 경우 Librosa 라이브러리를 사용해 MFCC feature를 추출하는데 feature vectore는 32차원, 샘플링 빈도는 14,440. FFT 윈도우 길이는 2048, 스텝 사이즈 역시 2048로 설정
- music input dimension의 일관성 유지를 위해 최대 길이는 192로 설정되어있음
Emotion Common Network
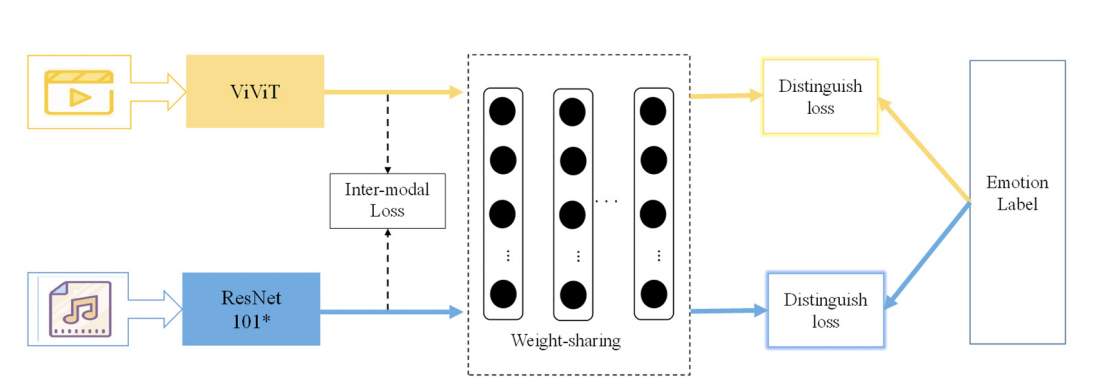
- Video: 비디오는 비디오 프레임의 정보가 중복되고 감정적인 정보가 많은 프레임은 소수에 불과하기 때문에 효율적인 감정 정보 추출을 위해 우선 비디오에서 emotion key frame을 선택한다. 이후 feature extraction network에서 visual transformer인 ViViT모델을 활용해 비디오의 시간적인 맥락 정보를 얻는다.
- Music: ResNet101을 채택하고 channel attention 매커니즘을 도입하여 감정 정보를 추출한다.
- Emotional common space: 비디오와 음악에서 추출된 emotional feature 간 가중치를 공유하는 MLP 구조를 채택해 emotional common space를 설계함.
- Loss function: 감정 네트워크에서도 두가지 손실 함수를 채택하는데 모달 내 손실과 모달 간 손실을 구분하여 구성하였다.
- Inter-model loss function
Ineter-model loss function은 다양한 모달 데이터의 emotional feature를 보존해 emotional common space에서 비디오와 음악으로부터 감정적인 구별되는 정보를 구축한다.
비디오와 음악 간 loss function은 이와 같이 구성된다
- Distinguish loss function
Distinguish loss function은 cross entropy loss function을 채택하였다.
- : emotional label
- : emotion common representation space of the multilayer perceptron structure
- 이렇게 얻어진 두가지 손실 함수를 사용해 최종적인 Emotion loss를 구할 수 있다.
여기서 과 는 weight coefficient를 나타낸다.
- Inter-model loss function
- Implementation
- 비디오 데이터 중복성을 줄이기 위해 emotion keyframe 스키마 채택
- emotion keyframe scheme는 프레임 간 color histogram 차이를 기반으로 비디오의 shot boundaries를 감지하고 한 샷씩 나눔
- 각 shot boundary frame에 대해 picture emotion 인지 네트워크 모델로 emotion score를 계산하고 임계값을 설정해 keyshot을 필터링함
- 각 keyshot에서 프레임간 차이가 가장 큰 프레임을 키 프레임으로 선택함으로써 프레임간 차이가 커지고, 중복성을 제거할 수 있음
Fusion Common Network
- Splicing fusion feature는 같은 모달 데이터의 다른 두개의 feature(content, emotion)를 나눔으로써 얻을 수 있다.
- 데이터 간의 유사성이 계산되며 해당 차원의 정보가 별도로 계산, 누적됨.
- splicing/fusion 방식: 두개의 feature dimension 사이의 유사성의 단순한 중첩(?)으로 볼 수 있음. 일단 fusion common space를 설계하는데 , 여기서 splicing feature들은 fusion public space를 통해 상호적인 fusion feature를 얻음.
- fusion common space: 컨텐츠 정보와 감정 정보의 이질성을 제거할 뿐만 아니라 컨텐츠 정보와 감정 정보끼리의 소통을 가능하게 하여 네트워크 구조에서 Fully connected layer(FC)를 도입.
- FC: 각 뉴런은 이전 레이어의 참여한 모든 뉴런들로 이루어져있는데 이를 통해 feature사이의 종합적인 정보 전이를 가능하게 하여 컨텐츠 정보와 감정 정보가 완전히 상호작용 할 수 있음
- Loss functio of common fusion space: 상호적인 fusion feature 사이 contrast의 손실을 측정한다.
Objective function of DPVM
위에서 얻은 세개의 loss function 으로 DPVM의 최적화 함수를 구하면
Experiment
Dataset
- HIMV-200K
- 대규모의 태깅 된 비디오 데이터셋인 Youtube-8M의 벤치마크 데이터셋
- 비디오 데이터는 Youtube로부터 얻어왔으며, 각 비디오는 오디오와 비디오 모달리티를 포함하고 있음
- 비디오는 시각적 정보를 기반으로 24개의 테마로 구분됨
- 예술/엔터테인먼트 테마의 뮤직비디오 관련 데이터로, 20만개의 비디오-뮤직 쌍으로 구성 되어 있음.
- MVED
- 영화 데이터셋
- 영화 내에서 배경음악이 포함된 비디오 클립을 15초 단위로 캡쳐
- 3천개의 비디오-음악 쌍으로 구성
- 각 데이터엔 슬프다, 행복하다, 무섭다와 같은 감정적인 묘사가 형용사로 제공되는데 이를 기반으로 데이터셋은 긍정, 부정, 중립의 세가지 polarity label을 제공함
- 제공된 emotion description과 emotion annotation을 결합해 행복-긍정, 슬픔-부정과 같은 형용사-polarity 간 복합 태그를 형성 할 수 있음.
- 복합 태그를 기준으로 각 비디오에 일치하는 음악 트랙 5개를 선정하는데, 이때 기준으로
i. 같은 영화나 TV 시리즈의 배경음악에 우선순위 부여
ii. 일관성이 있는 복합 태그
iii. 비디오 데이터와 음악 데이터에 대해 일관성 있는 주관적인 감상
* 아마 여러개의 영화 클립 중에서 같은 영화나 시리즈에 나온적 있는 음악, 일관성 있는 태깅과 감상이 있는 음악-비디오 페어를 줄세우기 해서 5개 선정한단 뜻인듯? - 선정된 5개의 음악 데이터는 각 비디오로 매칭이 되어 1만개의 비디오-음악 쌍을 생성한다.
Evaluation
비교 모델은 마찬가지로 Common space에 MLP가 사용되었고 3가지의 손실 함수를 최적화 한 모델이다. 비디오 feature 추출에 ImageNet을 사용하고 music feature 추출엔 OpenL3를 사용하였다.
- B-Emotion(single path): 감정 데이터셋에서 네트워크를 사전훈련 하였지만 감정 정보를 추출하지는 않음(베이스라인+emotion 학습)
- B-Content(single path): 기본 베이스라인
- : Splicing fusion strategy를 추가한 DPVM
- : interactive fusion strategy를 추가
- PPML: 복합 손실 함수 추가
에 PPML을 추가한 모델이 가장 좋은 성능을 보였음..당연함
따라서 비디오-음악 retrieval 작업에서 듀얼 패스 네트워크를 포함 하는 것이 성능이 가장 잘 나왔기 때문에 감성 정보의 중요성을 확인 할 수 있음 .
