
Lin, Tsung-Yi, et al. “Feature pyramid networks for object detection.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2017
Feature pyramid는 다양한 스케일의 object를 탐지하기 위한 방법이다. 본 논문에서는 DCN(Deep Convolution Network)에서 다중 스케일 피라미드 계층구조를 사용해 feature pyramid를 구축한다. Lateral connection을 포함한 Top-down 구조를 통해 모든 scale에서 고차원의 semantic feature map을 구축한다. 또한 FPN을 Faster R-CNN에 적용한다.
Preview
이 논문에서 언급하는 Pyramid란 Convolution network를 통해 얻은 feature map을 피라미드 형태로 쌓아올린 것을 의미한다. input과 가까운 레벨의 feature map은 convolution을 덜 거쳐 해상도가 높고(high resolution) 낮은 수준의 feature들로 구성이 되어있는 반면 level이 올라갈수록 저해상도와 높은 수준의 feature들로 구성된다.
기존의 feature pyramid 방식을 살펴보자.
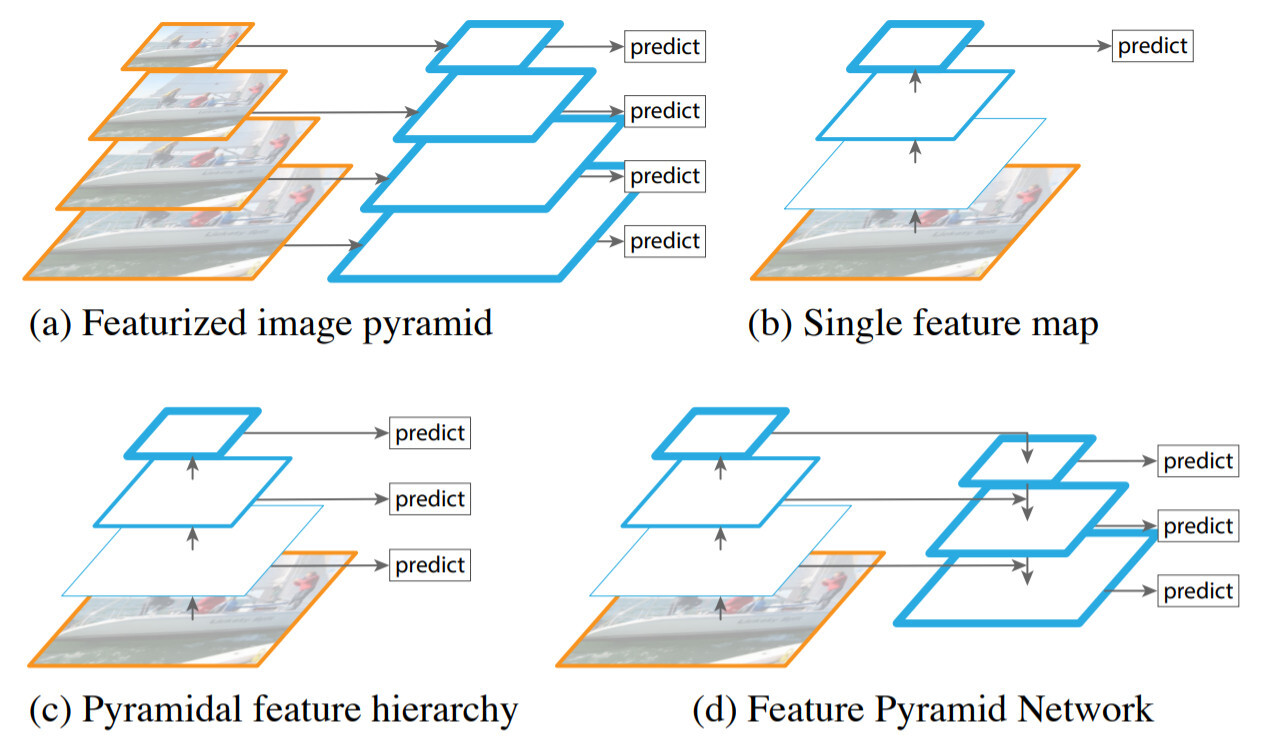
(a) Featurized Image Pyramid
Featurized image pyramid는 각 레벨의 크기가 미리 지정되어 있으며, 오브젝트들은 미리 지정된 레벨에 맞춰 크기가 변화하기 때문에 scale invariant한 특징이 있다. 해당 모델은 피라미드의 모든 레벨에서 스캔하여 scale-widely한 탐지가 가능하지만 밀도가 높은 샘플엔 한계가 있으며 메모리와 속도 측면에서 비효율적이다.
(b) Single Feature Map
Deep Convolutional Networks(ConvNets)의 등장으로 ConvNet이 Feature를 계산할 수 있게 되었고 이로 인해 고차원의 semantic 표현이 가능하게 되면서 single input만을 가지고도 recognition이 가능해졌다. 따라서 모든 레벨에서(고해상도 레벨에서도) 의미적으로 강력한 다중 스케일 feature 표현을 할 수 있다. 하지만 추론 속도가 느리고 메모리 차지가 많다는 단점이 있다.
(c) Pyramidal Feature Hierarchy
deep ConvNet은 feature만 계산하는 것 뿐만 아니라 레이어별 feature hierarchy도 계산할 수 있다. 이 feature hierarchy는 내부의 멀티 스케일과 pyramidal shape를 가지고 있다. 이러한 네트워크 내 feature hierarchy는 다른 공간적 해상도의 feature map을 생성하지만 깊이에 따라 semantic gap이 크다는 문제가 있다. 이로인해 저차원의 feature를 가지고 있는 고해상도 map은 object recognition을 위한 표현 능력을 해칠 수 있다.
해당 모델의 경우 중 하나인 SSD(Single Shot Detector)는 ConvNet의 pyramidal feature hierarchy를 이용한 첫번째 모델인데, 이런 SSD 형식의피라미드는 각각 다른 레이어들에서 부터 얻은 다중 스케일 피쳐맵을 재사용하기 때문에 비용 문제가 없다. 하지만 저차원 피쳐 사용을 피하기 위해 high-up 방식으로 피라미드 구축을 시작하는 것이 아닌 이미 계산된 레이어들을 재사용하는 방식으로, 새로운 레이어들을 추가하여 피라미드를 쌓기 때문에 작은 object 탐지를 위한 고해상도 map을 사용하지 못한다는 단점이 있다.
(d) Feature Pyramid Network
따라서 본 논문에서 제안하는 해당 모델은 모든 스케일에 강력한 의미를 가지게 하면서 ConvNet feature hierarchy의 pyramidal shape를 통합한다. 이를 위해 저해상도면서 의미적으로 강력한 feature들과 의미적으로 약하지만 고차원인 레이어를 Top-down 방식을 사용해 혼합한다. 그 결과 feature pyramid의 모든 레벨은 풍부한 의미를 가질 수 있게 된다.
Methods
해당 논문에서 제안하는 Feature pyramid network는 ConvNet의 pyramidal feature hierarchy를 끌어내는 것이 목적이기 때문에 FPN은 sliding window proposal(RPN)과 Fast R-CNN에 적용한다. FPN은 임의의 크기를 가진 단일 스케일 이미지를 입력하여 다중 레벨에서 특정 크기를 가진 피쳐맵을 추출한다. 이 과정은 backbone convolutional 구조에서 독립적으로 이뤄지며 해당 논문은 backbone network로써 ResNet을 사용한다.
(1) Bottom-up pathway
Bottom-up pathway는 ConvNet의 feed forward 계산 방식을 사용한다.같은 크기의 feature map을 네트워크의 같은 스테이지에 있다고 간주하며, 각 단계에 한개의 Pyramid level을 지정한다. 한 스테이지에서 가장 깊은 레이어는 가장 강력한 feature를 가지고 있기 때문에 각 스테이지의 최종 output을 feature map의 Reference set으로 설정한다. ResNet 각 스테이지의 마지막 residual block에서 나온 결과를 라고 하는데 이것들은 각각 conv2, conv3, conv4, conv5에서 추출되며 단계를 거듭할 수록 Feature map의 크기가 절반으로 줄어든다. 각각 {4,8,16, 32}pixel의 stride를 가지고 있다. 다만 conv1의 결과는 메모리 효율이 떨어지기 때문에 제외하였다.
(2) Top-down pathway and lateral connection
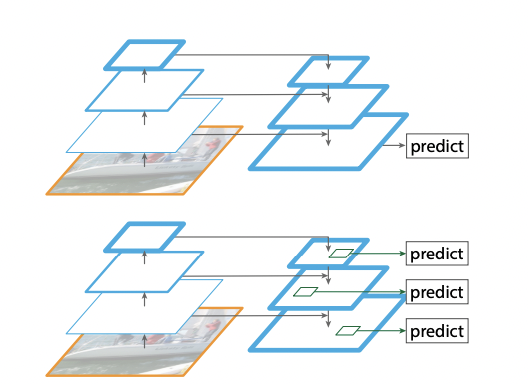
Top down pathway는 각 레벨의 피쳐맵을 2배로 업샘플링하여 채널 수를 맞춰주는 과정이다. 업생플링 된 피쳐맵은 원본 피쳐맵보다 공간적으로 좀 더 coarser하지만 더 강한 의미를 가지고 있다.
Top down pathway는 lateral connection을 통해 진행되는데, 각 lateral connection은 bottom up pathway로부터, 같은 크기의 피쳐맵을 통합한다. bottom up의 피쳐맵은 low-level semantic을 가지고 있지만 subsmapling이 조금밖에 안 되어 정확한 localization을 수행할 수 있다.
위의 그림을 보면 저해상도 피쳐맵을 2배만큼 업샘플링해주고 그에 상응하는 Bottom up map과 element-wise addition으로 합쳐주는데 이때 채널 차원 축소를 위해 1x1 컨볼루션 연산을 사용한다.
가장 해상도가 낮고 의미적으로 강력한 피쳐맵인 에 1x1 컨볼루션 연산을 적용함으로써 시작하며, element wise addition으로 통합된 피쳐맵에 3x3 컨볼루션 연산을 적용해 최종 피쳐맵를얻는다. 3x3 컨볼루션을 통해 채널수가 256으로 맞춰졌기 때문에 같은 차원 크기를 가지고 있다.
Application
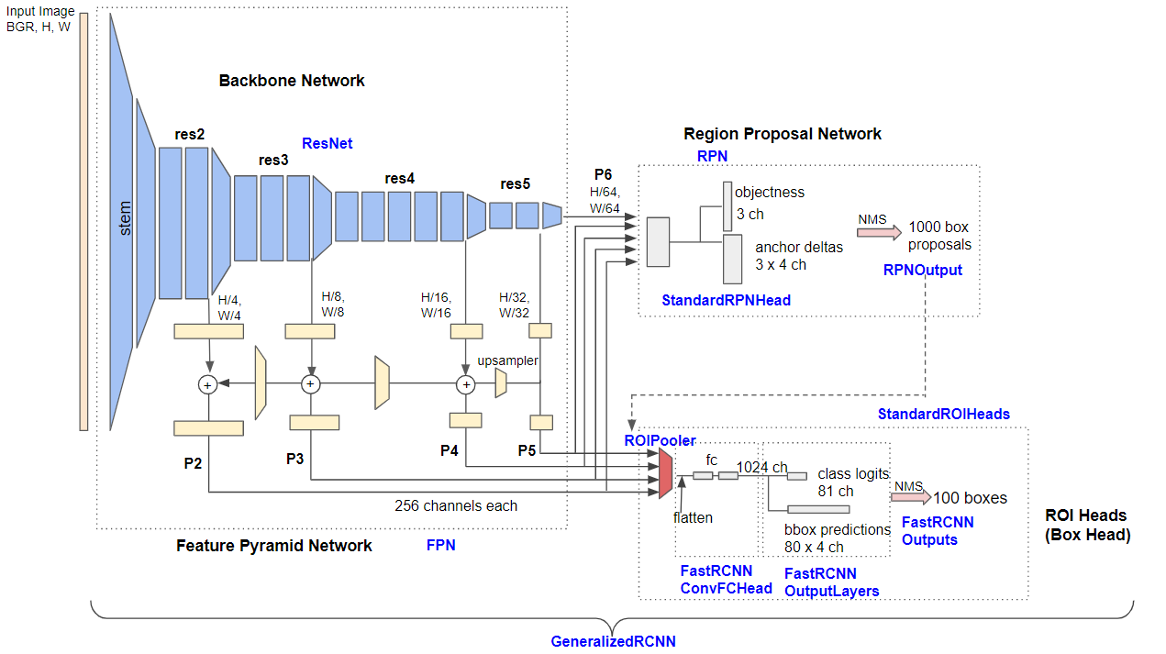
ResNet
Backbone network로써 ResNet을 사용하고 있다. ResNet에 이미지를 입력하고 Bottom up pathway를 통해 원본 이미지의 $$ 1/4, 1/8, 1/16, 1/32$$ 크기에 해당하는 output feature map 를 추출한다. 이후 Top-down pathway에서 1x1 컨볼루션과 업샘플링을 수행해주고, lateral connection으로 element-wise addiction, 3x3 컨볼루션 연산으로 최종 피쳐맵인 를 얻어준다.
(2) FPN for RPN
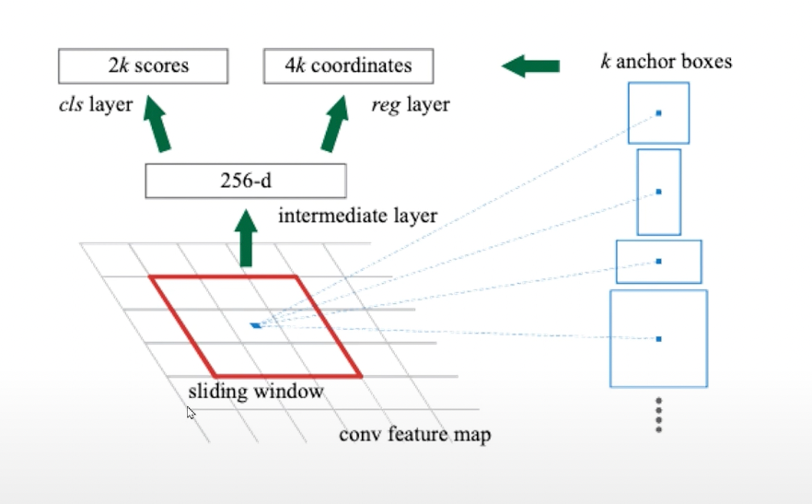
RPN은 컨볼루션 피쳐맵에 3x3 윈도우를 통과시키면서 윈도우의 anchor pixel을 기준으로 얻은 k개의 anchor box 중 class나 bounding box와 일치하는 anchor box를 proposal로써 ROI를 예측하는 테스크이다.
ResNet으로부터 얻은 를 각각 RPN에 입력하여 각 클래스의 스코어와 bounding box regressor를 출력한다. 그 중 클래스 스코어가 높은 상위 100개를 region proposal로 지정한다.
(3) FPN for Fast R-CNN
ResNet으로부터 얻은 를 RPN의 아웃풋인 100개의 region proposal과 함께 ROI pooling을 수행하여 고정된 크기의 feature map을 얻을 수 있다.
