학습목표
- 퍼센트론의 개념을 이해할 수 있다.
- 퍼셉트론을 간단히 구현해보자.
💠 퍼셉트론 (Perceptron)

-
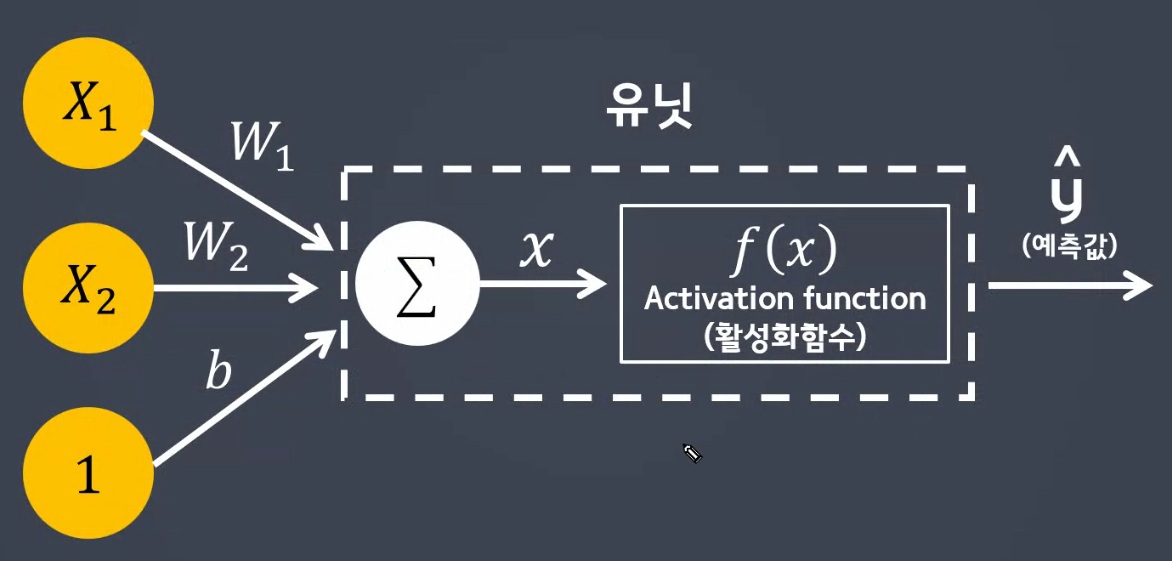
unit : 퍼셉트론 한 단위
-
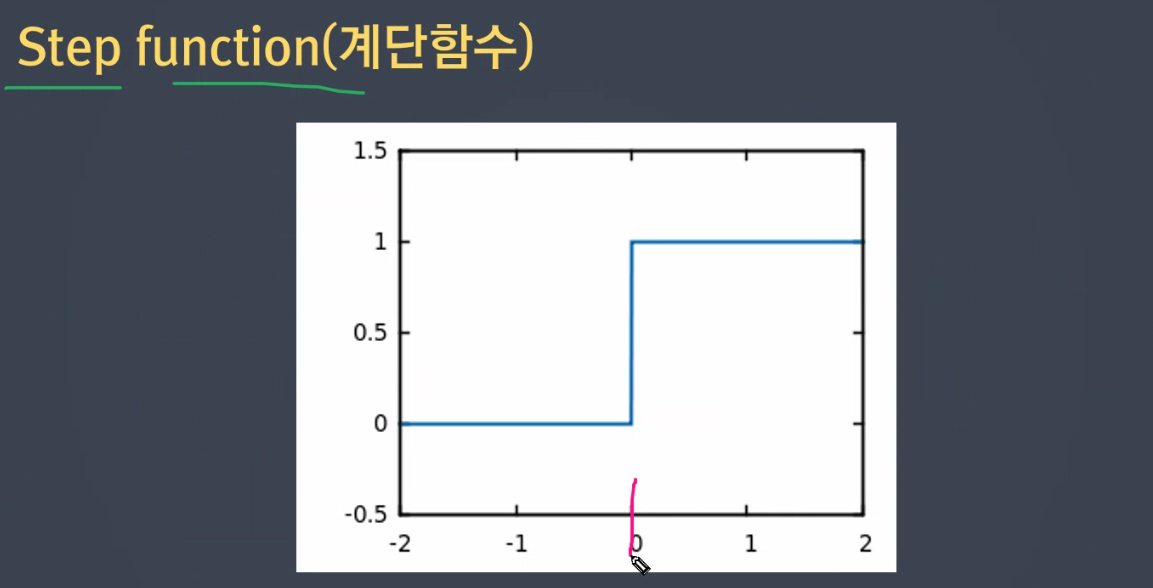
Activation function(활성화함수) : 역치
-
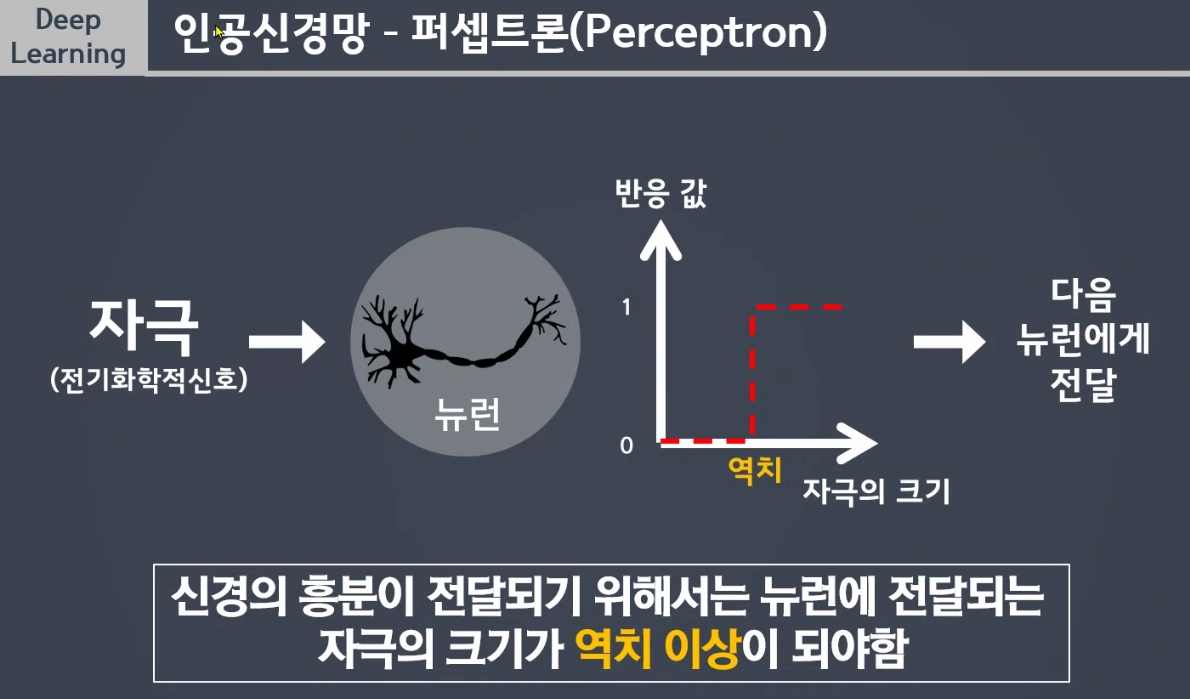
뉴런을 수학적 모델로 고안한 것
-
<= 0,> 0을 역치라고 생각하면 됨. -
기준값 이상일 경우 다음 뉴런에게 전달, 기준값 이하일 경우 비활성화한다.
퍼셉트론의 한계
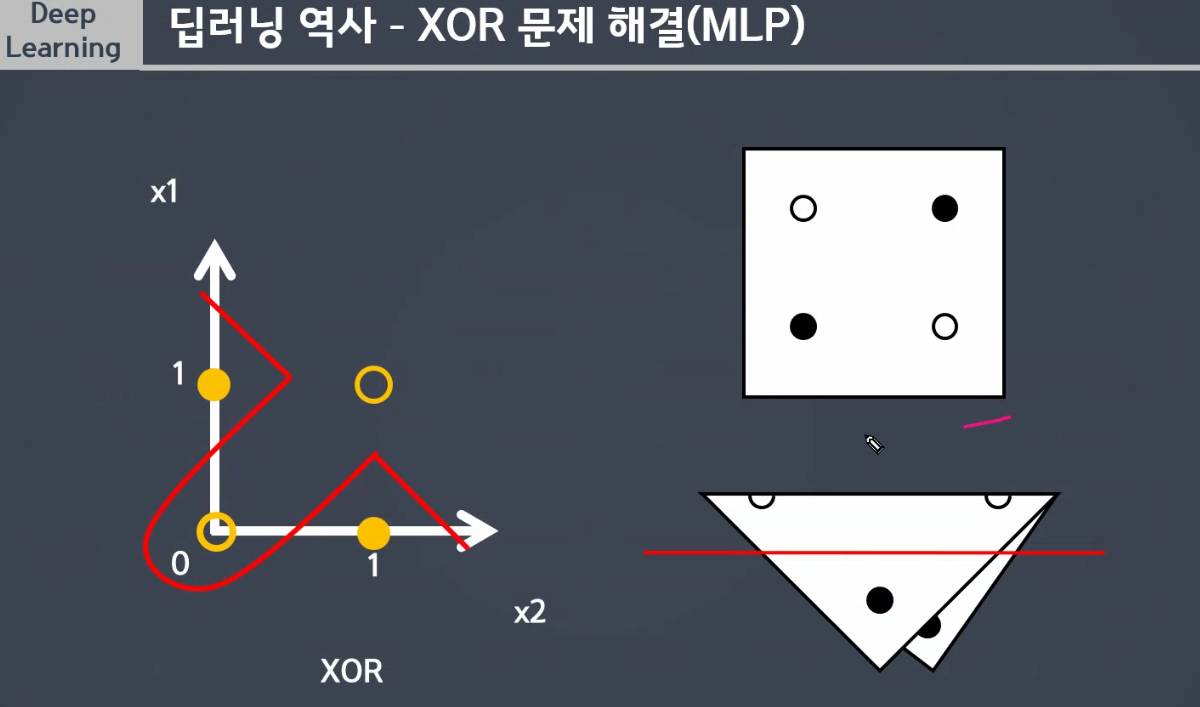
- AND 게이트, OR 게이트는 퍼셉트론으로 구분할 수 있다.
- XOR 게이트를 퍼셉트론으로 구분할 수 없다.
- 두개가 다를 때 1, 두개가 같으면 0
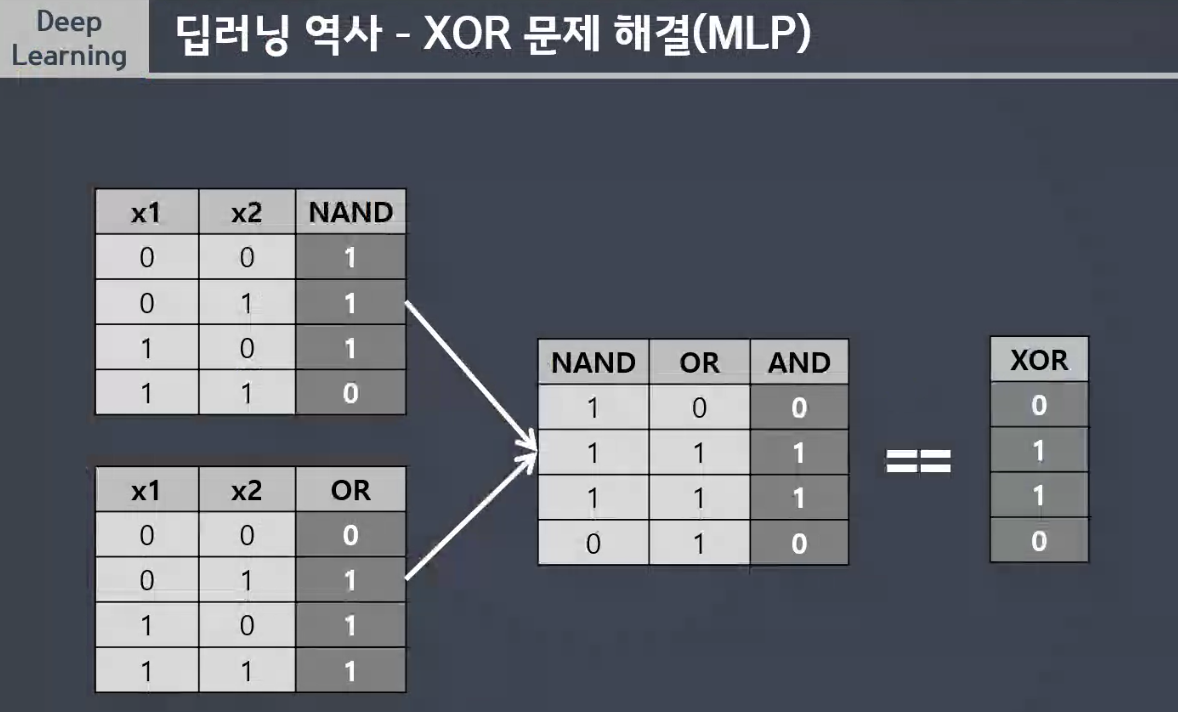
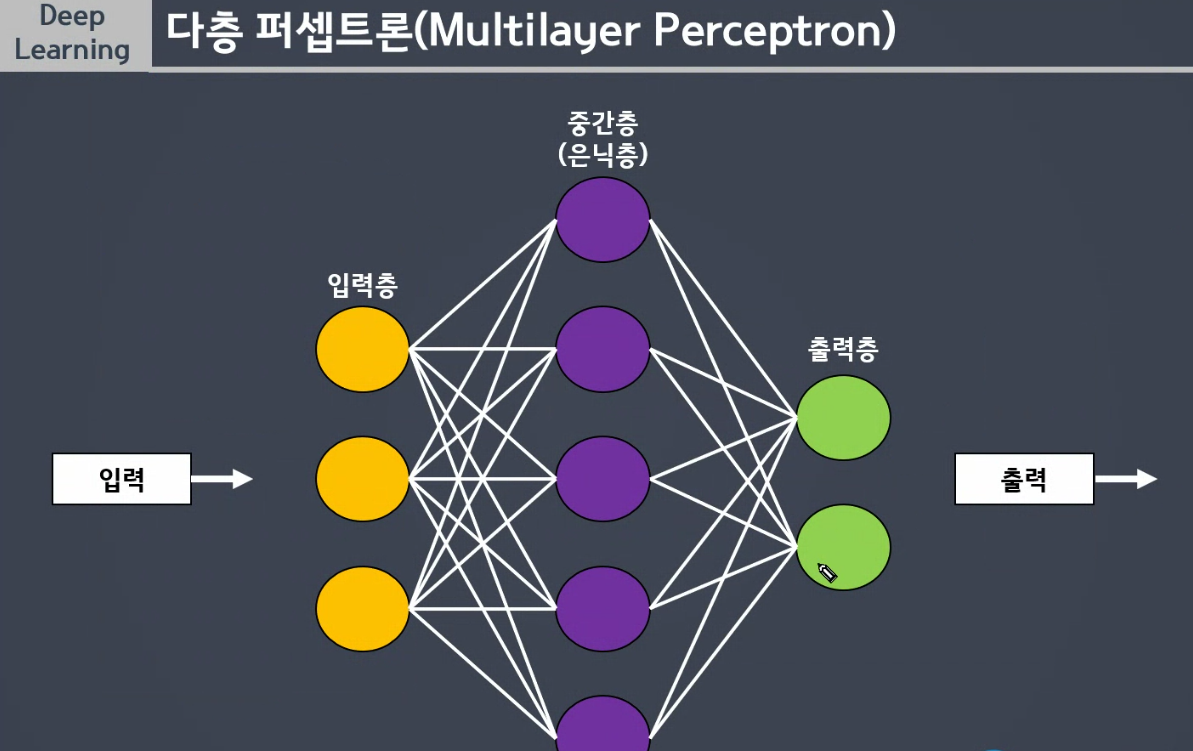
💠 MLP (Multilayer Perceptron)
- XOR 문제를 해결
- 퍼셉트론을 여러개의 층으로 구성하여 만든 신경망
- 비선형성의 특징을 지니는 분할선을 지닌다.
다층 퍼셉트론의 특징
비선형 데이터를 분리할 수 있다.
학습시간이 오래 걸린다.
가중치 파라미터가 많아 과적합되기 쉽다.
⭐ 가중치 초기 값에 민감하며 지역 최적점에 빠지기 쉽다.
실습
AND 퍼셉트론 만들기
import numpy as np
# 활성화 함수 : step function
def activation_function(x) :
if x <= 0:
return 0 # 비활성화
else:
return 1 # 활성화# AND 구분하는 가중치가 학습되었다고 가정
def AND(x1, x2) :
w1 = 1
w2 = 1
b = -1.5
y = w1*x1 + w2*x2 + b # 선형모델
return activation_function(y)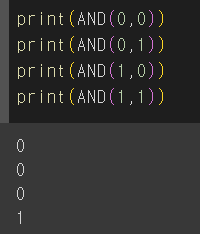
OR 퍼셉트론 만들기
# OR 구분하는 가중치가 학습되었다고 가정
def OR(x1,x2):
w1 = 1
w2 = 1
b = 0
y = w1*x1 + w2*x2 + b # 선형모델
return activation_function(y)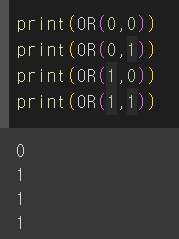
NAND 퍼셉트론 만들기
# NAND 구분하는 가중치가 학습되었다고 가정
def NAND(x1, x2) :
w1 = -1
w2 = -1
b = 2
y = w1*x1 + w2*x2 + b # 선형모델
return activation_function(y)
XOR를 해결하는 MLP 만들기
def XOR_MLP(x1, x2):
a2 = NAND(x1, x2)
a1 = OR(x1, x2)
return AND(a1, a2) 
keras 활용 XOR MLP 만들기
# 문제
X = np.array([[0,0],
[1,0],
[0,1],
[1,1]])
# 정답
y = np.array([0,1,1,0])from tensorflow.keras.models import Sequential # 뼈대 클래스
from tensorflow.keras.layers import InputLayer, Dense # 입력층, 퍼센트론의 묶음(중간층, 출력층)1. 모델설계
# 1. 모델 설계
xor_model = Sequential() # 뼈대 생성
xor_model.add(InputLayer(shape=(2,))) # 입력층
xor_model.add(Dense(units=2, activation='sigmoid')) # 중간층 2개
xor_model.add(Dense(units=1, activation='sigmoid')) # 출력층2. 학습방법 및 평가방법 설정
# 2. 학습방법 및 평가방법 설정
xor_model.compile(loss="binary_crossentropy", # 손실함수 : 모델 예측의 틀린 정도를 계산
optimizer="adam", # 최적화 함수 : 오차를 기반으로 가중치를 최적화한다.
metrics=['accuracy']) # 평가지표 : 정확도🔰 Binary Cross-Entropy Loss
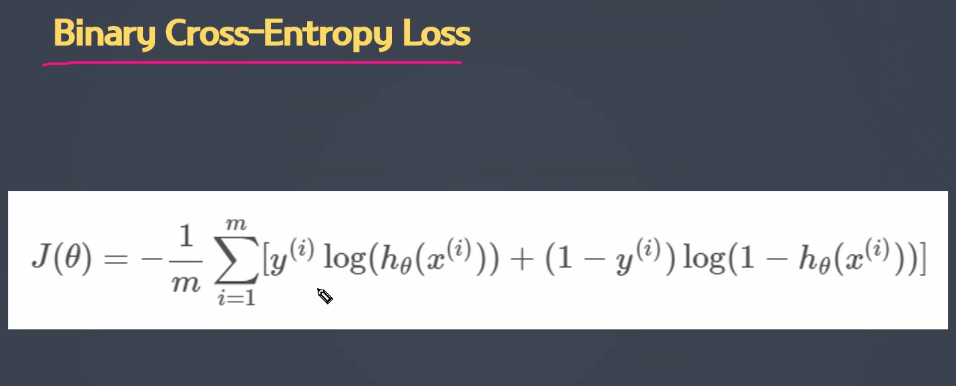
- 분류에서는 오차가 크지 않기 때문에
MSE를 이용해서 좋은 모델을 만드는데 도움이 되지 않기 때문에 CROSS ENTROPY LOSS를 사용한다.
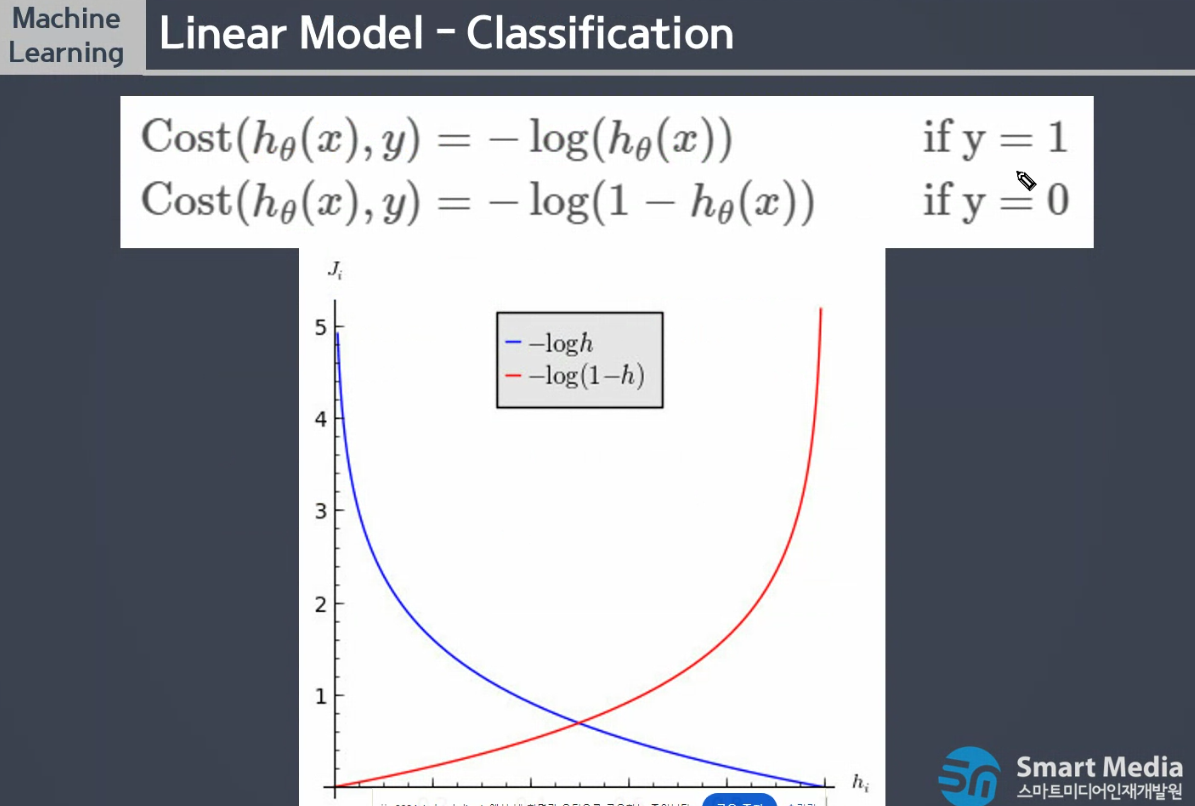
분류데이터의 오차값이 1을 넘지 않을 때 로그함수를 적용하는데, - 실제값 log함수 + (1-실제값)log함수
- 실제값이 1(빨간함수), 0(파란함수)인지에 따라 적절한 함수만 동작할 수 있도록 함
- log함수를 이용하여 잘못된 예측을 할수록 패널티를 더 크게 부과하여 차이가 크게 보인다.
3. 모델학습
xor_model.fit(X,y, epochs=2000) # 최적화 횟수4. 모델예측
xor_model.predict(np.array([[0,0],[1,0]]))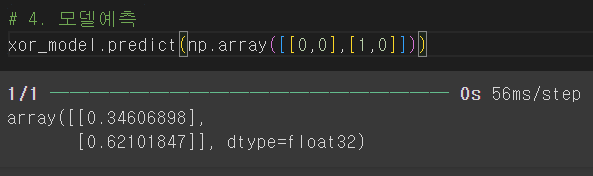
0.5 이하는 0, 0.5 이상이 1로 생각한다.
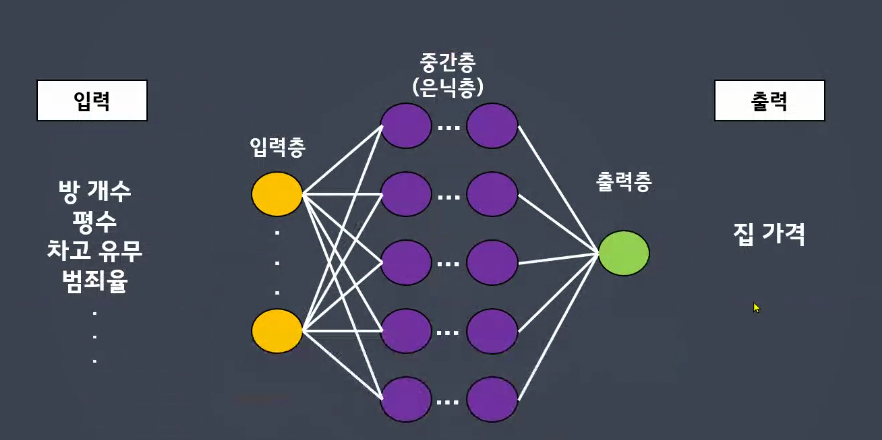
중간층은 몇 층으로 몇 개가 되든 상관 없다. 입력층과 출력층은 개수 확실한 수치로 작성
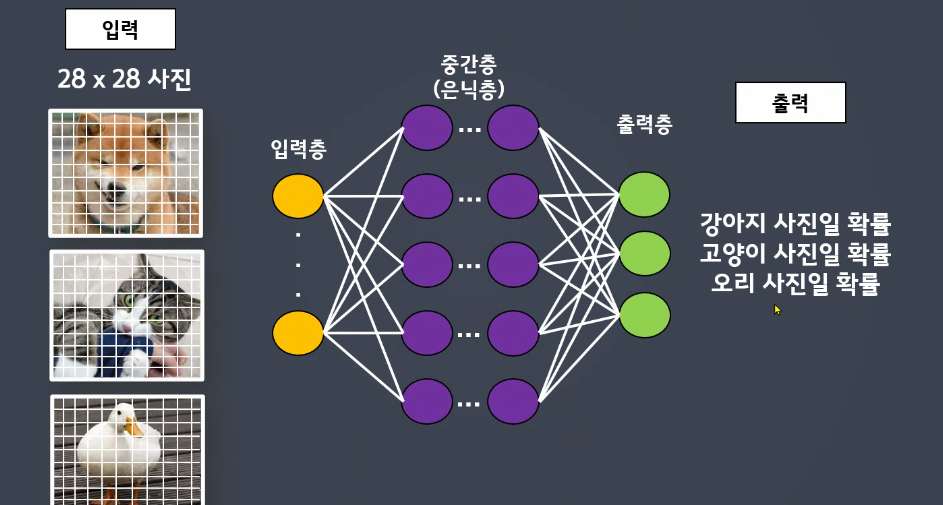
-
[예1] 사진(입력) -> 어떤 동물 사진인지 확률(출력)
입력층 : 28 * 28 개
출력층 : 3개 - 강아지, 고양이, 오리 사진일 확률 -
[예2] 그림(입력) -> 사진(출력)
입력층 : 28 28 개
출력층 : 28 28 개
픽셀 하나의 색을 예측 -> 1개로 본다.

Hello, World!